
分布式系統(tǒng)架構理論與組件
1.分布式系統(tǒng)的發(fā)展
在計算機發(fā)展的早期,一直都是集中式計算,計算能力依賴大型計算機。隨著互聯(lián)網(wǎng)的發(fā)展,繁重的業(yè)務需要巨大的計算能力才能完成,而集中式計算無法滿足要求,大型計算機的價格也非常昂貴。分布式計算將任務分解成更小的部分,分配給多臺計算機處理,這樣可以節(jié)約整體計算時間,大大提高計算效率。
互聯(lián)網(wǎng)大型網(wǎng)站往往面臨高并發(fā)訪問、海量數(shù)據(jù)處理等問題,必須保證系統(tǒng)高可用、易伸縮等等。分布式架構采用多臺機器協(xié)同工作,動態(tài)伸縮容量,使用冗余節(jié)點來消除單點故障,提高系統(tǒng)可用性。
2.分布式系統(tǒng)的挑戰(zhàn)
軟件開發(fā)沒有銀彈,任何系統(tǒng)結構都有利有弊,分布式系統(tǒng)的挑戰(zhàn)有三點:
- 1)網(wǎng)絡資源受限:節(jié)點間采用網(wǎng)絡通信,而網(wǎng)絡存在帶寬限制和延時,任何一個節(jié)點都無法做到瞬間響應和高吞吐量。
- 2)節(jié)點管理成本:分布式系統(tǒng)節(jié)點可能膨脹到成千上萬個,運維節(jié)點的成本非常高。
- 3)缺乏全局時鐘:網(wǎng)絡上計算機時鐘同步的準確性受到極大的限制,沒有一致的全局時間。計算機在空間隨意分布,很難定義不同機器上事件先后發(fā)生順序。
3.分布式系統(tǒng)基本理論
3.1 CAP定理
分布式系統(tǒng)的三個特性Consistency(一致性)、Availability(可用性)、Partition tolerance(分區(qū)容錯性),最多只能同時滿足其中兩個,三者不可兼得。
- Consistency (一致性):數(shù)據(jù)更新后,所有節(jié)點在同一時間的數(shù)據(jù)完全一致。客戶端并發(fā)訪問時,返回的數(shù)據(jù)是一致的。服務端盡快將數(shù)據(jù)復制到整個系統(tǒng),以保證數(shù)據(jù)最終一致。
- Availability (可用性):系統(tǒng)能夠一直為用戶服務,不出現(xiàn)操作失敗或者超時等情況。在單位時間內(nèi)的可用性常用N個9來衡量,比如99.999%的可用性。
- Partition Tolerance (分區(qū)容錯性):分布式系統(tǒng)內(nèi)部由許多節(jié)點構成,外界看上去是一個整體。節(jié)點或網(wǎng)絡分區(qū)遇到故障的時候,仍然能夠?qū)ν馓峁M足一致性或可用性的服務。系統(tǒng)中少量機器宕掉,剩下的機器還能夠正常運轉(zhuǎn),用戶沒有任何感知。
大型互聯(lián)網(wǎng)應用的集群節(jié)點非常多,發(fā)生節(jié)點或者網(wǎng)絡故障是常態(tài)。系統(tǒng)必須要滿足分區(qū)容錯性,最終只能在C和A之間取舍。
傳統(tǒng)行業(yè)項目有所不同,以金融系統(tǒng)為例,涉及到金錢的操作,必須要滿足數(shù)據(jù)一致性。出現(xiàn)網(wǎng)絡故障寧可停止服務,也要保證C,最終只能在A和P之間取舍。
3.2 PACELC理論
CAP理論并不能很好的指導現(xiàn)實的系統(tǒng)架構。比如Availability (可用性),如果接口長時間才返回結果,固然可用,但是業(yè)務上不能接受。大部分情況下,系統(tǒng)分區(qū)都是平穩(wěn)運行的,系統(tǒng)設計要權衡延遲與數(shù)據(jù)一致性的問題。為了保證數(shù)據(jù)一致性,讀寫的延遲必然升高。
在分區(qū)錯誤的情況下,在C和A中取舍,縮寫為 PAC。分區(qū)正確的情況下,取 Latency(延遲)與 Consistency(一致性),縮寫為LC。PACELC 中的 E 代表 Else,連起來就是PACELC。
