
jemalloc思想的極致演繹:深度解構Netty內存池的精妙設計與實現
內存分配
Netty內存池的核心設計借鑒了jemalloc的設計思想。jemalloc是由Jason Evans在FreeBSD項目中實現的高性能內存分配器,其核心優勢在于通過細粒度內存塊劃分與多層級緩存機制,降低內存碎片率并優化高并發場景下的內存分配吞吐量。
Netty基于jemalloc的多Arena架構實現內存池化,每個運行實例維護固定數量的內存分配域(Arena),默認數量與處理器核心數呈正相關。此設計通過多Arena的鎖分離機制,將全局競爭分散到獨立的Arena實例中。在高并發場景下,當線程進行內存分配時,僅需競爭當前Arena的局部鎖,而非全局鎖,從而實現近似無鎖化的分配效率。
線程首次執行內存操作時,通過輪詢算法動態綁定至特定Arena,該策略確保各Arena間的負載均衡。同時,Netty采用線程本地存儲技術,使每個線程持久化維護其綁定Arena的元數據及緩存狀態。這種設計實現三級優化。
1)無鎖化訪問:線程直接操作本地緩存的Arena元數據,消除跨線程同步開銷;
2)緩存親和性:內存塊在線程本地存儲中形成局部緩存,提升處理器緩存命中率;
3)資源隔離:各Arena獨立管理內存段,避免偽共享問題。

內存規格
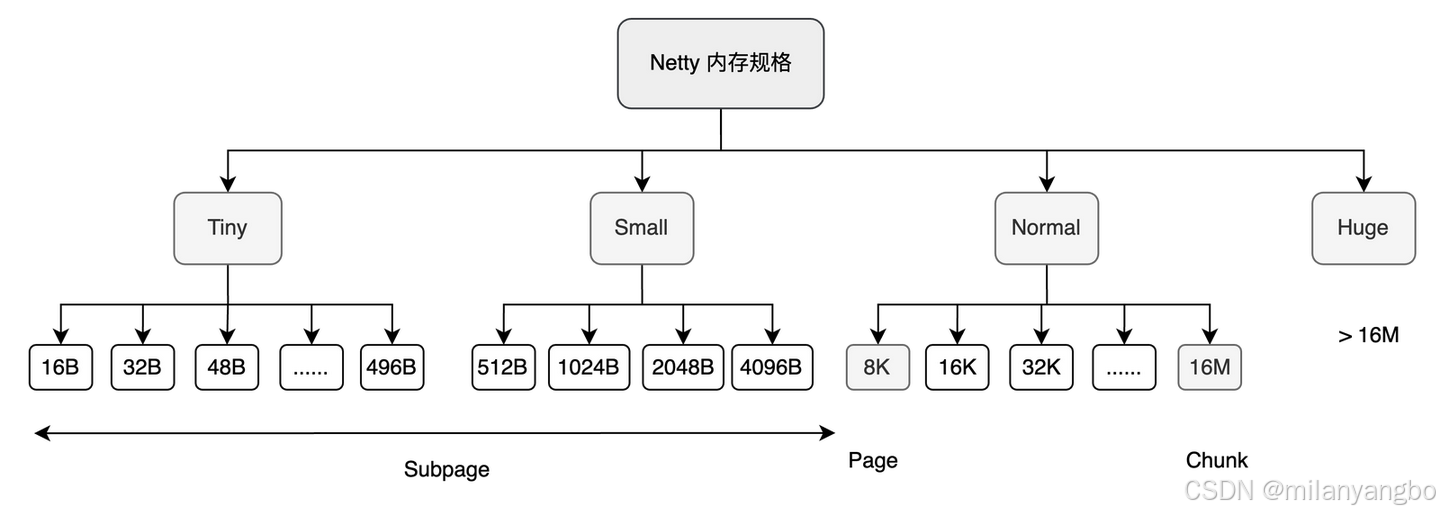
Arena中的內存單位主要包括Chunk、Page和Subpage。其中,Chunk是Arena中最大的內存單位,也是Netty向操作系統申請內存的基本單位,默認大小為16MB。每個Chunk會被進一步劃分為2048個Page,每個Page的大小為8KB。
Netty針對不同的內存規格采用了不同的分配策略。
1)當申請的內存小于8KB時,由Subpage負責管理內存分配;
2)當申請的內存大于8KB時,采用Chunk中的Page級別分配策略;
3)為了提高小內存分配的效率,Netty還引入了本地線程緩存機制,用于處理小于8KB的內存分配請求。
Chunk內部通過伙伴算法(Buddy Algorithm)管理多個Page,并通過一棵滿二叉樹實現內存分配。在這棵二叉樹中,每個子節點管理的內存也屬于其父節點。例如,當申請16KB的內存時,系統會從根節點開始逐層查找可用的節點,直到第10層。

為了判斷一個節點是否可用,Netty在每個節點內部維護了一個值,用于指示該節點及其子節點的分配狀態。
1)如果第9層節點的值為9,表示該節點及其所有子節點都未被分配;
