
轉自:https://blog.csdn.net/leonwei/article/details/105459382
在基于ue的手游開發中,經常會發現android系統的實際內存占用要比我們預估的高很多,優化內存的占用就要先明確究竟每1k實際的內存占用分布在哪里及如何運用工具有效的獲取真實的內存組成,本文將結合項目經驗詳細介紹這個部分,并據此分別介紹一些常用的瓶頸和優化。最終了解你的android程序中的每1k內存。
一、Android程序內存分配原理
Android內存管理基礎
Android內存的管理核心是paging和memory-mapping(mmap)。
Paging
Andoid系統中使用虛擬內存地址來索引內存,虛擬內存被劃分為固定大小的page頁,典型的頁大小為4K。內存分配最開始都是在虛擬內存上分配,當需要訪問這段內存的時候,如果發現它沒有存在于物理內存上(即MMU不能找到這個虛地址va對應的物理地址pa),即發生了缺頁(page fault),缺頁有幾種可能:
1. Bug,程序訪問了它不應該訪問的虛地址空間,android系統會觸發訪問不合法,kill掉進程
2. Va是合法的,但是這塊va對應的pa還從來沒有被分配出來過(例如你mmap的一段內存空間,但是從來沒用過,這時第一次在這塊內存上寫入),這叫做lazy-allocation,這時系統會真正分配一段物理內存給你用,然后在頁表上對應好這段pa和va。注意第一次寫入這里才算真正占用了物理內存,mmap的分配并不算。
3. Va是合法的,但是這va對應的pa內容當前并沒有在物理內存上,而是被swap到一個backup的file上,這時系統會給這個page在pa上分配物理內存,然后將這塊內容從文件讀回到物理內存上(swap-in)。
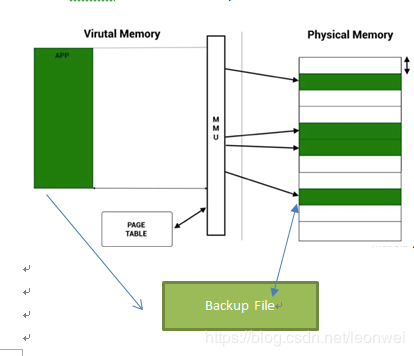
Swap和zram
典型的linux系統的虛擬內存都有swap操作,即一段物理內存在一段時間不用的時候,為了節省物理內存將他們備份到它的backup file上,一段時間后缺頁時再換回。
但是在android上大多數情況是沒有這套swap機制的,因為對于移動端的IO代價太大,所以大多數情況被映射到pa的page是不能被swap的。只有一種情況除外,即如果這段虛擬地址段具有backup file,并且當他被swap-in到pa后是只讀的,那么它是有機會被swap-out回disk的,因為swap這種內存的代價很小,他們不會在物理內存上被更改,通常這類情況包括那些代碼文件的mmap(如dex so等)。
此外android上還使用了一種特殊的ZRAM機制來壓縮一些物理內存上的page,但是并不把他們swap-out到disk上,而是仍然在ram中,這是一段被壓縮了的page,系統會選擇壓縮一些page存儲在內存中以騰出一些物理內存的占用。
MMAP
Linux上一個重要的特性是memory mapping。如上面所述,va和pa之間通過mmu建立了一個對應關系,通過page fault來觸發pa的分配,此外va還會對應一個backup file,作為swap-in/out時的備份存儲。這個va和backup file之間的對應關系就叫做memory mapping,我們可以利用這個機制做文件讀取。
Memory mapping的調用函數是mmap,它的原型是
void* mmap(void *addr, size_t length, int prot, int flags, int fd, size_t offset) void munmap(void *addr, size_t length)
addr為預映射的虛擬內存地址起始(傳null則讓系統給你分配)
length為大小 offset為偏移 prot為這段地址區域的保護方式: -PROT_EXEC(可被執行) -PROT_READ(可讀) -PROT_WRITE(可寫) -PROT_NONE(不能存取) flags代表為這段區域的各種特性: -MAP_FIXED:如果傳入是start地址不能成功建立映射,則放棄映射 -MAP_SHARED:對映射區域的寫入會復制回它的backup文件,而且允許其他進程共享對該文件的映射 -MAP_PRIVATE:對映射區域的寫入會產生一個backup文件的復制,且這個區域的修改都不會再寫回backup文件(shared和private必須二選一) -MAP_ANONYMOUS:匿名映射,忽略文件fd參數,且映射區域不能和其他進程共享 -MAP_DENYWRITE:只能寫入映射的內存,不能直接寫入文件 -MAP_LOCKED:鎖定映射區域、,說明該段不能被swap
它有兩種用法:
第一種是映射文件到內存做讀取, 這時提供一個文件句柄,然后將文件內容映射到一段虛擬內存地址空間,這樣就做到了通過訪問虛擬地址空間--造成缺頁—swapin backup file的方式來根據需要讀取文件。他相比傳統的文件讀取效率更高。
第二種是創建一個匿名映射,匿名映射沒有backupfile,只是單純分配一塊虛擬內存空間,這其實是android上調用new一個對象做的事情,我們new一塊int的數組,事實上在new后很可能是通過mmap分配了一塊虛擬內存空間,而只有當第一次寫入的時候才觸發缺頁而占用真正的物理內存,所以統計android的物理內存占用不是看new了多少,或者文件映射了多少,而是實際上虛擬內存缺頁了多少。
MMAP和new malloc
我們知道我們可以用new創建對象,new里面就是用的malloc/calloc等分配內存空間,那么malloc和mmap之間是什么關系呢。首先new 和malloc是c++/c語言層面的事情,實際在類linux的操作系統層面,給用戶提供的申請內存的函數只有brk/sbrk和mmap函數。
如下圖典型32位系統中一個進程的虛擬地址空間分布狀態,sbrk的作用就是擴展heap部分的上界,可以傳入一個分配的大小,并返回新的brk地址。
Malloc函數當申請小內存時使用sbrk來分配內存,大內存則使用mmap申請,如果是這種情況,這時的malloc并沒有申請物理內存的占用 。但實際上大部分malloc的實現都會在操作系統內再維護一個內存池,它會預先申請一塊較大的連續內存復用,最終都是走的mmap。

二、 Android程序的內存構成
有了前面的android的內存管理的基礎知識,這里談下android進程的內存組成
從adb meminfo說起
當我們運行adb shell dumpsys meminfo xxx.xxx.xxx的時候將得到一份最簡單的android程序內存報告,這里面的pss+swap的總量也是我們android內存統計的金標準。
一個典型的adb 內容如下

這里面可以看到pss privatedirty privateclean swapped diry 這幾個重要的指標
這里能看到的所有值都是物理內存大小,即缺頁的那些虛擬內存的大小,而不是真正虛擬內存的大小,注意這里看到的所有內存大小都是真真實實占著你的物理內存的(比如我隨便new 1個int[1024],在你對這塊內存寫入之前它都不會占用物理內存并體現在這里。)
PSS是指proportional set size,是指你的進程實際占用的物理內存大小,但是android內存涉及到在系統中同其他進程共享一部分庫(可能是so,可能是字體文件等的mmap),所以這里面會考慮這個因素計算你的進程平攤的這部分共享庫的大小,這里的p就意味著統計了這個平攤后的物理內存。這是衡量進程占用內存的最真實指標。
Private Dirty和Private Clean則是完全該進程自己(而不包括和別人共享部分)占用的物理內存,clean是指那部分可能被swap的內存部分(即前面說到的擁有backup文件,mmap之后一直保持只讀狀態,他們具有被swap out的可能,比如你的so庫文件。),而dirty部分就是除clean之外那些不能被swap的內存。Private Dirty通常是你的進程內存最需要優化的地方,因為他們是大頭。
Swapped Dirty指的并不是被swap-out出去的內存,而是android系統中zram機制壓縮掉的部分Private Dirty部分的不常用物理內存,這個重要度等同于Private Dirty,因為哪些Private Dirty會被壓縮不能被控制,所以這部分多通常也是Private Dirty 的。
因為PSS中已經包含了Private Dirty和Private Clean,但是沒包含swapped dity,所以最終衡量你的進程對物理內存的占用應該是取PSS+Swapped Dirty
下面則是按照各種category分別統計的內存值,仍然很有意義。
Native Heap:這是C/C++層直接通過malloc分配的內存,在UE的框架中你幾乎不會在ue代碼中分配到這部分內存,因為UE的所有malloc都統一走了UE的內存管理機制FMalloc,而Fmalloc的底層使用的mmap。所以當你看到Native Heap存在數值較大,一般只有幾個大的可能:除ue之外引入的其他第三方庫,以及一個很大的大頭gles的driver在client內存一側的分配。這部分的內存通常普遍較大,且剖析比較復雜,在非root的android機幾乎很難用正常的方法hook到,是很多UE手游內存分析人員的盲區,這部分profile我們后面詳細講。