很多存儲軟件實現(xiàn)了 PACELC 的策略,用戶根據(jù)不同業(yè)務場景使用不同的配置。以MySQL主從復制為例,提供了三種模式:
- 異步模式:主庫執(zhí)行完客戶端提交的事務,立即將結果返給客戶端,不關心從庫是否已經(jīng)接收并處理。由于數(shù)據(jù)同步的延時,客戶端在從庫上可能讀不到最新數(shù)據(jù)。這種模式對MySQL是性能最佳的,但是用戶需要權衡,業(yè)務能否忍受這種延時。
- 全同步復制:主庫執(zhí)行完客戶端提交的事務,所有的從庫都執(zhí)行了該事務才返回結果。這樣保證強一致性,但是響應時間變長了。
- 半同步復制:主庫在執(zhí)行完客戶端提交的事務后,等待至少一個從庫接收到并寫到 relay log 中,才返回給客戶端。這樣做延遲小了很多,相比于異步復制,數(shù)據(jù)更加不容易丟失。
3.3 BASE模型
BASE模型全稱是Basically Available(基本可用)、Soft-state(軟狀態(tài)/柔性事務)、Eventually Consistent(最終一致性)。絕大部分分布式系統(tǒng),實現(xiàn)分區(qū)容忍性是基本要求,因此要平衡一致性和可用性。BASE強調(diào)犧牲高一致性,獲得可用性。允許數(shù)據(jù)在一段時間內(nèi)不一致,只要保證最終一致就可以了。
3.4 一致性算法
分布式系統(tǒng)中的數(shù)據(jù)一致性問題,是系統(tǒng)設計中最關鍵、最有難度的領域,業(yè)界提出了很多成熟的一致性共識算法。
- Paxios算法
1998年,萊斯利·蘭伯特(Leslie Lamport)在《The Part-Time Parliament》論文中首次公開Paxos協(xié)議。他使用希臘的小島Paxos作為比喻,描述了Paxos小島中通過決議的流程。2001年,Lamport重新發(fā)表了樸實的算法描述版本《Paxos Made Simple》。
- Raft算法
由于Paxos算法太難以理解和實現(xiàn),斯坦福大學的 Diego Ongaro 和 John Ousterhout 提出了更容易理解的 Raft 算法。相比傳統(tǒng)的 Paxos 算法,Raft 將大量的計算問題分解成簡單的相對獨立的子問題,并且和 Multi-Paxos 有同樣的性能,
有興趣的朋友,可以看看Raft算法的動畫演示。
- ZAB協(xié)議
ZAB協(xié)議全稱 Zookeeper Atomic Broadcast(Zookeeper 原子廣播協(xié)議)。分布式協(xié)調(diào)服務ZooKeeper設計了支持崩潰恢復的一致性協(xié)議。基于該協(xié)議,ZooKeeper 實現(xiàn)了一種主從模式的系統(tǒng)架構來保持集群中各個副本之間的數(shù)據(jù)一致性。從設計上看,ZAB 協(xié)議和 Raft 很相似。
4.分布式架構組件
4.1 主要組件
- 服務注冊與發(fā)現(xiàn):Spring Cloud Eureka、Apache Nacos、Apache Zookeeper、ETCD
- 服務調(diào)用:Spring Cloud Feign、Apache Dubbo、Motan、gRPC
- 微服務網(wǎng)關:Spring Cloud Zuul、Spring Cloud Gateway、Apache ShenYu、Kong
- 微服務熔斷降級:Spring Cloud Hytrix、Alibaba Sentinel
- 負載均衡器:Spring Cloud Ribbon、Spring Cloud LoadBalancer
