
千億消息“過眼云煙”?Kafka把硬盤當(dāng)內(nèi)存用的性能魔法,全靠這一手!
Kafka 消息隊列
Apache Kafka是一個開源的分布式消息隊列,由LinkedIn公司開發(fā)并于2011年貢獻給Apache軟件基金會。Kafka被設(shè)計用來處理千億量級的實時數(shù)據(jù),被廣泛應(yīng)用于互聯(lián)網(wǎng)大規(guī)模數(shù)據(jù)處理平臺中。
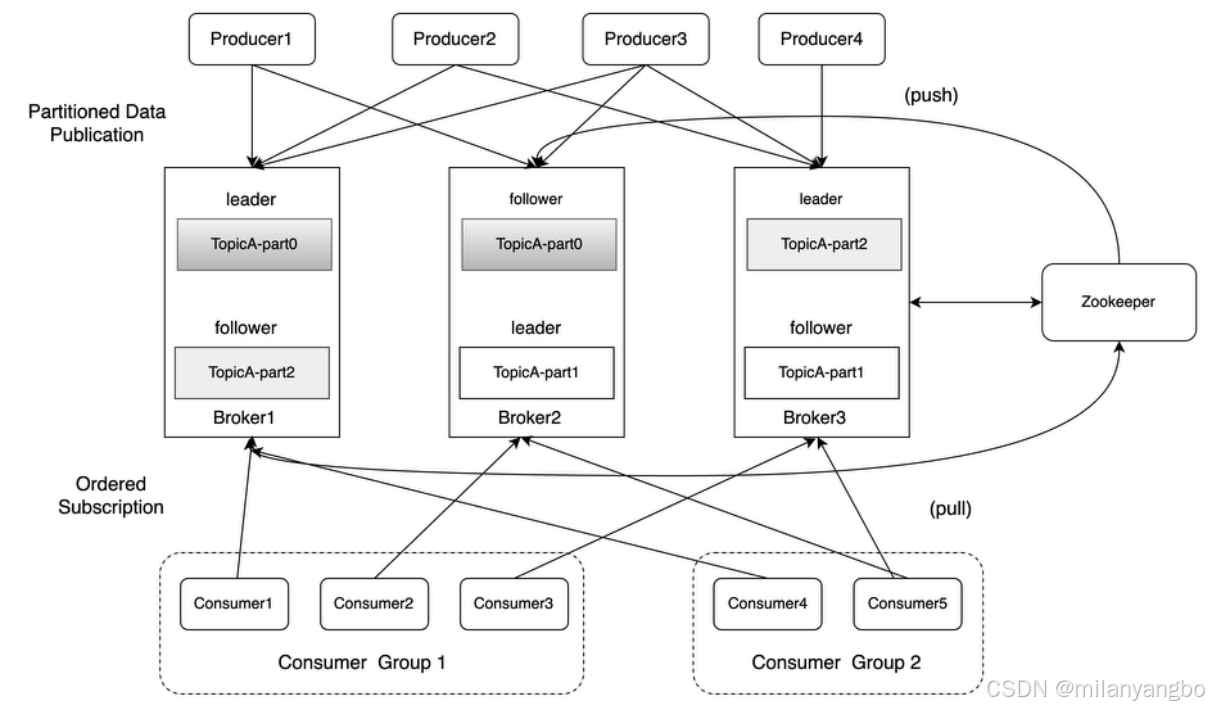