Dalvik Heap/other:這是android的java虛擬機分配的內存,也就是java部分分配的,ue基本不直接寫java層代碼,所以大的話多數是接入的第三方SDK分配的,這部分可以很容易的用android studio的memory profiler看到分配堆棧。
Stack:很好理解棧分配內存
Ashmem:進程的匿名共享內存 Anonymous Shared Memory ,通常不會很大,和操作系統有關系
GFX dev:通俗來說是你的顯存,android 顯存和內存在同樣的物理設備上,所以統計的總內存是包括顯存的,至于adb如何知道哪些是顯存,是因為gles和egl的so庫在分配顯存的時候也是使用的帶backup文件的mmap,adb只是簡單的統計了所有gles和egl的mmap將其視為顯存,這部分通常就是在gpu上的資源,gpu上的資源由很多種,占大頭的就是texture,buffer,shader programe,這個是所有游戲的大頭,后面也會詳細講這部分的profile。
Other Dev:除顯卡外所有其他硬件設備的mmap后的物理內存,可能包括聲卡等,通常不多。
.so mmap:這個就是so庫本身文件mmap占用的物理內存,我們隨著游戲進度會逐漸的讀取我們的so文件,造成和缺頁的部分就是在物理內存產生占用,這部分大就是so庫太大了,但是這部分因為有很多是readonly的mmap,所以有更大的機會被swap-out出去。
.apk .dex oat .art mmap:這些都是android 程序文件本身被mmap占用的內存,和so的性質差不多。
Other mmap:是所有除了上面的之外其他的所有非匿名方式的mmap,想要知道是什么可以通過下面要講的命令查看。
Unkonwn:在UE程序中這部分通常是最大的一塊,在meminf中它指所有的匿名mmap,因為是匿名的,所以meminf不知道是什么,就統計在unkown中,用匿名映射做的mmap基本就是mmap方式的內存分配,在ue中ue自己的Fmalloc系統使用的就完全是mmap方式的內存分配(改成ansi方式除外),所以這里的unkown內存基本等同于UE的fmalloc的內存,就是你的ue程序分配的內存。看,通過ue的fmalloc的內存其實只占整個android進程內存的一部分而已,我們通過ue的llm_full等跟蹤到的內存其實只是這個unkown內存的部分。
RSS 和 VSS
上面說的是PSS的統計,其實還有兩個口徑的內存統計,RSS和vss
通過adb shell top可以查看所有進程的rss vss信息。
RSS即resident set size,它表示該進程本身除了和別的進程共享部分實際占用的物理內存,即比pss小一些。
VSS則是值改進程分配的虛擬空間大小,這個值通常意義不大,因為理論上你的虛擬空間可以分配的很大,比如你要mmap很多的文件,但是并不代表你要同時訪問這些文件在物理內存上。
了解android的每1k內存 -- 查看進程完整的虛擬內存空間映射情況
到這里為止我們知道了使用簡單的adb指令查看android的內存組成,那么adb meminfo又是根據什么統計出來了呢,其實可以去查看adb meminfo的代碼實現,它基于了更詳細的虛擬內存映射信息。
通過指令adb run-as xxx.xxx.xxx cat /proc/pid/smaps 可以查看到當前整個進程的虛擬內存映射情況,即每1k物理內存是在哪里發生的。如下表是其中的一部分
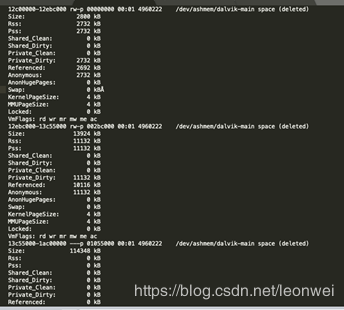
這里面詳細記錄了你的進程的每一塊虛擬地址空間的分配情況,如圖中的第一個block中,說的是12c0000-12ebc000這塊連續的虛地址空間,它的大小是2800K(虛擬地址大小),它也映射的物理內存RSs和pss都是2732kb,后面的ashemen說明它是一個匿名共享內存,最終會被統計到adb meminfo的ashm中 。
這個文件很大,很詳細,我們還可以得到一個更簡要的信息,通過命令
adb shell run-as xxx.xxx.xxx pmap pid –x 可以得到規整成下面的一個表
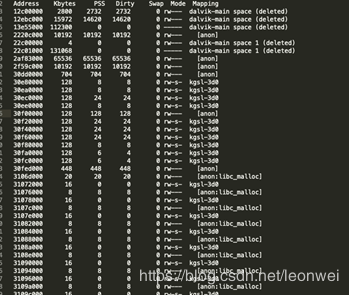
這個表更容易看,分別列出來虛擬內存其實地址,大小,映射的pss物理內存大小,內存屬性,以后后面的mapping的來源。
從mapping的來源我們可以簡單推測這個內存的創建來源。例如有這么些可能:
如果看到dalvik-main,那它一般是java 虛擬機的native 分配,這個最終會被統計到meminf的dalvik里。
Anon:這個就是匿名mmap映射,最終會被統計到meminf的unkown里,這個在UE中就是所有的Fmalloc
