
使用 ONNX 將 AI 推理引入 Java:企業架構師實用指南
引言
雖然 Python 主導了機器學習生態,但大多數企業應用仍運行在 Java 上。這種脫節造成了部署瓶頸。用 PyTorch 或 Hugging Face 訓練的模型在生產中往往需要 REST 封裝、微服務或多語言變通方式才能運行。這些做法會增加延遲、提高復雜度,并削弱對系統的控制力。
對企業架構師而言,這個挑戰并不陌生:如何在不破壞 Java 系統的簡單性、可觀測性和可靠性的前提下引入現代 AI?這個挑戰延續了我們此前關于將 GPU 級性能帶入企業 Java的探索,其中保持 JVM 原生的效率與可控性被證明至關重要。
開放神經網絡交換(ONNX) 標準給出了有力答案。在微軟的支持下并被各大框架廣泛采用,ONNX 能讓包含命名實體識別(NER)、分類、情感分析等在內的 Transformer 推理原生地在 JVM 中運行。無需 Python 進程,無需容器蔓延。
本文面向希望將機器學習推理引入 Java 生產系統的架構師,提供設計層面的指南。我們將探討分詞器集成、GPU 加速、部署模式以及在受監管的 Java 環境中安全、可擴展地運行 AI 的生命周期策略。
為什么對架構師重要
企業系統日益需要 AI 來驅動客戶體驗、自動化工作流、并從非結構化數據中提取洞見。但在金融、醫療等受監管領域,生產環境更看重可審計性、資源控制與 JVM 原生工具鏈。
雖然 Python 在試驗與訓練階段表現出色,但部署到 Java 系統時會帶來架構摩擦。將模型包裝為 Python 微服務會割裂可觀測性、擴大攻擊面,并引入運行時不一致。
ONNX 改變了這種局面。它為在 Python 中訓練并在 Java 內運行的模型提供標準化的導出格式,原生支持 GPU 加速且不依賴外部運行時。關于在 JVM 內直接利用 GPU 加速的更多模式,請參見:將 GPU 級性能帶入企業 Java。
對架構師而言,ONNX 解鎖四項關鍵收益:
- 語言一致性:推理運行在 JVM 內,而不是旁路的進程。
- 部署簡化:無需管理 Python 運行時或 REST 代理。
- 基礎設施復用:沿用現有的基于 Java 的監控、追蹤與安全控制。
- 可擴展性:在需要時啟用 GPU 執行,無需重構核心邏輯。
通過消除訓練與部署之間的運行時不匹配,ONNX 讓我們可以像對待任何可復用的 Java 模塊一樣對待 AI 推理:模塊化、可觀測、并可經受生產環境的考驗。
設計目標
在 Java 中設計 AI 推理不只是模型準確度問題,更是將機器學習嵌入企業系統的架構、運營與安全肌理中。良好的設計會設定系統級目標,確保 AI 的采用在各環境中可持續、可測試、且符合法規約束。
以下設計目標來自在 Java 中構建機器學習服務的高績效企業團隊的成功實踐:
消除生產中的 Python
ONNX 讓團隊可以將 Python 中訓練的模型導出并在 Java 中原生運行,避免嵌入 Python 運行時、gRPC 橋接或容器化的 Python 推理服務,這些都會增加運維摩擦并復雜化安全部署。
支持可插拔的分詞與推理
分詞器與模型應當模塊化且可配置。分詞器文件(如 tokenizer.json)和模型文件(如 model.onnx)應可按用例互換。通過分詞器與模型的組合,可以適配 NER、分類、摘要等任務,而無需重寫代碼或違反整潔架構原則。
確保 CPU – GPU 的靈活性
相同的推理邏輯應當既能在開發者筆記本(CPU)上運行,也能無改動地擴展到生產 GPU 集群。ONNX Runtime 原生支持通過 CPU 與 CUDA 執行提供者運行推理,使跨環境一致性既可行也具成本效益。