Kafka強大的數(shù)據(jù)吞吐量,其中最重要部分在于它的消息日志格式的設(shè)計,包括幾個特別重要的概念,主題(topic)、分區(qū)(partition)、分段(segment)、偏移量(offset)。
1)主題:Kafka按主題對消息進行分類。 主題是邏輯上的概念。
2)分區(qū):硬盤實際根據(jù)分區(qū)存儲日志。一個主題下通常有多個分區(qū),分區(qū)分布在不同的broker上,這使Kafka提供給了并行的消息處理和橫向擴容能力。并且分區(qū)通常會分組,每組有一個主分區(qū)、多個副本分區(qū),并分布在不同的broker上,從而起到容災(zāi)的作用。
3)分段:宏觀上看,一個分區(qū)對應(yīng)一個日志(Log)。由于生產(chǎn)者生產(chǎn)的消息會不斷追加到log文件末尾,為了防止 log 日志過大,Kafka 又引入了日志分段(LogSegment)的概念,將 log 切分為多個 LogSegement,相當(dāng)于一個巨型文件被平均分配為相對較小的文件,這樣也便于消息的維護和清理。
Log 和 LogSegement 也不是純粹物理意義上的概念,Log 在物理上只是以文件夾的形式存儲,而每個 LogSegement 對應(yīng)于磁盤上的一個日志文件(.log)和兩個索引文件(.index、timeindex),以及可能的其他文件(比如以.txindex為后綴的事務(wù)索引文件)。
4)偏移量:消息在日志中的位置,消息在被追加到分區(qū)日志文件的時候都會分配一個特定的偏移量。偏移量是消息在分區(qū)中的唯一標(biāo)識,是一個單調(diào)遞增且不變的值。Kafka 通過它來保證消息在分區(qū)內(nèi)的順序性,不過偏移量并不跨越分區(qū),也就是說,Kafka 保證的是分區(qū)有序而不是主題有序。
日志格式

