
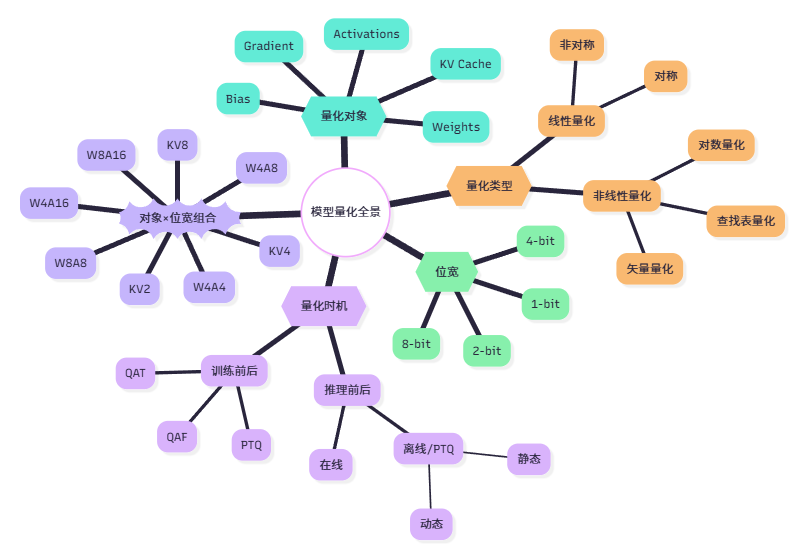
 本文通過五個方面系統介紹了大模型量化技術:首先闡述量化的基本概念,以低比特(INT8/4/2/1)取代 FP32 的壓縮與加速原理;其次按時間維度區分 PTQ、QAT 與 QAF 三種策略,明確何時量化;隨后按對象維度梳理權重、激活、梯度、KV-Cache 及偏置的量化差異;再從粒度維度比較 per-tensor、per-channel、per-group、per-token 的精度與開銷權衡;最后結合位寬與對象給出 W8A16、W4A8、KV4 等典型組合,完整呈現量化在模型大小、推理速度與部署場景中的綜合優化路徑。
本文通過五個方面系統介紹了大模型量化技術:首先闡述量化的基本概念,以低比特(INT8/4/2/1)取代 FP32 的壓縮與加速原理;其次按時間維度區分 PTQ、QAT 與 QAF 三種策略,明確何時量化;隨后按對象維度梳理權重、激活、梯度、KV-Cache 及偏置的量化差異;再從粒度維度比較 per-tensor、per-channel、per-group、per-token 的精度與開銷權衡;最后結合位寬與對象給出 W8A16、W4A8、KV4 等典型組合,完整呈現量化在模型大小、推理速度與部署場景中的綜合優化路徑。
量化(Quantization)是一種關鍵策略,用于優化大型機器學習模型(特別是深度神經網絡),使其在資源受限的硬件(如移動設備、邊緣設備,或為了云端的快速推理)上部署得更加高效。
什么是量化?
量化是指降低用于表示模型參數(權重)和激活值的數值精度的過程。
它不再使用 32 位浮點數(FP32),而通常采用更低精度的格式,例如 16 位浮點(FP16)、8 位整數(INT8)甚至更低。
把 FP32 → INT8/INT4/FP4 等低 bit 類型。
什么要對大模型進行量化?
