內存吞金獸(Elasticsearch)的那些事兒 -- 寫入&檢索原理
協調節點
客戶端寫入一條數據,到Elasticsearch集群里邊就是由協調節點來處理這次請求:

集群上的每個節點都是coordinating node,表明這個節點可以做路由。比如節點1接收到了請求,但發現這個請求的數據應該是由節點2處理(因為主分片在節點2上),所以會把請求轉發到節點2上。
- coodinate node通過hash算法可以計算出是在哪個主分片上,然后路由到對應的index node
shard = hash(document_id) % (num_of_primary_shards)
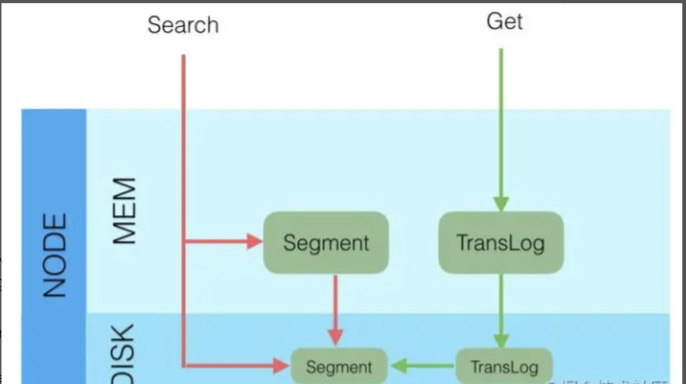
節點寫入
- 將數據寫到內存緩存區
- 然后將數據寫到translog緩存區
- 定期將數據從buffer中refresh到FileSystemCache中,生成segment文件,一旦生成segment文件,就能通過索引查詢到了
- refresh完,memory buffer就清空了。
- 定期將translog 從buffer flush到磁盤中
- 定期/定量從FileSystemCache中,結合translog內容
flush index到磁盤中。

默認配置運行流程:
- Elasticsearch會把數據先寫入內存緩沖區,然后每隔1s刷新到文件系統緩存區(當數據被刷新到文件系統緩沖區以后,數據才可以被檢索到)。所以:Elasticsearch寫入的數據需要1s才能查詢到
- 為了防止節點宕機,內存中的數據丟失,Elasticsearch會另寫一份數據到日志文件上,但最開始的還是寫到內存緩沖區,每隔5s才會將緩沖區的刷到磁盤中。所以:Elasticsearch某個節點如果掛了,可能會造成有5s的數據丟失。
- 等到磁盤上的translog文件大到一定程度或者超過了30分鐘,會觸發commit操作,將內存中的segment文件異步刷到磁盤中,完成持久化操作。
說白了就是:寫內存緩沖區(定時去生成segment,生成translog),能夠讓數據能被索引、被持久化。最后通過commit完成一次的持久化。
最后
等主分片寫完了以后,會將數據并行發送到副本集節點上,等到所有的節點寫入成功就返回ack給協調節點,協調節點返回ack給客戶端,完成一次的寫入。
更新和刪除
- 給對應的
doc記錄打上.del標識,如果是刪除操作就打上delete狀態,如果是更新操作就把原來的doc標志為delete,然后重新新寫入一條數據 -
前面提到了,每隔1s會生成一個segment 文件,那segment文件會越來越多越來越多。Elasticsearch會有一個merge任務,會將多個segment文件合并成一個segment文件。在合并的過程中,會把帶有
delete狀態的doc給物理刪除掉。
檢索原理
核心
link:3. 數據結構
兩大類
es的檢索主要分為兩大類
- 根據ID查詢doc(實時)
- 檢索內存的Translog文件
- 檢索硬盤的Translog文件
- 檢索硬盤的Segment文件
- 根據query(搜索詞)去查詢匹配的doc(近實時,因為segment文件是每隔一秒才生成一次的)
- 查詢Segment
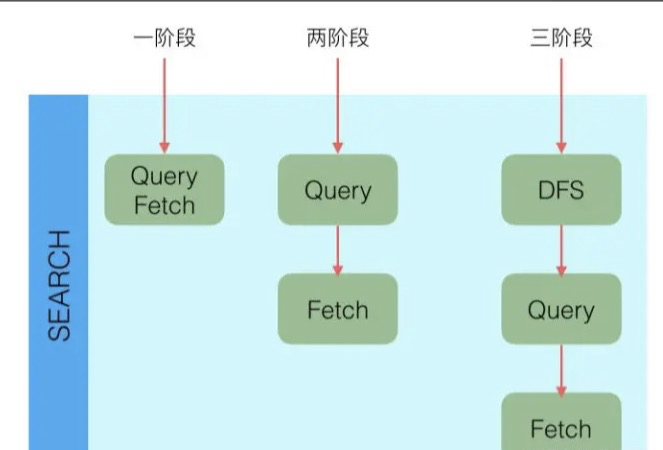
三階段
-
QUERY_AND_FETCH(查詢完就返回整個Doc內容)
-
QUERY_THEN_FETCH(先查詢出對應的Doc id ,然后再根據Doc id 匹配去對應的文檔)
-
DFS_QUERY_THEN_FETCH(先算分,再查詢)
- 「這里的分指的是 詞頻率和文檔的頻率(Term Frequency、Document Frequency)眾所周知,出現頻率越高,相關性就更強」
QUERY_THEN_FETCH總體的大概流程流程:
- 客戶端請求發送到集群的某個節點上。集群上的每個節點都是coordinate node(協調節點)
- 然后協調節點將搜索的請求轉發到所有分片上(主分片和副本分片都行)
- 每個分片將自己搜索出的結果
(doc id)返回給協調節點,由協調節點進行數據的合并、排序、分頁等操作,產出最終結果。 - 接著由協調節點根據
doc id去各個節點上拉取實際的document數據,最終返回給客戶端。
Query Phase階段時節點做的事:
- 協調節點向目標分片發送查詢的命令(轉發請求到主分片或者副本分片上)
- 數據節點(在每個分片內做過濾、排序等等操作),返回
doc id給協調節點
Fetch Phase階段時節點做的是:
- 協調節點得到數據節點返回的
doc id,對這些doc id做聚合,然后將目標數據分片發送抓取命令(希望拿到整個Doc記錄) - 數據節點按協調節點發送的
doc id,拉取實際需要的數據返回給協調節點
本文來自博客園,作者:房上的貓,轉載請注明原文鏈接:http://www.rzrgm.cn/lsy131479/p/15184408.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號