20162330 2017-2018-1《程序設計與數據結構》第三周學習總結
2017-2018-1 學習總結目錄: 1 2 3 5 6 7 9 10 11 12
目錄
- 0. 教材學習內容總結
- 0.1 查找
- 0.2 排序
- 0.3 分析查找與排序算法
- 1. 教材學習中的問題和解決過程
- 1.1 快速排序示例的理解
- 1.2 算法復雜度練習
- 2. 代碼調試中的問題和解決過程
- 2.1 數組中的字符串元素排序
教材學習內容總結
1.查找
-
查找是在數據項中找到指定目標元素或是確定目標不存在的過程。
-
查找池中找到目標需要的比較次數會隨著數據項的增加而增加;
查找算法作用于 Comparable (多態)對象中的數組(compareTo 方法比較元素)。 -
查找策略:
- ① 窮舉法(線性查找)
- ② 分治(二分查找)
-
線性查找:依次比較,不要求有序,基于 Comparable 接口的實現,時間復雜度:O(n)
二分查找:效率高,適用于有序數據項,迭代,分治,時間復雜度:O(nlog\(_2\)n)
public static Comparable binarySearch (Comparable[] data, Comparable target){
Comparable result = null;
int first = 0, last = data.length - 1,mid; //查找范圍
while(result == null && first <=last){
mid = (first + last)/2; //中間位置比較元素
if (data[mid].compareTo(target) == 0)
result = data[mid]; //查找成功
else
if(data[mid].compareTo(target) > 0)
last = mid - 1; //范圍縮小到前半段
else
first = mid + 1; //范圍縮小到后半段
}
return result;
}
【補充】二分查找算法主要步驟歸納如下:(假設是有序列表)
(1)定義初值:first = 0, last = length - 1;
(2)如果first ≤ last,循環執行以下步驟:
①mid = (first + last)/2;
② 如果 target 與 data[mid] 的關鍵字值相等,則查找成功,返回 mid 值,否則繼續執行;
③ 如果 target 小于 data[mid] 的關鍵字值,那么last = mid - 1,否則first = mid + 1。
(3)如果first > last,查找失敗,返回 null。
2.排序
-
排序:按照某種標準將一列數據項次序重排;
依據:關鍵字(字母、數字等);
順序:遞增、遞減、非遞增、非遞減。 -
選擇排序:掃描整個表,找到最小值,交換。反復將一個個具體的值放到它 最終 的有序位置。(整理無序撲克牌)
public static void selectionSort(Comparable[] data)
{
int min;
for(int index = 0 ; index < data.length - 1; index++) // 控制存儲位置
{
min = index;
for(int scan = index + 1;scan < data.length; scan++) // 查找余下數據
if (data[scan].compareTo(data[min]) < 0) // 查找最小值
min = scan;
swap(data,min,index); // 交換賦值
}
}
交換方法:
private static void swap(Comparable[] data,int index1,int index2){
Comparable temp = data[index1]; //引入一個臨時變量
data[index1] = data[index2];
data[index2] = temp;
}
-
示例:


-
插入排序:反復將一個個具體的值插入到有序的子序列中(合適位置)。(抓牌整理法)
偽代碼及實現過程:
for(從第二個數據開始對所有數據循環處理)
{
while (第i個數據小于它之前的第i-1個數據)
{
將第i個數據復制到一個空閑空間臨時存儲,這個空間為“哨兵”
在前i-1個數據中尋找合適的位置,將從該位置開始的元素全部后移
將哨兵數據插入到合適位置
}
}
public static void insertionSort (Comparable[] data)
{
for (int index = 1; index < data.length; index++)
{
Comparable key = data[index];
int position = index;
// 哨兵臨時存儲
while (position > 0 && data[position-1].compareTo(key) > 0)
{
data[position] = data[position-1]; //位置全部后移
position--;
}
data[position] = key; //合適位置
}
}
-
示例:
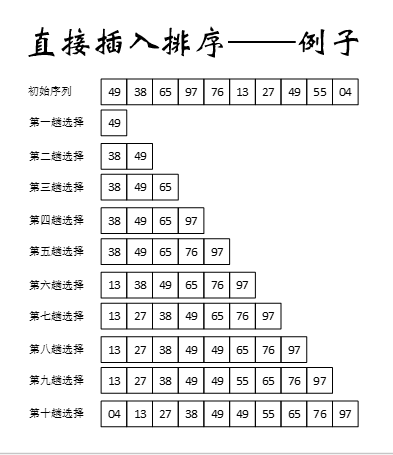
-
希爾排序:把一個長序列分割為若干個短序列,直接插入排序。
示例:
-
冒泡排序:反復比較相鄰元素,如果必要就交換次序。
public static void bubbleSort (Comparable[] data)
{
int position, scan;
for (position = data.length - 1; position >= 0; position--)
{
for (scan = 0; scan <= position - 1; scan++)
if (data[scan].compareTo(data[scan+1]) > 0)
swap (data, scan, scan+1); //逆序交換
}
}
-
示例:

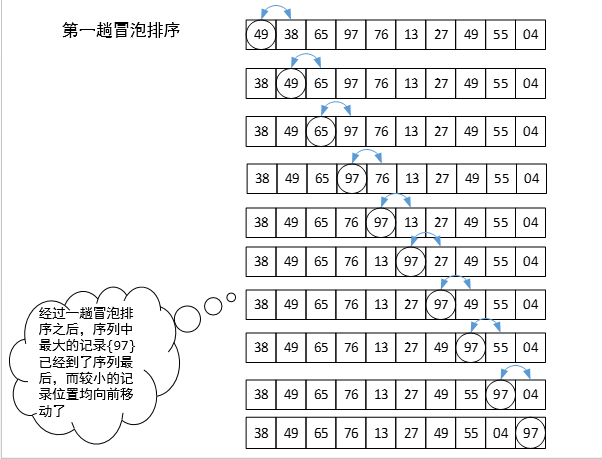
-
快速排序:根據樞軸劃分序列,之后使用遞歸對子序列排序。
樞軸:一般而言我們選擇整個序列的第一個數為樞軸。
public static void quickSort (Comparable[] data, int min, int max)
{
int pivot;
if (min < max)
{
pivot = partition (data, min, max); // make partitions(定義樞軸)
quickSort(data, min, pivot-1); // sort left partition
quickSort(data, pivot+1, max); // sort right partition
}
}
劃分并排序:
private static int partition (Comparable[] data, int min, int max)
{
// Use first element as the partition value
Comparable partitionValue = data[min];
int left = min;
int right = max;
while (left < right)
{
// Search for an element that is > the partition element
while (data[left].compareTo(partitionValue) <= 0 && left < right)
left++;
// Search for an element that is < the partitionelement
while (data[right].compareTo(partitionValue) > 0)
right--;
if (left < right)
swap(data, left, right);
}
// Move the partition element to its final position
swap (data, min, right);
return right;
}
-
示例:


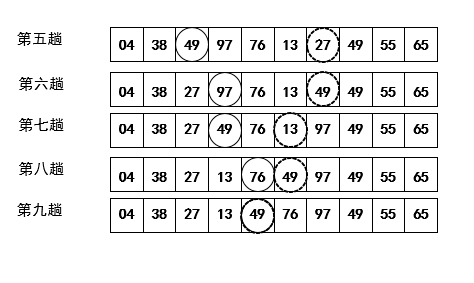
-
歸并排序:遞歸平分,直到每個序列只含一個元素,之后歸并為有序表。
public static void mergeSort (Comparable[] data, int min, int max)
{
if (min < max)
{
int mid = (min + max) / 2;
mergeSort (data, min, mid);
mergeSort (data, mid+1, max);
merge (data, min, mid, max);
}
}
歸并算法中關鍵代碼:
int first1 = first, last1 = mid; // endpoints of first subarray
int first2 = mid+1, last2 = last; // endpoints of second subarray
int index = first1; // next index open in temp array
// Copy smaller item from each subarray into temp until one
// of the subarrays is exhausted
while (first1 <= last1 && first2 <= last2)
{
if (data[first1].compareTo(data[first2]) < 0)
{
temp[index] = data[first1];
first1++;
}
else
{
temp[index] = data[first2];
first2++;
}
index++;
}
之后檢查各個序列中的元素是否用盡,最后將有序數據復制回原數組。
-
示例:

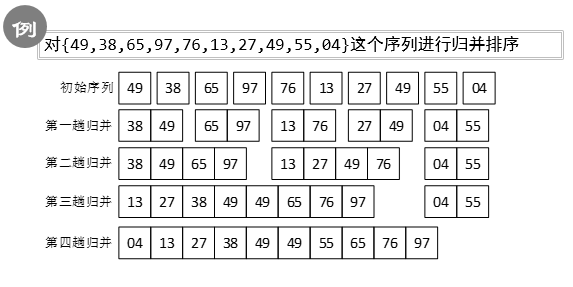
-
分配排序:用額外空間節省時間。(桶排序、基數排序)
示例:

-
堆排序:堆積排序(Heapsort)是指利用堆這種數據結構所設計的一種排序算法。堆是一個近似完全二叉樹的結構,并同時滿足堆性質:即子結點的鍵值或索引總是小于(或者大于)它的父結點。
示例:

3.分析查找及排序算法
-
考慮最差情形
-
查找算法:二分查找高效(對數階)
-
排序算法:性能比較
排序方法 平均時間 最壞情況 輔助存儲 冒泡排序 O(\(n^2\)) O(\(n^2\)) O(1) 選擇排序 O(\(n^2\)) O(\(n^2\)) O(1) 希爾排序 O(nlogn) O(nlogn) O(1) 快速排序 O(nlogn) O(\(n^2\)) O(logn) 堆排序 O(nlogn) O(nlogn) O(1) 歸并排序 O(nlogn) O(nlogn) O(n) 插入排序 O(\(n^2\)) O(\(n^2\)) O(1) 桶排序 O(n) O(\(n^2\)) O(n) 基數排序 O(d(n+k)) O(d(n+k)) O(d(kd)) 【注】表中n是排序元素個數,d個關鍵字,關鍵碼的取值范圍為k
教材學習中的問題和解決過程
-
【問題1】:在看本章內容的PPT時,快速排序有一個示例沒看懂,只看圖的話,我覺得實線圈中的數和加粗的虛線圈中的數的位置變動沒有什么規律,所以不太理解快速排序的執行順序。

-
解決方案 :在仔細閱讀了相關內容之后,我發現實線圈中的數和加粗的虛線圈中的數的位置變動規律、比較順序并不是受到同類線圈的影響,在選好樞軸以后,就開始首尾比較元素,以49為樞軸,左右依次比較,順序就跳過一次,直到縮減到中間位置,便實現了劃分序列。我原來是被不同的線圈中的數迷惑了,才弄錯了執行次序。
【注】樞軸是一個數。 -
【問題2】:關于考試時的算法復雜度練習,求該算法的時間復雜度:
void fun3(int n)
{ int i=0,s=0;
while (s<=n)
{ i++;
s=s+i;
}
}
- 解決方案 :之所以做錯是因為當時沒有仔細考慮while循環的執行次數,利用數學中的等差數列公式,可以最后得到 \(\frac{T(n)*[T(n) + 1]}{2}\),可簡化為\(T^2\)(n),而這個值又小于等于n,所以T(n) ≤ \(\sqrt{n}\),即時間復雜度為O(\(\sqrt{n}\))。
代碼調試中的問題和解決過程
-
【問題】:在看教材代碼程序13.4時,不理解將姓氏和名字交換過來之后怎么對數組中的字符串元素排序?

-
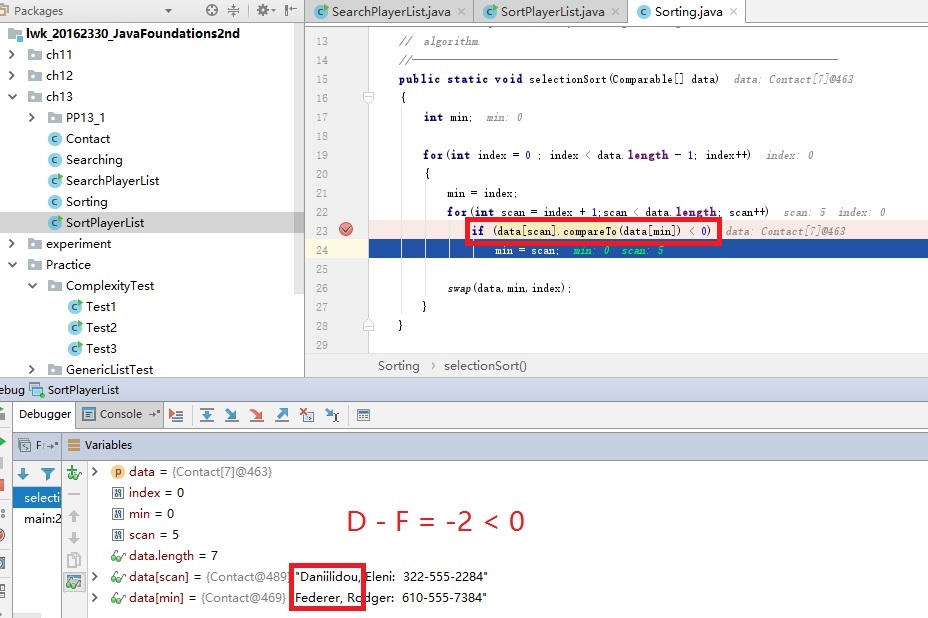
解決方案 :在IDEA中使用debug單步調試,我發現這里的關鍵字是按照字母的順序排列,從而返回一個正整數,負整數或者0。如圖所示:這里的scan索引是D開頭的姓氏,而min索引是F開頭的姓氏,使用compareTo比較時(ASCII碼表中),相當于將字母當成數字相減,所以這里得出的是負整數-2,小于0,所以重新賦值,即最小索引對應的值。
代碼托管
- 本周代碼上傳至 ch13 和 Practice 兩個文件夾里:
(statistics.sh腳本的運行結果截圖)

