20162330 2017-2018-1《程序設(shè)計與數(shù)據(jù)結(jié)構(gòu)》第十一周學(xué)習(xí)總結(jié)
2017-2018-1 學(xué)習(xí)總結(jié)目錄: 1 2 3 5 6 7 9 10 11 12
目錄
- 0. 教材學(xué)習(xí)內(nèi)容總結(jié)
- 0.1 哈希方法
- 0.2 哈希函數(shù)
- 0.3 解決問題
- 0.4 從哈希表中刪除元素
- 0.5 Java Collections API 中的哈希表
- 1. 教材學(xué)習(xí)中的問題和解決過程
- 1.1 哈希表變滿時,其性能會嚴(yán)重下降
- 1.2 最短路徑算法中的Path列表值
- 1.3 陳留余數(shù)法中確定H(key)中的key與哪個數(shù)取余
- 1.4 互聯(lián)網(wǎng)的搜索引擎對網(wǎng)頁建立索引
教材學(xué)習(xí)內(nèi)容總結(jié)
哈希方法
-
集合中元素的次序:
由元素添加到集合中或從集合中刪除的次序決定。(棧、隊列)
由保存在集合中的元素值的比較結(jié)果而定。(有序表、二叉查找樹)
-
在哈希方法中,元素保存在哈希表中,元素在表中的位置由哈希函數(shù)決定。哈希表中的每個位置稱為單元或桶。
-
使用哈希方法使得對某個元素的訪問時間不依賴于表中的元素個數(shù),不一定比較或定位,只需計算一個具體元素應(yīng)該放在哪里。
對哈希表中一個元素的所有操作都將是 O(1).
-
沖突:兩個元素或關(guān)鍵字都映射到表中的同一個位置。
-
理想哈希函數(shù):將每個元素映射到表中唯一位置的哈希函數(shù)。
對表中元素都有常數(shù)的訪問時間 O(1).
-
哈希表的擴(kuò)容:使用裝載因子動態(tài)調(diào)整。
在之前使用數(shù)組實現(xiàn)棧時,使用了動態(tài)調(diào)整的方法實現(xiàn)擴(kuò)容:
private void expandCapacity() { T[] larger = (T[]) (new Object[stack.length * 2]); for (int index = 0; index < stack.length; index++) larger[index] = stack[index]; stack = larger; }即當(dāng)數(shù)組滿了時,創(chuàng)建一個原來兩倍大小的數(shù)組,將原數(shù)組中的所有元素插入到新數(shù)組中,然后更新原數(shù)組的指向。但是對于哈希表來說,當(dāng)表變滿時其性能嚴(yán)重下降,所以更好的方法是使用裝載因子。(哈希表擴(kuò)展之前,表中允許的最大占有百分比,API 中默認(rèn)為0.75)
哈希函數(shù)
-
哈希函數(shù)能夠合理地將元素散列到表中以避免沖突。
合理的哈希函數(shù)仍能得到對數(shù)據(jù)集的常數(shù)階 O(1)訪問時間。
-
建立哈希函數(shù)的方法:
抽取:僅使用元素值或關(guān)鍵字中的一部分來計算保存元素的位置。(電話號碼、車牌號)
除法:將使用關(guān)鍵字除以某個正整數(shù)后的余數(shù)作為下標(biāo)。
Hashcode(key) = Math.abs(key) % p
將表的大小當(dāng)做 p 可根據(jù)下標(biāo)直接得到元素在表中的位置。使用 p 作為表長和除數(shù),有助于更好地散列關(guān)鍵字。(處理未知關(guān)鍵字)折疊:分段,注意每個子段的長度和下標(biāo)的長度一樣,最后一段可能稍短。
分類:移位折疊(分段相加)、邊界折疊(分段反轉(zhuǎn))。
【注】字符串可以用除法,也可以用折疊方法,使用異或函數(shù)將子串組合,轉(zhuǎn)換為數(shù)值。平方取中:關(guān)鍵字自乘,抽取結(jié)果中部,每次選擇的中部位必須相同。
基數(shù)轉(zhuǎn)換:關(guān)鍵字轉(zhuǎn)換為另一種數(shù)值基數(shù)。
數(shù)字分析:抽取關(guān)鍵字中的指定位進(jìn)行處理。(多種方式)
長度依賴:關(guān)鍵字和關(guān)鍵字的長度組合,或者再進(jìn)一步使用其他方法進(jìn)行處理而得到下標(biāo)。
