
Spark編程模型(核心篇 一)
目錄
- RDD概述
- RDD實現(xiàn)
- RDD運行流程
- RDD分區(qū)
- RDD操作分類
- RDD編程接口說明
一、RDD概述
- RDD:是Resilient distributed datasets的簡稱,中文為彈性分布式數(shù)據(jù)集;是Spark最核心的模塊和類
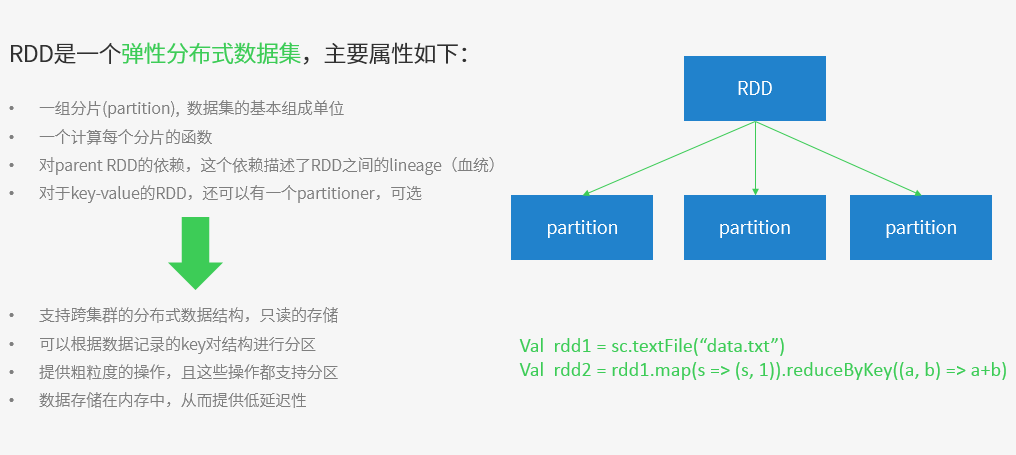
- DAG:
- Spark將計算轉(zhuǎn)換為一個有向無環(huán)圖(DAG)的任務(wù)集合,通過為RDD提供一種基于粗粒度變換(如map, filter, join等)的接口
- RDD類型:ParallelCollectionRDD, MapPartitionsRDD (mappedRDD?), UnionRDD…., ShuffledRDD, SchemaRDD, Results
- RDD操作分類:轉(zhuǎn)換操作(又分為創(chuàng)建操作、轉(zhuǎn)換操作)、行為操作(又分控制操作-進行RDD持久化、行為操作)
二、RDD實現(xiàn)
1、作業(yè)調(diào)度
A、當對RDD執(zhí)行轉(zhuǎn)換操作時,調(diào)度器會根據(jù)RDD的“血統(tǒng)”來構(gòu)建由若干高度階段(Stage)組成的有向無環(huán)圖(DAG), 每個階段包含盡可能多的連續(xù)“窄依賴”轉(zhuǎn)換
B、另外,調(diào)度分配任務(wù)采用“延時調(diào)度”機制,并根據(jù)”數(shù)據(jù)本地性“來確定
寬依賴與窄依賴:
- 窄依賴是指父RDD的每個分區(qū)只被子RDD的一個分區(qū)所使用,子RDD一般對應(yīng)父RDD的一個或者多個分區(qū)。(與數(shù)據(jù)規(guī)模無關(guān))不會產(chǎn)生shuffle
- 寬依賴指父RDD的多個分區(qū)可能被子RDD的一個分區(qū)所使用,子RDD分區(qū)通常對應(yīng)所有的父RDD分區(qū)(與數(shù)據(jù)規(guī)模有關(guān)),會產(chǎn)生shuffle
- 更細化文檔可參見 https://blog.csdn.net/weixin_39043567/article/details/89520896


