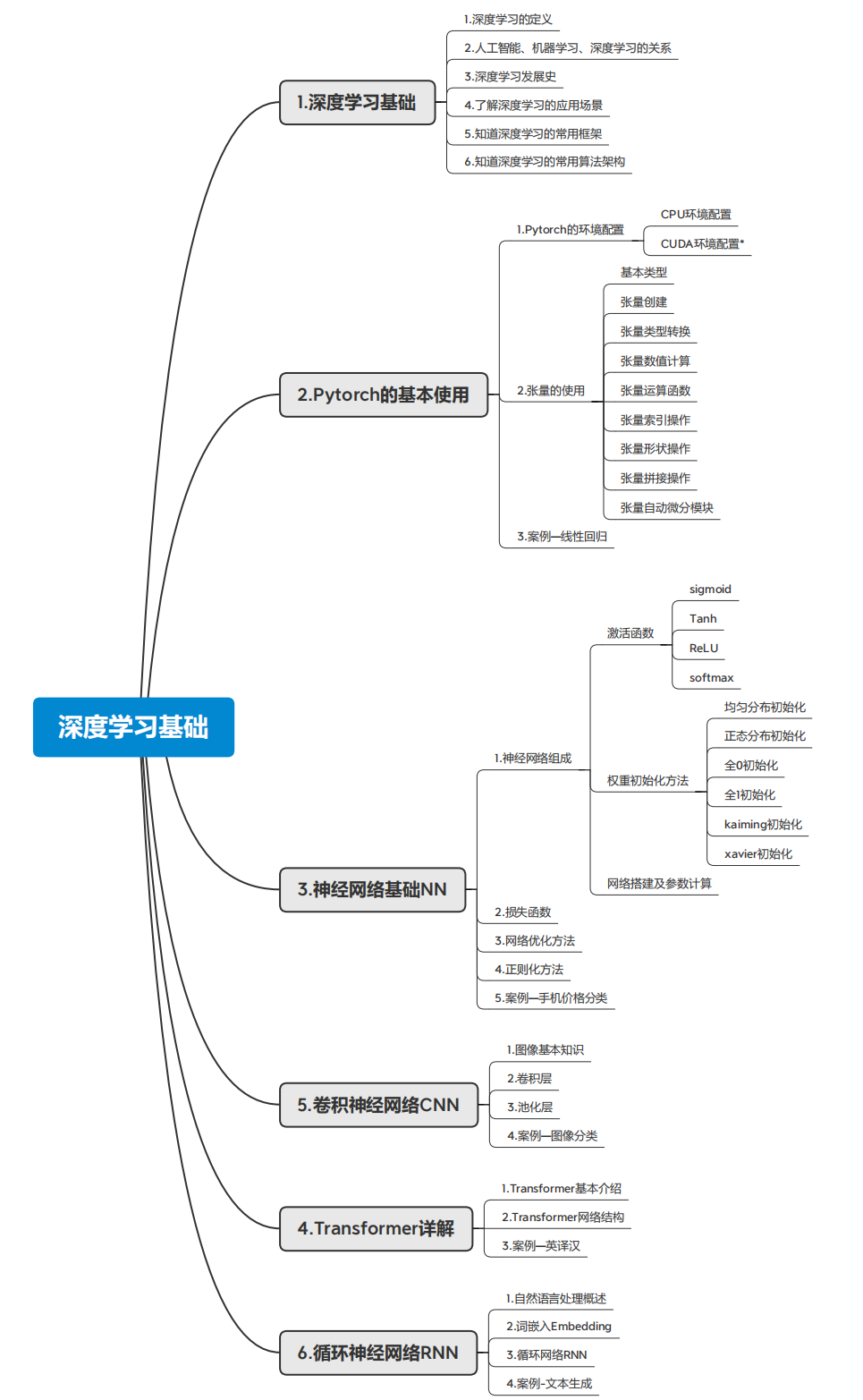
一、什么是深度學習
1.人工智能(AI, Artificial Intelligence)
這是最廣泛的概念,指的是使機器能夠模擬人類智能行為的技術和研究領域。AI包括理解語言(NLP、循環神經網絡)、識別圖像(卷積神經網絡CNN,CV即計算機視覺Computer Vision)、解決問題等各種能力。
2.機器學習(ML, Machine Learning)
機器學習是實現人工智能的一種方法。它涉及到算法和統計模型的使用,使得計算機系統能夠從數據中“學習”和改進任務的執行,而不是通過明確的編程來實現。機器學習包括多種技術,如線性回歸、支持向量機(SVM)、決策樹等。
3.深度學習(DL, Deep Learning)
深度學習是機器學習中的一種特殊方法,它使用稱為神經網絡NN的復雜結構,特別是“深層”的神經網絡,來學習和做出預測。深度學習特別適合處理大規模和高維度的數據,如圖像、聲音和文本。
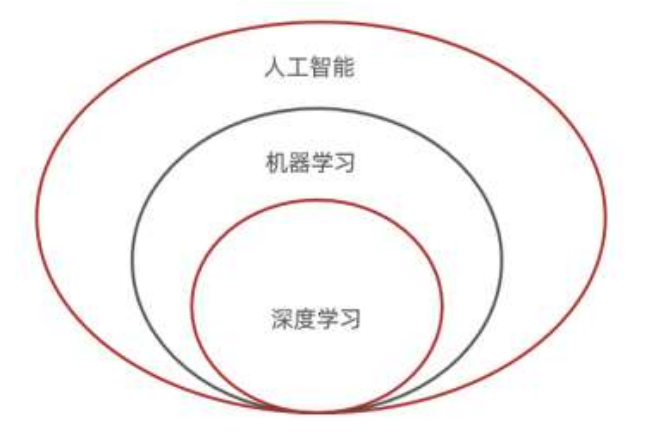
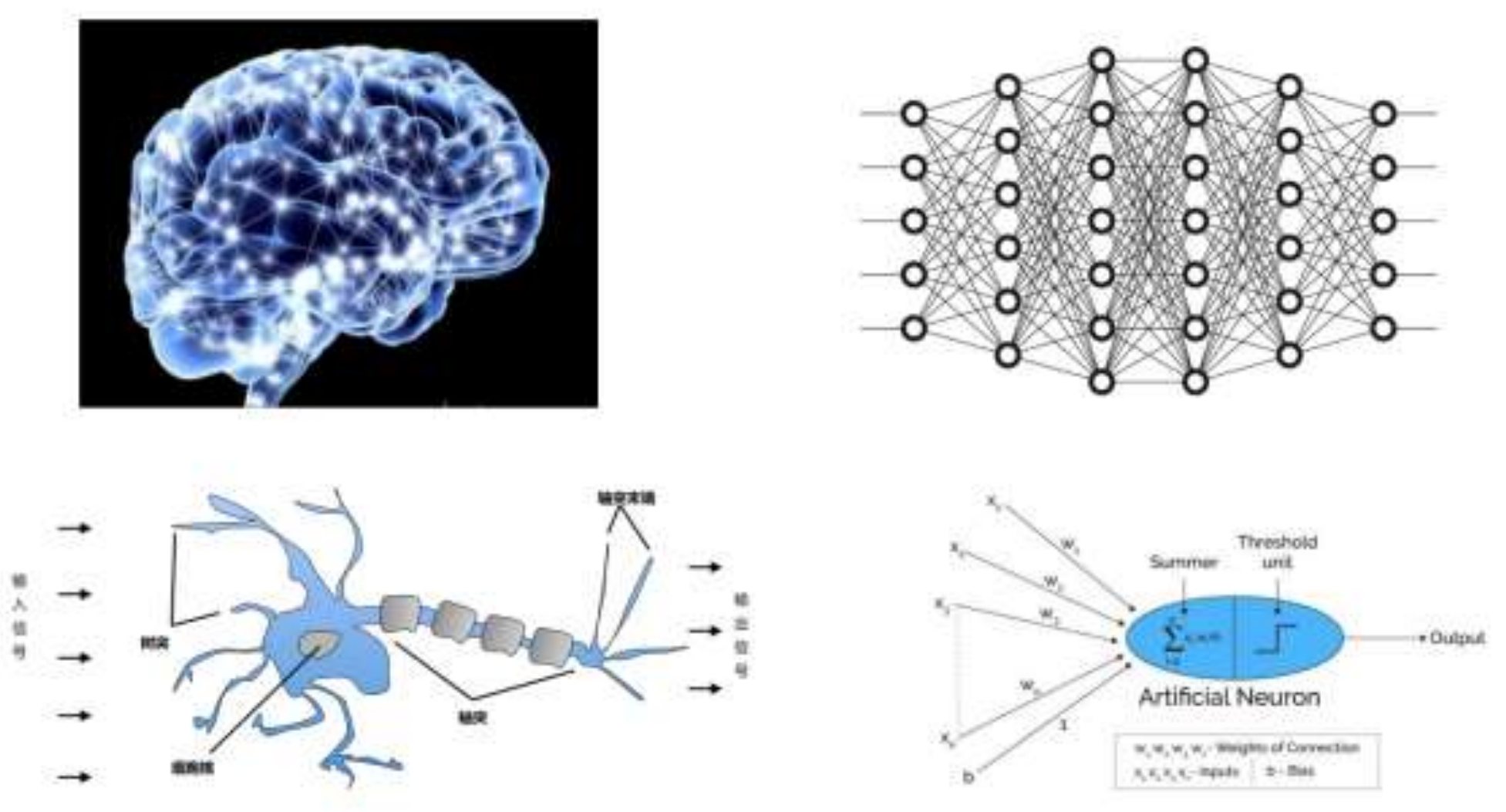
Threshold (Unit step activation function) 激活函數,非線性的激活函數