【注】將字符串中各字符按二進(jìn)制格式進(jìn)行處理,長度依賴和平方取中方法也能適用于字符串。 -
java.lang.Object類定義了 hashcode 方法,根據(jù)對象在內(nèi)存中的位置返回一個整數(shù)。所有的Java對象都能用于哈希方法,但對特定類最好還是定義一個具體的哈希函數(shù)。
解決沖突
-
鏈?zhǔn)椒椒?/strong>:將哈希表看成是集合的表而不是各獨(dú)立單元的表。
每個單元中保存一個指針,指向與表中該位置相關(guān)的元素集合。
-
鏈?zhǔn)椒椒ǖ膶崿F(xiàn)方式:
① 令保存表的數(shù)組大于表中的元素個數(shù),利用額外的空間作為溢出區(qū)來保存與每個表相對應(yīng)的鏈表;數(shù)組中的每個位置既保存元素(關(guān)鍵字),又保存鏈表中下一個元素在數(shù)組中的下標(biāo)。
② 使用鏈,哈希表中的每個單元或桶都類似于之前構(gòu)造鏈表時使用過的 LinearNode 類;
③ 讓表中的每個位置當(dāng)做指向集合的指針。 -
開放地址方法:在表中尋找不同于該元素原先哈希到的另一個開放的位置。(待學(xué)習(xí))
從哈希表中刪除元素
-
鏈?zhǔn)綄崿F(xiàn)中刪除:5種情形。(某一位置、表中(非溢出 → 溢出)、表尾、表的中間、不在表中)
-
開放地址實現(xiàn)中刪除:標(biāo)注,被覆蓋,重新處理。
Java Collections API 中的哈希表
- 提供方案:
Hashtable、HashMap、HashSet、IdentityHashMap、LinkedHashSet、LinkedHashMap、WeakHashMap.
教材學(xué)習(xí)中的問題和解決過程
-
【問題1】:書中的第一部分內(nèi)容介紹哈希方法時,為什么哈希表變滿時,其性能會嚴(yán)重下降?
-
解決方案 :我繼續(xù)讀了課本,結(jié)合哈希函數(shù)的定義,并且查找了一些資料,大致弄懂了。
當(dāng)關(guān)鍵字集合很大時,關(guān)鍵字值不同的元素可能會映射到哈希表的同一地址上,即 k1≠k2 ,但 H(k1)=H(k2),這種現(xiàn)象稱為 沖突,此時稱k1和k2為同義詞。實際中,沖突是不可避免的,只能通過改進(jìn)哈希函數(shù)的性能來減少沖突。
哈希函數(shù)不僅要容易計算,而且要對鍵值的分布要均勻。如果有太多的沖突,哈希表的性能將顯著下降,例如下面的哈希函數(shù):public static int hash(String key , int tableSize){ int hashVal = 0; for(int i=0;i<key.length;i++){ hashVal+=key.charAt(i); } return hashVal%tableSize; }這個哈希函數(shù)很簡單,很容易實現(xiàn),計算哈希值也非常快,但這是個糟糕的哈希函數(shù)。
假設(shè)tableSize很大,為10000,再假設(shè)所有的關(guān)鍵字值的長度都是8個或少于8個字符。因為一個ASCII char是一個0到127之間的整數(shù),那么哈希函數(shù)的值介于0到1016(127*8)之間,這個限制肯定不會產(chǎn)生一個均勻的分布。
所以后來才有了解決沖突、保證均勻分布的鏈?zhǔn)椒椒ê烷_放地址方法。
-
【問題2】:在解答“門票”上莫禮鐘的問題時引發(fā)的思考:最短路徑算法中的Path列表值表示什么?(如圖所示)
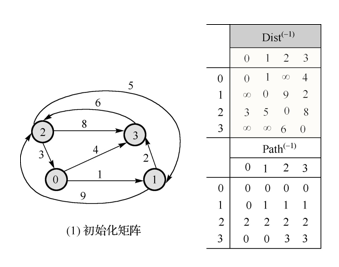
-
解決方案 :(查找資料)
課堂上只講了數(shù)值的規(guī)律,并沒有解釋原因。查找資料之后,我發(fā)現(xiàn)圖中對應(yīng)Disk(-1)的路徑Path(-1)是說:矩陣Path記錄 u,v 兩點之間最短路徑所必須經(jīng)過的點的數(shù)量,所以這里的規(guī)律可以表示為:對應(yīng)Disk表中無窮的值在Path中都為0,其他非無窮的值對應(yīng)每行點 u (起始點)的值。
-
【問題3】:陳留余數(shù)法中如何確定H(key)中的key與哪個數(shù)取余?