2、解析器集成:三個步驟 A、用戶每一行輸入編譯成一個類 B、類加載至JVM中 C、調(diào)用 類函數(shù)
3、內(nèi)存管理:
- 提供了3種持久化RDD的存儲策略: A、未序列化Java對象存在內(nèi)存中 B、序列化數(shù)據(jù)存在內(nèi)存中 C、序列化數(shù)據(jù)存儲在磁盤中
- 對內(nèi)存使用LRU回收算法進行管理 (以RDD為單位)
4、檢查點(Checkpoint)支持
- 為RDD提供設(shè)置Checkpoint的API,以將一些Checkpoint保存在外部存儲中
5、多用戶管理:提供公平調(diào)度算法、延遲調(diào)度、作業(yè)取消機制、細粒度資源共享、數(shù)據(jù)本地性
三、RDD運行流程
RDD在Spark中運行大概分為以下三步:
- 創(chuàng)建RDD對象
- DAGScheduler模塊介入運算,計算RDD之間的依賴關(guān)系,RDD之間的依賴關(guān)系就形成了DAG
- 每一個Job被分為多個Stage。劃分Stage的一個主要依據(jù)是當前計算因子的輸入是否是確定的,如果是則將其分在同一個Stage,避免多個Stage之間的消息傳遞開銷
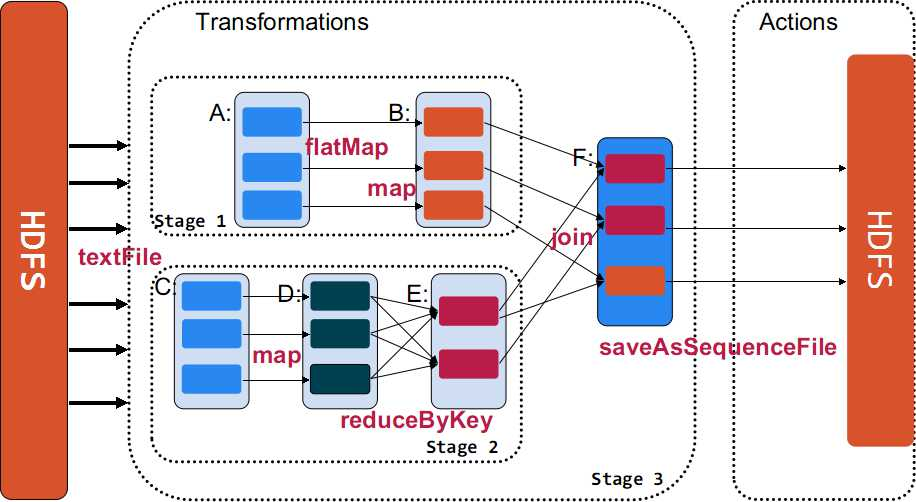
示例圖如下:

- 以下面一個按 A-Z 首字母分類,查找相同首字母下不同姓名總個數(shù)的例子來看一下 RDD 是如何運行起來的

- 創(chuàng)建 RDD 上面的例子除去最后一個 collect 是個動作,不會創(chuàng)建 RDD 之外,前面四個轉(zhuǎn)換都會創(chuàng)建出新的 RDD 。因此第一步就是創(chuàng)建好所有 RDD( 內(nèi)部的五項信息 )?
- 創(chuàng)建執(zhí)行計劃 Spark 會盡可能地管道化,并基于是否要重新組織數(shù)據(jù)來劃分 階段 (stage) ,例如本例中的 groupBy() 轉(zhuǎn)換就會將整個執(zhí)行計劃劃分成兩階段執(zhí)行。最終會產(chǎn)生一個 DAG(directed acyclic graph ,有向無環(huán)圖 ) 作為邏輯執(zhí)行計劃
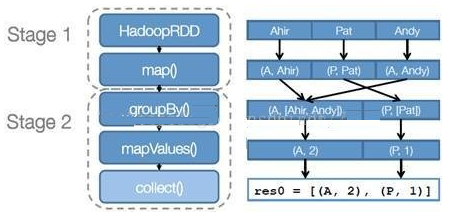
- 調(diào)度任務(wù) 將各階段劃分成不同的 任務(wù) (task) ,每個任務(wù)都是數(shù)據(jù)和計算的合體。在進行下一階段前,當前階段的所有任務(wù)都要執(zhí)行完成。因為下一階段的第一個轉(zhuǎn)換一定是重新組織數(shù)據(jù)的,所以必須等當前階段所有結(jié)果數(shù)據(jù)都計算出來了才能繼續(xù)
三、RDD分區(qū)
1、RDD分區(qū)計算
2、RDD分區(qū)函數(shù),以及默認提供兩種劃分器:哈希分區(qū)劃分器和范圍分區(qū)劃分器
四、RDD操作函數(shù)
Spark轉(zhuǎn)換操作函數(shù)講解: http://www.rzrgm.cn/jinggangshan/p/8086492.html
https://blog.csdn.net/taokeblog/article/details/103796987
行動操作函數(shù)講解:
五、RDD編程接口說明
Spark提供了通用接口來抽象每個RDD,包括
1、分區(qū)信息:數(shù)據(jù)集的最小分片
2、依賴關(guān)系
3、函數(shù)
4、劃分策略和數(shù)據(jù)位置的元數(shù)據(jù)
posted on 2020-01-08 13:40 心有多大,世界就有多大 閱讀(299) 評論(0) 收藏 舉報


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號