? 傳統機器學習算術依賴人工設計特征,并進行特征提取,而深度學習方法不需要人工,而是依賴算法自動提取特征。
? 深度學習模仿人類大腦的運行方式,從經驗中學習獲取知識。這也是深度學習被看做黑盒子,可解釋性差的原因。
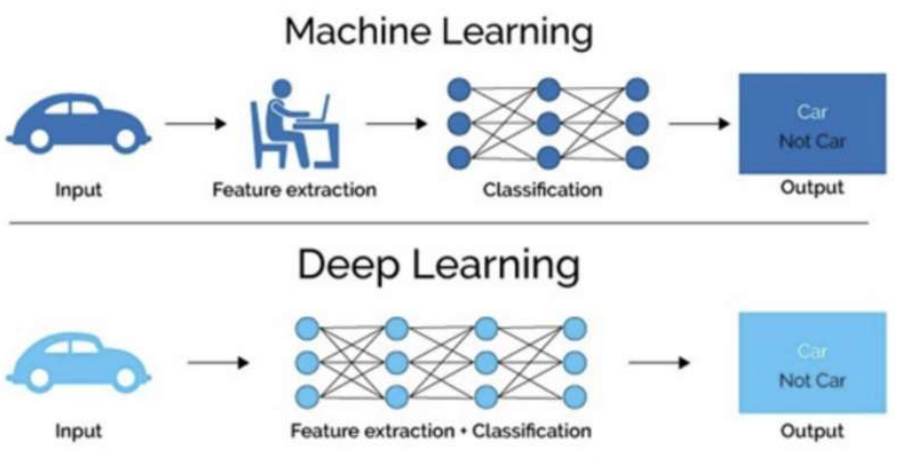
? 所有深度學習都是機器學習,但并非所有機器學習都是深度學習。深度學習的崛起源于其在處理特定類型的大數據問題上的卓越能力,尤其是那些傳統機器學習算法難以處理的復雜問題。然而,對于某些任務和數據集,更簡單的機器學習方法可能更加有效和適合。
? 在深度學習的過程中,每一層神經網絡都對輸入數據進行處理,從而學習到數據中的特征和模式。例如,在圖像識別任務中,第一層可能會識別邊緣,第二層可能會識別形狀,更深的層則可能識別復雜的對象特征,如面孔。這些層通過大量數據的訓練,逐漸優化它們的參數,從而提高模型的識別或預測能力。
? 深度學習的關鍵之一是“反向傳播”(BP,back propogation)算法,它通過計算損失函數(即實際輸出與期望輸出之間的差異)并將這種誤差反饋回網絡的每一層,來調整每層的權重。這種方法使得網絡能夠從錯誤中學習并不斷改進。
? 深度學習的一個重要的概念是“特征學習”,這意味著深度學習模型能夠自動發現和利用數據中的有用特征,而無需人工介入。這與傳統的機器學習方法不同,后者通常需要專家提前定義和選擇特征。
