分詞器模型
中文分詞是NLP中一個獨特且富有挑戰性的任務,因為中文文本沒有像英文空格那樣的天然詞語邊界。
現代分詞器模型(尤其是基于Transformer的模型如BERT、GPT等使用的中文分詞器)主要采用子詞分詞算法,但其處理方式與英文有顯著不同。
| 特性 | 傳統中文分詞器 (如Jieba, HanLP) | 現代模型分詞器 (如BERT的分詞器) |
|---|---|---|
| 目標 | 將文本切分成語言學意義上的詞。 | 將文本切分成對模型訓練最有效的單元。 |
| 輸出 | 詞的序列。[“我”, “喜歡”, “讀書”] |
子詞/字符的序列。[“我”, “喜”, “歡”, “讀”, “書”] 或 [“我”, “喜歡”, “讀”, “書”] |
| 歧義處理 | 需要復雜的算法(如HMM、CRF)來解決分詞歧義(如“乒乓球拍賣完了”)。 | 將問題拋給模型。模型在預訓練過程中通過上下文自行學習消歧。 |
| 與模型關系 | 獨立于下游的NLP模型,是預處理步驟。 | 深度集成,是模型的一部分,分詞方式與模型架構共同設計。 |
主流的中文分詞器(如BERT、ERNIE等使用的)并不像傳統中文分詞器那樣先進行“詞”的切分,而是將句子切分成更小的、更靈活的單元。主要有兩種策略:
1. 字符級分詞
這是最簡單直接的方法。
-
做法:將每個漢字或標點符號視為一個獨立的Token。
-
示例:
-
文本:
"我喜歡讀書" -
分詞結果:
[“我”, “喜”, “歡”, “讀”, “書”]
-
-
優點:
-
非常簡單,無需復雜的分詞算法。
-
詞匯表很小(幾千個常用漢字就足以覆蓋絕大多數文本)。
-
完全避免了分詞歧義問題。
-
-
缺點:
-
序列長度會很長。
-
模型需要從零學習詞語和短語的語義,增加了學習負擔。例如,模型需要自行理解“喜歡”是一個整體,而不是“喜”和“歡”的簡單相加。
-
-
使用模型:很多早期的中文BERT模型(如Google官方發布的
bert-base-chinese)就采用這種方式。
2. 子詞分詞(主要是WordPiece)
這是目前更主流、效果更好的方法。它結合了字符級和詞級的優點。
-
做法:
-
首先,它會有一個通過大量中文語料訓練得到的詞匯表。這個詞匯表中不僅包含常用漢字,也包含常見的詞語和詞綴。
-
對于一個句子,它首先嘗試匹配最長的、在詞匯表中存在的單元。如果找不到,就把詞拆分成更小的子詞,直到所有部分都在詞匯表中。
-
-
示例:
-
詞匯表包含詞語:
-
文本:
"人工智能很強大" -
分詞結果:
[“人工”, “##智能”, “很”, “強大”] -
說明: “人工智能”被拆成了“人工”和“##智能”,其中
##表示這是一個詞的后續部分。“強大”作為一個整體詞存在于詞匯表中。
-
-
詞匯表不包含詞語:
-
文本:
"韮菜盒子" -
分詞結果:
[“韮”, “##菜”, “盒”, “##子”] -
說明: “韮菜”可能不在詞匯表里,所以被拆成“韮”和“##菜”。“盒子”被拆成“盒”和“##子”,這是一種常見的子詞組合。
-
-
-
優點:
-
平衡了詞匯表大小和語義:常見詞保持完整,生僻詞或新詞可以拆解。
-
更好的泛化能力:模型能通過“##子”理解“盒子”、“鞋子”、“孩子”等有共同詞綴的詞。
-
效率更高:序列長度比純字符級短。
-
-
使用模型:很多后續優化的中文模型(如ERNIE, RoBERTa-wwm-ext)都采用了這種更智能的子詞分詞。
一、輸入
二、輸出
三、模型結構
四、處理流程
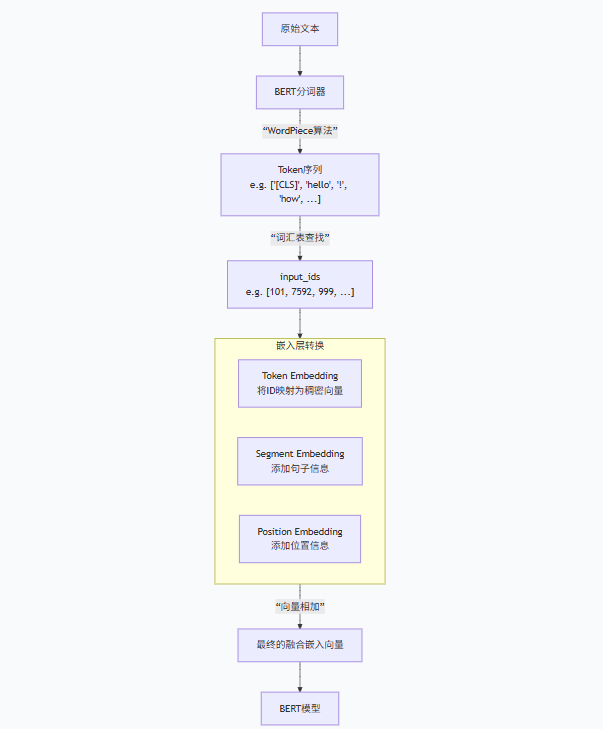
BERT 分詞器通過 “基礎分詞 + WordPiece 子詞拆分” 實現對文本的細粒度處理,既緩解了未登錄詞(OOV)問題,又保留了詞的語義完整性,同時通過特殊符號和輔助信息適配模型的雙向編碼需求,是 BERT 模型性能的重要保障。
BERT 詞匯表中每個詞(token)對應的向量
1. 詞匯表與初始向量的初始化
2. 詞嵌入的動態學習過程
3. 詞嵌入的最終形態
MLM網絡結構詳細分解
1. 輸入表示 (Input Representation)