大模型(LLMs)在推理過程中會消耗大量的內存和計算資源。而量化之后的模型可以實現以下功能:
- 縮小模型體積: 低精度數值占用更少內存。
- 加速推理: 許多硬件加速器(CPU、GPU、NPU)對低精度數據的處理速度更快,因為定點運算相比浮點運算通常更簡單、更快。
- 降低功耗: 由于量化后的數據占用的存儲空間更小,計算量和內存訪問減少,能耗隨之降低。
- 實現邊緣部署: 許多硬件設備(如專用的 AI 芯片、GPU 等)對低精度計算提供了專門的硬件優化,可以高效地處理量化后的神經網絡運算,在資源受限的設備上運行大模型。
量化原理
量化的基本原理,即把模型的參數(weights)等從浮點數(如float32)轉換為定點數(如int8)。在計算時,再將定點數據反量化回浮點數據。
量化的兩個重要過程,一個是量化(Quantize),另一個是反量化(Dequantize):
- 量化就是將浮點型實數量化為整型數(FP32->INT8)
- 反量化就是將整型數轉換為浮點型實數(INT8->FP32)
量化類型
那么具體是如何轉換數值的呢?通常有以下兩種轉換方式:
| 類型 | 子類 | 特點與適用場景 |
|---|---|---|
| 線性量化 | 對稱量化 | 零點為0,適合權重,計算高效,硬件友好。 |
| 非對稱量化 | 引入零點(zero-point),適合激活值,精度高但計算復雜。 | |
| 非線性量化 | — | 如對數量化、矢量量化、查找表量化等,適用于極端壓縮或非均勻分布數據。 |
不同的方法使用不同的量化公式,得到不同的量化參數:
- ??scale
- 0??zero-point
具體的會在數學篇進行介紹(先挖一個坑,后面填吧)
量化策略
訓練前后
從訓練視角來看,我們可以在模型的訓練前或訓練后進行量化,據此可以分為以下幾種:
| 策略 | 階段 | 是否需要重訓練 | 精度 | 適用 |
|---|---|---|---|---|
| PTQ (Post-Training Quant.) | 訓練后 | ? | 稍低 | 快速部署 |
| QAT (Quant.-Aware Training) | 訓練中 | ? | 高 | 極致精度 |
| QAF (Quant.-Aware Fine-tuning) | 微調階段 | ? | 中高 | 資源有限 |
1.訓練后量化(PTQ) :在不重新訓練的情況下,對已訓練好的模型進行量化。
2.量化感知訓練(QAT):在訓練過程中模擬量化,并更新量化參數。
- 通常比 PTQ 精度更高,特別適用于大型或復雜模型。
- 計算開銷更大,因為需要重新訓練。
3.量化感知微調(QAF):從一個已訓練好的 FP32 模型出發,在模擬量化的同時進行少量微調,使權重適應低比特表示。
- 在 PTQ 與完整 QAT 之間取得折中:比從頭訓練快得多,但通常比 PTQ 恢復更多精度——尤其當原始 PTQ 出現明顯下降時。
推理前后
從推理視角來看,根據量化過程在推理前后,可以分為:
| 分類 | 說明 | 子類 | 子類說明 |
|---|---|---|---|
| 離線 | 推理前量化 | 靜態 | 用校準集一次性算好量化參數 |
| 動態 | 每次前向實時算激活值 | ||
| 在線 | 推理時量化 | — |
1.離線量化:上線前完成全部量化,即提前確定好激活值的量化參數 $ S(scale) $ 和 $ Z(zero-point) $,在推理時直接使用。
- 比如之前我們提到PTQ,是離線量化里最常見的實現方式。在大多數情況下,離線量化指的就是PTQ。
離線量化 ≈ PTQ(Post-Training Quantization)
- 離線量化又可以細分為:
- 靜態量化(Static Quantization):同時量化權重和激活值,推理前用校準數據集一次性算好量化參數。
因為屬于離線量化之PTQ,所以也叫靜態離線量化(PTQ-Static)
- 動態量化(Dynamic Quantization):僅量化權重,激活值在推理時實時量化。
因為屬于離線量化之PTQ,所以也叫動態離線量化(PTQ-Dynamic)
2.在線量化:推理時才量化,即在推理過程中動態計算量化參數 $ S(scale) $ 和 $ Z(zero-point) $。
量化對象和量化層級
根據量化的對象的不同,可以分為不同的層級:
- 權重量化(Weight Quantization): 僅量化模型權重。
因為只量化權重,也稱為weight-only quantization
- 激活量化(Activation Quantization): 也對各層輸出(激活值)進行量化。
- 梯度量化(Gradient Quantization): 訓練時對梯度進行量化以減少通信開銷。
- KV緩存量化(KV Cache Quantization): 對注意力中的KV緩存進行量化以降低顯存占用。
