


Scrapy爬取網易云音樂和評論(一、思路分析)
教程系列鏈接目錄:
1、Scrapy爬取網易云音樂和評論(一、思路分析)
2、Scrapy爬取網易云音樂和評論(二、Scrapy框架每個模塊的作用)
3、Scrapy爬取網易云音樂和評論(三、爬取歌手)
4、Scrapy爬取網易云音樂和評論(四、關于API)
5、Scrapy爬取網易云音樂和評論(五、評論)
項目GitHub地址:https://github.com/sujiujiu/WYYScrapy
很尷尬,csdn不允許發爬取類的文章然后都屏蔽了,然后重新發到博客園這邊了。
前提:
scrapy這個框架很多人用過,網上教程也很多,但大多就是爬爬小說這種比較簡單且有規律的,網易云音樂也有很多人寫過,也有API,不過大多是爬取了熱門歌曲,或是從歌單下手,但是考慮到歌單會有很多重復的。當然,從歌手頁的話,如果有多個歌手合唱,那每個歌手頁也都會有這首歌,但他們的鏈接是一樣的,也是會有重復的,但是相對來說就比較少,所以就從歌手下手。
在GitHub上也有很多優秀的例子,但沒有文檔,我這里寫一個整站的。
項目GitHub地址:https://github.com/sujiujiu/WYYScrapy
因為種種原因,我后來還是沒有用框架又寫了一遍。這一塊運行成功了,但是我沒有去關注數量就中斷了,就只能拿出來當教程吧。
- 開發環境:WIN7+Anaconda+py2.7+scrapy
- 數據庫:MongoDB
- 文章的順序:先分析思路,再分析scrapy框架每個模塊的作用,最后寫代碼和分析API,只有5篇。
之前有小伙伴問我為什么在已經出到3.x后期了我還要用2.7,其實是我當時學的時候在折騰2.7,就是懶。而且當時scrapy對py3很不友好,文檔也很有限,當然是后來才知道Anaconda這個好東西的。Anaconda2和3都有了,3能不能裝scrapy我不知道,還沒試過。如果你不想用2.7,可以先嘗試下Anaconda3裝一裝scrapy看看能不能裝成功,是哪個版本的。
一、我們先爬歌手,有兩種方法:
方法一:遍歷id
第一種是遍歷,id數大概十一二萬的樣子,大多id是相隔不遠的。
- 優點:遍歷比較方便,比較全。有個別歌手有主頁,但是沒有申請音樂人,只能通過自己搜索訪問id,用這種方式比較完整。