? 深度學習的成功依賴于大量的數據和強大的計算能力。隨著數據量的增長和計算技術的發展,深度學習模型在圖像和語音識別、自然語言處理、游戲、醫療診斷等多個領域取得了顯著成就。它通過提供更精確和復雜的數據處理能力,推動了人工智能技術的飛速發展。然而,這種技術也面臨挑戰,如需求大量的訓練數據,模型的復雜性和不透明性,以及對計算資源的高需求。盡管如此,深度學習仍然是當今最激動人心的技術前沿之一,其應用潛力巨大。
深度學習優缺點
1.優點
? 精度高,性能優于其他的機器學習算法,甚至在某些領域超過了人類
? 隨之計算機硬件的發展,可以近似(即擬合)任意的非線性函數
? 近年來在學界和業界受到了熱捧,有大量的框架(如pyTorch)和庫可供調。
2.缺點
? 黑箱,很難解釋模型是怎么工作的
? 訓練時間長,需要大量的計算資源(GPU)
? 網絡結構復雜,需要調整超參數多
? 部分數據集上表現不佳,容易發生過擬合
二、應用領域和發展史
1、應用場景
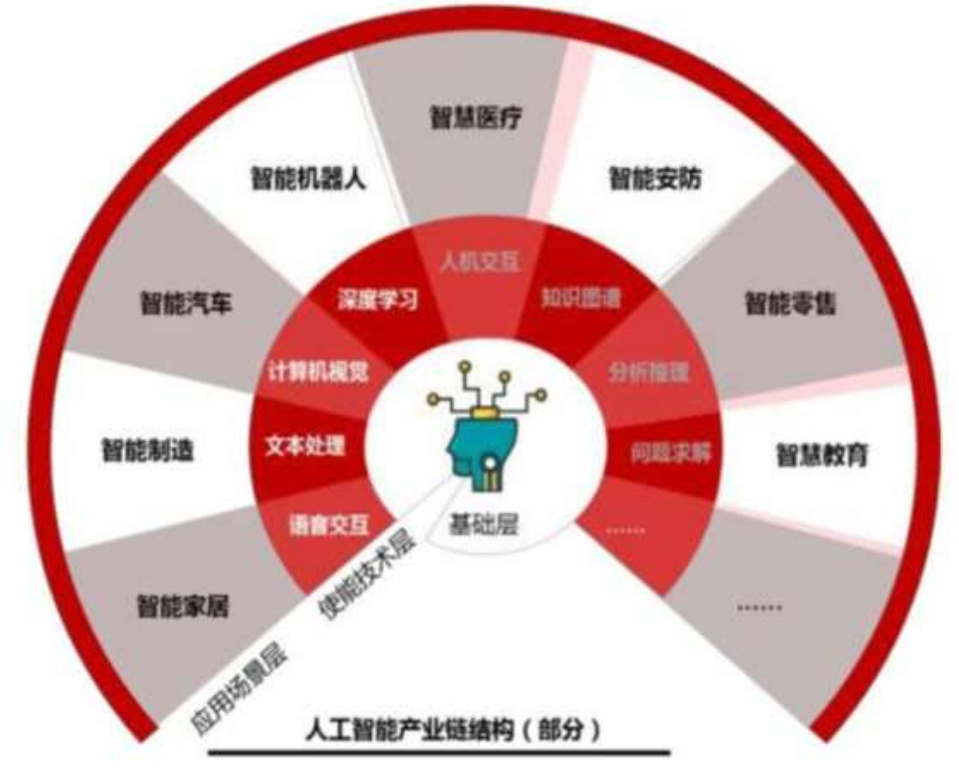
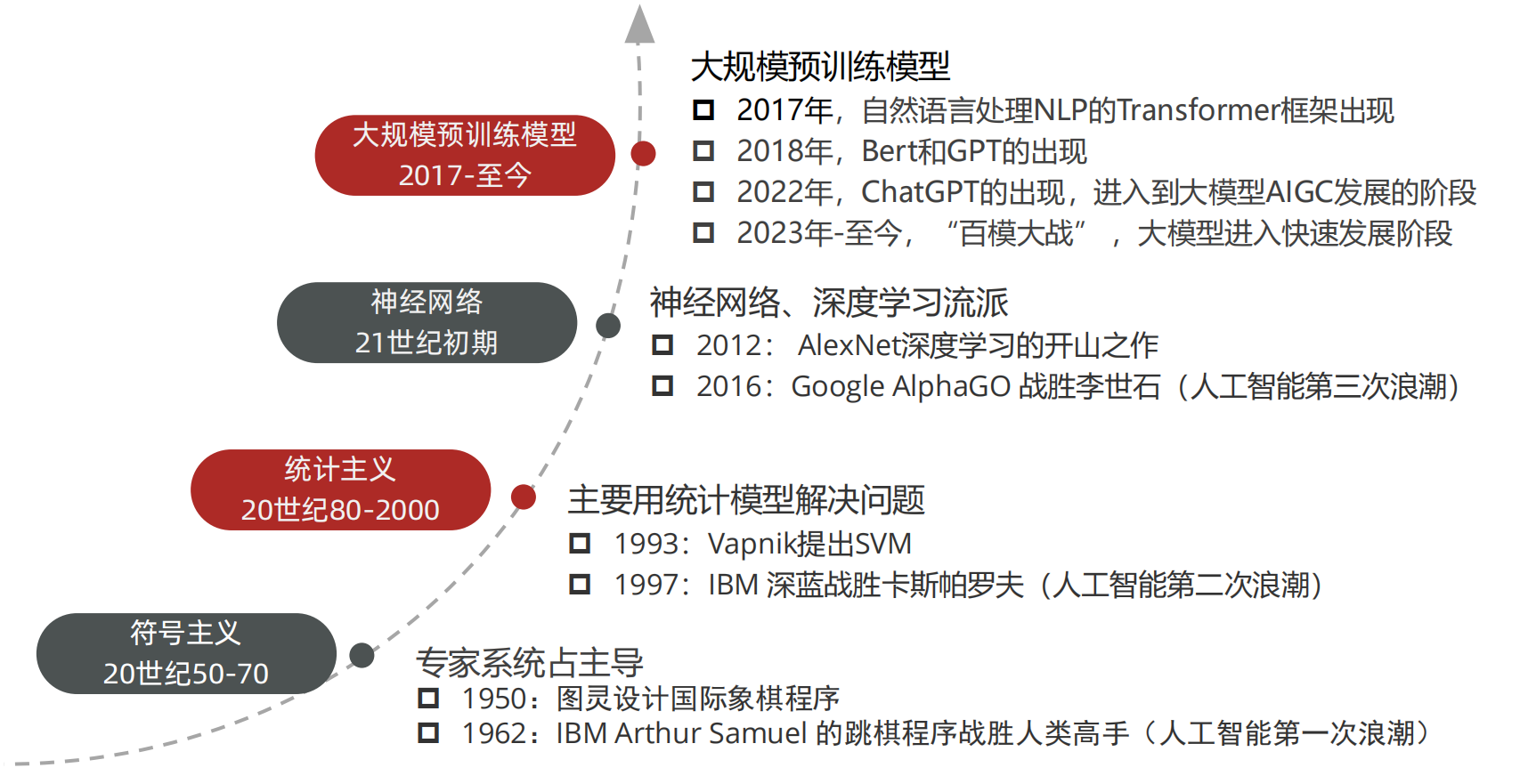
2、發展史
3、AI發展三要素
數據、算法、算力三要素相互作用,是未來AI發展的基石
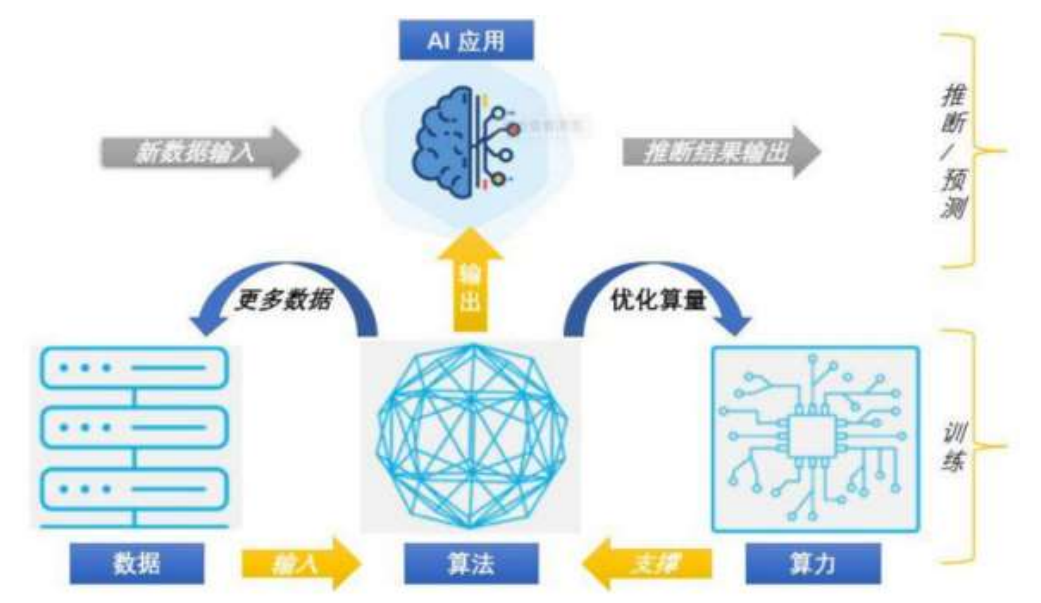
