
為什么我強烈推薦 TOON(Token-Oriented Object Notation)——以及 .NET 版 Toon.NET
給 LLM 喂結構化數據,別再硬塞 JSON 了。在很多真實場景里,TOON 同時做到更省 Token、更穩的解析/檢索、更易于寫提示詞。
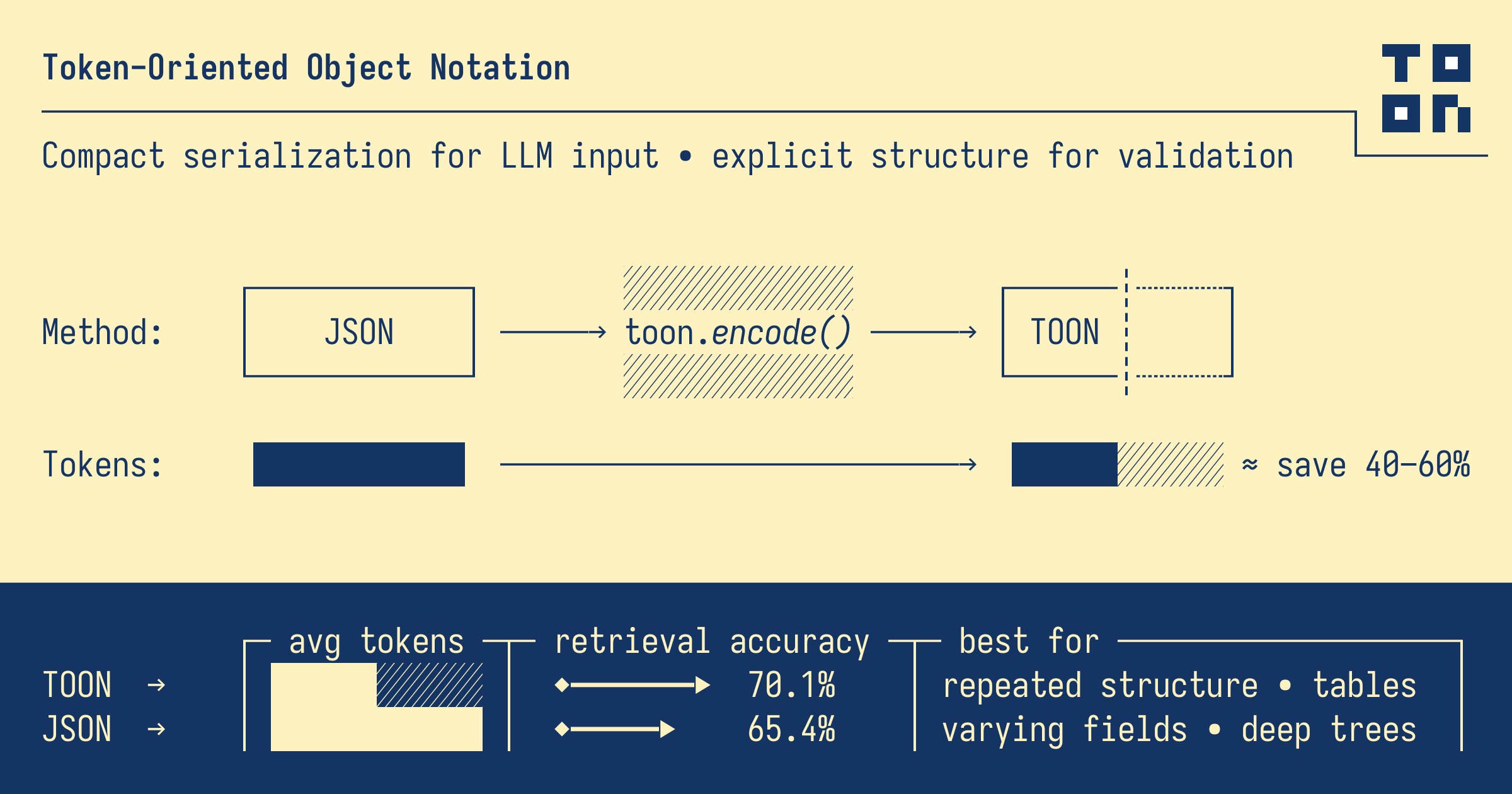
(上圖:TOON 官方邏輯圖,來源 toon-format/toon 倉庫。 )
TOON 是什么?
TOON 是一種為 LLM 輸入而生的緊湊序列化格式。它把 YAML 的縮進層級和 CSV 的表格行融合起來,用極少的符號把結構表達清楚,特別擅長“字段一致的對象數組”(如表格數據)。官方定位很明確:只用作模型輸入的中間層——應用里照常用 JSON,喂給模型前再轉成 TOON。(GitHub)
核心特性(官方):
- 更省 Token:通常比 JSON 少 30–60%。
- 更穩健:用顯式長度
[N]和字段頭{a,b,c}做“護欄”,便于校驗與約束。 - 語法極簡:去掉大括號/引號等重復符號,縮進表達層級,表頭只寫一次、數據連行輸出。(GitHub)
為什么不是 JSON(以及“壓縮 JSON”)?