-
解決方案 :(查找資料)
對于散列表長為 m 的散列函數(shù)公式為:f( key ) = key mod p ( p ≤ m ),若散列表表長為m,通常p為小于或等于表長(最好接近m)的最小質(zhì)數(shù)或不包含小于20質(zhì)因子的合數(shù)。這么做是因為如果 p 的約數(shù)越多,那么沖突的幾率就越大,這樣余數(shù)相同的數(shù)就會增加,從而使得散列表第一次處理數(shù)據(jù)時的利用率降低,從而增加了算法復(fù)雜度,以上是個人理解。下面舉一個查到的例子說明一下:某散列表的長度為100,散列函數(shù) H(k) = k%P ,則P通常情況下最好選擇哪個呢?
A、91 B、93 C、97 D、99【解析】實踐證明,當(dāng)P取小于哈希表長的最大質(zhì)數(shù)時,產(chǎn)生的哈希函數(shù)較好。我選97,因為它是離長度值最近的最大質(zhì)數(shù)。
-
至于為什么P應(yīng)該這么選取,以下簡單的證明過程:(gcd表示最大公約數(shù))
假設(shè) p 是一個有較多約數(shù)的數(shù),同時在數(shù)據(jù)中存在 key 滿足最大公約數(shù) gcd(p,key) = d > 1 ,即有 p = a·d , key = b·d ,則有以下等式:key % p = key – p·[key/p] = key – p·[b/a] 。其中,[b / a]的取值范圍是不會超過[0,a-1]的正整數(shù)。也就是說,[b / a]的值只有a 種可能,而p 是一個預(yù)先確定的數(shù)。因此上式的值就只有a 種可能了(這顯然縮小了余數(shù)分布的范圍)。這樣,取 mod 運(yùn)算之后的余數(shù)仍然在[0,p-1]內(nèi),但是它的取值僅限于等式可能取到的那些值,也就是說余數(shù)的分布變得不均勻了。容易看出,p 的約數(shù)越多,發(fā)生這種余數(shù)分布不均勻的情況就越頻繁,沖突的幾率越高。而素數(shù)的約數(shù)是最少的,因此我們選用大素數(shù)。所以 p應(yīng)該最優(yōu)選擇素數(shù)。
-
【問題4】:關(guān)于索引在生活中的應(yīng)用,互聯(lián)網(wǎng)的搜索引擎是如何對網(wǎng)頁建立索引從而實現(xiàn)篩選和排序的呢?
-
解決方案 :(閱讀吳軍老師的《數(shù)學(xué)之美》)

在第 8 章的內(nèi)容中,書中談到搜索引擎,對于我需要的答案,可以整合如下:
計算機(jī)做布爾運(yùn)算是非常非常快的。現(xiàn)在最便宜的微機(jī)都可以一次進(jìn)行三十二位布爾運(yùn)算,一秒鐘進(jìn)行十億次以上。當(dāng)然,由于這些二進(jìn)制數(shù)中絕大部分位數(shù)都是零,我們只需要記錄那些等于1的位數(shù)即可。于是,搜索引擎的索引就變成了一張大表:表的每一行對應(yīng)一個關(guān)鍵詞,而每一個關(guān)鍵詞后面跟著一組數(shù)字,是包含該關(guān)鍵詞的文獻(xiàn)序號。
對于互聯(lián)網(wǎng)的搜索引擎來講,每一個網(wǎng)頁就是一個文獻(xiàn)。互聯(lián)網(wǎng)的網(wǎng)頁數(shù)量是巨大的,網(wǎng)絡(luò)中所用的詞也非常多。因此,這個索引是巨大的。早期的搜索引擎,由于計算機(jī)速度和容量的限制,只能對重要、關(guān)鍵的主題詞建立索引。至今很多學(xué)術(shù)雜志還要求作者提供 3-5 個關(guān)鍵詞。這樣,所有不常見的詞和太常見的虛詞就找不到了。現(xiàn)在,為了保證對任何搜索都能提供相關(guān)的網(wǎng)頁,常見的搜索引擎都會對所有的詞進(jìn)行索引。但是,這在工程上卻極具挑戰(zhàn)性。