1 數據:AI模型的‘汽油’
2 算法:AI模型的‘大腦’
3 算力:AI模型的‘發動機’
1 CPU:負責調度任務、計算任務等;主要適合I/O密集型的任務
2 GPU:更加適合矩陣運算;主要適合計算密集型任務
3 TPU:Tensor,專門針對神經網絡訓練設計一款處理器
三、深度學習使用場景
(1)圖像識別和處理
? 物體檢測:從圖片中識別和定位不同的物體。
? 面部識別:用于安全系統和個性化服務。
? 醫學影像分析:識別疾病標志,如癌癥篩查中的腫瘤檢測。
(2)自然語言處理(NLP)
? 機器翻譯:如谷歌翻譯等工具。
? 語音識別:用于語音助手和自動語音轉文字服務。
? 文本生成:自動撰寫新聞稿、生成創意內容等。
(3)音頻處理
? 音樂生成:創造新的音樂作品。
? 語音合成:如智能助手中的自然語音反饋。
(4)視頻分析
? 行為分析:在安全監控中分析人類行為。
? 實時視頻處理:用于增強現實和虛擬現實應用。
(5)游戲和仿真
? AI對戰:在復雜的游戲中模擬人類玩家。
? 環境模擬:創建逼真的虛擬環境和情境。
(6)自動駕駛汽車
? 環境感知:理解和解釋周圍環境。
? 決策制定:自動駕駛過程中的安全決策。
(7)推薦系統
? 個性化推薦:在電子商務、社交媒體和娛樂平臺中推薦產品或內容。
(8)金融領域