- 偏置量化(Bias Quantization): 有時也對偏置進行量化,但通常保持較高精度。
也就是說,在模型量化過程中,量化可以應用于模型的多個部分,包括:
- 模型參數(weights):如權重矩陣,這些是模型訓練過程中學習到的參數。
- 激活值(activations):如神經元的輸出值,這些值在前向傳播過程中動態生成。
- 梯度(gradient):如反向傳播過程中計算的梯度值,用于更新模型參數。
- KV Cache:在 Transformer 的自回歸解碼階段,KV Cache 用于緩存每一層的鍵(Key)和值(Value)張量,以避免重復計算,從而顯著提升長序列生成的效率。
- 偏置(Bias):指模型中各層加性偏置項(如線性層、卷積層后的 bias)。由于偏置參數量遠小于權重(百萬級 vs 十億級),其對整體模型大小的影響有限,因此通常不量化或僅使用較高精度(如 INT16或 FP16),僅在極端壓縮需求下(如邊緣設備部署),才考慮與權重一并量化至 INT8。
| 量化對象 | 是否常被量化 | 量化方式舉例 | 備注 |
|---|---|---|---|
| 模型參數(weights) | ? 是 | INT8/INT4,對稱或非對稱量化,GPTQ/AWQ 等 | 直接決定模型大小與推理速度 |
| 激活值(activations) | ? 是 | 動態或靜態量化,per-token/per-tensor | 顯著降低顯存,需校準分布誤差 |
| 梯度(gradient) | ?/? 可選 | 2–8 bit 均勻量化,Top-K 稀疏化 | 主要用于訓練加速與分布式通信壓縮 |
| KV Cache | ? 是 | INT8/INT4,混合精度保留關鍵 token | 顯著降低顯存,提升吞吐 |
| Bias | ? 通常否 | 保留為 FP16/INT16,極端場景下低比特量化 | 參數量小,量化收益低 |
量化粒度(Granularity)
| 粒度 | 解釋 | 適用對象 |
|---|---|---|
| per-tensor / per-layer | 整層共享一個 scale & zero-point | 通用 |
| per-channel | 每個輸出通道各自 scale | 權重 |
| per-token | 每個 token(行)各自 scale | 激活 |
| per-group / sub-channel | 每連續 N 個元素為一組 scale | 權重/激活 |
- 逐層量化(per-tensor):整個層的所有權重使用相同的縮放因子 $ S $ 和偏移量 $ Z $。
- 逐通道量化(per-channel):每個通道單獨使用一組 $ S $ 和 $ Z $。
- 逐組量化(per-group):將權重按組劃分,每個組使用一組 $ S $ 和 $ Z $。
- 逐 token 量化(per-token):對輸入序列中的 每一個 token(即矩陣的每一行) 單獨計算并使用一組 $ S $ 和 $ Z $。
量化位寬
根據存儲一個權重元素所需的位數,可以分為8bit量化、4bit量化、2bit量化和1bit量化。
| 位寬 | 特點與適用場景 |
|---|---|
| 8-bit | 最常用,精度損失小,廣泛支持(INT8/FP8)。 |
| 4-bit | 極限壓縮,適合大模型部署(如 AWQ、GPTQ)。 |
| 2-bit | 極端壓縮,精度損失大,需配合誤差補償機制。 |
| 1-bit | 極限壓縮,僅限特定任務或研究使用(如 BNN)。 |
對象×位寬組合
根據量化對象和量化位寬的不同組合,可以分為:
| 方案 | 組合名 | 含義 | 示例 |
|---|---|---|---|
| 僅權重 | W8A16 | 權重8bit,激活16bit(未量化,保持原精度) | |
| W4A16 | 權重4bit,激活16bit(未量化,保持原精度) | ||
| 權重+激活 | W8A8 | 權重8bit,激活8bit | SmoothQuant、ZeroQuant |
| W4A8 | 權重4bit,激活8bit | QoQ | |
| W4A4 | 權重4bit,激活4bit | Atom、QuaRot、OmniQuant | |
| KV Cache | KV8 | KV緩存8bit | LMDeploy、TensorRT-LLM |
| KV4 | KV緩存4bit | Atom、QuaRot、QoQ | |
| KV2 | KV緩存2bit | KIVI、KVQuant |
Summary
根據以上介紹的所有內容,為了方便理解記憶總結了一張圖:

 浙公網安備 33010602011771號
浙公網安備 33010602011771號