
Java編譯器優化秘籍:字節碼背后的IR魔法與常見技巧
中間表達形式
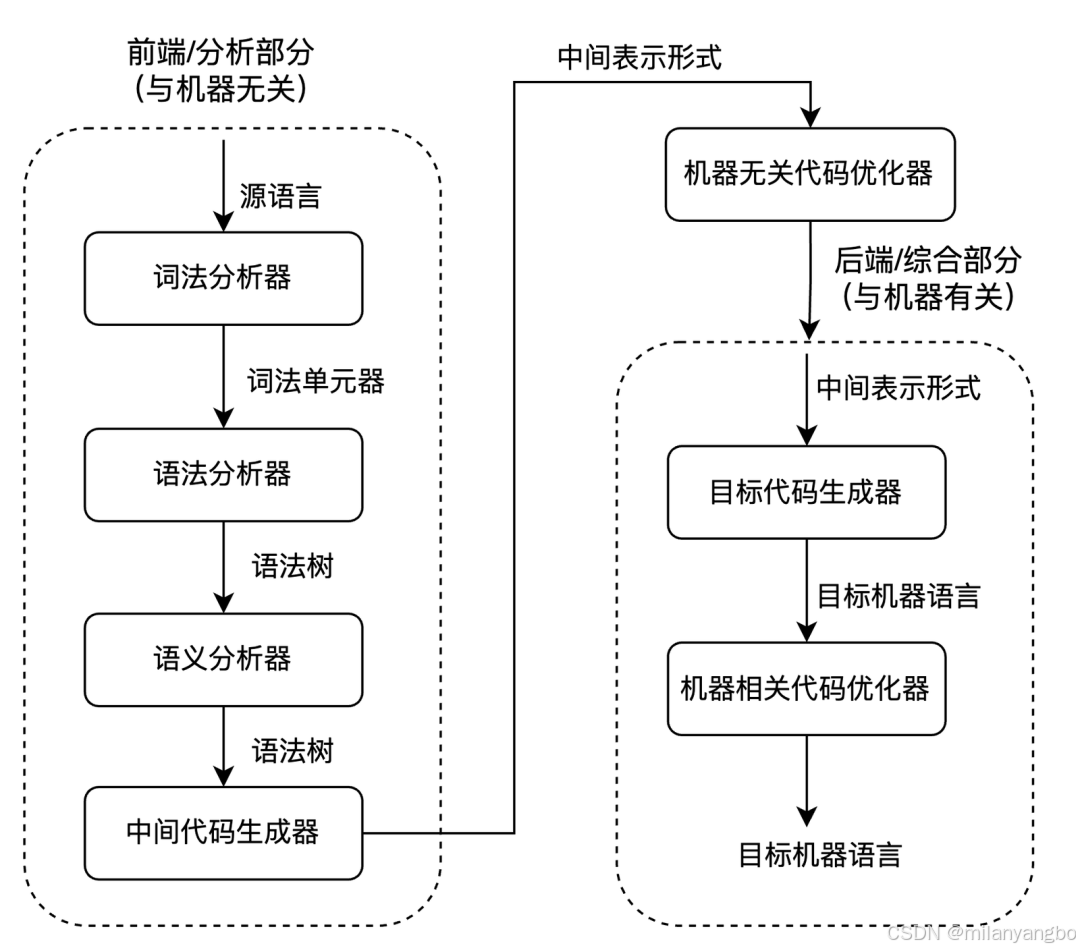
編譯器通常被劃分為前端編譯器和后端編譯器兩個部分。前端編譯器負責對源代碼進行詞法分析、語法分析和語義分析,生成中間表達形式(Intermediate Representation ,IR)。這種由前端生成的IR被稱為高級中間表達形式(High Intermediate Representation,HIR),其優化主要與源代碼本身的特性有關。
后端后端編譯器則將HIR轉換為低級中間表達形式(Low Intermediate Representation,LIR),并進行進一步的優化。這種優化主要與目標機器的硬件特性有關。最終,LIR會被翻譯成目標機器代碼。
在不考慮解釋執行的情況下,源代碼到最終機器碼的轉換過程通常包括兩個編譯階段:
1)Java編譯器(如javac)將源代碼編譯成字節碼;
2)即時編譯器將字節碼編譯成機器碼。
對于即時編譯器,字節碼直接被視為一種IR,是Java虛擬機的通用“語言”。它結構化、平臺無關,但對于進行復雜的全局優化而言,其基于棧的指令格式和較為緊湊的表示方式并不總是最理想的。
因此,當即時編譯器(如C1或C2)開始工作時,它首先會將輸入的字節碼轉換為其內部更適合分析和優化的IR。現代編譯器通常采用圖結構的IR,其中靜態單賦值(Static Single Assignment,SSA)IR是一種常用的IR特性,它要求每個變量只被賦值一次。SSA形式極大地簡化了許多優化算法的實現,如常量傳播、死代碼消除、公共子表達式消除、寄存器分配等。
HotSpot C2編譯器采用一種稱為Sea of Nodes(節點之海)的高度優化的圖IR,它就是基于SSA的。這種IR將程序表示為數據流圖和控制流圖的結合,節點代表操作,邊代表數據流或控制依賴。它允許進行非常自由和強大的代碼變換和優化。
總結來說,從Java源代碼到最終在處理器上執行的機器碼,如果排除純解釋執行,大致經歷以下IR轉換:
源代碼 ->(javac)->Java字節碼 ->(即時編譯前端) ->即時編譯內部HIR (如SSA圖) ->(即時編譯中端優化) ->即時編譯內部LIR ->(即時編譯后端) ->目標機器碼。
機器無關的編譯優化
編譯優化的方法主要可以分為機器無關與機器相關的優化。
1)機器無關的優化與硬件特征無關,比如把常數值在編譯期計算出來(常數折疊)。
2)機器相關的優化則需要利用某硬件特有的特征,比如 SIMD 指令等。
值編號
值編號(Value numbering)用于消除冗余的計算。編譯器通過跟蹤每個計算的值,如果發現兩個計算的值相同,就可以將其中一個計算替換為另一個計算的結果。
// 值編號前的代碼
int a = 5;
int b = 10;
int c = a + b;
int d = a + b;
// 值編號后的代碼
int a = 5;
int b = 10;
int c = a + b;
int d = c;
常數折疊
常量折疊(Constant folding)通過在編譯時計算常數表達式的值,將這些表達式替換為它們的計算結果。
// 常量折疊前的代碼
int a = 5 * 10;
// 常量折疊后的代碼
int a = 50;
常數傳播
常數傳播(Constant oropagation)它通過分析代碼中的常數賦值和使用,將常數值直接傳播到使用它們的表達式中。
// 常量傳播前的代碼
int a = 10;
int b = 20;
int c = a + b;
// 常量傳播后的代碼