優化為可預測延遲與線程安全
推理必須像任何企業級服務一樣:確定性、線程安全、資源高效。干凈的多線程、模型預加載與顯式內存控制對于滿足 SLA、增強可觀測性并避免并發系統中的競態條件至關重要。
設計為跨棧復用
基于 ONNX 的推理模塊應能夠整潔地集成到 REST API、批處理管道、事件驅動處理器與嵌入式分析層。將預處理、模型執行與后處理解耦,是實現復用、可測試與長期維護合規性的關鍵。
這些目標幫助企業團隊在不犧牲架構完整性、開發敏捷性或合規要求的情況下采用機器學習。
系統架構概覽
將機器學習推理引入企業級 Java 系統不僅僅是模型集成的問題,更需要清晰的架構分層與模塊化。一個健壯的基于 ONNX 的推理系統應被設計為一組松耦合組件,每個組件負責推理生命周期中的特定環節。
核心流程從接收來自 REST 端點、Kafka 流或基于文件的集成等多種來源的輸入開始。原始輸入會交由分詞器組件處理,將其轉換為 Transformer 模型所需的數值格式。分詞器通過一個兼容 Hugging Face 的 tokenizer.json 文件進行配置,確保與訓練時使用的詞表與編碼方式一致。
完成分詞后,輸入流入 ONNX 推理引擎。該組件調用 ONNX Runtime,在 CPU 或 GPU 后端執行模型推理。如果可用 GPU 資源,ONNX Runtime 可無縫委派給基于 CUDA 的執行提供者,而無需更改應用邏輯。推理引擎返回一組預測,通常是logits(模型的原始、未經過 softmax 的輸出分數)或類別 ID,隨后由后處理模塊進行解釋。
后處理器將原始輸出轉化為有意義的領域實體,如標簽、類別或抽取字段。最終結果會路由到下游消費者,無論是業務流程引擎、關系型數據庫還是 HTTP 響應管道。
系統遵循整潔的架構流:適配器到分詞器、分詞器到推理引擎、推理引擎到后處理器、后處理器到消費者。每個模塊都可以獨立開發、測試與部署,使整個管道高度可復用與可維護。
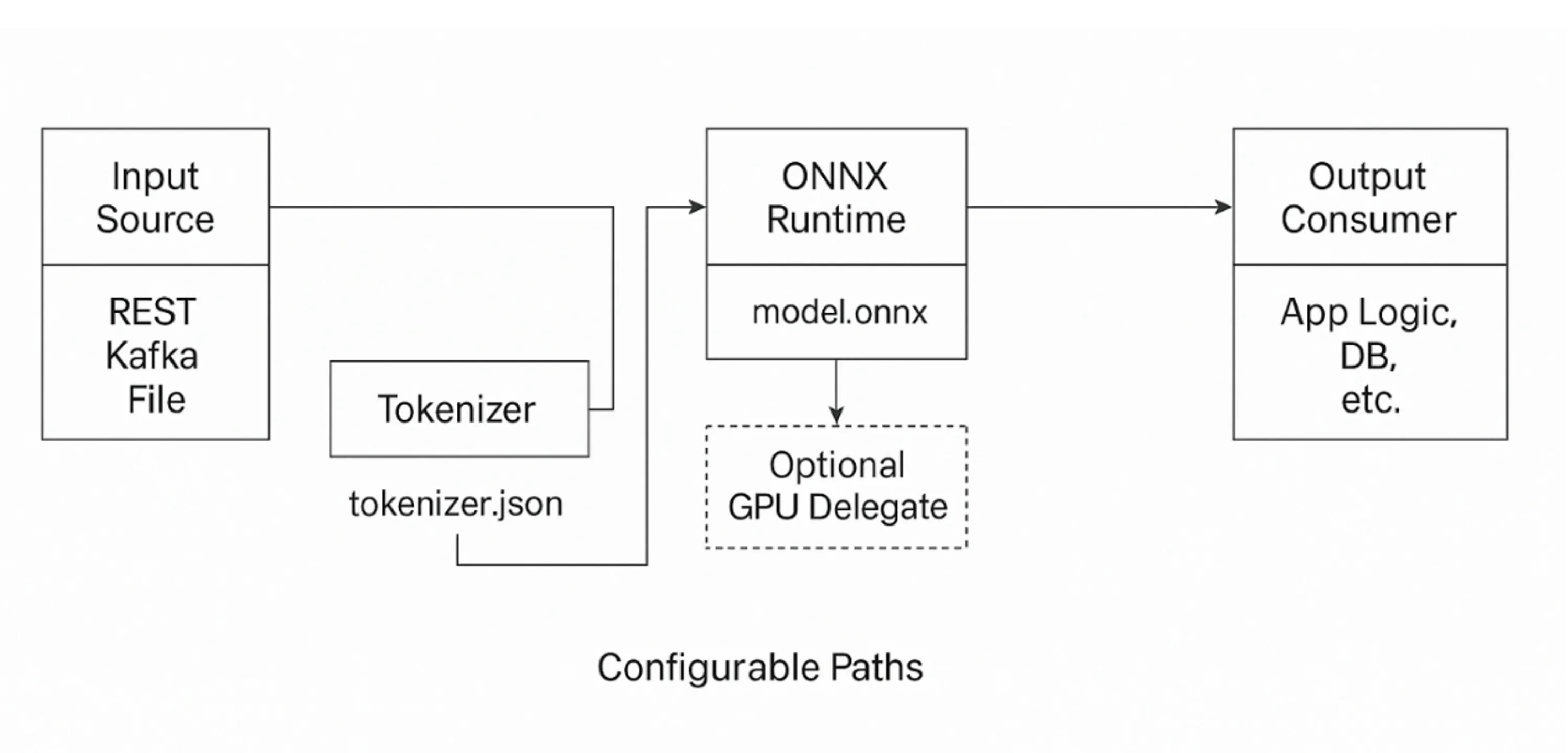
圖 1:Java 中可插拔的 ONNX 推理架構
通過將推理視為一條定義清晰的轉換流水線,而非嵌入到單體服務內部的邏輯,架構師可以對性能、可觀測性與部署進行精細化控制。這種模塊化方法也支持模型的演進,能夠在不破壞系統穩定性的情況下更新分詞器或 ONNX 模型。
模型生命周期
在多數企業場景中,機器學習模型在 Java 生態之外進行訓練,通常使用 Hugging Face Transformers 或 PyTorch 等 Python 框架。模型定稿后,會連同其分詞器配置一起導出為 ONNX 格式,生成 model.onnx 文件與兼容的 tokenizer.json 文件。
對于基于 Java 的推理系統,這些工件相當于版本化輸入,類似外部 JAR 或模式文件。架構師應將其視為受控的部署資產:經過驗證、測試,并在各環境間有序發布,遵循與代碼或數據庫遷移同樣的紀律。
可重復的模型生命周期包括導出模型與分詞器、用代表性用例進行測試,并存儲到內部的注冊表或制品庫。在運行時,推理引擎與分詞器模塊通過配置加載這些文件,實現安全更新而無需重啟或完整重新部署應用。
通過將模型與分詞器提升為一等部署組件,團隊可以獲得可追溯性與版本控制。在受監管環境中,這種提升對于可復現性、可解釋性與回滾能力至關重要。
分詞器架構