Anon:libc_malloc 這個是通過malloc方法進入的mmap,即你所有的new ,malloc調用,在ue里面這個基本就是第三方庫的malloc分配,當然還有一個大頭是gles 的driver的malloc分配。
Kgsl-3d則是gles對顯存硬件的虛擬內存映射,換句話說就是顯存,meminf正是統計這個標簽來獲取gfx的大小。
在后半段還會看到**.SO,這個不是說這個so分配了多少,而是這個so文件本身在虛擬內存映射后缺頁的物理內存大小,即so文件被當前讀入到內存上的大小,這個會動態改變,因為程序對so的訪問也是動態的
還有***.ttf,這個就是對ttf字體文件的讀取,同so的讀取一樣。
可以看到,其實adb meminf也是靠這個pmap映射算出來前面那份報表。
根據這個映射清單,我們基本可以先大致一眼瞄出程序的主要內存占用在哪。作為UE手游,通常你要關注的是
Nativeheap(主要是gl的driver和第三方庫,會很大,你的圖形資源是否太多)
GFX(顯存,貼圖,buffer,shader,你的圖形資源是否太多)
Unkown(UE中的fmalloc)
So mmap(So庫是否太大)
當然從這里還是不能給出一些指導意見,所以我們需要再詳細分解這些內存的使用,因為我們基于了UE4引擎,所以我們還有更多的手段。
1.UE程序的完整內存組成
因為在UE引擎內部的內存分配和釋放望去可以在引擎層hook住,所以UE引擎范圍內的內存使用我們是可以詳細的追蹤細化的。在引擎層我們能hook住的內存分配主要來自兩塊:
通過FMalloc對內存的分配。因為UE用fmalloc承接了所有new/delete,所以通過在fmalloc這層去hook,可以抓住這些分配。另外malloc底層又通過mmap去分配,等于通過追蹤UE的fmalloc可以追蹤整個android內存的Unkonw部分,即匿名mmap映射部分。
通過對graphic api的調用而觸發一些gpu資源的創建。例如通過一個glcreatexxx可以創建某個顯卡資源,整個過程會產生driver的開銷即gpu上顯存的開銷,在很多平臺我們不太可能準確的查詢到這里面多分配了多少內存,但是至少可以根據資源估計出在顯卡上的顯存開銷。這個顯存的開銷就對應了gfx部分。
所以在ue的引擎內部我們有可能容易的細化上面說的Unkonw和GFX部分。而UE引擎為我們提供了這個機制,即LLM(Low Level Memory Checker)
2.1LLM
LLM通過插入各種tag來將所有待統計的內存劃歸到某個tag下。通過維護一個tag的堆棧,將fmalloc到的內存統計到當前棧頂的tag下。Llm在最底層hook了fmalloc的每一個統計,如果沒有任何tag在當前棧中,那么所有內存計入在untagged這個tag下,如果我們在代碼中插入一個基于scoped的tag,就可以把這個scope下的內存計入你的tag下。通過LLm我們不會遺漏任何Fmalloc分配的內存。
此外程序剛初始化的時候,LLM會記錄一個內存,被它估計為可執行程序本身的內存,記在Program這個tag下。而rhi每個對于gpu資源的創建也會被LLM記錄在額外的texture,buffer等標簽下,他們不是fmalloc內存的一部分,是對GPU的內存占用的估算。
LLM的類型
LLM主要分兩種,即兩種統計口徑,分別為default和platform,他們是兩個維度的統計。
LLM基于代碼中定義LLMTag來偽每個內存打標簽,一個tag要至少包含類型名,組名,可以通過查看LLM_ENUM_GENERIC_TAGS這個宏來看所有的tag。
一個tag要么屬于default的統計范疇,要么屬于platform的統計范疇,這個可以通過查看DECLARE_LLM_MEMOPRY_STAT這部分代碼來判斷屬于哪個口徑。
default和platform的tag會同時設置,也就是說default和platform會同時統計每個內存的使用,每個內存都會被default和platform的某個tag同時抓到。
default-統計和平臺無關的內存
(即無論到哪個平臺上,default的內存都是差不多的)
通過stat LLM和stat llmfull 可以看到詳細的統計。前者是按大組去統計的,后者是細分的。主要的統計項目包括:
platform-統計和平臺相關的
通過stat llmplatform可以看到詳細的統計,主要項目包括

可以看到上面一些tag是存在交叉的,例如platform口徑下的fmalloc實際上包含了default下面的很多tag的和。
之所有有這樣兩個口徑是方便我們從不同維度理解內存的組成,platform的維度和機型平臺相關,default則和平臺無關。當然無論哪個維度,加起來的總和是一樣的。
怎樣打開并使用LLM?