本周考試錯題總結
-
本周課下測試還未給出錯題和解析:

-
課上測試錯題如下:
【錯題1】有以下用Java語言描述的算法,說明其功能并計算復雜度
double fun(double y,double x,int n)
{
y=x;
while (n>1)
{
y=y*x;
n--;
}
return y;
}
【正解】計算\(x^n\);O(n)
【理解】當時因為循環前將x的值賦給了y,所以我有點糾結到底是計算\(x^n\)還是\(y^n\),最后寫成\(y^n\)。仔細一想,在循環前的y是否賦值與循環內的x沒有關系,即使循環之外y賦值為x,循環內仍然是x,如果將循環內的y理解為x那么y則是無規律增長的,所以這里是計算\(x^n\),至于O(n),我竟然忘記了加大O符號(?_?)。
- 【錯題2】求該算法的時間復雜度:
void fun3(int n)
{ int i=0,s=0;
while (s<=n)
{ i++;
s=s+i;
}
}
【正解】O(\(\sqrt{n}\))
【理解】之所以做錯是因為當時沒有仔細考慮while循環的執行次數,利用數學中的等差數列公式,可以最后得到 \(\frac{T(n)*[T(n) + 1]}{2}\),可簡化為\(T^2\)(n),而這個值又小于等于n,所以T(n) ≤ \(\sqrt{n}\),即時間復雜度為O(\(\sqrt{n}\))。
結對及互評
- 本周我的結對伙伴莫禮鐘除了聽了課堂上的一些內容之外,課后就沒有其他學習活動了,我建議他把書過一遍,但是仍然被“狼人殺”束縛著,監督幾次都沒有效果。星期一的時候翻了幾頁構建之法,之后又忙于老鄉會,保證過不再通宵玩游戲但是又通宵了一次。本學期只有第一周學習情況良好,之后便一蹶不振。
本周結對學習情況
- 20162319
- 結對學習內容
- 構建之法第十六章(一小部分)
其他(感悟、思考等,可選)
本周狀態一般,比前兩周稍差一些,有點匆忙,但是每當空閑時有有些缺少動力,本周課堂測試做得也不好,能做對的2分題沒有得分,說明前一章的掌握情況有些死板。對于這周的學習內容,我明顯感覺到難度在逐漸上升。這周的活動略多,總是突然來一個通知,有時會影響一天的計劃,但是也不能因為事多就把主要精力大量分散。下周繼續保持狀態,求穩不求快。
-
【附1】教材及考試題中涉及到的英語:
Chinese English Chinese English 泛型 generic 劃分元素 partition element 線性查找 linear search 樞軸點 pivot point 二分查找 binary search 優化 optimize 插入排序 insertion sort 子表 sublist(s) 歸并排序 merge sort 子集 subset 排除 eliminate 指定的 designated -
【附2】本周小組博客:團隊學習:《構建之法》
學習進度條
| 代碼行數(新增/累積) | 博客量(新增/累積) | 學習時間(新增/累積) | 重要成長 | |
|---|---|---|---|---|
| 目標 | 5000行 | 30篇 | 400小時 | |
| 第一周 | 234/234 | 1/28 | 14/14 | 了解算法效率、大O符號等理論內容 |
| 第二周 | 255/489 | 1/29 | 12/26 | 了解敏捷的團隊、泛型的使用 |
| 第三周 | 436/925 | 2/31 | 10/36 | 了解一些查找和排序的算法 |
-
計劃學習時間:14小時
-
實際學習時間:10小時
-
有效學習時間:4小時
-
改進情況:學習時間有些下降,本周創建小組博客反復試驗模板花費了一些不必要的時間,在代碼上明顯感覺有些亂,下周打算把課本上的內容再過一遍。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號