
sparkJavaApi逐個詳解
說明:掌握spark的一個關鍵,就是要深刻理解掌握RDD各個函數的使用場景,這樣我們在寫業務邏輯的時候就知道在什么時候用什么樣的函數去實現,得心應手,本文將逐步收集整理各種函數原理及示例代碼,持續更新,方便大家學習掌握。
函數列表:
1、join的使用
2、cogroup的使用
3、GroupByKey的使用
4、map的使用
5、flatmap的使用
6、mapPartitions的使用
7、mapPartitionsWithIndex的使用
8、sortBy的使用
9、takeOrdered的使用
10、takeSample的使用
11、distinct的使用
12、cartesian的使用
13、fold的使用
14、countByKey的使用
15、reduce的使用
16、aggregate的使用
17、aggregateByKey的使用
18、foreach的使用
19、foreachPartition的使用
20、lookup的使用
21、saveAsTextFile的使用
22、saveAsObjectFile的使用
23、treeAggregate的使用
24、treeReduce的使用
1、join的使用
官方文檔描述:
Return an RDD containing all pairs of elements with matching keys in `this` and `other`.
Each* pair of elements will be returned as a (k, (v1, v2)) tuple,
where (k, v1) is in `this` and* (k, v2) is in `other`.
Performs a hash join across the cluster.
函數原型:
def join[W](other: JavaPairRDD[K, W]): JavaPairRDD[K, (V, W)]
def join[W](other: JavaPairRDD[K, W], numPartitions: Int): JavaPairRDD[K, (V, W)]
def join[W](other: JavaPairRDD[K, W], partitioner: Partitioner): JavaPairRDD[K, (V, W)]將一組數據轉化為RDD后,分別創造出兩個PairRDD,然后再對兩個PairRDD進行歸約(即合并相同Key對應的Value),過程如下圖所示:
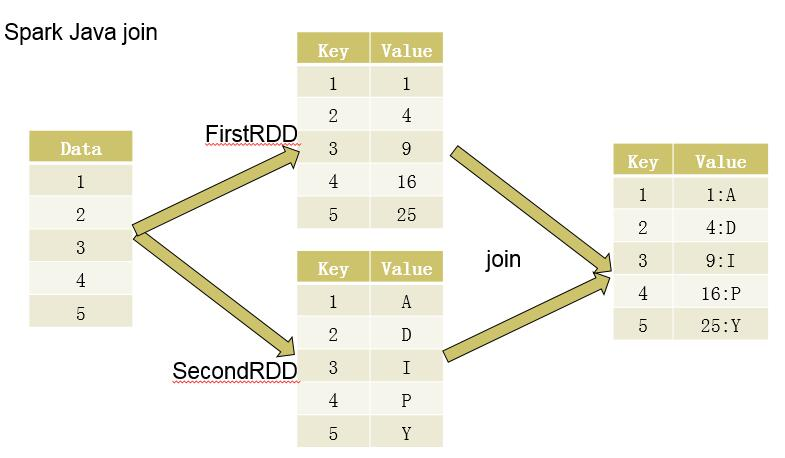
代碼實現如下:
public class SparkRDDDemo {
public static void main(String[] args){
SparkConf conf = new SparkConf().setAppName("SparkRDD").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> data = Arrays.asList(1,2,3,4,5);
JavaRDD<Integer> rdd = sc.parallelize(data);
//FirstRDD
JavaPairRDD<Integer, Integer> firstRDD = rdd.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer num) throws Exception {
return new Tuple2<>(num, num * num);
}
});
//SecondRDD
JavaPairRDD<Integer, String> secondRDD = rdd.mapToPair(new PairFunction<Integer, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Integer num) throws Exception {
return new Tuple2<>(num, String.valueOf((char)(64 + num * num)));
}
});
JavaPairRDD<Integer, Tuple2<Integer, String>> joinRDD = firstRDD.join(secondRDD);
JavaRDD<String> res = joinRDD.map(new Function<Tuple2<Integer, Tuple2<Integer, String>>, String>() {
@Override
public String call(Tuple2<Integer, Tuple2<Integer, String>> integerTuple2Tuple2) throws Exception {
int key = integerTuple2Tuple2._1();
int value1 = integerTuple2Tuple2._2()._1();
String value2 = integerTuple2Tuple2._2()._2();
return "<" + key + ",<" + value1 + "," + value2 + ">>";
}
});
List<String> resList = res.collect();
for(String str : resList)
System.out.println(str);
sc.stop();
}
}
補充1
join就是把兩個集合根據key,進行內容聚合;
A join B的結果:(1,("Spark",100)),(3,("hadoop",65)),(2,("Tachyon",95))
源碼分析:
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = self.withScope {
this.cogroup(other, partitioner).flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w)
)
}
**
從源碼中可以看出,join() 將兩個 RDD[(K, V)] 按照 SQL 中的 join 方式聚合在一起。與 intersection() 類似,首先進行 cogroup(), 得到 <K, (Iterable[V1], Iterable[V2])> 類型的 MappedValuesRDD,然后對 Iterable[V1] 和 Iterable[V2] 做笛卡爾集,并將集合 flat() 化。
**
實例:
1 List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7); 2 final Random random = new Random(); 3 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); 4 JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() { 5 @Override 6 public Tuple2<Integer, Integer> call(Integer integer) throws Exception { 7 return new Tuple2<Integer, Integer>(integer,random.nextInt(10)); 8 } 9 }); 10 11 JavaPairRDD<Integer,Tuple2<Integer,Integer>> joinRDD = javaPairRDD.join(javaPairRDD); 12 System.out.println(joinRDD.collect()); 13 14 JavaPairRDD<Integer,Tuple2<Integer,Integer>> joinRDD2 = javaPairRDD.join(javaPairRDD,2); 15 System.out.println(joinRDD2.collect()); 16 17 JavaPairRDD<Integer,Tuple2<Integer,Integer>> joinRDD3 = javaPairRDD.join(javaPairRDD, new Partitioner() { 18 @Override 19 public int numPartitions() { 20 return 2; 21 } 22 @Override 23 public int getPartition(Object key) { 24 return (key.toString()).hashCode()%numPartitions(); 25 } 26 }); 27 System.out.println(joinRDD3.collect());
2.cogroup的使用
然后對B組集合中key相同的value進行聚合,之后對A組與B組進行"join"操作;
示例代碼:
1 public class CoGroup { 2 3 public static void main(String[] args) { 4 SparkConf conf=new SparkConf().setAppName("spark WordCount!").setMaster("local"); 5 JavaSparkContext sContext=new JavaSparkContext(conf); 6 List<Tuple2<Integer,String>> namesList=Arrays.asList( 7 new Tuple2<Integer, String>(1,"Spark"), 8 new Tuple2<Integer, String>(3,"Tachyon"), 9 new Tuple2<Integer, String>(4,"Sqoop"), 10 new Tuple2<Integer, String>(2,"Hadoop"), 11 new Tuple2<Integer, String>(2,"Hadoop2") 12 ); 13 14 List<Tuple2<Integer,Integer>> scoresList=Arrays.asList( 15 new Tuple2<Integer, Integer>(1,100), 16 new Tuple2<Integer, Integer>(3,70), 17 new Tuple2<Integer, Integer>(3,77), 18 new Tuple2<Integer, Integer>(2,90), 19 new Tuple2<Integer, Integer>(2,80) 20 ); 21 JavaPairRDD<Integer, String> names=sContext.parallelizePairs(namesList); 22 JavaPairRDD<Integer, Integer> scores=sContext.parallelizePairs(scoresList); 23 /** 24 * <Integer> JavaPairRDD<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> 25 * org.apache.spark.api.java.JavaPairRDD.cogroup(JavaPairRDD<Integer, Integer> other) 26 */ 27 JavaPairRDD<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> nameScores=names.cogroup(scores); 28 29 nameScores.foreach(new VoidFunction<Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>>>() { 30 private static final long serialVersionUID = 1L; 31 int i=1; 32 @Override 33 public void call( 34 Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> t) 35 throws Exception { 36 String string="ID:"+t._1+" , "+"Name:"+t._2._1+" , "+"Score:"+t._2._2; 37 string+=" count:"+i; 38 System.out.println(string); 39 i++; 40 } 41 }); 42 43 sContext.close(); 44 } 45 }
示例結果:
- ID:4 , Name:[Sqoop] , Score:[] count:1
- ID:1 , Name:[Spark] , Score:[100] count:2
- ID:3 , Name:[Tachyon] , Score:[70, 77] count:3
- ID:2 , Name:[Hadoop, Hadoop2] , Score:[90, 80] count:4
官方文檔描述:
For each key k in `this` or `other`, return a resulting RDD that contains a tuple
with the list of values for that key in `this` as well as `other`.1 List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7, 1, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); 3 4 JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() { 5 @Override 6 public Tuple2<Integer, Integer> call(Integer integer) throws Exception { 7 return new Tuple2<Integer, Integer>(integer,1); 8 } 9 }); 10 11 //與 groupByKey() 不同,cogroup() 要 aggregate 兩個或兩個以上的 RDD。 12 JavaPairRDD<Integer,Tuple2<Iterable<Integer>,Iterable<Integer>>> cogroupRDD = javaPairRDD.cogroup(javaPairRDD); 13 System.out.println(cogroupRDD.collect()); 14 15 JavaPairRDD<Integer,Tuple2<Iterable<Integer>,Iterable<Integer>>> cogroupRDD3 = javaPairRDD.cogroup(javaPairRDD, new Partitioner() { 16 @Override 17 public int numPartitions() { 18 return 2; 19 } 20 @Override 21 public int getPartition(Object key) { 22 return (key.toString()).hashCode()%numPartitions(); 23 } 24 }); 25 System.out.println(cogroupRDD3);
3、GroupByKey的使用
感覺reduceByKey只能完成一些滿足交換率,結合律的運算,如果想把某些數據聚合到一些做一些操作,得換groupbykey
比如下面:我想把相同key對應的value收集到一起,完成一些運算(例如拼接字符串,或者去重)
1 public class SparkSample { 2 private static final Pattern SPACE = Pattern.compile(" "); 3 4 public static void main(String args[]) { 5 SparkConf sparkConf = new SparkConf(); 6 sparkConf.setAppName("Spark_GroupByKey_Sample"); 7 sparkConf.setMaster("local"); 8 9 JavaSparkContext context = new JavaSparkContext(sparkConf); 10 11 List<Integer> data = Arrays.asList(1,1,2,2,1); 12 JavaRDD<Integer> distData= context.parallelize(data); 13 14 JavaPairRDD<Integer, Integer> firstRDD = distData.mapToPair(new PairFunction<Integer, Integer, Integer>() { 15 @Override 16 public Tuple2<Integer, Integer> call(Integer integer) throws Exception { 17 return new Tuple2(integer, integer*integer); 18 } 19 }); 20 21 JavaPairRDD<Integer, Iterable<Integer>> secondRDD = firstRDD.groupByKey(); 22 23 List<Tuple2<Integer, String>> reslist = secondRDD.map(new Function<Tuple2<Integer, Iterable<Integer>>, Tuple2<Integer, String>>() { 24 @Override 25 public Tuple2<Integer, String> call(Tuple2<Integer, Iterable<Integer>> integerIterableTuple2) throws Exception { 26 int key = integerIterableTuple2._1(); 27 StringBuffer sb = new StringBuffer(); 28 Iterable<Integer> iter = integerIterableTuple2._2(); 29 for (Integer integer : iter) { 30 sb.append(integer).append(" "); 31 } 32 return new Tuple2(key, sb.toString().trim()); 33 } 34 }).collect(); 35 36 37 for(Tuple2<Integer, String> str : reslist) { 38 System.out.println(str._1() + "\t" + str._2() ); 39 } 40 context.stop(); 41 } 42 }
補充1 引自:http://blog.csdn.net/zongzhiyuan/article/details/49965021
在spark中,我們知道一切的操作都是基于RDD的。在使用中,RDD有一種非常特殊也是非常實用的format——pair RDD,即RDD的每一行是(key, value)的格式。這種格式很像Python的字典類型,便于針對key進行一些處理。
針對pair RDD這樣的特殊形式,spark中定義了許多方便的操作,今天主要介紹一下reduceByKey和groupByKey,因為在接下來講解《在spark中如何實現SQL中的group_concat功能?》時會用到這兩個operations。
首先,看一看spark官網[1]是怎么解釋的:
reduceByKey(func, numPartitions=None)
Merge the values for each key using an associative reduce function. This will also perform the merginglocally on each mapper before sending results to a reducer, similarly to a “combiner” in MapReduce. Output will be hash-partitioned with numPartitions partitions, or the default parallelism level if numPartitions is not specified.