假如互聯(lián)網(wǎng)上有 100 億個有意義的網(wǎng)頁,而詞匯表的大小至少是30萬,那么這個索引的大小至少是 100 億 x 30萬 = 3000 萬億。考慮到大多數(shù)詞只出現(xiàn)在一部分文本中,壓縮比為100:1,也是30萬億的量級。為了網(wǎng)頁 排名方便,索引中還需存有大量附加信息,諸如每個詞出現(xiàn)的位置、次數(shù)等等。因此,整個索引就變得非常之大,顯然,這不是一臺服務(wù)器的內(nèi)存能夠存下的。所以,這些索引需要通過分布式的方式存儲到不同的服務(wù)器上。普遍的做法就是根據(jù)網(wǎng)頁的序號將索引分成很多份,分別存儲在不同的服務(wù)器中。每當(dāng)接受一個查詢時,這個查詢就被分發(fā)到許許多多的服務(wù)器中,這些服務(wù)器同時并行處理用戶請求,并把結(jié)果送到主服務(wù)器進(jìn)行合并處理,最后將結(jié)果返回給用戶。
隨著互聯(lián)網(wǎng)上內(nèi)容的增加,尤其是互聯(lián)網(wǎng) 2.0 時代,用戶產(chǎn)生的內(nèi)容越來越多,即使是Google這樣的服務(wù)器數(shù)量近乎無限的公司,也感到了數(shù)據(jù)增加帶來的壓力。因此,需要根據(jù)網(wǎng)頁的重要性、質(zhì)量和訪問的頻率建立常用和非常用等不同級別的索引。常用索引需要訪問的速度快,附加信息多,更新也要快;而非常用的要求就低多了。但是不論搜索引擎的索引在工程上如何復(fù)雜,原理上依然非常簡單,即等價于布爾運(yùn)算。
代碼調(diào)試中的問題和解決過程
- 暫無。
代碼托管
- 本周代碼上傳至 test 文件夾中:
(statistics.sh腳本的運(yùn)行結(jié)果截圖)
上周考試錯題總結(jié)
- 【錯題1】Consider a digraph with the following vertices and edges:
vertices: 1, 2, 3, 4
edges: (1,2), (2,1), (3,4)
Which of the following statements are true?
A.The graph has a cycle
B.The graph is connected
C.The graph is acyclic
D.all of the above are true
E.neither a, b, nor c are true.
-
錯誤原因:對環(huán)的概念理解有誤,在兩個元素之間也可能形成環(huán),錯選C。
解析:這個圖有一個循環(huán),即邊(1,2)和(2,1)。因為在1和4之間沒有路徑,所以沒有連接。 -
【錯題2】A graph is a special kind of tree.
A.true
B .false -
錯誤原因:沒有認(rèn)真思考樹和圖的關(guān)系,錯選A。
加深理解:樹是一種特殊的圖,教材的第420頁提到樹總是圖,所以所有的樹都是圖,而所有的圖不一定是樹,所以樹是一種特殊的圖。 -
A cycle is a path that starts and ends on the same vertex.
A.true
B .false -
錯誤原因:對環(huán)的定義理解不清,之前有考慮過重復(fù)邊,但還是錯選A。
加深理解:一個環(huán)是一條在同一頂點開始和結(jié)束的路徑,并且不會有任何重復(fù)邊。
結(jié)對及互評
本周結(jié)對學(xué)習(xí)情況
-
莫禮鐘本周狀態(tài)一般,在團(tuán)隊上面,需要再積極主動一些。在個人學(xué)習(xí)方面,聽課效率不錯,下來我們又一起討論了關(guān)于如何畫出AOE網(wǎng)實現(xiàn)工程中的最短路徑問題,本周結(jié)對學(xué)習(xí)內(nèi)容較少,還有些問題在門票活動中已給出回答。
-
- 結(jié)對學(xué)習(xí)內(nèi)容
- 使用AOE網(wǎng)實現(xiàn)工程中的最短路徑
- 結(jié)對學(xué)習(xí)內(nèi)容
其他(感悟、思考等,可選)
本周算是比較忙的一周,個人作業(yè)除了完成課堂上關(guān)于圖的活動之外,還在課下大致學(xué)習(xí)了第二十章的內(nèi)容。在課堂上婁老師加入了“出門門票”的活動,支持。