輸入是一個經過處理的句子(或一對句子),其中部分Token被特殊處理。
-
原始Token:
[CLS]我 愛 自然 語言 處理[SEP] -
MLM處理后的Token(如圖):
-
隨機選擇15%的Token作為待預測候選。
-
在這15%中:
-
80%的概率替換為
[MASK]:例如 “愛” ->[MASK] -
10%的概率替換為隨機Token:例如 “語言” -> “蘋果” (但此例中我們仍展示為更常見的
[MASK]) -
10%的概率保持不變:例如 “語言” -> “語言” (但此例中我們仍展示為更常見的
[MASK])
-
-
最終輸入模型的是:
[CLS]我[MASK]自然[MASK]處理[SEP]
-
每個Token的輸入表示由三部分相加構成:
-
Token Embeddings: 詞嵌入,
[MASK]有自己對應的嵌入向量。 -
Segment Embeddings: 句子分段嵌入,用于區分兩個句子。
-
Position Embeddings: 位置嵌入,表示每個Token在序列中的順序。
2. BERT主干網絡 (Backbone Network)
-
結構: 一個多層的(例如12層或24層)Transformer編碼器堆疊而成。
-
核心機制: 每一層都包含一個多頭自注意力機制和一個前饋神經網絡。
-
功能: 通過自注意力機制,每個位置的Token都能與序列中的所有其他Token進行交互,從而生成一個上下文感知的編碼向量。
-
輸入輸出:
-
輸入: 序列的嵌入表示
(batch_size, sequence_length, hidden_size)。 -
輸出: 經過深層Transformer編碼后的序列表示,形狀與輸入相同。圖中的
[MASK]位置對應的輸出向量,已經包含了來自全局上下文的信息,用于預測原始詞。
-
3. MLM輸出層 (MLM Head)
這是MLM任務特有的部分,它只應用于被Mask的位置(或其候選位置)。
-
輸入: BERT最后一層輸出的、對應被Mask位置的上下文向量(例如,圖中“愛”和“語言”位置對應的輸出向量
T_[MASK]1和T_[MASK]2)。 -
結構:
-
一個線性層: 通常是一個前饋網絡,使用GELU激活函數。這一步的作用是進行特征變換和降維(有時)。
-
Layer Normalization: 對輸出進行標準化,穩定訓練過程。
-
輸出權重矩陣: 這是最關鍵的一步。使用BERT輸入嵌入矩陣
W_embedding的轉置 作為輸出層的權重矩陣。-
動機: 這被稱為 權重綁定,可以減少模型參數,并被認為能使輸入和輸出空間保持一致,提升模型性能。
-
-
-
輸出: 一個大小為
vocab_size(例如30522)的概率分布。通過Softmax函數計算,表示該被Mask位置是詞匯表中每個詞的可能性。-
對于第一個
[MASK],模型會輸出一個分布,其中 “愛” 的概率應該最高。 -
對于第二個
[MASK],會輸出另一個分布,其中 “語言” 的概率應該最高。
-
4. 損失計算 (Loss Calculation)
-
計算方式: 使用交叉熵損失。
-
范圍: 僅計算被Mask的那些位置的損失。圖中未被Mask的位置(如“我”、“自然”、“處理”等)的輸出不參與MLM的損失計算。
-
目標: 通過優化這個損失,BERT學會了如何根據上下文來預測被遮蓋的詞語,從而深入理解語言的內在規律。
訓練模式 vs. 推理模式的重要區別
-
訓練: 如上所述,模型可以同時看到多個被
[MASK]的Token,并并行地預測它們。因為訓練時我們有真實標簽,計算損失不需要依賴上一個預測結果。 -
推理: 標準的BERT本身并不直接用于像傳統語言模型那樣逐詞生成文本。如果需要用MLM方式進行預測,通常做法是:
-
每次只Mask一個Token(或少量Token)。
-
讓模型預測這個Token。
-
用預測出的詞替換掉
[MASK],再預測下一個。
但這種方式效率很低。所以BERT通常用于完形填空(一次預測一個Mask)或作為特征提取器,而不是自回歸文本生成。
-

 浙公網安備 33010602011771號
浙公網安備 33010602011771號