也就是,reduceByKey用于對每個key對應的多個value進行merge操作,最重要的是它能夠在本地先進行merge操作,并且merge操作可以通過函數自定義。
groupByKey(numPartitions=None)
Group the values for each key in the RDD into a single sequence. Hash-partitions the resulting RDD with numPartitions partitions. Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will provide much better performance.
也就是,groupByKey也是對每個key進行操作,但只生成一個sequence。需要特別注意“Note”中的話,它告訴我們:如果需要對sequence進行aggregation操作(注意,groupByKey本身不能自定義操作函數),那么,選擇reduceByKey/aggregateByKey更好。這是因為groupByKey不能自定義函數,我們需要先用groupByKey生成RDD,然后才能對此RDD通過map進行自定義函數操作。
為了更好的理解上面這段話,下面我們使用兩種不同的方式去計算單詞的個數[2]:
- val words = Array("one", "two", "two", "three", "three", "three")
- val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
- val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _)
- val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum))
上面得到的wordCountsWithReduce和wordCountsWithGroup是完全一樣的,但是,它們的內部運算過程是不同的。
(1)當采用reduceByKeyt時,Spark可以在每個分區移動數據之前將待輸出數據與一個共用的key結合。借助下圖可以理解在reduceByKey里究竟發生了什么。 注意在數據對被搬移前同一機器上同樣的key是怎樣被組合的(reduceByKey中的lamdba函數)。然后lamdba函數在每個區上被再次調用來將所有值reduce成一個最終結果。整個過程如下:

(2)當采用groupByKey時,由于它不接收函數,spark只能先將所有的鍵值對(key-value pair)都移動,這樣的后果是集群節點之間的開銷很大,導致傳輸延時。整個過程如下:
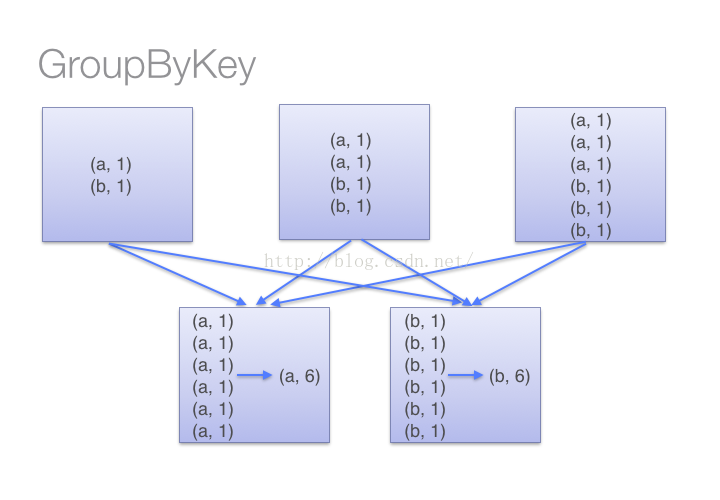
因此,在對大數據進行復雜計算時,reduceByKey優于groupByKey。
另外,如果僅僅是group處理,那么以下函數應該優先于 groupByKey :
(1)、combineByKey 組合數據,但是組合之后的數據類型與輸入時值的類型不一樣。
(2)、foldByKey合并每一個 key 的所有值,在級聯函數和“零值”中使用。
最后,對reduceByKey中的func做一些介紹:
如果是用Python寫的spark,那么有一個庫非常實用:operator[3],其中可以用的函數包括:大小比較函數,邏輯操作函數,數學運算函數,序列操作函數等等。這些函數可以直接通過“from operator import *”進行調用,直接把函數名作為參數傳遞給reduceByKey即可。如下:
- <span style="font-size:14px;">from operator import add
- rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
- sorted(rdd.reduceByKey(add).collect())
- [('a', 2), ('b', 1)]</span>
#################################################################################################################################
官方文檔描述:
Group the values for each key in the RDD into a single sequence. Allows controlling the partitioning of the 從源碼中可以看出groupByKey()是基于combineByKey()實現的, 只是將 Key 相同的 records 聚合在一起,一個簡單的 shuffle 過程就可以完成。ShuffledRDD 中的 compute() 只負責將屬于每個 partition 的數據 fetch 過來,之后使用 mapPartitions() 操作進行 aggregate,生成 MapPartitionsRDD,到這里 groupByKey() 已經結束。最后為了統一返回值接口,將 value 中的 ArrayBuffer[] 數據結構抽象化成 Iterable[]。groupByKey() 沒有在 map 端進行 combine(mapSideCombine = false),這樣設計是因為map 端 combine 只會省掉 partition 里面重復 key 占用的空間;但是,當重復 key 特別多時,可以考慮開啟 combine。
實例:
1 List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); 3 //轉為k,v格式 4 JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() { 5 @Override 6 public Tuple2<Integer, Integer> call(Integer integer) throws Exception { 7 return new Tuple2<Integer, Integer>(integer,1); 8 } 9 }); 10 11 JavaPairRDD<Integer,Iterable<Integer>> groupByKeyRDD = javaPairRDD.groupByKey(2); 12 System.out.println(groupByKeyRDD.collect()); 13 14 //自定義partition 15 JavaPairRDD<Integer,Iterable<Integer>> groupByKeyRDD3 = javaPairRDD.groupByKey(new Partitioner() { 16 //partition各數 17 @Override 18 public int numPartitions() { return 10; } 19 //partition方式 20 @Override 21 public int getPartition(Object o) { 22 return (o.toString()).hashCode()%numPartitions(); 23 } 24 }); 25 System.out.println(groupByKeyRDD3.collect());
4、map的使用
數據集中的每個元素經過用戶自定義的函數轉換形成一個新的RDD,新的RDD叫MappedRDD
5、flatmap的使用
6、mapPartitions的使用
mapPartitions與map類似,但是如果在映射的過程中需要頻繁創建額外的對象,使用mapPartitions要比map高效的過。比如,將RDD中的所有數據通過JDBC連接寫入數據庫,如果使用map函數,可能要為每一個元素都創建一個connection,這樣開銷很大,如果使用mapPartitions,那么只需要針對每一個分區建立一個connection。
兩者的主要區別是調用的粒度不一樣:map的輸入變換函數是應用于RDD中每個元素,而mapPartitions的輸入函數是應用于每個分區。
假設一個rdd有10個元素,分成3個分區。如果使用map方法,map中的輸入函數會被調用10次;而使用mapPartitions方法的話,其輸入函數會只會被調用3次,每個分區調用1次。