本周的團(tuán)隊作業(yè)有些散導(dǎo)致在分工時有些沒頭緒,這次團(tuán)隊任務(wù)按要求應(yīng)該把 代碼規(guī)范、后端架構(gòu)、WBS圖、優(yōu)先級象限圖、ER圖、燃盡圖、TODOList 都呈現(xiàn)出來才算完成吧?雖然我們組的代碼規(guī)范仍需要補(bǔ)充,但是在所有團(tuán)隊當(dāng)中算是最完整的一組了,為自己鼓掌!我們幾個人分別使用對應(yīng)軟件先進(jìn)行學(xué)習(xí),再按要求完成,有的能使用Xmind代替就用Xmind了。當(dāng)然在學(xué)習(xí)軟件或者功能的過程中,有的任務(wù)完成得還不夠熟練和規(guī)范,使用一個軟件并不是一周就可以熟練運(yùn)用的。例如我負(fù)責(zé)的燃盡圖,按照給出參考資料的方法這個圖在碼云上是生成不了的(因為生成網(wǎng)站只針對github上的milestone),用命令行在虛擬機(jī)中裝了一大堆插件還是運(yùn)行錯誤,只好在 github 上重建一個項目,挺費(fèi)勁才弄出來,但是我發(fā)現(xiàn)小組成員用的一些軟件可以自動生成,下周我打算再試試。
每次看到我們團(tuán)隊的總投入時間都比其他團(tuán)隊多,而其他團(tuán)隊的成員可以把這部分時間用在個人學(xué)習(xí)或者其他事情上,總感覺有些憋屈,但是從長遠(yuǎn)的角度來看,多學(xué)會使用幾種工具軟件、提高一下搜商何嘗不是一件樂事呢?這大概是一件重要但不緊急的事。從其他團(tuán)隊的情況看我們團(tuán)隊算是優(yōu)秀的團(tuán)隊了,但是和其他大學(xué)(北航、福大等)的軟件工程團(tuán)隊比起來還是差得太遠(yuǎn)。總之,我們團(tuán)隊會做好自己的分內(nèi)之事,完成質(zhì)量方面盡力即可。
-
【附1】教材及考試題中涉及到的英語:
Chinese English Chinese English 沖突 collision 動態(tài)調(diào)整 dynamic resizing 抽取 extraction 線性探測 linear probing -
【附2】本周小組博客
學(xué)習(xí)進(jìn)度條
| 代碼行數(shù)(新增/累積) | 博客量(新增/累積) | 學(xué)習(xí)時間(新增/累積) | 重要成長 | |
|---|---|---|---|---|
| 目標(biāo) | 5000行 | 30篇 | 400小時 | |
| 第一周 | 234/234 | 1/28 | 14/14 | 了解算法效率、大O符號等理論內(nèi)容 |
| 第二周 | 255/489 | 1/29 | 12/26 | 了解敏捷的團(tuán)隊、泛型的使用 |
| 第三周 | 436/925 | 2/31 | 10/36 | 了解一些查找和排序的算法 |
| 第四周 | 977/1902 | 3/34 | 10/46 | 掌握實現(xiàn)線性結(jié)構(gòu) |
| 第五周 | 800/2702 | 2/36 | 12/58 | 掌握實現(xiàn)棧集合 |
| 第六周 | 260/2962 | 1/37 | 8/64 | 掌握實現(xiàn)隊列集合 |
| 第七周 | 843/3805 | 4/41 | 12/76 | 掌握實現(xiàn)樹的基本結(jié)構(gòu) |
| 第八周 | 738/4543 | 1/42 | 12/88 | 二叉樹實驗(查找樹、平衡樹) |
| 第九周 | 1488/6031 | 2/44 | 15/103 | 掌握堆的實現(xiàn)、哈夫曼樹基本結(jié)構(gòu) |
| 第十周 | 1340/7371 | 2/46 | 12/115 | 查找與排序?qū)嶒灐D的基本概念及實現(xiàn)方法 |
| 第十一周 | 436/7807 | 3/49 | 17/132 | 圖的遍歷方法、最短路徑等問題、大致了解哈希方法 |
-
計劃學(xué)習(xí)時間:20小時
-
實際學(xué)習(xí)時間:17小時
-
有效學(xué)習(xí)時間:4小時
-
改進(jìn)情況:本周學(xué)習(xí)時間有增加,對于團(tuán)隊項目中一些工具的用途還需多了解一些,以便更好地組織團(tuán)隊完成任務(wù)。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號