
C++ 過濾出字符串的中文(GBK,UTF-8)
最近在處理游戲敏感詞之類的東西,為了加強屏蔽處理,所以需要過濾掉字符串中的除漢字之外的是其他東西如數字,符號,英文字母等。
首先我查閱資料并寫了個函數:
示例:返回輸入字符串中漢字的個數:
std::string StrWithOutSymbol(const std::string &source) { string sourceWithOutSymbol; int i = 0; while (source[i] != 0) { if (source[i] & 0x80 ) { sourceWithOutSymbol += source[i]; sourceWithOutSymbol += source[i + 1]; i += 2; else { i ++; } } return
sourceWithOutSymbol;
}
這個函數的原理是ord($str)&0x80來判斷漢字
80對應的二進制代碼為1000 0000,最高位為一,代表漢字漢字編碼格式通稱為10格式一個漢字占2字節,但只代表一個字符
"Windows中,中文簡體字符集的編碼是同時用1個字節和2個字節來表示的。當高位是0x00~0x7f時,為一個字節,高位為0x80以上時用2個字節表示"
當你發現一個字節的內容大于0x7f,那它肯定是個(跟另外一個字節拼湊成一個)漢字,如何判斷肯定大于0x7f呢?
0x7f(1111111)后面一個數就是0x80(10000000),所以想要大于0x7f,這個字節的最高位都肯定是1,我們只需要判斷這個最高位是否為1就行了。
判斷方法:
位與(相同的位都是1的才為1,否則為0):
如:要判斷一個數的第三位是否是1,只要跟4(100)位與,判斷一個數的第2位是否為1就跟2(10)位與.
同理判斷第八位是否為1只要跟(10000000)也就是0x80位與了.
這里為什么不用>0x7f?php可能還行,但在其他強類型語言里面,1個字節的最高位用來標示負數,一個負數肯定不可能大于0x7f(最大的整數)
再舉個例子:
a的assic碼是97(1100001)
A的assic碼是65(1000001)
b的assic碼是98(1100010)
B的assic碼是66(1000010)
發現一個規律:一個a-z的字母,只要是小寫字母,第六位肯定是1,我們可以用這個來判斷大小寫:
這時候只要跟用以個字母跟0x20(100000)來位與判斷:
if(ord($a)&0x20){
//大寫
}
如何把所有字母改成大寫?第六位的1改成0就行了:
$a='a';
$a = chr(ord($a)&(~0x20));
echo $a;
然后我信心滿滿的吧這個函數加入到項目中去,點擊運行,輸入中文進行檢查,當!項目報錯了????數組越界????
這是為什么,我又定位到報錯的地方,發現我使用的cocos-lua,在向c++傳遞字符串的時候傳進來的字符串是以UTF-8來進行編碼的,我又去找UIF-8的編碼規則發現
UTF-8編碼規則:如果只有一個字節則其最高二進制位為0;如果是多字節,其第一個字節從最高位開始,連續的二進制位值為1的個數決定了其編碼的字節數,其余各字節均以10開頭。UTF-8轉換表表示如下:
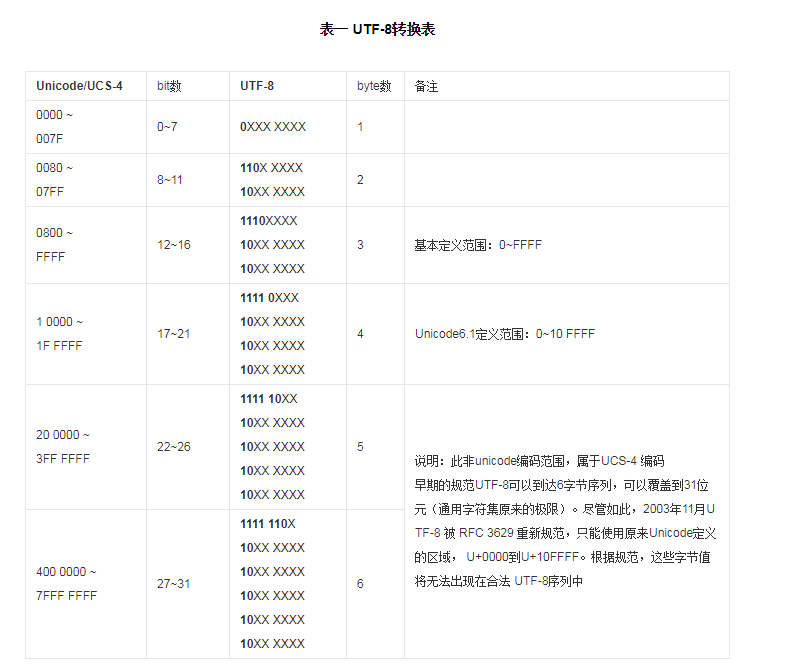
而我之前的是按照GBK編碼進行操作的,GBK每個中文字符只占兩個字節,而utf-8的話中文可能占3個字節,四個字節,甚至是五個六個,所以用剛才那樣的函數就會有越界的情況發生,所以對用UTF-8進行編碼的字符串,就需要進行另外的處理,所以我寫了一個新函數:
對UTF-8編碼的字符串進行中文篩選的函數:
std::string censorStrWithOutSymbol(const std::string &source) { string sourceWithOutSymbol; int i = 0; while (source[i] != 0) { if (source[i] & 0x80 && source[i] & 0x40 && source[i] & 0x20) { int byteCount = 0; if (source[i] & 0x10) { byteCount = 4; } else { byteCount = 3; } for (int a = 0; a < byteCount; a++) { sourceWithOutSymbol += source[i]; i++; } } else if (source[i] & 0x80 && source[i] & 0x40) { i += 2; } else { i += 1; } } return sourceWithOutSymbol; }
點擊運行,成功了!舒服。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號