

(一)Seq2Seq概述
Seq2Seq(Sequence to Sequence,序列到序列模型) 是一種循環神經網絡的變種,包括編碼器 (Encoder) 和解碼器 (Decoder) 兩部分,編碼器和解碼器通常使用RNN結構。
Seq2Seq模型是輸出的長度不確定時采用的模型,這種情況一般是在機器翻譯的任務中出現,將一句中文翻譯成英文,那么這句英文的長度有可能會比中文短,也有可能會比中文長,所以輸出的長度就不確定了。
RNN 結構及使用
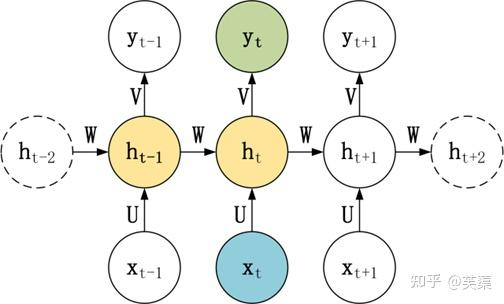
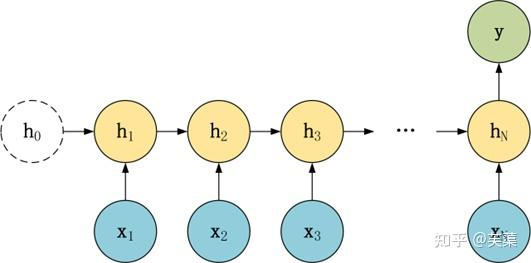
RNN基本的模型如上圖所示,每個神經元接受的輸入包括:前一個神經元的隱藏層狀態h(用于記憶)和當前的輸入x(當前信息)。
神經元得到輸入之后,會計算出新的隱藏狀態h和輸出y,然后再傳遞到下一個神經元。因為隱藏狀態h的存在,使得RNN具有一定的記憶功能。
RNN結構變種
常要對RNN模型結構進行少量的調整,根據輸入和輸出的數量,分為三種比較常見的結構:N vs N、1 vs N、N vs 1。
N vs N
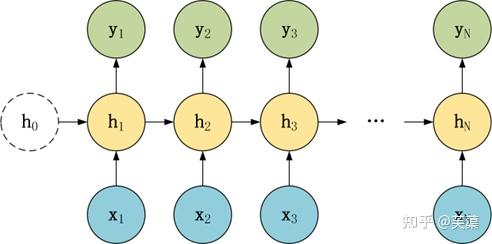
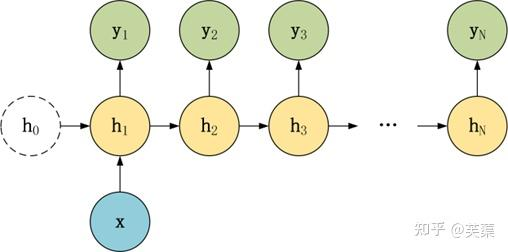
1 vs N
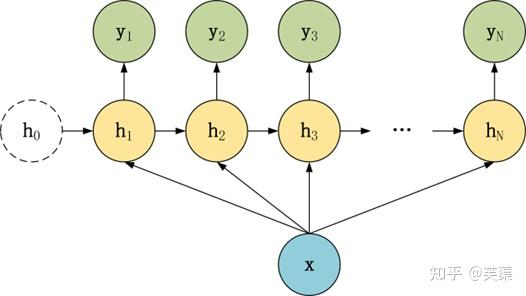
N vs 1
(二)Seq2Seq架構
Seg2Seg架構是一種在自然語言處理只領域中非常重要的模型結構,廣泛應用于諸如機器翻譯、文本摘要、對話系統等任務。
該架構的核心思想是將輸入序列映射為一個中間表示,然后再從這個中間表示生成目標序列。
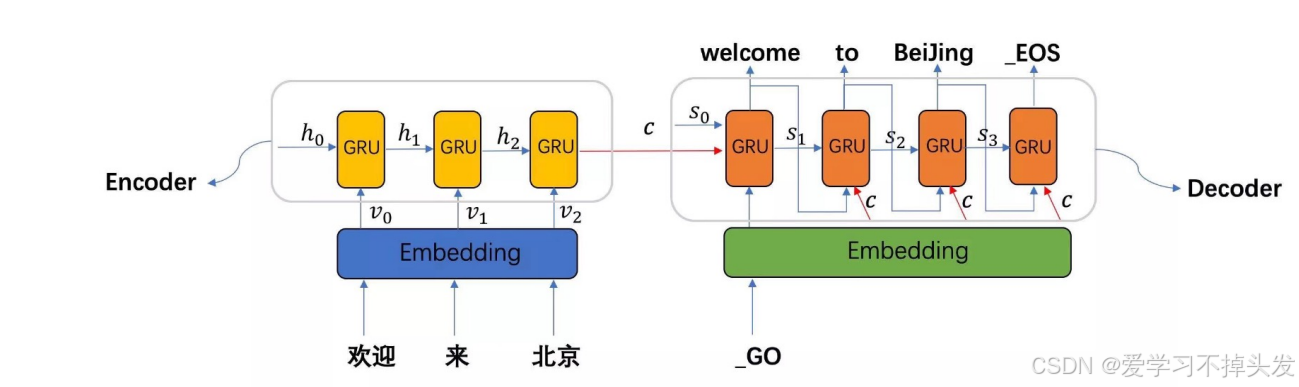
seq2seq模型架構包括三部分,分別是:
- encoder(編碼器)
- decoder(解碼器)
- c(中間語義張量)