函數原型:
def mapPartitions[U](f:FlatMapFunction[java.util.Iterator[T], U]): JavaRDD[U]
def mapPartitions[U](f:FlatMapFunction[java.util.Iterator[T], U],
preservesPartitioning: Boolean): JavaRDD[U]1 List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7); 2 //RDD有兩個分區 3 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,2); 4 //計算每個分區的合計 5 JavaRDD<Integer> mapPartitionsRDD = javaRDD.mapPartitions(new FlatMapFunction<Iterator<Integer>, Integer>() { 6 @Override 7 public Iterable<Integer> call(Iterator<Integer> integerIterator) throws Exception { 8 int isum = 0; 9 while(integerIterator.hasNext()) 10 isum += integerIterator.next(); 11 LinkedList<Integer> linkedList = new LinkedList<Integer>(); 12 linkedList.add(isum); 13 return linkedList; } 14 }); 15 16 System.out.println("mapPartitionsRDD~~~~~~~~~~~~~~~~~~~~~~" + mapPartitionsRDD.collect());
######################################################################################################################################
rdd的mapPartitions是map的一個變種,它們都可進行分區的并行處理。
兩者的主要區別是調用的粒度不一樣:map的輸入變換函數是應用于RDD中每個元素,而mapPartitions的輸入函數是應用于每個分區。
假設一個rdd有10個元素,分成3個分區。如果使用map方法,map中的輸入函數會被調用10次;而使用mapPartitions方法的話,其輸入函數會只會被調用3次,每個分區調用1次。
//生成10個元素3個分區的rdd a,元素值為1~10的整數(1 2 3 4 5 6 7 8 9 10),sc為SparkContext對象
val a = sc.parallelize(1 to 10, 3)
//定義兩個輸入變換函數,它們的作用均是將rdd a中的元素值翻倍
//map的輸入函數,其參數e為rdd元素值
def myfuncPerElement(e:Int):Int = {
println("e="+e)
e*2
}
//mapPartitions的輸入函數。iter是分區中元素的迭代子,返回類型也要是迭代子
def myfuncPerPartition ( iter : Iterator [Int] ) : Iterator [Int] = {
println("run in partition")
var res = for (e <- iter ) yield e*2
res
}
val b = a.map(myfuncPerElement).collect
val c = a.mapPartitions(myfuncPerPartition).collect
在spark shell中運行上述代碼,可看到打印了3次run in partition,打印了10次e=。
從輸入函數(myfuncPerElement、myfuncPerPartition)層面來看,map是推模式,數據被推到myfuncPerElement中;mapPartitons是拉模式,myfuncPerPartition通過迭代子從分區中拉數據。
這兩個方法的另一個區別是在大數據集情況下的資源初始化開銷和批處理處理,如果在myfuncPerPartition和myfuncPerElement中都要初始化一個耗時的資源,然后使用,比如數據庫連接。在上面的例子中,myfuncPerPartition只需初始化3個資源(3個分區每個1次),而myfuncPerElement要初始化10次(10個元素每個1次),顯然在大數據集情況下(數據集中元素個數遠大于分區數),mapPartitons的開銷要小很多,也便于進行批處理操作。
mapPartitionsWithIndex和mapPartitons類似,只是其參數多了個分區索引號。
7、mapPartitionsWithIndex的使用
mapPartitionsWithIndex與mapPartitions基本相同,只是在處理函數的參數是一個二元元組,元組的第一個元素是當前處理的分區的index,元組的第二個元素是當前處理的分區元素組成的Iterator函數原型:
def mapPartitionsWithIndex[R]( f:JFunction2[jl.Integer, java.util.Iterator[T],
java.util.Iterator[R]],
preservesPartitioning: Boolean = false): JavaRDD[R]
源碼分析:
def mapPartitions[U: ClassTag](f:Iterator[T] => Iterator[U],
preservesPartitioning:Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(this, (context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}從源碼中可以看到其實mapPartitions已經獲得了當前處理的分區的index,只是沒有傳入分區處理函數,而mapPartitionsWithIndex將其傳入分區處理函數。
實例:
1 List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7); 2 //RDD有兩個分區 3 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,2); 4 //分區index、元素值、元素編號輸出 5 JavaRDD<String> mapPartitionsWithIndexRDD = javaRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<Integer>, Iterator<String>>() { 6 @Override 7 public Iterator<String> call(Integer v1, Iterator<Integer> v2) throws Exception { 8 LinkedList<String> linkedList = new LinkedList<String>(); 9 int i = 0; 10 while (v2.hasNext()) 11 linkedList.add(Integer.toString(v1) + "|" + v2.next().toString() + Integer.toString(i++)); 12 return linkedList.iterator(); 13 } 14 },false); 15 16 System.out.println("mapPartitionsWithIndexRDD~~~~~~~~~~~~~~~~~~~~~~" + mapPartitionsWithIndexRDD.collect());
8、sortBy的使用
官方文檔描述:
Return this RDD sorted by the given key function.
