內存吞金獸(Elasticsearch)的那些事兒 -- 數據結構及巧妙算法
系列目錄
內存吞金獸(Elasticsearch)的那些事兒 -- 認識一下
內存吞金獸(Elasticsearch)的那些事兒 -- 數據結構及巧妙算法
內存吞金獸(Elasticsearch)的那些事兒 -- 架構&三高保證
內存吞金獸(Elasticsearch)的那些事兒 -- 寫入&檢索原理
內存吞金獸(Elasticsearch)的那些事兒 -- 常見問題痛點及解決方案
ES 本質上是一個支持全文搜索的分布式內存數據庫,特別適合用于構建搜索系統。ES 之所以能有非常好的全文搜索性能,最重要的原因就是采用了倒排索引。倒排索引是一種特別為搜索而設計的索引結構,倒排索引先對需要索引的字段進行分詞,然后以分詞為索引組成一個查找樹,這樣就把一個全文匹配的查找轉換成了對樹的查找,這是倒排索引能夠快速進行搜索的根本原因。
倒排索引
一圖勝千言

再舉個例子
假設我們有這樣兩個商品,一個是煙臺紅富士蘋果,一個是蘋果手機 iPhone XS Max。
|
DOCID
|
SKUID
|
標題
|
|---|---|---|
| 666 | 1234 | 煙臺紅富士蘋果 |
| 888 | 1235 | 蘋果手機 iPhone XS Max |
這個表里面的 DOCID 就是唯一標識一條記錄的 ID,和數據庫里面的主鍵是類似的。
倒排索引的存儲
|
TERM
|
DOCID
|
|---|---|
| 煙臺 | 666 |
| 紅富士 | 666 |
| 蘋果 | 666,888 |
| 手機 | 888 |
| iPhone | 888 |
| XS | 888 |
| Max | 888 |
可以看到,這個倒排索引的表,它是以單詞作為索引的 Key,然后每個單詞的倒排索引的值是一個列表,這個列表的元素就是含有這個單詞的商品記錄的 DOCID。
當我們往 ES 寫入商品記錄的時候,ES 會先對需要搜索的字段,也就是商品標題進行分詞。分詞就是把一段連續的文本按照語義拆分成多個單詞。然后 ES 按照單詞來給商品記錄做索引,就形成了上面那個表一樣的倒排索引。當我們搜索關鍵字“蘋果手機”的時候,ES 會對關鍵字也進行分詞,比如說,“蘋果手機”被分為“蘋果”和“手機”。然后,ES 會在倒排索引中去搜索我們輸入的每個關鍵字分詞,搜索結果應該是:
|
TERM
|
DOCID
|
|---|---|
| 蘋果 | 666,888 |
| 手機 | 888 |
666 和 888 這兩條記錄都能匹配上搜索的關鍵詞,但是 888 這個商品比 666 這個商品匹配度更高,因為它兩個單詞都能匹配上,所以按照匹配度把結果做一個排序,最終返回的搜索結果就是:
蘋果Apple iPhone XS Max
煙臺紅富士蘋果
這個搜索過程,其實就是對上面的倒排索引做了二次查找,一次找“蘋果”,一次找“手機”。注意,整個搜索過程中,我們沒有做過任何文本的模糊匹配。ES 的存儲引擎存儲倒排索引時,肯定不是像我們上面表格中展示那樣存成一個二維表,實際上它的物理存儲結構和 MySQL 的 InnoDB 的索引是差不多的,都是一顆查找樹。
elasticsearch中的數據結構
(當然也是lucene的數據結構
升級版倒排索引
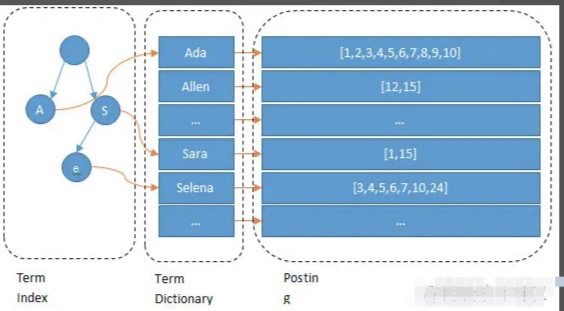
組成三部分
term dictionary
會根據分詞器對文字進行分詞(也就是圖上所看到的Ada/Allen/Sara..),這些分詞匯總起來叫做Term Dictionary
優化手段
該部分的詞會非常非常多,所以es內部對其進行了排序,使用二分查找法來查,故而就不需要遍歷整個詞集
posting list
通過分詞找到對應的記錄,這些文檔ID保存在PostingList
優化手段
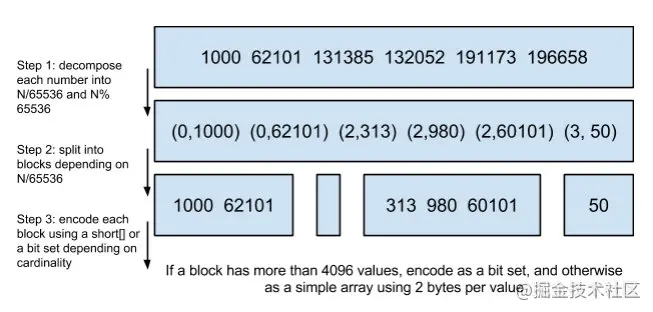
為節約磁盤空間和快速得出交并集結果 。使用FOR以及RBM編碼技術對內容壓縮
FOR原理

RBM原理
term index
由于Term Dictionary的詞實在太多了,不可能把Term Dictionary所有的詞都放在內存中,于是elastic還抽了一層叫做Term Index,這層只存儲 部分 詞的前綴,Term Index會存在內存中(檢索會特別快)
這里遺留一個問題,如果Term Index樹還是很大怎么辦?
找的時候咋找
字典里的索引頁一樣,A開頭的有哪些term,分別在哪頁,可以理解term index是一顆樹。通過term index可以快速地定位到term dictionary的某個offset,然后從這個位置再往后順序查找。大大減少了磁盤隨機讀的次數
優化手段
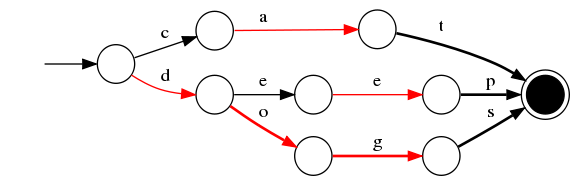
為節省內存 ,該部分在內存中是以FST(https://cs.nyu.edu/~mohri/pub/fla.pdf)的形式保存的
- 1)空間占用小。通過對詞典中單詞前綴和后綴的重復利用,壓縮了存儲空間;
- 2)查詢速度快。O(len(str))的查詢時間復雜度。
更多優化
當對多個字段進行檢索時,利用了bitmap按位與進行歸并優化(本身也是用bitmap的方式進行了存儲
# 假設條件為name=fsdm and age=18取出來的數據如下 [1, 3, 5] -> 10101 [1, 2, 4, 5] -> 11011 # 這樣兩個二進制數組求與便可得出結果: 10001 -> [1, 5] |
注:在特定場景非bitmap存儲時,使用跳表來進行聯合查詢
為啥快
- 磁盤東西盡量搬內存
- 各種奇技淫巧算法
- 苛刻態度使用內存
本文來自博客園,作者:房上的貓,轉載請注明原文鏈接:http://www.rzrgm.cn/lsy131479/p/15184315.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號