Seq2Seq是一種重要的 RNN 模型,也稱為Encoder-Decoder模型,可以理解為一種 N×M 的模型。
模型包含兩個部分:Encoder用于編碼序列的信息,將任意長度的序列信息編碼到一個向量C里。
而Decoder是解碼器,解碼器得到上下文信息向量C之后可以將信息解碼,并輸出為序列。
Seq2Seq模型結構有很多種,下面是幾種比較常見的:
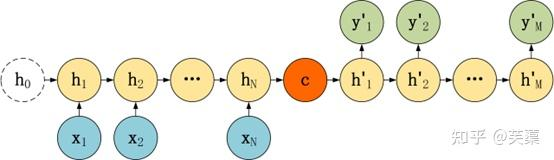
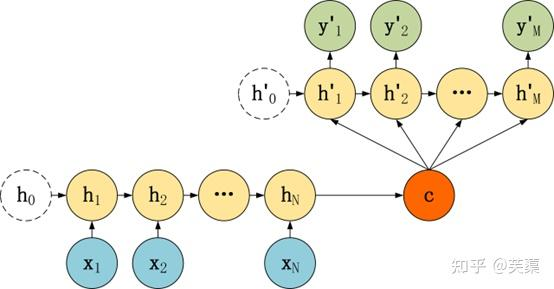
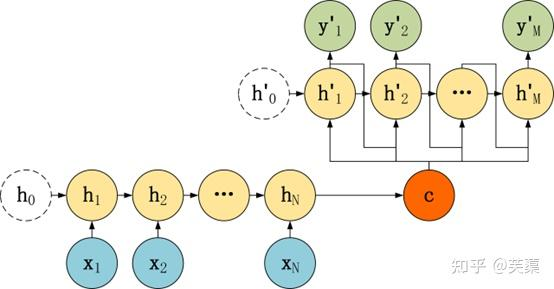
(三)Seq2Seq編解碼
Seq2Seq模型的主要區別在于Decoder,它們的Encoder都是一樣的。
編碼
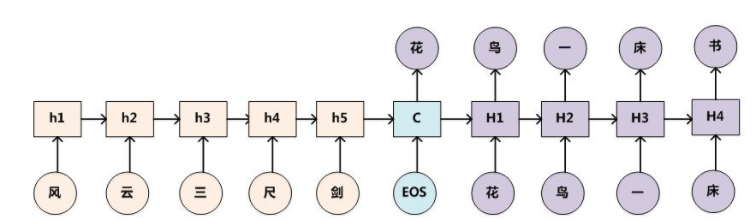
以下圖為例:
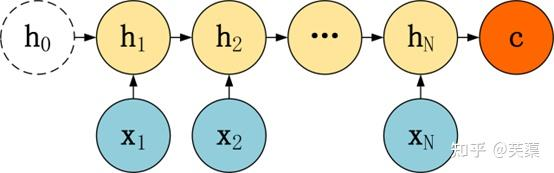
(1)編碼器
編碼器負責將輸入序列(例如一段文本)映射成一個中間的表示,即中間語義張量C,通常是一個固定長度的向量。
常用的編碼器結構是循環神經網絡(RNN)或者長短時記憶網絡(LSTM),近年來也包括了Transformer模型編碼器工作流程。
(2)編碼器工作流程
對輸入的文本序列每個時間步都會產生一個隱藏狀態,這些隱藏狀態會捕捉到輸入序列的信息,并被傳遞給下一個時刻。
在Seq2Seq中,編碼器會將整個輸入序列處理完后,最后一個時刻的隱藏狀態會被用作解碼器的初始隱藏狀態。
(3)編碼流程
1個時間步1個時間步的編碼,每個時間步有隱藏層輸出,最終組合成中間語義張量C。
(4)張量計算
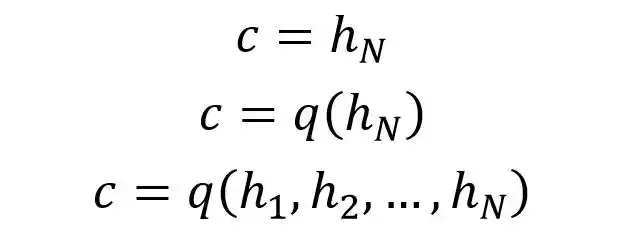
例子中編碼器Encoder與一般的RNN區別不大,只是中間神經元沒有輸出,其中的上下文向量C可以采用多種方式進行計算。
C可以直接使用最后一個神經元的隱藏狀態hN表示,也可以在最后一個神經元的隱藏狀態上進行某種q函數變換hN而得到,等等。