int c = 10 + 20;
死代碼消除
死代碼消除(Dead Code Elimination)旨在移除程序中不會影響最終結果的代碼,減少程序的大小。
// 死代碼消除前的代碼
int a = 10;
int b = 20;
int c = a + b; // 這行代碼是死代碼,因為 c 沒有被使用
if (a > 5) {
print("a is greater than 5");
}
int d = 30; // 這行代碼是死代碼,因為 d 沒有被使用
// 死代碼消除后的代碼
int a = 10;
if (a > 5) {
print("a is greater than 5");
}
公共子表達式消除
公共子表達式消除(Common subexpression elimination,CSE)通過識別并消除重復的子表達式,避免在運行時多次計算相同的子表達式。
// 公共子表達式消除前的代碼
int a = x * y;
int b = x * y;
// 公共子表達式消除后的代碼
int a = x * y;
int b = a;
null判斷消除
null判斷消除(Null check elimination)通過在編譯時分析代碼,確定某些引用不可能為null,從而消除不必要的null檢查。
// null判斷消除前的代碼
String str = "Hello, World!";
// Null檢查
if (str != null) {
System.out.println(str);
}
// null判斷消除后的代碼
// 編譯器可以確定str不可能為null,從而消除null檢查
String str = "Hello, World!";
System.out.println(str);
邊界檢查消除
邊界檢查消除(Bounds check elimination)通過在編譯時分析代碼,判斷數組訪問是否越界,從而在運行時避免不必要的邊界檢查。
// 邊界檢查消除前的代碼
// for循環中的數組訪問array[i]需要進行邊界檢查
int[] array = new int[10];
for (int i = 0; i < array.length; i++) {
array[i] = i * 2;
}
// 邊界檢查消除后的代碼
// 編譯器消除了for循環中的邊界檢查,因為它可以在編譯時確定i的值不會越界
int[] array = new int[10];
for (int i = 0; i < 10; i++) {
array[i] = i * 2;
}
循環展開
循環展開(Loop unrolling)通過減少循環次數并在每次循環中執行更多的操作,以減少循環控制開銷。同時它還會增加一個基本塊中的指令數量,從而為指令排序的優化算法創造機會。在循環展開的基礎上,可以實現把多次計算優化成一個向量計算。
// 循環展開前的代碼
int sum = 0;
for (int i = 1; i <= 10; i++) {
sum += i;
}
// 循環展開后的代碼
// 優化后將循環次數減少到了5次
int sum = 0;
for (int i = 1; i <= 10; i += 2) {
sum += i;
sum += i + 1;
}
未完待續
很高興與你相遇!如果你喜歡本文內容,記得關注哦!
本文來自博客園,作者:poemyang,轉載請注明原文鏈接:http://www.rzrgm.cn/poemyang/p/19024509

 浙公網安備 33010602011771號
浙公網安備 33010602011771號