


Scrapy爬取網易云音樂和評論(三、爬取歌手)
教程系列鏈接目錄:
1、Scrapy爬取網易云音樂和評論(一、思路分析)
2、Scrapy爬取網易云音樂和評論(二、Scrapy框架每個模塊的作用)
3、Scrapy爬取網易云音樂和評論(三、爬取歌手)
4、Scrapy爬取網易云音樂和評論(四、關于API)
5、Scrapy爬取網易云音樂和評論(五、評論)
項目GitHub地址:https://github.com/sujiujiu/WYYScrapy
前面有提到,spiders目錄下的文件最好不要取和項目相同的名字,如果取了也沒關系,有辦法,在導入模塊的最前面加上這句:
from __future__ import absolute_import
因為參考的文章太多了,我也找不到出處的鏈接了抱歉。
一、導入:

仍然提醒,要記得導入items的那幾個模塊、
二、最基本的代碼結構是這樣的:
class WangYiYunCrawl(scrapy.Spider):
name = 'WangYiYun'
allowed_domains = ['music.163.com']
# start_urls = 'http://music.163.com/discover/artist/cat?id={gid}&initial={initial}'
group_ids = (1001, 1002, 1003, 2001, 2002, 2003, 6001, 6002, 6003, 7001, 7002, 7003, 4001, 4002, 4003)
initials = [i for i in range(65,91)] + [0]
headers = {
"Referer":"http://music.163.com",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3067.6 Safari/537.36",
}
def start_requests(self):
pass
def parse(self,response):
pass
最前面的那一大段前面都有說過,就不再提,這里的headers是自己寫的,所以后面會調用到self.headers,只在settings.py文件里配置的這里可以省略,后面也不用用。
還剩allowed_domains。

首先講一下我之前一直困惑的地方:start_urls 和start_requests()可以同時存在,也可以只要一個即可。
如果你寫的是start_urls,那start_requests()這個函數可以省掉,直接在parse里對它進行處理,parse這個函數,就是爬蟲的主程序,平常怎么寫就怎么寫。
然后這個response,我們先來看代碼:
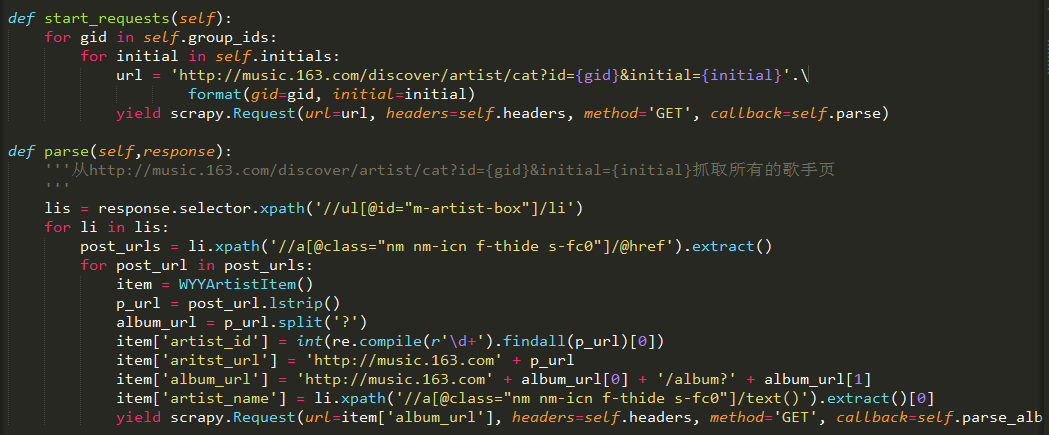
start_requests()這個函數在返回的時候,(對了,這個scrapy里返回用的都不是return,而是yield,迭代的意思),使用Request,可以看到它大多是和requests這個庫很像,它的作用也是一樣,返回是一個response,它特別的在于它最后一個參數,callback的值接的是回調函數,即你要把返回的response作為參數傳遞給哪個函數,這個函數后面不需要括號,所以一開始我也沒搞懂它是個什么。
另外,這里調用headers是因為我將headers定義在了這個class里,如果是定義在settings.py里,這里可省略。
之后的函數都是這樣,如果你要將什么參數穿到下一個函數,都可以用這個,而在回調函數里必須傳入這個response參數。
關于parse函數,
parse這個函數的名稱無所謂,但是最好帶上parse(許多scrapy類型的文章都這么用,一眼看上去就知道是什么),并且保證傳遞的回調函數參數和這個函數名稱一致即可。
三、parse函數
1、默認情況,scrapy推薦使用Xpath,因為response這個對象可以直接使用Xpath來解析數據,比如我代碼中的:
response.selector.xpath('//ul[@id="m-artist-box"]/li')
response對象下直接就可以用selector.xpath。當然,除此之外,還有一種使用xpath的方法:
from scrapy.selector import Selector
selector = Selector(response.body)
關于Selector的用法,可以參考:
http://blog.csdn.net/liuweiyuxiang/article/details/71065004
但是這種方法并不是特別方便,所以直接使用response.selector.xpath的方法就好。
2、關于xpath的格式,參考中文官方文檔吧,http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html。它跟lxml大同小異,但是還是有些區別,如圖,這是四種基本的方法:

它返回的其實都是數組,xpath不用說,然后最常用的就是extract了,這個返回的列表里都是文本,而不是Selector對象

它獲取的就是所有href的集合。
等價于BeautifulSoup這么用,只不過這個是獲取單個的:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.content,'lxml')
href = soup.find('a')['href']
然后簡單提兩個xpath簡單而常用用法:
@href:這種@后面加什么的,都是某個標簽的某個屬性,其他比如src也是這樣用。
text():這個就是獲取文本了。
3、
item = WYYArtistItem()
它就是那個對應某個爬蟲所對應的數據庫的字段,因為mongodb存儲的格式類似json,在python里它就是個dict,當它是個dict就可以了。
4、使用scrapy.Request它可以傳遞的不只是url,它也可以傳遞整個item,使用meta,例如
yield scrapy.Request(url=url,meta={'item': item}, headers=self.headers, method='GET', callback=self.parse)
然后在parse()函數調用的時候,
def parse(self,response):
item = response.meta['item']
但是并不建議這么用,因為很浪費資源。
另外,傳遞url的時候,除了用url,如果獲得的url這段直接存進了item里,也可以直接用item['url']:
yield scrapy.Request(url=item['album_url'], headers=self.headers, method='GET', callback=self.parse_album_list)
最最最最重要的一點是,如果要存到數據庫里,比如最后一個不用再Request了,那么一定要加上
yield item
這樣才能存進數據庫里,之前一直存不進去,一個就是前面忘了導入items,一個就是這里。
四、其他部分
后面基本都照這個模式來,因為我的順序是:歌手--專輯頁--專輯所有歌曲--歌曲,剛好每一個爬下來的url都可以直接傳遞給下一個函數,通過callback的方式。
這里最大的好處就是,比如歌手頁,不用爬下來存一個列表,然后到了下一個函數,再遍歷一遍這個列表,它每抓一個url,直接就能到下一個函數運行。
我運行的時候最大的一個問題就是‘yield item’那里,四個部分,它只存最后一個,搞得我一臉懵逼,后來想想大概要執行完這個,然后再把前面的改成yield item,才能都存進去。這個是一個很嚴重的問題。
所以最好就是在parse就是第一個地方就存,yield item,存完再改成yield Request再執行下一個函數。
代碼補上了,但是肯定有瑕疵,因為最后運行的時候我測試了一下成功了,但是關于存取有些無奈,就棄用了。
本文來自博客園,作者:蘇酒酒,轉載請注明原文鏈接:http://www.rzrgm.cn/sujiujiu/p/15371839.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號