Kafka日志是以批為單位進行日志存儲的,所謂的批指的是Kafka會將多條日志壓縮到同一個批次(Batch)中,然后以Batch為單位進行后續(xù)的諸如索引的創(chuàng)建和消息的查詢等工作。對于每個批次而言,其默認(rèn)大小為4KB,并且保存了整個批次的起始偏移量和時間戳等元數(shù)據(jù)信息,而對于每條消息而言,其偏移量和時間戳等元數(shù)據(jù)存儲的則是相對于整個批次的元數(shù)據(jù)的增量,通過這種方式,Kafka能夠減少每條消息中數(shù)據(jù)占用的磁盤空間。
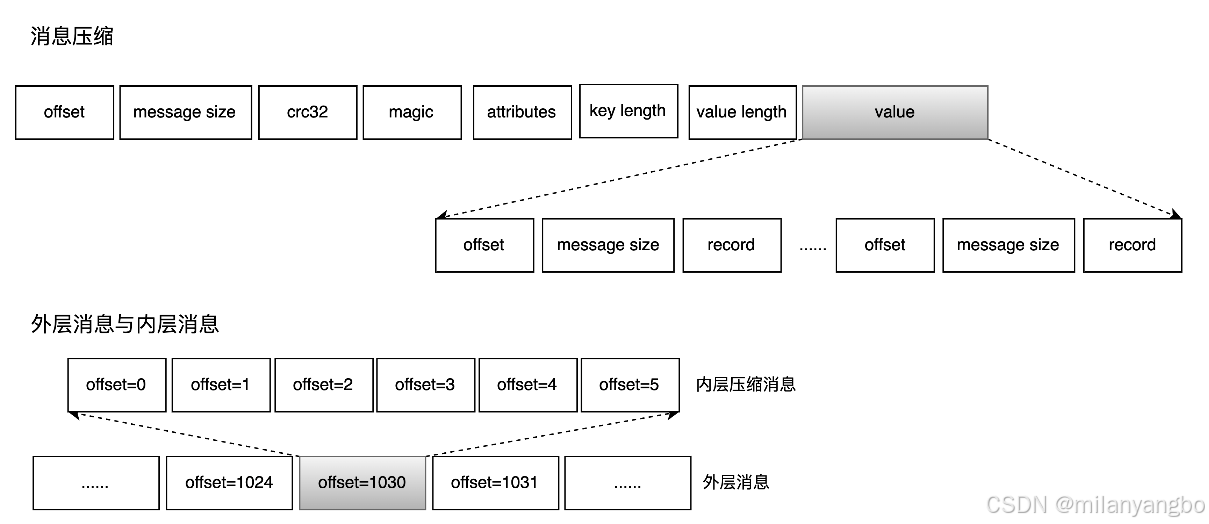
Kafka將日志消息只寫入Page Cache,而Page Cache中的數(shù)據(jù)通過Linux的flusher程序進行異步刷盤,將數(shù)據(jù)順序追加寫到硬盤日志文件中。由于Page Cache是在內(nèi)存中進行緩存,因此讀寫速度非常快。順序追加寫充分利用順序 I/O 寫操作,可有效提升Kafka 的吞吐量。Kafka甚至鼓勵使用足夠的內(nèi)存讓活躍數(shù)據(jù)集能完全駐留在Page Cache中。
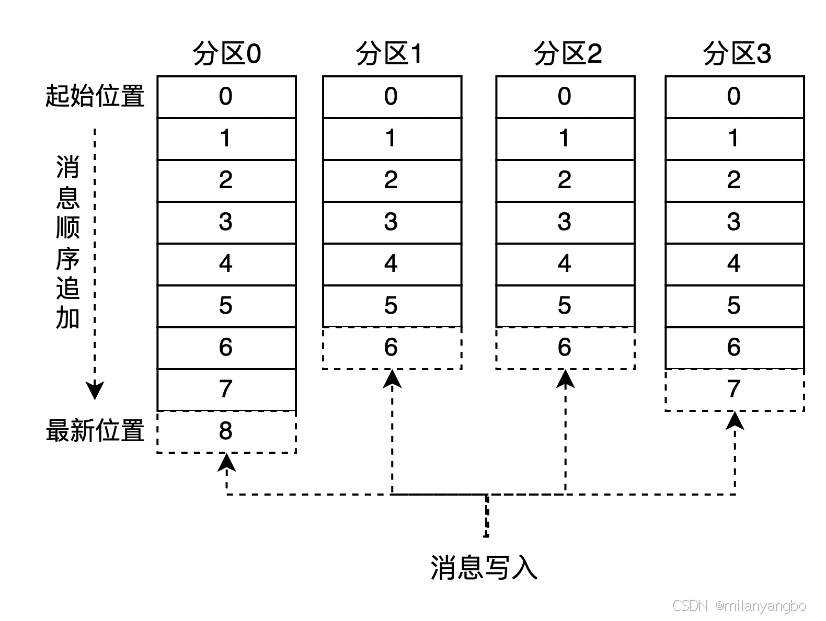
具體到日志文件中的每個 LogSegement 都有一個基準(zhǔn)偏移量 (baseOffset),用來標(biāo)識當(dāng)前 LogSegement 中第一條消息的 offset。偏移量是一個 8字節(jié)的長整形。日志文件和兩個索引文件都是根據(jù)基準(zhǔn)偏移量命名的,名稱固定為 20 位數(shù)字,沒有達到的位數(shù)則用 0 填充。比如第一個 LogSegment 的基準(zhǔn)偏移量為 0,對應(yīng)的日志文件為 00000000000000000000.log。