2)如果第9層節點的值為10,表示該節點本身不可分配,但其第10層的子節點可以被分配;
3)如果第9層節點的值為12,表示該節點及其所有子節點都不可分配,因為可分配節點的深度超過了樹的總深度。
Subpage
為了提高內存分配的利用率,Netty在分配小于8KB的內存時,不再直接分配整個Page,而是將Page進一步劃分為更小的內存塊,由Subpage進行管理。Subpage根據內存塊的大小分為兩大類。
1)Tiny:小于512B的內存請求,最小分配單位為16B,對齊大小也為16B。其區間為[16B, 512B),共有32種不同的規格。
2)Small:大于等于512B但小于8KB的內存請求,共有四種規格:512B、1024B、2048B和4096B。
Subpage采用位圖(bitmap)來管理空閑內存塊。由于不存在申請連續多個內存塊的需求,Subpage的分配和釋放操作非常簡單高效。
例如,假設需要分配20B的內存,系統會將其向上取整到32B。對于一個8KB(8192B)的Page,可以劃分為8192B / 32B = 256個內存塊。由于每個long類型有64位,因此需要256 / 64 = 4個long類型的變量來描述所有內存塊的分配狀態。因此,位圖數組的長度為4,分配時從bitmap[0]開始記錄。每分配一個內存塊,系統會將bitmap[0]中的下一個二進制位標記為1,直到bitmap[0]的所有位都被占用后,再繼續分配bitmap[1],依此類推。
在首次申請小內存空間時,系統需要先申請一個空閑的頁,并將該頁標記為已占用。隨后,該Subpage會被存入Subpage池中,以便后續直接從池中分配。Netty中共定義了36種Subpage規格,因此使用36個Subpage鏈表來表示Subpage內存池。

ChunkList
由于單個Chunk的大小僅為16MB,在實際應用中遠遠不夠,因此Netty會創建多個Chunk,并將它們組織成一個鏈表。這些鏈表由 ChunkList持有,而ChunkLis 是根據Chunk的內存使用率來組織的,每個ChunkList 都有一個明確的使用率范圍。
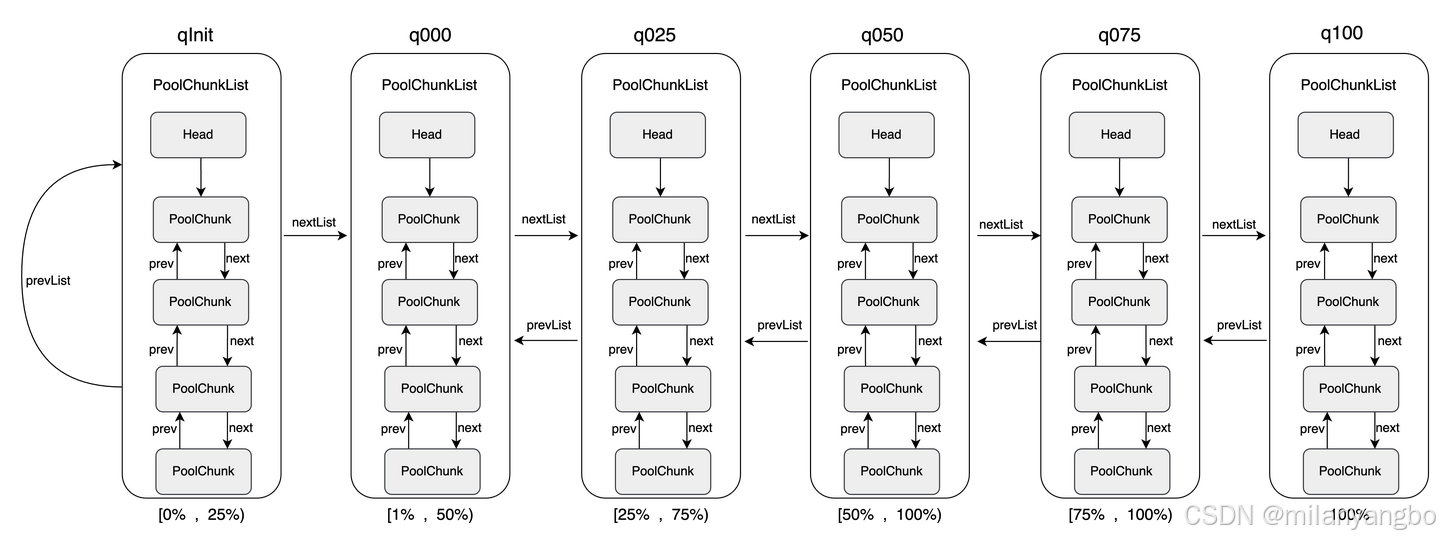
ChunkList的使用率范圍是重疊的,例如q025的[25%, 50%)和q050的[50%, 75%),兩者在 50% 處存在重疊。這種重疊設計并非偶然,而是 Netty 為了優化內存管理而有意引入的。