- 分布式監(jiān)控:Spring Boot Admin、美團 CAT、Zabbix、Prometheus + Grafana + Alertmanager、Open-Falcon
- 配置管理:Spring Cloud Config、Alibaba Nacos、百度Disconf、攜程Apollo
- 消息隊列:RocketMQ、Kafka、RabbitMQ
- 任務調(diào)度:Apache Dolphinscheduler、Apache ElasticJob、XXL-JOB
- 分布式事務:Alibaba Seata
- 調(diào)用鏈跟蹤:Spring Cloud Sleuth + ZipKin、Apache Skywalking
- 日志采集:Flume + Kafka + HDFS、Elasticsearch + Logstash + kafka + Kiabana
- 分庫分表:Apache ShardingSphere、MyCat 、美團DBProxy
- 分布式鎖:Redisson + Redis
- 權限控制:Spring Security、Shiro + JWT
- 文件系統(tǒng):Fastdfs、Minio、HDFS
- 反向代理:Nginx
4.2 輔助工具
- Java應用診斷:Alibaba Arthas
4.3 常用架構
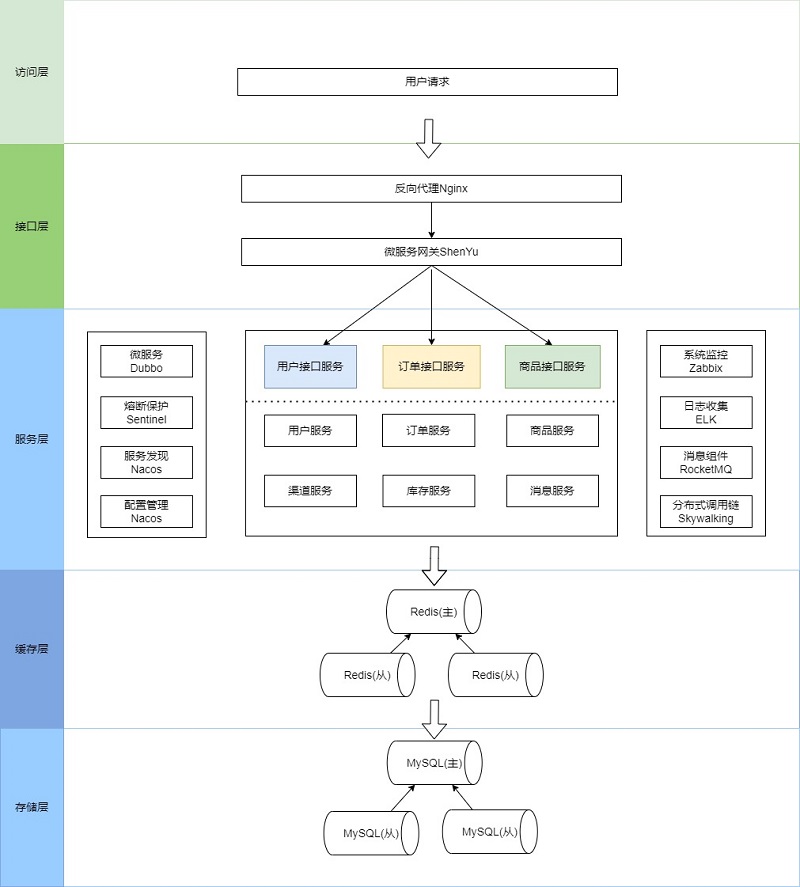
5.常用數(shù)據(jù)庫
5.1 數(shù)據(jù)庫的發(fā)展
數(shù)據(jù)庫是一個悠久歷史的行業(yè),從誕生到現(xiàn)在也有接近五十年的歷史了。數(shù)據(jù)庫一直在技術、業(yè)務以及應用場景等方面不停地演進和發(fā)展。上世紀九十年代,針對個人辦公、個人娛樂以及企業(yè)信息化的場景,基于X86服務器誕生了像MySQL、MS SQL Server這些著名的關系型數(shù)據(jù)庫。
NoSQL數(shù)據(jù)庫是由于互聯(lián)網(wǎng)業(yè)務的誕生而產(chǎn)生的。2006年,谷歌引入了BigTable,后續(xù)出現(xiàn)了HBase、Cassandra、MongoDB和Redis,這些數(shù)據(jù)庫都是由不同的底層數(shù)據(jù)組織形式去解決不同的問題。在2010年前后,谷歌又引入了以Spanner為代表的新產(chǎn)品,出現(xiàn)了F1、SequoiaDB、TiDB等NewSQL數(shù)據(jù)庫,使用SQL解決應用性問題,也保留了NoSQL的可擴展性問題。
NoSQL數(shù)據(jù)庫是為了解決傳統(tǒng)關系型數(shù)據(jù)庫的弊端,它有四個特點:
- 易擴展:NoSQL數(shù)據(jù)共同的特點是去掉關系數(shù)據(jù)庫的關系型特性,數(shù)據(jù)之間無關系,這樣就非常容易擴展,在架構的層面上帶來了可擴展的能力。
- 高性能:NoSQL數(shù)據(jù)庫都具有非常高的讀寫性能,尤其在大數(shù)據(jù)量下同樣表現(xiàn)優(yōu)秀。由于數(shù)據(jù)之間的無關系性,數(shù)據(jù)庫的結構簡單。
- 高可用:NoSQL在不太影響性能的情況,就可以方便地實現(xiàn)高可用的架構。比如Cassandra、HBase模型,通過復制模型也能實現(xiàn)高可用。
- 數(shù)據(jù)模型靈活:NoSQL無須事先為要存儲的數(shù)據(jù)建立字段,隨時可以存儲自定義的數(shù)據(jù)格式。而在關系數(shù)據(jù)庫里,增刪字段是一件非常麻煩的事情。
5.2 OLTP和OLAP
從業(yè)務場景來看,數(shù)據(jù)處理可以分為OLTP和OLAP。這兩種場景采用何種數(shù)據(jù)庫,取決于開發(fā)人員的技術水平和經(jīng)驗。通常來說,OLTP采用強一致性的關系型數(shù)據(jù)庫,OLAP采用NoSQL或者列式數(shù)據(jù)庫。