- 缺點:但是這種方式會有很多404,就需要你去處理。
但我最開始用的是下面這種,我們也拿這個來分析:
方法二:從分類獲取所有入駐的歌手的id
優缺點與方法一剛好相反。
- 優點:不用去做404處理。
- 缺點:獲取歌手不完全。分類里只有已經入駐的歌手,你仔細搜搜就會發現很多歌手的主頁只有一個收藏的標簽,卻沒有個人主頁的標簽。沒有個人主頁的都是沒有入駐、沒有簽約,或是歌是被別人上傳的,被歸類到該主頁下的。
1、從這個頁面,爬取所有歌手的id:http://music.163.com/#/discover/artist
這里要說一下,網易云的所有網址,要去掉中間那個#號才是真正的url,帶#的查看源代碼是獲取不到真正的信息的。所以正的url其實是:http://music.163.com/discover/artist 。
我們看這個頁面左側欄:

2、因為當時我寫的時候,參考到這篇,https://github.com/runningRobin/music163/blob/master/music163/spiders/spider.py
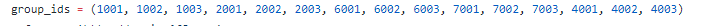
這個group_ids里的就是左側每個項對應所有的頁面了(不包括最上方的推薦歌手和入駐歌手,因為包含在其他里面了)
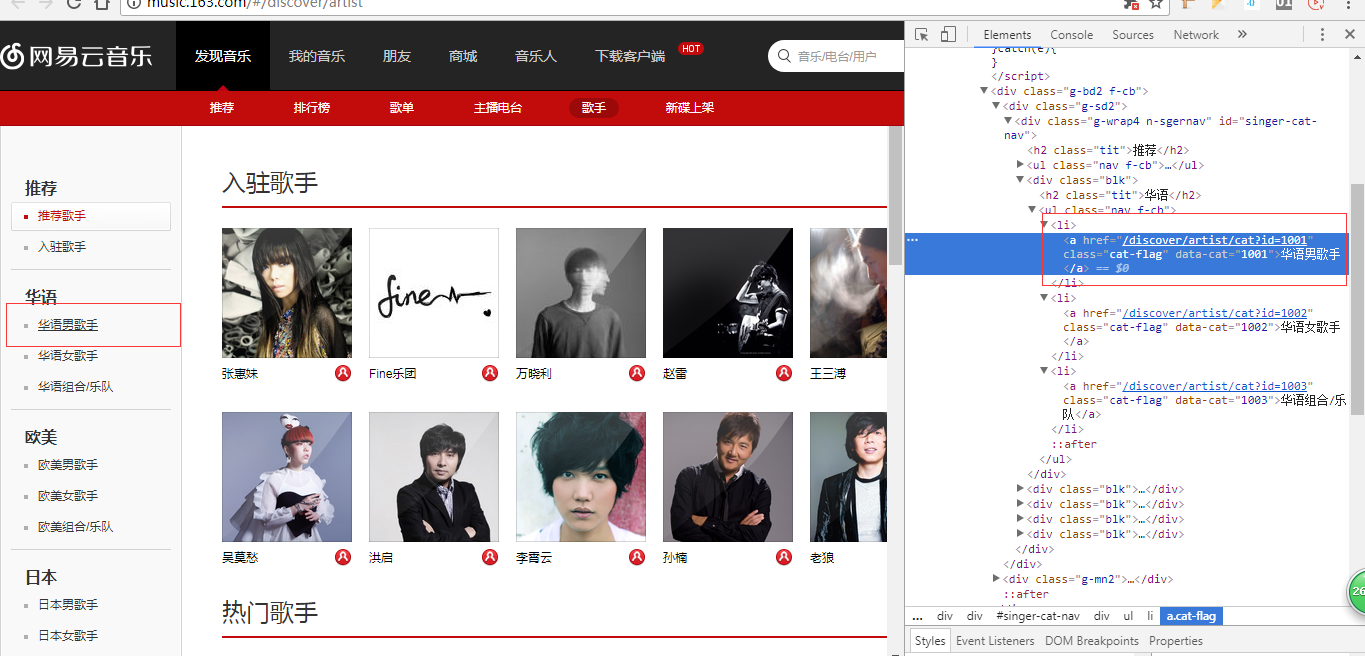
3、我們按F12或右鍵檢查,如圖,每個對應的url是:http://music.163.com/discover/artist/cat?id=xxx:
4、然后我們再點進去:
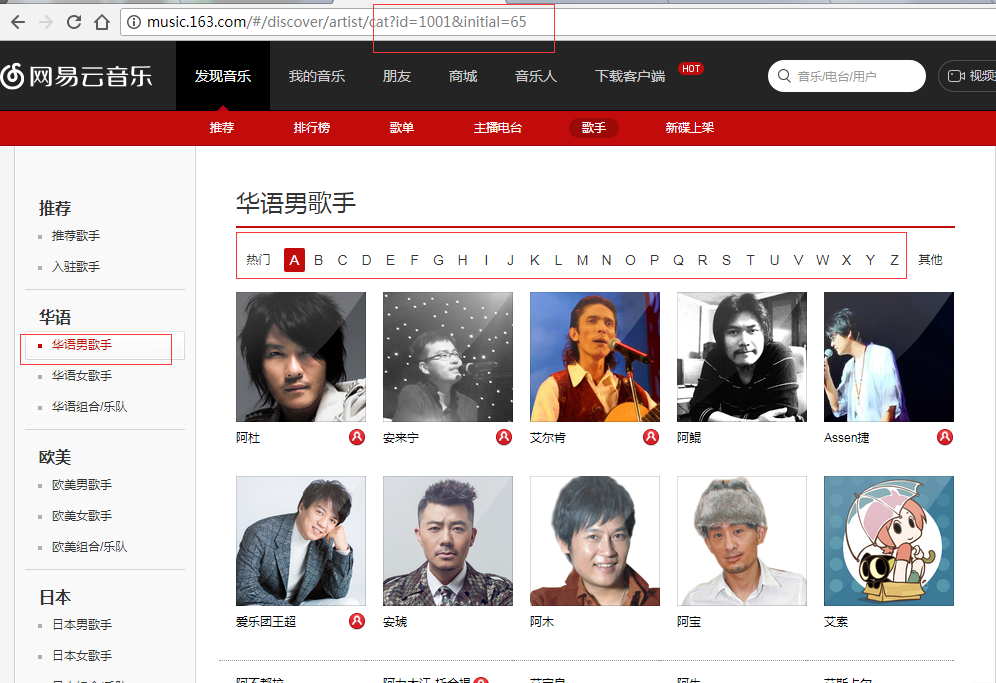
url的id就是上面這個id了,而后面的initial是什么呢?initial是首字母的意思,你看下面我們選中的是A,然后它是65,是不是想到ASCII碼,在ASCII碼中A就是從65開始的,Z是90,后面以此類推,最后有個其他,是0,我們將它弄成一個列表:
# 男女、國家分類id
group_ids = (1001, 1002, 1003, 2001, 2002, 2003, 6001, 6002, 6003, 7001, 7002, 7003, 4001, 4002, 4003)