- 結構信息的冗余:JSON 的每一行都重復鍵名,合并空格/去換行后雖然“壓縮”了字符,但并沒有減少模型看見的關鍵 Token 數,甚至可能降低模型對結構的把握(你給出的實驗里就體現為識別率下降)。
- TOON 的思路:一次聲明、按行鋪開。對于多行同構數據,去掉重復鍵名就是“白撿”的 Token 節省,同時字段頭與行數構成了顯式約束,更利于模型“對齊”結構。官方基準在多組數據上都顯示對 JSON 有明顯節省,且對 “緊湊 JSON”(minified/compact)依舊有可觀優勢。(GitHub)
一句話:當你的數據像表格那樣“多行同字段”時,TOON 的收益隨規模復利增長。(GitHub)
官方基準與節省幅度
在官方基準里(GitHub 熱門倉庫、日常分析、電商訂單三類數據),TOON 相對 JSON 平均節省 ~49% Token,相對緊湊 JSON 也節省 ~28%;不同數據結構會有差異,但總體趨勢穩定。(GitHub)
官方圖例也給出一個直觀口徑:≈ 40–60% 節省,并顯示在檢索類任務上的準確率提升示意。
你提供的模型對比數據同樣有參考意義:
- gpt-5-nano:TOON 96.1%(148/154),優于 CSV / YAML / 緊湊 JSON / XML / JSON。
- gemini-2.5-flash:TOON 86.4%,與 CSV/XML 相近,顯著高于 JSON。
- haiku / grok 等輕量或非推理模型:TOON 仍具競爭力,但不同模型差異更大。
這些是你給出的內部評測結果,用的數據集與提示模板會影響分數,但方向與官方結論一致。
什么時候用 / 不用?
強烈推薦用在:
- 大量同構記錄(表格、日志、指標、清單、訂單等)
- 檢索/比對/校驗型任務(顯式行數與字段讓模型少犯錯)
- 上下文成本敏感、批量調用頻繁的 Agent/Workflow
謹慎使用或繼續用 JSON:
- 深層嵌套、字段形態差異大的對象(此時 JSON 可能更高效)
- 需要對外暴露 API / 存儲:TOON 是輸入層而非通用交換格式。(GitHub)
JSON → TOON:一眼看懂
同一份數據:
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}
轉為 TOON:
users[2]{id,name,role}:
1,Alice,admin
2,Bob,user
頭部一次性給出行數和字段次序,后面只寫值行。(GitHub)
Prompt 最佳實踐(官方建議)
- 當作輸入喂給模型時,直接展示格式而不是解釋格式;用 ```toon 代碼塊包起來即可。
- 讓模型產出 TOON 時,務必在提示里給出期望的表頭、兩空格縮進、行數
[N]與實際行數一致等約束。(GitHub)
.NET 實現:AIDotNet/Toon.NET
我們開源了 Toon.NET,對齊官方規范(當前 v1.3),并盡量提供與 System.Text.Json 一致的 API 與選項模型,方便 .NET 開發者“無縫上手”。(GitHub)
亮點
- 高性能編碼:對象、原子數組(行內)、對象數組(表格)路徑已實現
- 解碼管線在推進中(掃描/解析/驗證),當前已支持原子值回讀
- 選項包括
Indent / Delimiter(Comma|Tab|Pipe) / Strict / LengthMarker等 - 目標框架:.NET 8/9/10;許可:MIT。(GitHub)
快速開始(C#)
using Toon;
var options = new ToonSerializerOptions
{
Indent = 2,
Delimiter = ToonDelimiter.Comma,
Strict = true,
LengthMarker = null
};
var data = new
{
users = new[]
{
new { name = "alice", age = 30 },
new { name = "bob", age = 25 }
},
tags = new[] { "a", "b", "c" },
numbers = new[] { 1, 2, 3 }
};
string toonText = ToonSerializer.Serialize(data, options);
// users[2]{name,age}:
// 1,alice
// 2,bob
// tags[3]: a,b,c
// numbers[3]: 1,2,3
以上示例與官方格式對齊;更多 API、選項與路線圖詳見倉庫 README。(GitHub)
倉庫地址
- TOON 官方:toon-format/toon(規范、TS 實現、基準與圖示)。(GitHub)
- .NET 實現:AIDotNet/Toon.NET(歡迎 Star、Issue、PR)。(GitHub)
落地清單(給工程團隊)
- 識別數據形態:優先挑選“多行同字段”的提示數據(表格類)。(GitHub)
- 引入編碼步驟:應用層仍用 JSON,在入模前
encode(JSON) → TOON。(GitHub) - 模板化約束:在系統提示中固定 TOON 表頭、縮進、
[N]規則,并做長度/字段校驗。(GitHub) - 測量而非臆測:不同 tokenizer/模型會帶來差異,基于你的真實數據做一次 A/B(Token/費用/準確率)。(GitHub)
- 回退策略:當數據深嵌套/非同構時,保留 JSON 路徑;TOON 不是通用存儲/對外 API。(GitHub)
常見坑與注意
- 混合或復雜數組:TOON 會回退為列表項寫法,不再是表格行,收益會變小。(GitHub)
- 空格/縮進/行數要嚴格匹配;建議在服務端做一次輕量校驗再送模型。(GitHub)
- Tokenizer 不同會帶來節省幅度波動(官方基準用 GPT 系列的 cl100k/o200k)。(GitHub)
結語
如果你的 LLM 應用經常把成百上千行的表格/對象數組塞給模型,TOON 是一個立竿見影的“省錢+增穩”方案。現在就試試:

 浙公網安備 33010602011771號
浙公網安備 33010602011771號