得到上下文向量C之后,需要傳遞到Decoder。
解碼
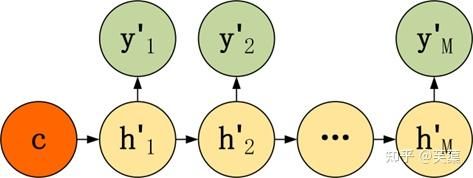
Decoder有多種不同的結構,列舉三種:
- 第一種
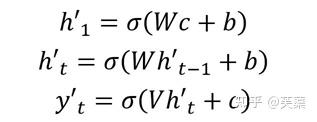
- 第二種
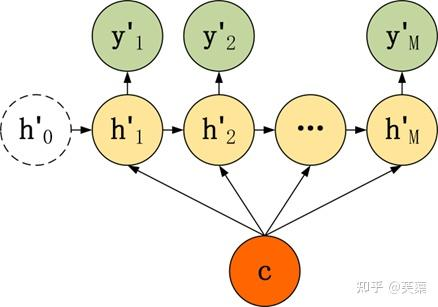
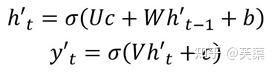
有了自己的初始隱藏層狀態h'0,不再把上下文向量C當成是RNN的初始隱藏狀態,而是當成RNN每一個神經元的輸入。
- 第三種
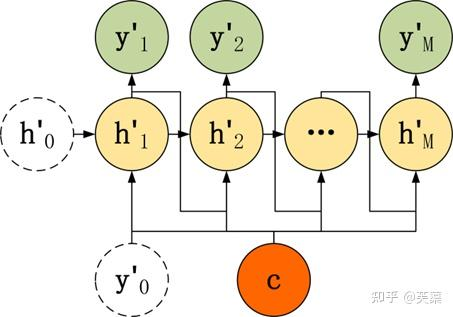
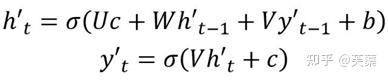
和第二種類似,但是在輸入的部分多了上一個神經元的輸出y'。即每一個神經元的輸入包括:上一個神經元的隱藏層向量h',上一個神經元的輸出y',當前的上下文向量輸入C。
(1)解碼器
解碼器接受編碼器傳遞過來的初始隱藏狀態,并逐步生成目標序列。
解碼器也是一個RNN系列模型,通常會包含一個額外的注意力機制,以便在生成目標序列過程中動態地關注輸入席列的不同部分。
(2)解碼器的工作流程
一個時間步一個時間步的解碼,采用自回歸機制進行解碼,上一個時間步的輸出作為下一個的輸入。
每個時間步都會用到中間語義張量C。
(3)解碼流程
每個時間步輸入input和ht-1,輸出output和ht。
再接一個全連接層+softmax做一個分類,從分類結果中找一個預測結果即可。
(四)注意力機制
(1)為什么引入注意力機制
上述的seq2seq看似沒有什么問題,其實有一個很大的問題就是使用的是encoder-decoder的結構,我們希望能把不論多長的句子的信息都包含在一個固定的向量C里面去表達。