示例中第 2 個 LogSegment 對應(yīng)的基準(zhǔn)偏移量是 256,也說明了該 LogSegment 中的第一條消息的偏移量為 256,同時可以反映出第一個 LogSegment 中共有 256 條消息(偏移量從 0 至 255 的消息)。
日志索引
Kafka主要有兩種類型的索引文件:偏移量索引文件(.indx)和時間戳索引文件(.timeindex)。偏移量索引文件中存儲的是消息的偏移量與該偏移量所對應(yīng)的消息的物理地址;時間戳索引文件中則存儲的是消息的時間戳與該消息的偏移量值。
Kafka中的索引文件以稀疏索引(Sparse index)的方式構(gòu)造消息的索引,它并不保證每個消息在索引文件中都有對應(yīng)的索引項。如上日志格式中所述,Kafka 至少寫入 4KB 消息數(shù)據(jù)之后,才會在索引文件中增加一個索引項。
偏移量索引
偏移量索引分為2個部分,總共占8個字節(jié)。
1)relativeOffset(4B):消息的相對偏移量,即offset - baseOffset,其中baseOffset為整個segmentLogFile的起始消息的offset。
2)position(4B):物理地址,也就是日志在分段日志文件中的實際位置。

假設(shè) Kafka 需要找出偏移量為 23 的消息:
1)首先通過二分法找到不大于23的最大偏移量索引【22,656】;
2)然后從position(656)開始順序查找偏移量為23的消息。

時間戳索引
時間戳索引分為2部分,公占12個字節(jié)。
1)timestamp:當(dāng)前日志分段文件中建立索引的消息的時間戳。
2)relativeoffset:時間戳對應(yīng)消息的相對偏移量。

假設(shè) Kafka 需要找出偏移量為 28 的消息:
1)在時間戳索引文件中找到不大于該時間戳的最大時間戳對應(yīng)的最大索引項【1526384718283,28】;
2)在偏移量索引文件中檢索不超過對應(yīng)relativeoffset(28)的最大偏移量索引的項【26,838】;
3)按照偏移量索引的檢索方式找到對應(yīng)的具體消息。

日志清理
Kafka提供了兩種日志清理策略。
1)日志刪除(Log Deletion):按照一定的保留策略來直接刪除不符合條件的日志分段。
2)日志合并(Log Compaction):針對每個消息的key進行整合,對于有相同key的的不同value值,只保留最后一個版本。
日志刪除
Kafka的默認(rèn)清理策略是日志刪除,主要有三種方式。
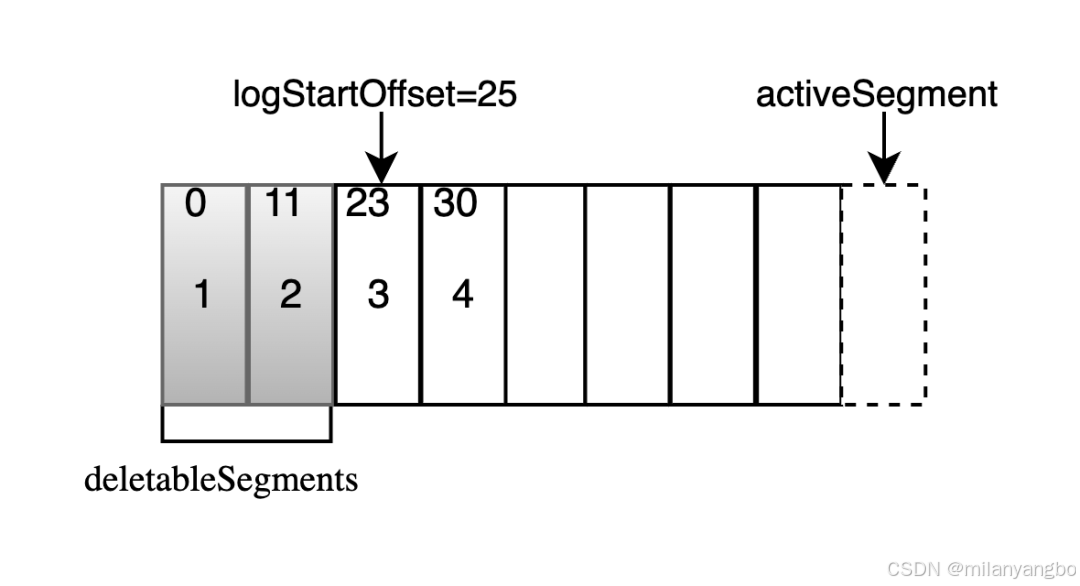
1)基于日志大小:檢查當(dāng)前日志的大小size是否超過設(shè)定的閾值retentionSize的差值,來尋找可刪除的日志分段的文件集合deletableSegments。