- OLTP(on-line transaction processing)
OLTP為聯(lián)機事務處理,主要用來記錄業(yè)務事件的發(fā)生。當行為產(chǎn)生后,系統(tǒng)記錄事件是誰在什么時候什么地方做了什么事,在數(shù)據(jù)庫中進行數(shù)據(jù)的增刪改查,要求高實時性、強穩(wěn)定性、數(shù)據(jù)一致性。
- OLAP(On-Line Analytical Processing)
OLAP為聯(lián)機分析處理,側(cè)重大數(shù)據(jù)量查詢。當業(yè)務發(fā)展到一定程度,要利用離線數(shù)據(jù)做分析,為決策提供支持。
5.3 常用NoSQL數(shù)據(jù)庫
- MongoDB
MongoDB是一個面向文檔的數(shù)據(jù)庫,以JSON格式存儲數(shù)據(jù)。它主要用于網(wǎng)站的數(shù)據(jù)存儲、內(nèi)容管理與緩存應用。MongoDB支持全文檢索,查詢方式非常豐富,在數(shù)據(jù)處理與聚合等方面具有很強的靈活性,同時具備極高的擴展性和可用性。
- Cassandra
Cassandra是一套開源分布式數(shù)據(jù)庫系統(tǒng)。最初由Facebook開發(fā),用于儲存收件箱等簡單格式數(shù)據(jù),集Google BigTable的數(shù)據(jù)模型與Amazon Dynamo的完全分布式的架構于一身。由于Cassandra良好的可擴展性,被Digg、Twitter等知名Web 2.0網(wǎng)站所采納,成為了一種流行的分布式結構化數(shù)據(jù)存儲方案。
- CouchDB
CouchDB是一個面向文檔的數(shù)據(jù)庫,以JSON格式存儲數(shù)據(jù)。CouchDB可以用于存儲網(wǎng)站的數(shù)據(jù)與內(nèi)容,以及提供緩存等。支持通過JavaScript在CouchDB上運行MapReduce查詢。CouchDB還提供了一個非常方便的基于Web的管理控制臺。
- Redis
Redis是一個內(nèi)存中的鍵值數(shù)據(jù)庫。Redis具備存儲和操作高級數(shù)據(jù)類型的能力。這些數(shù)據(jù)類型是大多數(shù)開發(fā)人員熟悉的基本數(shù)據(jù)結構(列表、映射、集合)。Redis的讀寫數(shù)據(jù)的效率極高,遠遠超過常規(guī)數(shù)據(jù)庫,常常用于大型項目的緩存層。
- HBase
HBase 是一個面向列式存儲的分布式數(shù)據(jù)庫,其設計思想來源于 Google 的 BigTable 論文。HBase 底層存儲基于 HDFS 實現(xiàn),集群的管理基于 ZooKeeper 實現(xiàn)。HBase 良好的分布式架構設計為海量數(shù)據(jù)的快速存儲、隨機訪問提供了可能,基于數(shù)據(jù)副本機制和分區(qū)機制可以輕松實現(xiàn)在線擴容、縮容和數(shù)據(jù)容災,是大數(shù)據(jù)領域中 Key-Value 數(shù)據(jù)結構存儲最常用的數(shù)據(jù)庫方案。
- Elasticsearch
Elasticsearch 是一個分布式、高擴展、高實時的搜索與數(shù)據(jù)分析引擎。它提供了一個多用戶能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java語言開發(fā)的,并作為Apache許可條款下的開放源碼發(fā)布,是一種流行的企業(yè)級搜索引擎。
- ClickHouse
ClickHouse 是俄羅斯的Yandex(類似百度)開源的列式存儲數(shù)據(jù)庫,主要用于在線分析處理查詢,能夠使用SQL查詢實時生成分析數(shù)據(jù)報告。使用場景與Elasticsearch類似,甚至有更高的性能。