1.默認dev debug 包才開啟,如果在test包開啟,則需要設置宏ALLOW_LOW_LEVEL_MEM_TRACKER_IN_TEST= 1
2.需要連接調試器啟動,例如xcode或者android studio
3.加上啟動參數 -LLM
4 如果啟動參數帶上 -LLMCSV 則會定期將結果自動保存在磁盤為csv文件。
5.帶上啟動參數 -LLMCSV可以寫到csv里面
運行時,輸入指令stat LLMFULL 和stat LLMPLATFORM 分別看到default和platform兩種統計口徑的結果
2.2 構建你的UE程序的android內存清單
在對一個基于UE程序的android進行內存剖析的時候,第一件事情一定是生成一個報告,這個報告可以說明總的pss的每一k分別分布在哪里,這才是解決一切問題的前提,不然都是盲猜。
在這里我們需要試圖整理出一個完整的UE程序的內存清單。
從最前面我們知道Android內存從meminfo上來看可以分為
Nativeheap
Davik
Gfx
.so/.dex/.oart map…
Unkonw
而UE的fmalloc采用匿名映射,基本代表unkonwn的部分,而且ue還估計了tex buffer的顯存,可以認為代表了大部分的gfx。而LLm肢解了fmalloc和顯存這部分。
所以可以認為用llm我們首先就分解開了gfx的大部分和unkonw的全部。
那么然后是其他的幾個部分,需要我們自己做點工作了。
NativeHeap部分
這部分是所有通過malloc分配的內存。UE內部的任何內存分配都不在這里,那么這里主要是什么?主要是其他任何第三方so通過malloc獲取的內存,事實上ue內部也可能存在某些插件不走統計的fmalloc而是直接malloc系統內存,那么也會進入這里。這其中最大大頭的一個so通常就是那個叫做libgles***.so所分配的,它代表顯卡driver在driver層分配的內存(注意不是顯存)。
這部分內存通常很大,怎么分析。我們需要把這部分內存的分配hook到。
如果是root的版本(或者是非root但是android10以上版本)你可以參考這個文檔https://source.android.com/devices/tech/debug/native-memory上的一些方法,包括其中介紹的malloc debug,perfetto等方法,強烈推薦的是android-10以上可以用的perfetto,如果是任意一臺一些低端機,那么就只能采用一些hack的方法。我推薦一個開源的項目xhook https://github.com/iqiyi/xHook,是通過 PLT (Procedure Linkage Table) 的技術hook住任意函數的調用,當然就包括malloc。
在筆者的項目中集成了這個xhook,然后我hook住所有so的malloc,relloc,calloc,free。就可以拿到每個so的native heap的分配,他們的和就等于這個nativeheap的值。
一個典型的UE手游的nativeheap的分解值可能是這樣的:

轉存失敗重新上傳取消
不出意外gles相關的so會是絕對大頭,它是顯卡的driver部分(我們后面分析顯存的時候在細講),另外我們看UE4本身也會有走非fmalloc的代碼,是其中的某些plugin。
除了可以通過這種方法拿到每個so占用的nativeheap,還可以自己寫些代碼拿到具體這個so的nativeheap分布在了那里。例如我想分析gles的driver占用的這125M內存是從哪來的,有的人說gles的driver是顯卡driver決定的,我們無法介入,確實這里是一個黑盒,但是所有的driver內存分配究竟還是你的每一個gl api調用而產生的,通過在你的每個glapi調用前后打tag,你還是應該能夠統計到這些內存究竟同什么樣的api調用相關,你就知道該優化什么。
例如筆者在項目中在所有的gl api前后打一些tag,來分段統計這個hook到的gles的nativeheap,可以非常精確的拿到幾個大戶對driver的內存分配情況,例如tex,buffer,shader的創建。此外我們甚至還可以結合具體邏輯再細分tag,拿到具體哪些類型的buffer更占顯卡driver等等。