2)基于時間:檢查當(dāng)前日志文件中是否有保留時間超過設(shè)定的閾值retentionMs,來尋找可刪除的的日志分段文件集合deletableSegments。
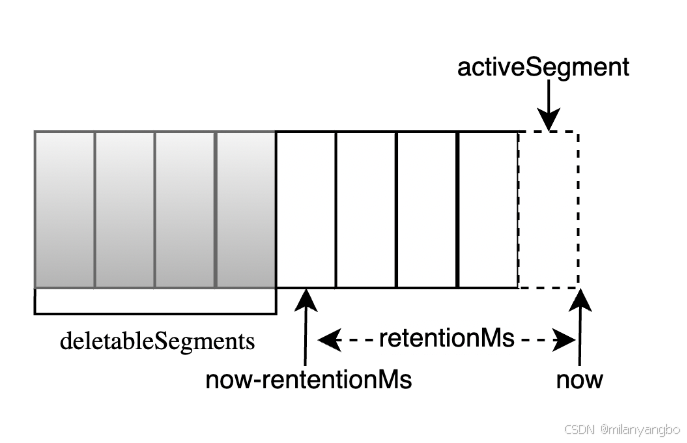
3)基于日志起始偏移量:檢查某日志分段的下一個日志分段的baseOffset是否小于等于logStartOffset,來尋找可刪除的的日志分段文件集合deletableSegments。
日志合并
對于特定主題(通常用于存儲狀態(tài)變更或配置信息),可以開啟日志合并。它確保對于每個消息Key,分區(qū)中至少保留其最新Value的記錄。舊版本的值會被清理。壓縮過程在后臺進行,掃描日志段,對具有相同Key的消息,只保留最新偏移量(即最新版本)的那條。已標(biāo)記為刪除(Value為null)的Key,若其所有版本都被壓縮,則該Key最終會被移除。
這類似于LSM樹的合并思想,適用于那些只需要關(guān)心每個Key最新狀態(tài)的場景。

總結(jié): 殊途同歸,擁抱順序I/O的制勝法寶
在現(xiàn)代高性能存儲系統(tǒng)的設(shè)計中,一個關(guān)鍵出發(fā)點在于將存儲介質(zhì)的物理特性(如速度、成本、壽命和訪問模式)與實際業(yè)務(wù)需求(如讀寫比例、數(shù)據(jù)量和延遲要求)完美結(jié)合,并通過合適的數(shù)據(jù)結(jié)構(gòu)和I/O策略實現(xiàn)最優(yōu)匹配。
以 MySQL的 InnoDB引擎為例,為應(yīng)對關(guān)系型數(shù)據(jù)庫中復(fù)雜的范圍查詢和排序需求,InnoDB 采用了B+樹索引。這種結(jié)構(gòu)具備高扇出、多層級的特點,能夠?qū)⑦壿嫴檎腋咝в成涞酱疟P頁訪問。同時,B+樹的葉子節(jié)點之間通過鏈表連接,配合順序預(yù)讀和操作系統(tǒng)的Page Cache機制,使得在讀密集型或混合負(fù)載場景下具備良好性能。
RocksDB則采用了不同的路徑。它基于 LSM 樹的設(shè)計理念,先將寫入數(shù)據(jù)暫存于內(nèi)存(MemTable),再批量、有序地寫入磁盤(SSTable 文件)。后臺的合并機制異步合并文件、清理冗余,從而保持讀寫平衡。這種將隨機寫轉(zhuǎn)化為順序?qū)懙姆绞剑貏e適合SSD介質(zhì),能大幅提升寫入吞吐量。
在 Kafka 中,核心思路則是將消息寫入分區(qū)日志,以追加的方式順序?qū)懭氪疟P。每個分區(qū)天然支持并行擴展,Kafka 利用了機械硬盤的順序?qū)憙?yōu)勢,同時在 SSD 上也有良好的性能表現(xiàn)。加上操作系統(tǒng) Page Cache 的高效緩存機制,它在實際場景中甚至可以提供接近內(nèi)存級別的讀寫速度。
這三種系統(tǒng)雖然應(yīng)用場景不同,底層結(jié)構(gòu)各異,但有一個共識:順序 I/O 是提升存儲系統(tǒng)性能的關(guān)鍵路徑。它們都充分利用了 Page Cache 和底層硬件的特點,體現(xiàn)了技術(shù)設(shè)計中對硬件現(xiàn)實的尊重與對系統(tǒng)性能的極致追求。
很高興與你相遇!
如果你喜歡本文內(nèi)容,記得關(guān)注哦!!!
本文來自博客園,作者:poemyang,轉(zhuǎn)載請注明原文鏈接:http://www.rzrgm.cn/poemyang/p/19052513

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號