對于較長的句子,根本沒辦法包含所有有用的信息;序列較長的時候,梯度消失就會變得明顯,尤其是RNN機制實際中存在長程梯度消失的問題。對于較長的句子,我們很難寄希望于將輸入的序列轉化為定長的向量而保存所有的有效信息,所以隨著所需翻譯句子的長度的增加,這種結構的效果會顯著下降。
如果我們想翻譯一個段落,一篇文章,難道我們需要將所有段落都運行encoder到一個常量C,再去翻譯這個常量?很明顯不是,我們會一句一句地去翻譯,我們每次都是注意力集中在一部分去翻譯,而且翻譯每一句話,也是注意力集中在某幾個詞匯上的,只使用最后一個神經元得到的向量C效果不理想。
(2)引入注意力機制
接下來就是大名鼎鼎的attention模型了,attention模型就跟人的注意力一樣,跟人類翻譯文章時候的思路有些類似,即將注意力關注于我們翻譯部分對應的上下文。
如下圖所示,當我們翻譯“knowedge”時,只需將注意力放在源句中“知識”的部分;當翻譯“power”時,只雲將注意力集中在“力量”。這樣,當我們decoder預測目標翻譯的時候就可以看到encoder的所有信息,而不僅局限于原來模型中定長的隱藏向量,并且不會喪失長程的信息。
換句話說,attention模型并不像前面提到的Encoder的結構一樣對整個句子用一個C表征,它對于每個單詞都有一個以單詞為中心的表征。使用了Attention后,Decoder 的輸入就不是固定的上下文向量C了,而是會根據當前翻譯的信息計算當前的C。
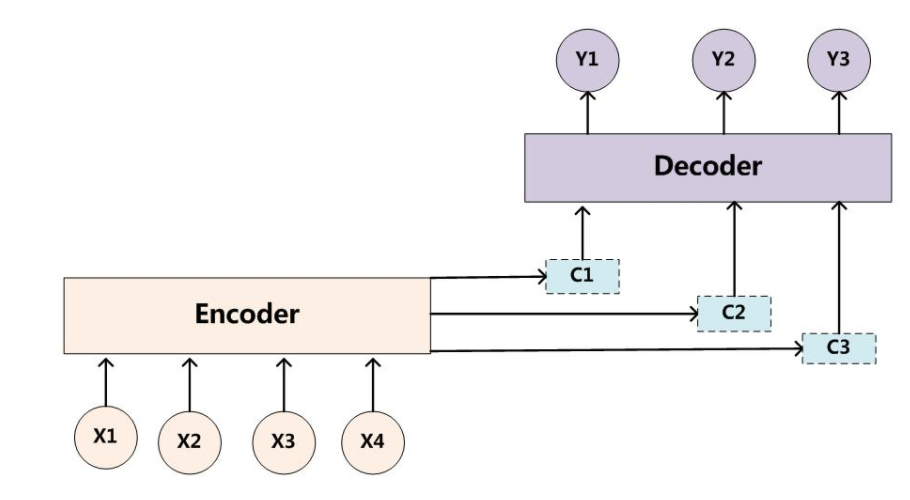
相比于之前的encoder-decoder模型,attention模型最大的區別就在于它不在要求編碼器將所有輸入信息都編碼進一個固定長度的向量之中。相反,此時編碼器需要將輸入編碼成一個向量的序列,而在解碼的時候每一步都會選擇性的從向量序列中挑選一個子集進行進一步處理。這樣在產生每一個輸出的時候,都能夠做到充分利用輸入序列攜帶的信息,而且這種方法在翻譯任務中取得了非常不錯的成果。
(3)引入注意力機制
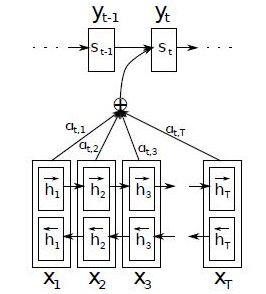