如果沒有重疊區間,當一個Chunk的使用率剛好達到某個ChunkList的邊界時,它會被立即移動到另一個鏈表中。例如:如果一個Chunk的使用率從24.9%增加到25%,它會從q000 移動到q025;如果使用率從25%降低到24.9%,它又會從q025移動回q000。這種頻繁的移動會導致額外的性能開銷。
通過引入重疊區間,Netty可以避免這種頻繁的移動。例如:在q025的范圍為[25%, 50%) 時,即使Chunk的使用率降低到25%,它仍然可以保留在q025中,直到使用率降低到25%以下(即進入q000的范圍)。
同理,當Chunk的使用率增加到50%時,它仍然可以保留在q025中,直到使用率超過50% 才移動到 q050。
總結:從I/O到內存的協同進化
高性能網絡架構的構建并非單一技術的堆砌,而是一個自底向上、層層遞進的協同進化過程。
1)核心矛盾:其根源在于,應用程序的數據處理需求與操作系統提供的底層I/O能力之間存在巨大的協作鴻溝。傳統的阻塞I/O模型,正是這種鴻溝導致效能損耗的直接體現。
2)調度權轉移:I/O模型的演進史,本質上是一部資源調度權的自底向上轉移史。從應用層被動等待(阻塞I/O),到將調度權交給內核(I/O多路復用),再到內核主動完成全部工作(異步I/O),系統的控制流越來越智能,資源利用也越來越高效。
3)架構具象化:Reactor模型通過職責分離和事件驅動,將這種高效的調度思想具象化為可落地的軟件架構。主從Reactor模式將資源模塊化,實現了流水線式的并行處理,使系統效能得以最大化。
4)效率的終極追求:當I/O和線程模型優化到極致后,內存管理成為新的決勝點。內存池技術,特別是Netty的精細化設計,其核心思想是“用結構化預置取代隨機化操作”。通過空間預占(預分配)和精準復用(多級緩存與規格匹配),它將高昂的動態內存操作,轉化為低成本的確定性計算,使內存調度效率與硬件承載能力完美匹配。
最終,當事件驅動降低了線程調度的微觀成本,資源復用消除了內存管理的隱性消耗,而分層解耦提升了模塊協作的宏觀效率時,一個高吞吐、低延遲的健壯系統便水到渠成。這不僅僅是技術的勝利,更是對系統復雜性進行有序治理的架構智慧的體現。
很高興與你相遇!如果你喜歡本文內容,記得關注哦
本文來自博客園,作者:poemyang,轉載請注明原文鏈接:http://www.rzrgm.cn/poemyang/p/19160579

 浙公網安備 33010602011771號
浙公網安備 33010602011771號