**
sortBy根據給定的f函數將RDD中的元素進行排序。
**
實例:
1 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data, 3); 3 final Random random = new Random(100); 4 //對RDD進行轉換,每個元素有兩部分組成 5 JavaRDD<String> javaRDD1 = javaRDD.map(new Function<Integer, String>() { 6 @Override 7 public String call(Integer v1) throws Exception { 8 return v1.toString() + "_" + random.nextInt(100); 9 } 10 }); 11 System.out.println(javaRDD1.collect()); 12 //按RDD中每個元素的第二部分進行排序 13 JavaRDD<String> resultRDD = javaRDD1.sortBy(new Function<String, Object>() { 14 @Override 15 public Object call(String v1) throws Exception { 16 return v1.split("_")[1]; 17 } 18 },false,3); 19 System.out.println("result--------------" + resultRDD.collect());
9、takeOrdered的使用
官方文檔描述:
Returns the first k (smallest) elements from this RDD using the natural ordering for T while maintain the order.
**
takeOrdered函數用于從RDD中,按照默認(升序)或指定排序規則,返回前num個元素。
**
源碼分析:
1 def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope { 2 if (num == 0) { 3 Array.empty 4 } else { 5 val mapRDDs = mapPartitions { items => 6 // Priority keeps the largest elements, so let's reverse the ordering. 7 val queue = new BoundedPriorityQueue[T](num)(ord.reverse) 8 queue ++= util.collection.Utils.takeOrdered(items, num)(ord) 9 Iterator.single(queue) 10 } 11 if (mapRDDs.partitions.length == 0) { 12 Array.empty 13 } else { 14 mapRDDs.reduce { (queue1, queue2) => 15 queue1 ++= queue2 16 queue1 17 }.toArray.sorted(ord) 18 } 19 } 20 }
從源碼分析可以看出,利用mapPartitions在每個分區里面進行分區排序,每個分區局部排序只返回num個元素,這里注意返回的mapRDDs的元素是BoundedPriorityQueue優先隊列,再針對mapRDDs進行reduce函數操作,轉化為數組進行全局排序。
1 public static class TakeOrderedComparator implements Serializable,Comparator<Integer>{ 2 @Override 3 public int compare(Integer o1, Integer o2) { 4 return -o1.compareTo(o2); 5 } 6 } 7 List<Integer> data = Arrays.asList(5, 1, 0, 4, 4, 2, 2); 8 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data, 3); 9 System.out.println("takeOrdered-----1-------------" + javaRDD.takeOrdered(2)); 10 List<Integer> list = javaRDD.takeOrdered(2, new TakeOrderedComparator()); 11 System.out.println("takeOrdered----2--------------" + list);
10、takeSample的使用
官方文檔描述:
Return a fixed-size sampled subset of this RDD in an array
**
takeSample函數返回一個數組,在數據集中隨機采樣 num 個元素組成。
**
源碼分析:
1 def takeSample( 2 withReplacement: Boolean, 3 num: Int, 4 seed: Long = Utils.random.nextLong): Array[T] = 5 { 6 val numStDev = 10.0 7 if (num < 0) { 8 throw new IllegalArgumentException("Negative number of elements requested") 9 } else if (num == 0) { 10 return new Array[T](0) 11 } 12 val initialCount = this.count() 13 if (initialCount == 0) { 14 return new Array[T](0) 15 } 16 val maxSampleSize = Int.MaxValue - (numStDev * math.sqrt(Int.MaxValue)).toInt 17 if (num > maxSampleSize) { 18 throw new IllegalArgumentException("Cannot support a sample size > Int.MaxValue - " + s"$numStDev * math.sqrt(Int.MaxValue)") 19 } 20 val rand = new Random(seed) 21 if (!withReplacement && num >= initialCount) { 22 return Utils.randomizeInPlace(this.collect(), rand) 23 } 24 val fraction = SamplingUtils.computeFractionForSampleSize(num, initialCount, withReplacement) 25 var samples = this.sample(withReplacement, fraction, rand.nextInt()).collect() 26 // If the first sample didn't turn out large enough, keep trying to take samples; 27 // this shouldn't happen often because we use a big multiplier for the initial size 28 var numIters = 0 29 while (samples.length < num) { 30 logWarning(s"Needed to re-sample due to insufficient sample size. Repeat #$numIters") 31 samples = this.sample(withReplacement, fraction, rand.nextInt()).collect() 32 numIters += 1 33 } 34 Utils.randomizeInPlace(samples, rand).take(num) 35 }
實例:
1 List<Integer> data = Arrays.asList(5, 1, 0, 4, 4, 2, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data, 3); 3 System.out.println("takeSample-----1-------------" + javaRDD.takeSample(true,2)); 4 System.out.println("takeSample-----2-------------" + javaRDD.takeSample(true,2,100)); 5 //返回20個元素 6 System.out.println("takeSample-----3-------------" + javaRDD.takeSample(true,20,100)); 7 //返回7個元素 8 System.out.println("takeSample-----4-------------" + javaRDD.takeSample(false,20,100));
11、distinct的使用
官方文檔描述:
Return a new RDD containing the distinct elements in this RDD.
函數原型:
def distinct(): JavaRDD[T]
def distinct(numPartitions: Int): JavaRDD[T]
**
第一個函數是基于第二函數實現的,只是numPartitions默認為partitions.length,partitions為parent RDD的分區。
distinct() 功能是 deduplicate RDD 中的所有的重復數據。由于重復數據可能分散在不同的 partition 里面,因此需要 shuffle 來進行 aggregate 后再去重。然而,shuffle 要求數據類型是 <K, V> 。如果原始數據只有 Key(比如例子中 record 只有一個整數),那么需要補充成 <K, null> 。這個補充過程由 map() 操作完成,生成 MappedRDD。然后調用上面的 reduceByKey() 來進行 shuffle,在 map 端進行 combine,然后 reduce 進一步去重,生成 MapPartitionsRDD。最后,將 <K, null> 還原成 K,仍然由 map() 完成,生成 MappedRDD。
**
實例:
1 List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7, 1, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); 3 4 JavaRDD<Integer> distinctRDD1 = javaRDD.distinct(); 5 System.out.println(distinctRDD1.collect()); 6 JavaRDD<Integer> distinctRDD2 = javaRDD.distinct(2); 7 System.out.println(distinctRDD2.collect());
12、cartesian的使用
官方文檔描述:
Return the Cartesian product of this RDD and another one, that is, the RDD of all pairs of
實例:
1 List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); 3 4 JavaPairRDD<Integer,Integer> cartesianRDD = javaRDD.cartesian(javaRDD); 5 System.out.println(cartesianRDD.collect());
13、fold的使用
官方文檔描述:
Aggregate the elements of each partition, and then the results for all the partitions,
using a given associative and commutative function and a neutral "zero value".