? 風險評估:信貸評分和投資風險分析。
? 欺詐檢測:識別異常交易行為。
(9)醫療領域
? 藥物發現:加速新藥物的研發。
? 疾病預測和分析:基于患者數據預測疾病風險。
四、流行深度學習框架
1.TensorFlow
TensorFlow是Google開發的一款開源軟件庫,專為深度學習或人工神經網絡而設計。TensorFlow允許你可以使用流程圖創建神經網絡和計算模型。它是可用于深度學習的最好維護和最為流行的開源庫之一。TensorFlow框架可以使用C++也可以使用Python。你可以使用TensorBoard進行簡單的可視化并查看計算流水線。其靈活的架構允許你輕松部署在不同類型的設備上。不利的一面是,TensorFlow沒有符號循環,不支持分布式學習。此外,它還不支持Windows。
? 出生地:Google
? 特點:計算圖、分布式訓練效果強、底層C構建速度快,生態強大
? 主要調包語言:Python、C/C++、JS
? 評價:對標Pytorch、學術界沒市場了、部署更加的方便
? 入門推薦:建議做工程的小伙伴入門
2.Pytorch
Pytorch是Meta(前Facebook)的框架,前身是Torch,支持動態圖,而且提供了Python接口。是一個以Python優先的深度學習框架,不僅能夠實現強大的GPU加速,同時還支持動態神經網絡。Python是現在學術界的霸主,對于想要做學術的同學絕對首推(重點)。