GFX和顯存相關部分
顯存通常是一個UE程序的絕對大頭。在Android程序中,顯示相關資源需要的內存包括:
A CPU游戲引擎測需要對應的結構
B Meminfo上GFX部分的顯存
C Meminfo上面的GL Mtrack
D Meminfo上面的EGL Mtrack
E 顯卡driver分配的
其中A包括為了創建貼圖,buffer等在cpu這邊的結構體,原始數據等,已經被LLM統計了,他是內存的部分,相對好追蹤,就不討論。
B出現在adb meminfo上,是我們常規意義上稱為的顯卡訪問的存儲資源,顯存。它的統計方法是統計pmap中顯存mmap映射文件(adreno上是kgsl-3D0這個文件)的pss部分。
C 這一項只有較新的設備有,因為android上顯存的管理和內存不一樣,不是采用虛擬內存映射,缺頁后再調入物理內存,而是虛存vs有多大,就直接為其分配多大的物理內存。所以很多老的系統只統計B而計算出的總PSS其實是要比真實物理內存占用要小的。而GL Mtracker這個項正是統計了那些pss映射為0的部分的vss大小。所以這個加上B才是真實的顯存大小 ,如果你的android系統不統計C,那么可以自己去pmap里面累加。
D 這是EGL分配的硬件資源,因為一些顯示資源不是gl分配的,例如backbuffer是系統從窗口系統中分配的,這屬于egl的分配范疇。一些老的系統沒有統計這個。
E opengl是一個client-server架構,server指的是顯卡那部分,client指的就是CPU這側的dirver部分,很多顯示資源不只需要在server部分對應顯存分配,同樣需要消耗大量的client部分的driver內存。例如去創建一個新的glbuffer,不管這個buffer實際上有多大,筆者在一些adreno機器上測試它在driver這塊都需要分配固定的4096+284k的內存,因為driver內部要維持一個渲染狀態和結構。例如去map一個glbuffer,那么driver這邊通常是需要malloc一個這個glbuffer大小的buffer出來,用來接受你對map結果的寫入,driver在合適的時機再同步給server那邊的glbuffer。所以gl的driver部分的內存是不可忽視的一大塊,它就是我們前面將的那一節的nativeheap的gles的部分。
很多老的機器系統因為不統計C和D,會導致pss看起來比實際小很多。
A在llm中有,E在nativeheap中獲取,這里面我們還不能拿到準確組成的是BCD,即真正顯存上的那一部分,但是如果我們看gl文檔,gl資源的組成主要就包括以下幾種:texture,buffer,shader和program,sampler,queryobject。而大頭主要就是texture,buffer,shader和program。所以我們可以推測。事實上在UE里面已經對texture和buffer進行的推測。
在gl每次創建tex和buffer的最底層,UE都加了一個hook,根據當前tex和buffer的屬性推測了程序實際使用的tex和buffer大小,我們通過指令stat rhi,可以看到ue推測的各種類型的tex和buffer內存。那么bcd三項的和減去ue推測的tex和buffer,就只剩下shader和program的內存了。
這里我們對顯存可以拿到完整的清單。當然對于bcd三項我們還有其他方法,例如截幀軟件可以截取當前所有存活于顯卡的渲染資源,包括看到所有的tex,buffer,shader,也可以用來輔助定位哪些顯示資源占了更多。
.so/.dex/.oart map…
這部分是程序代碼文件本身的mmap部分,在游戲過程中,隨著隨游戲代碼文件的讀入,而導致缺頁分配物理內存,如果項目這個很大,要考慮對so文件瘦身。
Dalvik
這是java虛擬機部分分配的內存,因為我們幾乎不會寫java代碼,所以基本不大,另外也可以輕易的用android studio的profilor分析到這部分內存的產生。
你的內存組成清單
下面我們就可以專業的拿出一個完整的UE程序在android上的內存組成清單,它應該看起來包括這些主要內容。

在正常情況下這里面的子項加起來應該基本等于total部分,如果有明顯出入,就要再具體分析出入在哪里了。