The function op(t1, t2) is allowed to modify t1 and return it as its result value
to avoid object allocation; however, it should not modify t2.fold是aggregate的簡化,將aggregate中的seqOp和combOp使用同一個函數op。
從源碼中可以看出,先是將zeroValue賦值給jobResult,然后針對每個分區利用op函數與zeroValue進行計算,再利用op函數將taskResult和jobResult合并計算,
同時更新jobResult,最后,將jobResult的結果返回。
實例:
1 List<String> data = Arrays.asList("5", "1", "1", "3", "6", "2", "2"); 2 JavaRDD<String> javaRDD = javaSparkContext.parallelize(data,5); 3 JavaRDD<String> partitionRDD = javaRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>() { 4 @Override 5 public Iterator<String> call(Integer v1, Iterator<String> v2) throws Exception { 6 LinkedList<String> linkedList = new LinkedList<String>(); 7 while(v2.hasNext()){ 8 linkedList.add(v1 + "=" + v2.next()); 9 } 10 return linkedList.iterator(); 11 } 12 },false); 13 14 System.out.println(partitionRDD.collect()); 15 16 String foldRDD = javaRDD.fold("0", new Function2<String, String, String>() { 17 @Override 18 public String call(String v1, String v2) throws Exception { 19 return v1 + " - " + v2; 20 } 21 }); 22 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + foldRDD);
14、countByKey的使用
官方文檔描述:
源碼分析:
def countByKey(): Map[K, Long] = self.withScope {
self.mapValues(_ => 1L).reduceByKey(_ + _).collect().toMap
}注意,從上述分析可以看出,countByKey操作將數據全部加載到driver端的內存,如果數據量比較大,可能出現OOM。因此,如果key數量比較多,建議進行
rdd.mapValues(_ => 1L).reduceByKey(_ + _),返回RDD[T, Long]。**
實例:
1 List<String> data = Arrays.asList("5", "1", "1", "3", "6", "2", "2"); 2 JavaRDD<String> javaRDD = javaSparkContext.parallelize(data,5); 3 4 JavaRDD<String> partitionRDD = javaRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>() { 5 @Override 6 public Iterator<String> call(Integer v1, Iterator<String> v2) throws Exception { 7 LinkedList<String> linkedList = new LinkedList<String>(); 8 while(v2.hasNext()){ 9 linkedList.add(v1 + "=" + v2.next()); 10 } 11 return linkedList.iterator(); 12 } 13 },false); 14 System.out.println(partitionRDD.collect()); 15 JavaPairRDD<String,String> javaPairRDD = javaRDD.mapToPair(new PairFunction<String, String, String>() { 16 @Override 17 public Tuple2<String, String> call(String s) throws Exception { 18 return new Tuple2<String, String>(s,s); 19 } 20 }); 21 System.out.println(javaPairRDD.countByKey());
15、reduce的使用
官方文檔描述:
Reduces the elements of this RDD using the specified commutative and associative binary operator.
函數原型:
def reduce(f: JFunction2[T, T, T]): T根據映射函數f,對RDD中的元素進行二元計算(滿足交換律和結合律),返回計算結果。
從源碼中可以看出,reduce函數相當于對RDD中的元素進行reduceLeft函數操作,reduceLeft函數是從列表的左邊往右邊應用reduce函數;之后,在driver端對結果進行合并處理,因此,如果分區數量過多或者自定義函數過于復雜,對driver端的負載比較重。
實例:
1 JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf); 2 3 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 4 5 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,3); 6 7 Integer reduceRDD = javaRDD.reduce(new Function2<Integer, Integer, Integer>() { 8 @Override 9 public Integer call(Integer v1, Integer v2) throws Exception { 10 return v1 + v2; 11 } 12 }); 13 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + reduceRDD);
16、aggregate的使用
官方文檔描述:
Aggregate the elements of each partition, and then the results for all the partitions, using given combine functions and a neutral "zero value".
This function can return a different result type, U, than the type of this RDD, T. Thus, we need one operation for merging a T into an U and one operation for merging two U's,
as in scala.TraversableOnce. Both of these functions are allowed to modify and return their first argument instead of creating a new U to avoid memory allocation.
aggregate函數將每個分區里面的元素進行聚合,然后用combine函數將每個分區的結果和初始值(zeroValue)進行combine操作。
這個函數最終返回U的類型不需要和RDD的T中元素類型一致。 這樣,我們需要一個函數將T中元素合并到U中,另一個函數將兩個U進行合并。
其中,參數1是初值元素;參數2是seq函數是與初值進行比較;參數3是comb函數是進行合并 。
注意:如果沒有指定分區,aggregate是計算每個分區的,空值則用初始值替換。
實例:
1 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,3); 3 Integer aggregateValue = javaRDD.aggregate(3, new Function2<Integer, Integer, Integer>() { 4 @Override 5 public Integer call(Integer v1, Integer v2) throws Exception { 6 System.out.println("seq~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + v1 + "," + v2); 7 return Math.max(v1, v2); 8 } 9 }, new Function2<Integer, Integer, Integer>() { 10 int i = 0; 11 @Override 12 public Integer call(Integer v1, Integer v2) throws Exception { 13 System.out.println("comb~~~~~~~~~i~~~~~~~~~~~~~~~~~~~"+i++); 14 System.out.println("comb~~~~~~~~~v1~~~~~~~~~~~~~~~~~~~" + v1); 15 System.out.println("comb~~~~~~~~~v2~~~~~~~~~~~~~~~~~~~" + v2); 16 return v1 + v2; 17 } 18 }); 19 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~"+aggregateValue);
17、aggregateByKey的使用
官方文檔描述:
Aggregate the values of each key, using given combine functions and a neutral "zero value".This function can return a different result type, U
, than the type of the values in this RDD,V.Thus, we need one operation for merging a V into a U and one operation for merging two U's,as in scala.TraversableOnce.