分詞器是 Transformer 推理系統中最容易被忽視卻至關重要的組件之一。人們的注意力往往集中在模型上,但分詞器負責將人類可讀文本轉換為模型需要的輸入 ID 與注意力掩碼。只要這一轉換過程存在任何不匹配,就會出現靜默失敗——預測在語法上看似合理,語義上卻不正確。
在 Hugging Face 生態中,分詞邏輯被序列化到 tokenizer.json 文件中。該工件編碼了詞表、分詞策略(例如字節對編碼或 WordPiece)、特殊 token 處理與配置設置。它必須使用訓練時完全相同的分詞器類與參數生成。即便是細微差異,如缺少 [CLS] token 或詞表索引偏移,都會降低性能或破壞推理輸出。
從架構上看,分詞器應以獨立、線程安全的 Java 模塊存在,消費 tokenizer.json 文件并生成可用于推理的結構。它必須接受原始字符串并返回結構化輸出,包含 token ID、注意力掩碼以及(可選)偏移映射,以便下游解釋。在 Java 服務中直接嵌入這層邏輯,而不是依賴 Python 微服務,可以降低延遲并避免脆弱的基礎設施依賴。
在 Java 中構建分詞層還能實現監控、單元測試,并完整集成到企業 CI/CD 流水線,同時便于在禁止 Python 運行時的安全或受監管環境中部署。在我們的架構中,分詞器是一個模塊化的運行時組件,能夠動態加載 tokenizer.json 文件并在不同模型與團隊之間復用。
推理引擎
一旦輸入文本被轉換為 token ID 與注意力掩碼,推理引擎的核心任務就是將這些張量傳入 ONNX 模型并返回有意義的輸出。在 Java 中,這一過程由 ONNX Runtime 的 Java API 負責,提供成熟的綁定以加載模型、構造張量、執行推理與獲取結果。
推理引擎的核心是 OrtSession 類,它是 ONNX 模型的編譯、初始化后的表示,可在請求之間復用。該會話應在應用啟動時初始化,并在各線程之間共享。每次請求都重建會話會引入不必要的延遲與內存壓力。
準備輸入涉及創建 NDArray 張量,如 input_ids、attention_mask,以及可選的 token_type_ids,這些都是 Transformer 模型通常期望的標準輸入。張量由 Java 原生數據結構構造,再傳入 ONNX 會話。會話運行推理并生成輸出,通常包括 logits、類別概率或結構化標簽,具體取決于模型。
在 Java 中,推理調用通常如下:
OrtSession.Result result = session.run(inputs);
ONNX Runtime 還支持執行提供者,用以決定推理在 CPU 還是 GPU 上運行。在啟用了 CUDA 的系統上,推理可以以最小配置卸載到 GPU。如果 GPU 資源不可用,則優雅地回退到 CPU,使得跨環境行為保持一致。這種靈活性讓單一 Java 代碼庫可以從開發者筆記本擴展到生產 GPU 集群,無需分支邏輯,與我們在“將 GPU 級性能帶入企業 Java”一文中討論的理念一脈相承。
從架構角度看,推理引擎必須保持無狀態、線程安全與資源高效。它應提供干凈的可觀測性接口:日志、追蹤與結構化錯誤處理。對于高吞吐場景,池化與微批處理有助于優化性能;在低延遲語境下,內存復用與會話調優對于保持可預測的推理成本至關重要。
將推理視為具有清晰契約與可邊界化性能特征的模塊化服務,架構師即可將 AI 邏輯完全與業務工作流解耦,實現獨立演進與可靠擴展。
部署模式
設計推理引擎只是挑戰的一半;如何在企業環境中部署同樣重要。Java 系統涵蓋從 REST API 到 ETL 管道與實時引擎的廣泛場景,因此基于 ONNX 的推理必須在不重復邏輯或割裂配置的前提下進行適配。