當我們拿出了這樣的一個清單,一個UE程序在android上的內存瓶頸會非常清晰,然后下一步就是去優化這些瓶頸了。
3 UE程序常見的內存瓶頸和優化
這里會對應上面一節給出的內存組成清單,來簡要說下可能會成為瓶頸的地方及其常用優化方法。
貼圖的顯存
最有效的方法是砍美術!是的,如果程序的占用顯存過大,多少都涉及到過量的美術資源。
當然除了砍美術之外,還包括合適的貼圖壓縮格式和質量,貼圖的合并減少貼圖的張數。我們經常以貼圖的尺寸,格式來估計貼圖占用的顯存大小,但是實際上這是個理想情況,實際上在很多硬件上,最終一個貼圖對顯存的占用還要受很多因素,例如,內存的對齊。筆者曾經在一個snapdragon660的機器上實測過幾種不同格式分辨率貼圖的實際對顯存pss的占用。

大多數情況實際的pss都要比ue估計的更多。這里面似乎存在這樣幾個規則:
對于astc6*6 4*4,顯存的實際分配情況比預估多,猜測至少對于adreno存在astc圖像按照16個block對其的情況(因為如果按照16個block對齊計算則同實際pss值一致)
16block對其的情況存在一些基礎開銷:
開了mip的貼圖:28k,因低級mip也須補足最小16 block
同壓縮大小不成比例的貼圖:astc8*8最適合128 倍數的貼圖
astc6*6最適合96倍數的貼圖
astc4*4最適合64倍數的貼圖
同比例差很大的貼圖會產生對其開銷,例如1024*1024的帶mip的貼圖在astc6*6下比預期要多86k(14%)。
所以我們要盡量選用和你壓縮質量最匹配的分辨率,并且因為每張帶mip的28k的基礎開銷,能合并貼圖盡量合并是能減少內存大小的。
當然為了更貼合實際使用情況,可以修改ue的估算公式。
此外合理的加載,gc,緩存,texturestreaming的使用都是貼圖的優化策略。
Buffer的顯存
和貼圖一樣,要先考慮過量的美術資源使用,除此,還要考慮到:
是否引入了沒使用的attributer,如uv2,color
是否用了過多的instance合批造成的instance buffer等。
此外statimesh的streaming也可以考慮打開。
Shader和program的顯存/內存
shader變體是UE的一個老大難問題,在大型項目中,幾乎都存在變體爆炸的問題,事實上筆者的項目在shader這塊曾經累計摳出來過不下200M的內存。這里面可能需要考慮的策略包括:
盡可能減少母材質,減少對母材質管線屬性的的overrider(例如overide它的blendmode就等于新出一個ps)
減少材質可使用的vertexfactory
減少顯示的定義更多的materialshaderd模板類型
在materialshader的shoulcompile里面做更多更細致的裁剪,去掉不可能的組合
只加載當前qulitylevel的材質
除了減少變體外,ue中默認永遠不會清理已經編譯的shader和programe,這會導致你的程序越跑這部分內存越高,到達一個峰值,可以考慮使用LRU動態卸載一些不用的programe,考慮在shader被編譯到programe后及時卸載,尤其是使用binarycache的情況下,其實根本是不需要編譯glshader的,programe完全從binary生成。
另外包括推遲shader和programe的編譯階段,ue默認在initrhi階段就編譯glshader了,但其實很多情況這個shader根本從來沒被用來attach glprogram。
由于ue內部完全沒有考慮對glshader的卸載,所以這塊需要自己改造一下。
Gles的driver
如果跟蹤gles的native的分配情況,會發現這里面的大頭還是tex,buffer和shader的相關操作。一些較常見的問題包括:
創建任何一個glbuffer,在很多機器上都存在一個4k左右的基礎開銷,無論這個buffer多大,而如果你的游戲使用了大量的buffer,尤其是你用了大量的ubo,你會發現你的ubo真正的顯存加起來可能只有幾k,但是在driver層用于管理他們的結構內存已經高達幾十M!所以一定不要使用大量散裝的ubo,你應該嘗試使用ue的emulated ubo,或者自己合并全局的ub,并用double buffer去管理cpu和gpu的訪問沖突。