# 歌手姓名首字母id
initials = [i for i in range(65,91)] + [0]
二、歌手頁
1、點進來之后我們來到歌手頁,http://music.163.com/#/artist?id=6452 ,同樣,去掉#
2、我們會發現下面有好幾個塊,

我們獲取的這個url對應的是熱門50首,如果你只需要熱門歌曲你可以獲取它所有鏈接:

這個代碼被我分為兩塊,第一塊是熱門50首的url,也只有url。
而第二塊textarea里是json,是這些歌曲的完整的信息,我獲取的是json信息,只不過,這些信息通過lxml.etree或者BeautifulSoup用text的方式獲取下來會是字符串,我們需要用json將它格式化,但是極個別在爬取的過程中,死活獲取不到。
3、上面那個是歌手的熱門歌曲,我們要獲取全站,就得從歌手的專輯下手,獲取專輯里所有的歌手才行。因為scrapy本身的束縛,其實說是全站,并不是那么方便,比如這四個板塊,我們只能選一個,一直往下,單曲或MV就得另寫。
4、我們在專輯頁會發現,有些是有很多頁的,后來搜的時候發現了API,所以接下來的東西,我們就不通過頁面的方式了。
API我是通過這個網站發現的:http://moonlib.com/606.html ,因為最開始我的目的是爬評論,來看到評論的API很多變了,我以為這些都變了,一開始還擱置了沒用,傻傻的去寫lxml,但是它的翻頁的序號是爬不到的,后來隨手測試了一下API,發現都有用。
我們用到的是2到6(不包括5,沒用到歌單),第7條接口是MV的,不過不幸沒有發現像專輯一樣的列表頁信息,它只有單曲的MV的API。
不過這里我們用不上,后面會專門分析API。
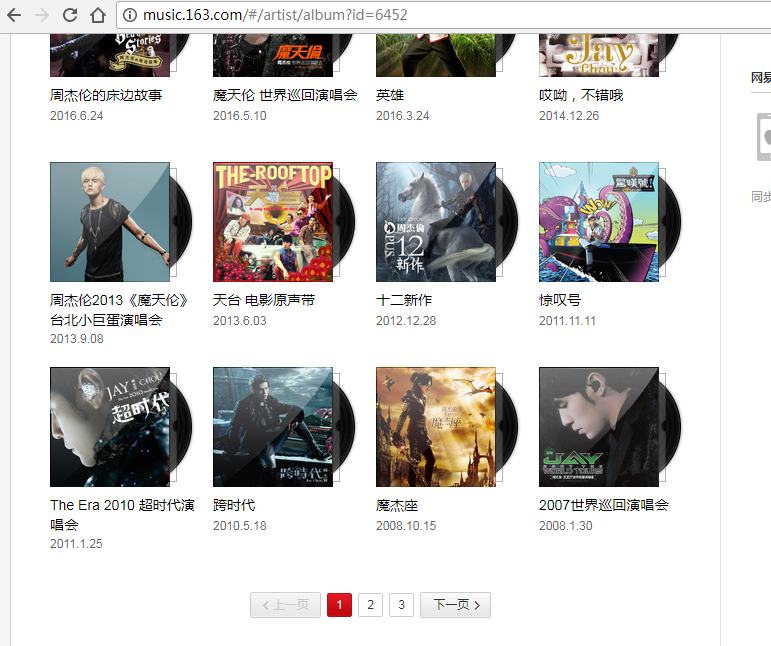
5、接下來就是每個專輯的所有歌曲還有專輯、歌手的一些信息,專輯下也有評論
6、最后就是歌曲頁了
好,思路就是這樣,接下來我們分析Scrapy這個框架。
本文來自博客園,作者:蘇酒酒,轉載請注明原文鏈接:http://www.rzrgm.cn/sujiujiu/p/15371824.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號