在多數情況下,分詞器與推理引擎作為 Java 庫直接嵌入,從而避免運行時依賴,并與日志、監控與安全框架整潔集成。在 Spring Boot 與 Quarkus 等框架中,推理就是另一個可注入的服務。
更大的團隊常將這層邏輯外置為共享模塊,負責分詞器與模型加載、張量準備與 ONNX 會話執行。外置化促進復用、簡化治理、并在各服務之間提供一致的 AI 行為。
在具備 GPU 的環境中,可以通過配置啟用 ONNX Runtime 的 CUDA 提供者,無需更改代碼。相同的 Java 應用既能在 CPU 集群上運行,也能在 GPU 集群上運行,使部署既可移植又資源感知。
模型制品既可隨應用打包,也可從模型注冊表或掛載卷動態加載。后者支持熱替換、回滾與 A/B 測試,但需要謹慎的驗證與版本管理。關鍵在于靈活性。一個可插拔、對環境敏感的部署模型,無論是嵌入式、共享式還是容器化,都能確保推理無縫融入現有的 CI/CD 與運行策略。
與框架層抽象的比較
Spring AI 等框架通過為 OpenAI、Azure 或 AWS Bedrock 等提供者提供客戶端抽象,簡化了調用外部大型語言模型的過程。這些框架在原型化對話界面與檢索增強生成(RAG)管道方面很有價值,但其工作層次與基于 ONNX 的推理根本不同。前者將推理委托給遠程服務,后者則在 JVM 內直接執行模型,使推理保持確定性、可審計且完全受企業控制。
這種區別具有實際影響。外部框架的輸出不可重復,并依賴第三方提供者的可用性與不斷演進的 API。相比之下,ONNX 推理使用版本化的工件,model.onnx 與 tokenizer.json,在各環境中表現一致,從開發者筆記本到生產 GPU 集群都不例外。這種可重復性對合規與回歸測試至關重要,因為模型行為的細微差異可能帶來顯著的下游影響。它也確保敏感數據不離開企業邊界,這在金融與醫療等領域是基本要求。
也許更為重要的是,ONNX 保持供應商中立。作為被各訓練框架廣泛支持的開放標準,組織可以自由使用偏好的生態進行訓練,并在 Java 中部署,而不必擔心供應商鎖定或 API 漂移。由此,ONNX 與 Spring AI 等框架是互補關系而非競爭關系。前者為合規關鍵的工作負載提供穩定的、進程內的基礎;后者幫助開發者在應用邊緣快速探索生成式用例。對架構師而言,能夠清晰劃定這條邊界,才能確保 AI 采用既具創新性又在運營上可持續。
下一步
既然我們已經闡明如何通過原生分詞與無狀態推理層將 ONNX 模型集成到 Java 系統中,下一步的挑戰是在生產環境中安全、可靠地擴展這套架構。
在下一篇文章中,我們將探討:
- Java 中的安全與審計:實現可追蹤、可解釋且符合法治的 AI 管道。
- 可擴展的推理模式:在 CPU/GPU 線程、異步作業隊列與高吞吐管道間負載均衡,使用 Java 原生構造。
- 內存管理與可觀測性:剖析推理內存占用、追蹤慢路徑,并使用 JVM 原生工具調優延遲。
- 超越 JNI 的演進:動手解讀外部函數與內存 API(JEP 454)作為未來可靠推理管道對 JNI 的替代方案。
作者注:本文實現基于獨立的技術研究,不代表任何特定組織的架構。
本文翻譯自:https://www.infoq.com/articles/onnx-ai-inference-with-java/,作者:Syed Danish Ali

 浙公網安備 33010602011771號
浙公網安備 33010602011771號