The former operation is used for merging values within a partition, and the latter is used for merging values between partitions. To avoid memory allocation,
both of these functions are allowed to modify and return their first argument instead of creating a new U.aggregateByKey函數對PairRDD中相同Key的值進行聚合操作,在聚合過程中同樣使用了一個中立的初始值。
和aggregate函數類似,aggregateByKey返回值的類型不需要和RDD中value的類型一致。
因為aggregateByKey是對相同Key中的值進行聚合操作,所以aggregateByKey函數最終返回的類型還是Pair RDD,
對應的結果是Key和聚合好的值;而aggregate函數直接是返回非RDD的結果,這點需要注意。在實現過程中,定義了三個aggregateByKey函數原型,
但最終調用的aggregateByKey函數都一致。其中,參數zeroValue代表做比較的初始值;參數partitioner代表分區函數;參數seq代表與初始值比較的函數;參數comb是進行合并的方法。
實例:
1 //將這個測試程序拿文字做一下描述就是:在data數據集中,按key將value進行分組合并, 2 //合并時在seq函數與指定的初始值進行比較,保留大的值;然后在comb中來處理合并的方式。 3 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 4 int numPartitions = 4; 5 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); 6 final Random random = new Random(100); 7 JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() { 8 @Override 9 public Tuple2<Integer, Integer> call(Integer integer) throws Exception { 10 return new Tuple2<Integer, Integer>(integer,random.nextInt(10)); 11 } 12 }); 13 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~"+javaPairRDD.collect()); 14 15 JavaPairRDD<Integer, Integer> aggregateByKeyRDD = javaPairRDD.aggregateByKey(3,numPartitions, new Function2<Integer, Integer, Integer>() { 16 @Override 17 public Integer call(Integer v1, Integer v2) throws Exception { 18 System.out.println("seq~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + v1 + "," + v2); 19 return Math.max(v1, v2); 20 } 21 }, new Function2<Integer, Integer, Integer>() { 22 int i = 0; 23 @Override 24 public Integer call(Integer v1, Integer v2) throws Exception { 25 System.out.println("comb~~~~~~~~~i~~~~~~~~~~~~~~~~~~~" + i++); 26 System.out.println("comb~~~~~~~~~v1~~~~~~~~~~~~~~~~~~~" + v1); 27 System.out.println("comb~~~~~~~~~v2~~~~~~~~~~~~~~~~~~~" + v2); 28 return v1 + v2; 29 } 30 }); 31 System.out.println("aggregateByKeyRDD.partitions().size()~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~"+aggregateByKeyRDD.partitions().size()); 32 System.out.println("aggregateByKeyRDD~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~"+aggregateByKeyRDD.collect());
18、foreach的使用
官方文檔描述:
Applies a function f to all elements of this RDD.
foreach用于遍歷RDD,將函數f應用于每一個元素。
實例:
1 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,3); 3 javaRDD.foreach(new VoidFunction<Integer>() { 4 @Override 5 public void call(Integer integer) throws Exception { 6 System.out.println(integer); 7 } 8 });
19、foreachPartition的使用
官方文檔描述:
Applies a function f to each partition of this RDD.
foreachPartition和foreach類似,只不過是對每一個分區使用f。
實例:
1 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,3); 3 4 //獲得分區ID 5 JavaRDD<String> partitionRDD = javaRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<Integer>, Iterator<String>>() { 6 @Override 7 public Iterator<String> call(Integer v1, Iterator<Integer> v2) throws Exception { 8 LinkedList<String> linkedList = new LinkedList<String>(); 9 while(v2.hasNext()){ 10 linkedList.add(v1 + "=" + v2.next()); 11 } 12 return linkedList.iterator(); 13 } 14 },false); 15 System.out.println(partitionRDD.collect()); 16 javaRDD.foreachPartition(new VoidFunction<Iterator<Integer>>() { 17 @Override 18 public void call(Iterator<Integer> integerIterator) throws Exception { 19 System.out.println("___________begin_______________"); 20 while(integerIterator.hasNext()) 21 System.out.print(integerIterator.next() + " "); 22 System.out.println("\n___________end_________________"); 23 } 24 });
20、lookup的使用
官方文檔描述:
Return the list of values in the RDD for key `key`. This operation is done efficiently if the RDD has a known partitioner by only searching the partition that the key maps to.
lookup用于(K,V)類型的RDD,指定K值,返回RDD中該K對應的所有V值。
從源碼中可以看出,如果partitioner不為空,計算key得到對應的partition,在從該partition中獲得key對應的所有value;
如果partitioner為空,則通過filter過濾掉其他不等于key的值,然后將其value輸出。
實例:
1 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data, 3); 3 JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() { 4 int i = 0; 5 @Override 6 public Tuple2<Integer, Integer> call(Integer integer) throws Exception { 7 i++; 8 return new Tuple2<Integer, Integer>(integer,i + integer); 9 } 10 }); 11 System.out.println(javaPairRDD.collect()); 12 System.out.println("lookup------------" + javaPairRDD.lookup(4));
21、saveAsTextFile的使用
官方文檔描述:
Save this RDD as a text file, using string representations of elements.
saveAsTextFile用于將RDD以文本文件的格式存儲到文件系統中。
從源碼中可以看到,saveAsTextFile函數是依賴于saveAsHadoopFile函數,由于saveAsHadoopFile函數接受PairRDD,
所以在saveAsTextFile函數中利用rddToPairRDDFunctions函數轉化為(NullWritable,Text)類型的RDD,然后通過saveAsHadoopFile函數實現相應的寫操作。
實例:
1 實例: 2 3 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 4 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,5); 5 javaRDD.saveAsTextFile("/user/tmp");
22、saveAsObjectFile的使用
官方文檔描述:
Save this RDD as a SequenceFile of serialized objects.
saveAsObjectFile用于將RDD中的元素序列化成對象,存儲到文件中。
從源碼中可以看出,saveAsObjectFile函數是依賴于saveAsSequenceFile函數實現的,將RDD轉化為類型為
實例:
1 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,5); 3 javaRDD.saveAsObjectFile("/user/tmp");
23、treeAggregate的使用
官方文檔描述:
Aggregates the elements of this RDD in a multi-level tree pattern.