5.4 常用關系型數(shù)據(jù)庫
- Oracle
Oracle是全球最大的信息管理軟件及服務供應商,總部位于美國加州Redwoodshore。Oracle數(shù)據(jù)庫產(chǎn)品為財富排行榜上的前1000家公司采用,是最知名、使用最廣泛的企業(yè)數(shù)據(jù)庫。
- DB2
DB2是IBM公司開發(fā)的關系數(shù)據(jù)庫管理系統(tǒng),主要用于大型應用系統(tǒng),具有較好的可伸縮性 。DB2是IBM推出的第二個關系型數(shù)據(jù)庫,所以稱為DB2。它提供了高層次的數(shù)據(jù)利用性、完整性、安全性、并行性、可恢復性,以及小規(guī)模到大規(guī)模應用程序的執(zhí)行能力,具有與平臺無關的基本功能和SQL命令運行環(huán)境。可以同時在不同操作系統(tǒng)使用,包括Linux、UNIX 和 Windows。
- Microsoft SQL Sever
Microsoft SQL Server 是一個全面的數(shù)據(jù)庫平臺,使用集成的商業(yè)智能 (BI)工具提供了企業(yè)級的數(shù)據(jù)管理。Microsoft SQL Server數(shù)據(jù)庫引擎為關系型數(shù)據(jù)和結構化數(shù)據(jù)提供了更安全可靠的存儲功能,使您可以構建和管理用于業(yè)務的高可用和高性能的數(shù)據(jù)應用程序。
- MySQL
MySQL是使用最廣泛的開源關系型數(shù)據(jù)庫,由瑞典MySQL AB公司開發(fā),現(xiàn)在已被 Oracle收購。MySQL與常用的主流數(shù)據(jù)庫Oracle、SQL Server相比,特點就是免費,并且在任何平臺上都能使用,占用的資源較小,受個人用戶以及中小企業(yè)青睞。對于大型項目來說,MySQL的承載能力和安全性就略遜于Oracle數(shù)據(jù)庫。
- MariaDB
MariaDB數(shù)據(jù)庫管理系統(tǒng)是MySQL的一個分支,主要由開源社區(qū)在維護,采用GPL授權許可。MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能輕松成為MySQL的代替品。在存儲引擎方面,使用XtraDB來代替MySQL的InnoDB。MariaDB名稱來自創(chuàng)始人Michael Widenius的女兒Maria的名字。
- PostgreSQL
PostgreSQL 是一個強大的開源對象關系數(shù)據(jù)庫系統(tǒng),它使用并擴展了SQL語言,并結合了許多安全存儲和擴展最復雜數(shù)據(jù)工作負載的功能。PostgreSQL的起源可以追溯到 1986 年作為加州大學伯克利分校POSTGRES項目的一部分。PostgreSQL的架構、可靠性、數(shù)據(jù)完整性、功能集、可擴展性得到充分的驗證,開源社區(qū)也非常活躍。它是最接近工業(yè)標準SQL92的查詢語言,至少實現(xiàn)了SQL:2011標準中要求的179項主要功能中的160項(注:目前沒有哪個數(shù)據(jù)庫管理系統(tǒng)能完全實現(xiàn)SQL:2011標準中的所有主要功能)。
- TiDB
TiDB是PingCAP公司自主設計、研發(fā)的開源分布式關系型數(shù)據(jù)庫,是一款同時支持在線事務處理與在線分析處理 (Hybrid Transactional and Analytical Processing,HTAP)的融合型分布式數(shù)據(jù)庫產(chǎn)品,具備水平擴容或者縮容、金融級高可用、實時 HTAP、云原生的分布式數(shù)據(jù)庫、兼容 MySQL 5.7 協(xié)議和MySQL生態(tài)等重要特性,為用戶提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解決方案。TiDB適合高可用、強一致要求較高、數(shù)據(jù)規(guī)模較大等各種應用場景。