? 出生地:FaceBook
? 特點:生態強大、入門爽歪歪、代碼量少(重點)
? 主要調包語言:Python、C/C++
? 評價:入門很快、速度有點慢、部署很垃圾、學術界的霸主
? 入門推薦:想要做學術的同學絕對首選,幾乎現在頂會論文的代碼都是這個框架寫的。
3.PaddlePaddle
百度推出的深度學習框架,算是國人最火的深度學習框架了。更新了2.0的高級API與動態圖后,Paddle更加的強大。百度有很多PaddlePaddle的教程,對于初學者來說還是相當不錯的。PaddlePaddle有很多便捷的工具,比如Detection、CV、NLP、GAN的工具包,也有專門的可視化工具(遠離Tensorboard的支配)。
? 出生地:百度
? 特點:計算圖動態圖都支持、有高級API、速度快、部署方便、有專門的平臺
? 主要調包語言:Python、C/C++、JS
? 入門推薦:如果沒有卡那就非常適合,如果算力不缺,建議先看看Pytorch,當然也可以PaddlePaddle。
4.ONNX(萬能轉換)
ONNX是一種針對機器學習所設計的開放式的文件格式,用于存儲訓練好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存儲模型數據并交互。用大白話說就是是一個中間件,比如你Pytorch的模型想轉換別的,就得通過ONNX,現在有的框架可以直接轉,但是在沒有專門支持的時候,ONNX就非常重要了,萬物先轉ONNX,ONNX再轉萬物。ONNX本身也有自己的模型庫以及很多開源的算子,所以用起來門檻不是那么高。
? 出生地:有點多,很多大廠一起整的
? 特點:萬能轉換
? 主要調包語言:Python、C/C++
? 入門推薦:不用刻意學習,用到了再看。
五、主流算法模型
1.卷積神經網絡(CNN)--做圖像
? 適用于圖像識別、視頻分析、醫學影像等。
? 特別擅長處理帶有空間關系的數據。
2.循環神經網絡(RNN)及其變體(如LSTM、GRU)--做文本
? 適用于時間序列數據處理,如語音識別、音樂生成、自然語言處理。
? 能夠處理序列數據中的時間動態性。
3.Transformer架構--做生成任務
? 引領自然語言處理的新浪潮,如BERT、GPT系列。
? 適用于復雜的語言理解和生成任務。
4.自編碼器(Autoencoders):
? 用于數據降維、去噪、特征學習等。
? 在異常檢測和數據生成中也有應用。
5.生成對抗網絡(GANs):
? 用于圖像生成、藝術創作、數據增強等。
? 擅長生成逼真的圖像和視頻。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號