可理解為更復雜的多階aggregate。
從源碼中可以看出,treeAggregate函數先是對每個分區利用scala的aggregate函數進行局部聚合的操作;同時,依據depth參數計算scale,
如果當分區數量過多時,則按i%curNumPartitions進行key值計算,再按key進行重新分區合并計算;最后,在進行reduce聚合操作。這樣可以通過調解深度來減少reduce的開銷。
實例:
1 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,3); 3 //轉化操作 4 JavaRDD<String> javaRDD1 = javaRDD.map(new Function<Integer, String>() { 5 @Override 6 public String call(Integer v1) throws Exception { 7 return Integer.toString(v1); 8 } 9 }); 10 11 String result1 = javaRDD1.treeAggregate("0", new Function2<String, String, String>() { 12 @Override 13 public String call(String v1, String v2) throws Exception { 14 System.out.println(v1 + "=seq=" + v2); 15 return v1 + "=seq=" + v2; 16 } 17 }, new Function2<String, String, String>() { 18 @Override 19 public String call(String v1, String v2) throws Exception { 20 System.out.println(v1 + "<=comb=>" + v2); 21 return v1 + "<=comb=>" + v2; 22 } 23 }); 24 System.out.println(result1);
24、treeReduce的使用
官方文檔描述:
Reduces the elements of this RDD in a multi-level tree pattern.
與treeAggregate類似,只不過是seqOp和combOp相同的treeAggregate。
從源碼中可以看出,treeReduce函數先是針對每個分區利用scala的reduceLeft函數進行計算;最后,在將局部合并的RDD進行treeAggregate計算,這里的seqOp和combOp一樣,初值為空。在實際應用中,可以用treeReduce來代替reduce,
主要是用于單個reduce操作開銷比較大,而treeReduce可以通過調整深度來控制每次reduce的規模。
實例:
1 List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,5); 3 JavaRDD<String> javaRDD1 = javaRDD.map(new Function<Integer, String>() { 4 @Override 5 public String call(Integer v1) throws Exception { 6 return Integer.toString(v1); 7 } 8 }); 9 String result = javaRDD1.treeReduce(new Function2<String, String, String>() { 10 @Override 11 public String call(String v1, String v2) throws Exception { 12 System.out.println(v1 + "=" + v2); 13 return v1 + "=" + v2; 14 } 15 }); 16 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + treeReduceRDD);
25、combineByKey的使用
官方文檔描述:
Generic function to combine the elements for each key using a custom set of aggregation functions. Turns an RDD[(K, V)] into a result of type RDD[(K, C)], for a "combined type" C Note that V and C can be different -- for example, one might group an RDD of type (Int, Int) into an RDD of type (Int, Seq[Int]).
Users provide three functions:
- `createCombiner`, which turns a V into a C (e.g., creates a one-element list)
- `mergeValue`, to merge a V into a C (e.g., adds it to the end of a list)
- `mergeCombiners`, to combine two C's into a single one.
In addition, users can control the partitioning of the output RDD, and whether to perform map-side aggregation (if a mapper can produce multiple items with the same key).
該函數是用于將RDD[k,v]轉化為RDD[k,c],其中類型v和類型c可以相同也可以不同。
其中的參數如下:
- createCombiner:該函數用于將輸入參數RDD[k,v]的類型V轉化為輸出參數RDD[k,c]中類型C;
- mergeValue:合并函數,用于將輸入中的類型C的值和類型V的值進行合并,得到類型C,輸入參數是(C,V),輸出是C;
- mergeCombiners:合并函數,用于將兩個類型C的值合并成一個類型C,輸入參數是(C,C),輸出是C;
- numPartitions:默認HashPartitioner中partition的個數;
- partitioner:分區函數,默認是HashPartitionner;
- mapSideCombine:該函數用于判斷是否需要在map進行combine操作,類似于MapReduce中的combine,默認是 true。
從源碼中可以看出,combineByKey()的實現是一邊進行aggregate,一邊進行compute() 的基礎操作。假設一組具有相同 K 的 <K, V> records 正在一個個流向 combineByKey(),createCombiner 將第一個 record 的 value 初始化為 c (比如,c = value),然后從第二個 record 開始,來一個 record 就使用 mergeValue(c, record.value) 來更新 c,比如想要對這些 records 的所有 values 做 sum,那么使用c = c + record.value。等到 records 全部被 mergeValue(),得到結果 c。假設還有一組 records(key 與前面那組的 key 均相同)一個個到來,combineByKey() 使用前面的方法不斷計算得到 c’。現在如果要求這兩組 records 總的 combineByKey() 后的結果,那么可以使用 final c = mergeCombiners(c, c') 來計算;然后依據partitioner進行不同分區合并。
實例:
1 List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7, 1, 2); 2 JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); 3 //轉化為pairRDD 4 JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() { 5 @Override 6 public Tuple2<Integer, Integer> call(Integer integer) throws Exception { 7 return new Tuple2<Integer, Integer>(integer,1); 8 } 9 }); 10 11 JavaPairRDD<Integer,String> combineByKeyRDD = javaPairRDD.combineByKey(new Function<Integer, String>() { 12 @Override 13 public String call(Integer v1) throws Exception { 14 return v1 + " :createCombiner: "; 15 } 16 }, new Function2<String, Integer, String>() { 17 @Override 18 public String call(String v1, Integer v2) throws Exception { 19 return v1 + " :mergeValue: " + v2; 20 } 21 }, new Function2<String, String, String>() { 22 @Override 23 public String call(String v1, String v2) throws Exception { 24 return v1 + " :mergeCombiners: " + v2; 25 } 26 }); 27 System.out.println("result~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + combineByKeyRDD.collect());

 浙公網安備 33010602011771號
浙公網安備 33010602011771號