- TBase
TiDB是騰訊在Postgres-XC基礎上開發(fā)的數(shù)據(jù)庫。Postgres-XC(eXtensible Cluster)是一個提供寫可擴展、同步、對稱的和透明的PostgreSQL群集解決方案的開源項目。相較于Postgres-XC,TBase的穩(wěn)定性得到了較大提高,通過在內(nèi)核中引入GROUP概念,提出了雙Key分布策略,有效地解決了數(shù)據(jù)傾斜的問題。它根據(jù)數(shù)據(jù)的時間戳,將數(shù)據(jù)分為冷數(shù)據(jù)和熱數(shù)據(jù),分別存儲于不同的存儲設備中,有效地解決了存儲成本的問題。
- OceanBase
OceanBase是由螞蟻集團自主研發(fā)的企業(yè)級分布式關系數(shù)據(jù)庫,始創(chuàng)于2010年。OceanBase在TPC-C和TPC-H測試上都刷新了世界紀錄的國產(chǎn)原生分布式數(shù)據(jù)庫。OceanBase具有數(shù)據(jù)強一致、高可用、高性能、在線擴展、高度兼容SQL標準和主流關系數(shù)據(jù)庫、低成本等特點。
- SequoiaDB
SequoiaDB巨杉數(shù)據(jù)庫是一款金融級分布式關系型數(shù)據(jù)庫,主要面對高并發(fā)聯(lián)機交易型場景提供高性能、可靠穩(wěn)定以及無限水平擴展的數(shù)據(jù)庫服務。用戶可以在 SequoiaDB 巨杉數(shù)據(jù)庫中創(chuàng)建多種類型的數(shù)據(jù)庫實例,以滿足上層不同應用程序各自的需求。SequoiaDB 巨杉數(shù)據(jù)庫支持 MySQL、MariaDB、PostgreSQL 和 SparkSQL四種關系型數(shù)據(jù)庫實例、JSON文檔類數(shù)據(jù)庫實例、以及 S3對象存儲的非結構化數(shù)據(jù)實例。
6.參考
https://www.yisu.com/zixun/323416.html
https://blog.csdn.net/qq_16933229/article/details/109729522
https://www.jianshu.com/p/794ba6b42dcc
http://www.rzrgm.cn/lidabo/p/15822815.html
https://blog.csdn.net/qq_31960623/article/details/116308332
http://www.rzrgm.cn/lidabo/p/15822815.html
https://blog.csdn.net/qq_43413788/article/details/119171555
https://blog.csdn.net/yuhaiyang_1/article/details/80862914
https://blog.csdn.net/TJtulong/article/details/106510970
https://blog.51cto.com/u_14637492/5260036
公 眾 號:編碼專家
獨立博客:codingbrick.com
文章出處:http://www.rzrgm.cn/xiaoyangjia/p/16470042.html
本文版權歸作者所有,任何人或團體、機構全部轉(zhuǎn)載或者部分轉(zhuǎn)載、摘錄,請在文章明顯位置注明作者和原文鏈接。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號