另外包括長期的mapbuffer也會在driver分配內存。
此外也可以嘗試ue中分開存放的頂點的attribufer buffer,但是pos buffer因為tbdr的問題還是盡量單獨存放。
Uobject
減少數量和減少屬性。通過將場景中的物件整合成hism后發布,是可以大大減少uobject的總量的,此外通過objlist dump出每個類型的uobject的數量和內存后,針對性的刪掉它們中沒用的成員變量
Malloc unused
這是一個躲不掉的內存開銷,因為ue的bin式的內存管理會將所有的內存分配按照固定大小對其從整個page中分配。這個過程至少就存在這樣兩種浪費:一個是內存的對其浪費,一個是頁的空白浪費。避免這個問題,有幾種思路:
總的內存分配減少,這部分內存就自然成比例減少。
做好內存對齊,找到那些對其不良的部分,我們可以hook malloc的底層,發現這樣的地方
減少內存分配的次數,頻繁程度,尤其是短期內的大量分配,它會容易分配大量page,雖然后面內存被釋放,但是dirty page已然被撐大而不能有效回縮,造成大量的unused 內存。這里面的重災區又常見在tarray的頻繁resize,可以hook一下所有因tarray的reize導致的內存分配去優化它。如果是renderthread,通常可以用fmemstack,sceneallocater的array來避免頻繁的直接內存分配,至于rhithread也有類似于rhicmdlist.alloc這種優化的內存分配方式。
Lua
包括合理的設置lua的gc參數,gc的步長,閾值等,防止lua到了較高內存才執行gc。此外如果是大量的配置表導致的lua內存則要考慮用其他方式代替,如sqlite。
代碼的so map
除了減少我們的代碼量之外,還要strip掉so的符號,以及不去編譯一些用不到的UE特性,plugin等。
Assetregistry
如果資源量太多,會發現assetregistry,包括fname等都會占用較高的內存,除了我們盡量減少cook清單外,還可以考慮關閉assetregistry,不會對游戲性能造成什么影響。
總之,工欲善其事必先利其器,發現問題->分析問題->解決問題的最前面應該是找到發現問題的方法論并制作發現問題的工具,而這正是本文想著重講述的。
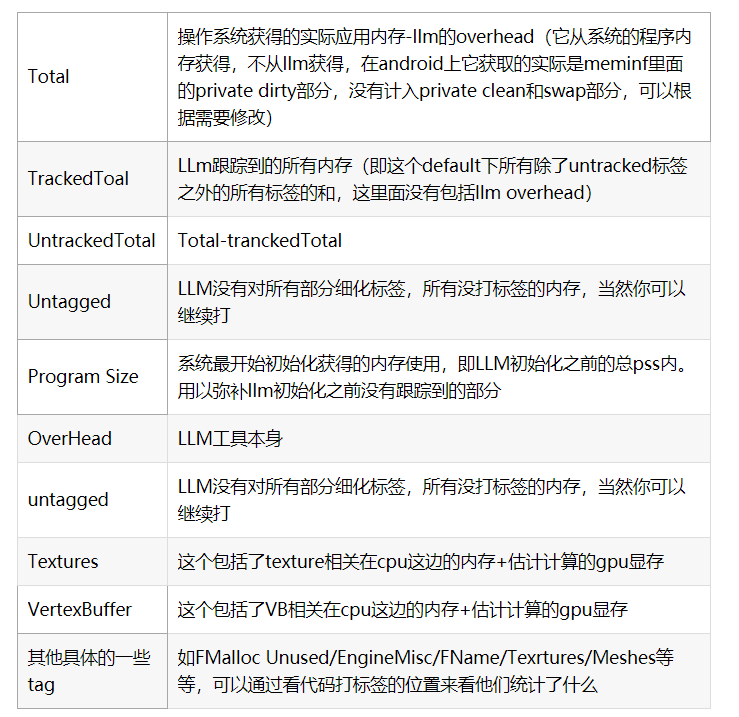
Total
操作系統獲得的實際應用內存-llm的overhead(它從系統的程序內存獲得,不從llm獲得,在android上它獲取的實際是meminf里面的private dirty部分,沒有計入private clean和swap部分,可以根據需要修改)
TrackedToal
LLm跟蹤到的所有內存(即這個default下所有除了untracked標簽之外的所有標簽的和,這里面沒有包括llm overhead)
UntrackedTotal
Total-tranckedTotal
Untagged
LLM沒有對所有部分細化標簽,所有沒打標簽的內存,當然你可以繼續打
Program Size
系統最開始初始化獲得的內存使用,即LLM初始化之前的總pss內。用以彌補llm初始化之前沒有跟蹤到的部分
OverHead
LLM工具本身
untagged
LLM沒有對所有部分細化標簽,所有沒打標簽的內存,當然你可以繼續打
Textures
這個包括了texture相關在cpu這邊的內存+估計計算的gpu顯存
VertexBuffer
這個包括了VB相關在cpu這邊的內存+估計計算的gpu顯存
其他具體的一些tag
如FMalloc Unused/EngineMisc/FName/Texrtures/Meshes等等,可以通過看代碼打標簽的位置來看他們統計了什么————————————————版權聲明:本文為CSDN博主「leonwei」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。原文鏈接:https://blog.csdn.net/leonwei/java/article/details/105459382

 浙公網安備 33010602011771號
浙公網安備 33010602011771號