使用了Attention后,Decoder的輸入就不是固定的上下文向量C了,而是會根據當前翻譯的信息,計算當前的C,如上圖顯示。
Attention需要保留Encoder每一個神經元的隱藏層向量h,然后Decoder的第t個神經元要根據上一個神經元的隱藏層向量h't-1計算出當前狀態與Encoder每一個神經元的相關性et。
神經元相關性et是一個N維的向量(Encoder神經元個數為N),若et的第i維越大,則說明當前節點與Encoder第i個神經元的相關性越大。et的計算方法有很多種,即相關性系數的計算函數a有很多種。
si表示解碼器i時刻的隱藏狀態,計算公式是
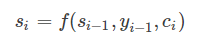
ci是由編碼時的隱藏向量序列(h1,…,hTx)按權重相加得到的。
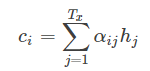
αij又是怎么得到的呢?這個其實是由第i-1個輸出隱藏狀態si?1和輸入中各個隱藏狀態共同決定的,也即是
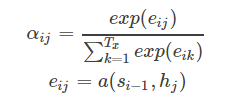
我們現在再把公式按照執行順序匯總一下:
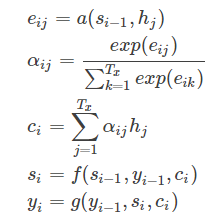
(五)編解碼舉例
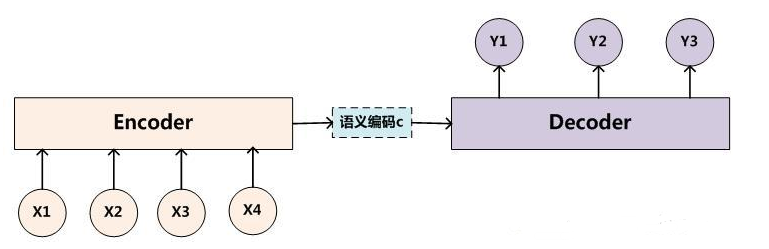
其中,X、Y均由各自的單詞序列組成:
X = <x1,x2,...,xm>
Y = <y1,y2,...,yn>
Encoder:是將輸入序列通過非線性變換編碼成一個指定長度的向量C(中間語義表示)。
C = F(x1,x2,...,xm)
Decoder:是根據向量C(encoder的輸出結果)和之前生成的歷史信息y1,y2,...,yn來生成i時刻要生成的單詞yi。
yi = G(C,y1,y2,...,yn-1)

 浙公網安備 33010602011771號
浙公網安備 33010602011771號