
將 GPU 級性能帶到企業級 Java:CUDA 集成實用指南
引言
在企業軟件世界中,Java 依靠其可靠性、可移植性與豐富生態持續占據主導地位。
然而,一旦涉及高性能計算(HPC)或數據密集型作業,Java 的托管運行時與垃圾回收開銷會在滿足現代應用的低延遲與高吞吐需求上帶來挑戰,尤其是那些涉及實時分析、海量日志管道或深度計算的場景。
與此同時,最初為圖像渲染設計的圖形處理器(GPU)已成為并行計算的實用加速器。
像 CUDA 這樣的技術讓開發者能夠駕馭 GPU 的全部算力,在計算密集型任務上獲得顯著的加速效果。
但問題在于:CUDA 主要面向 C/C++,而 Java 開發者由于集成復雜性,鮮少涉足這條路徑。本文旨在彌合這一差距。
我們將逐步講解:
- GPU 級加速對 Java 應用意味著什么
- 并發模型的差異以及為什么 CUDA 至關重要
- 將 CUDA 與 Java 集成的實用方法(JCuda、JNI 等)
- 帶有性能基準的上手用例
- 確保企業級可用性的最佳實踐
無論你是關注性能的工程師,還是探索下一代擴展技術的 Java 架構師,這份指南都適合你。
核心概念理解:多線程、并發、并行與多進程
在深入 GPU 集成之前,清晰理解 Java 開發者常用的不同執行模型至關重要。這些概念常被交叉使用,但彼此含義不同。理解邊界能幫助你把握 CUDA 加速真正閃光之處。
多線程(Multithreading)
多線程是指 CPU(或單個進程)在同一內存空間中并發執行多個線程的能力。在 Java 中,這通常通過 Thread 與 Runnable 或更高級的 ExecutorService 等構造實現。多線程的優勢在于輕量與快速啟動,但由于所有線程共享同一堆內存,也會帶來競態、死鎖與線程爭用等問題。
并發(Concurrency)
并發是指以能讓多個任務隨時間推進的方式來管理它們——要么在單核上交錯執行,要么跨多核并行執行。可以把它視作對任務執行的編排,而非一次性同時做完所有事。Java 通過 java.util.concurrent 等包對并發提供了良好支持。
并行(Parallelism)
并行則是指真正同時執行多個任務,相對于可能包含交錯的并發。真正的并行需要硬件支持,如多核 CPU 或多個執行單元。盡管很多開發者把線程與性能聯系在一起,實際的加速效果取決于任務并行化的有效程度。Java 通過 Fork/Join 框架提供支持,但基于 CPU 的并行性最終受限于核心數量與上下文切換開銷。
多進程(Multiprocessing)
多進程涉及運行多個進程,每個進程擁有獨立的內存空間,可能在不同的 CPU 核上并行執行。它比多線程更隔離、更健壯,但開銷更大。在 Java 中,真正的多進程通常意味著啟動獨立的 JVM 或將工作卸載到微服務。
CUDA 在哪里發揮作用?
上述模型都高度依賴 CPU 核,其數量最多也就幾十個。相較之下,GPU 能并行運行成千上萬的輕量線程。CUDA 允許你使用這種大規模數據并行的執行模型,非常適合矩陣運算、圖像處理、海量日志轉換或脫敏、以及實時數據分析等任務。
這種細粒度的數據級并行幾乎無法用標準的 Java 多線程實現——這正是 CUDA 帶來真正價值的地方。
CUDA 與 Java —— 全景概覽
Java 開發者傳統上工作在受管的 JVM 世界里,距離面向硬件的低層優化相當遙遠。另一方面,CUDA 處于截然不同的世界,通過精細的內存管理、啟動成千上萬的線程、并最大化 GPU 利用率來榨取性能。
那么這兩個世界如何交匯?
什么是 CUDA?
統一計算設備架構(CUDA)是 NVIDIA 的并行計算平臺與 API 模型,允許開發者在 NVIDIA GPU 上實現大規模并行執行的軟件。它通常通過 C 或 C++ 使用,你需要編寫在 GPU 上并行運行的“內核(kernel)”。
CUDA 擅長:
- 數據并行工作負載(如圖像處理、金融仿真、日志轉換)
- 細粒度并行(成千上萬線程)
- 對計算受限操作的加速
為什么 Java 不是原生契合?
Java 并不原生支持 CUDA,原因包括:
- JVM 無法直接訪問 GPU 內存或執行管線
- 大多數 Java 庫以 CPU 與基于線程的并發為中心設計
- Java 的內存管理(垃圾回收、對象生命周期)對 GPU 不友好
但只要采用正確的工具與架構,你完全可以橋接 Java 與 CUDA,在關鍵位置釋放 GPU 加速。
可用的集成選項
將 GPU 加速引入 Java 的方法有多種,各有取舍。
JCuda 是 CUDA 的直接 Java 綁定,同時暴露底層 API 與諸如 Pointer、CUfunction 等高層抽象。它非常適合原型或試驗,但通常需要手動內存管理,可能限制其在生產中的使用。
Java 本地接口(JNI)通過允許你用 C++ 編寫 CUDA 內核并暴露給 Java,提供更強的控制與通常更優的性能。盡管樣板代碼更多,但在需要穩定性與細粒度資源控制的企業級集成中,此法更受青睞。
Java Native Access(JNA)是調用本地代碼時較為簡單、啰嗦更少的替代方案,但對 CUDA 類工作負載而言,它并不總能提供所需的性能或靈活性。
此外還有一些新興工具,如 TornadoVM、Rootbeer 與 Aparapi,它們通過字節碼轉換或 DSL 從 Java 啟用 GPU 加速。這些工具適合研究與試驗,但未必適合規模化生產。
實用集成模式——從 Java 調用 CUDA
在我們可視化了架構之后,來拆解各組件在實踐中的協同工作方式。
為了更好地理解 Java 與 CUDA 在運行時的互動,圖 1 概述了關鍵組件與數據流。
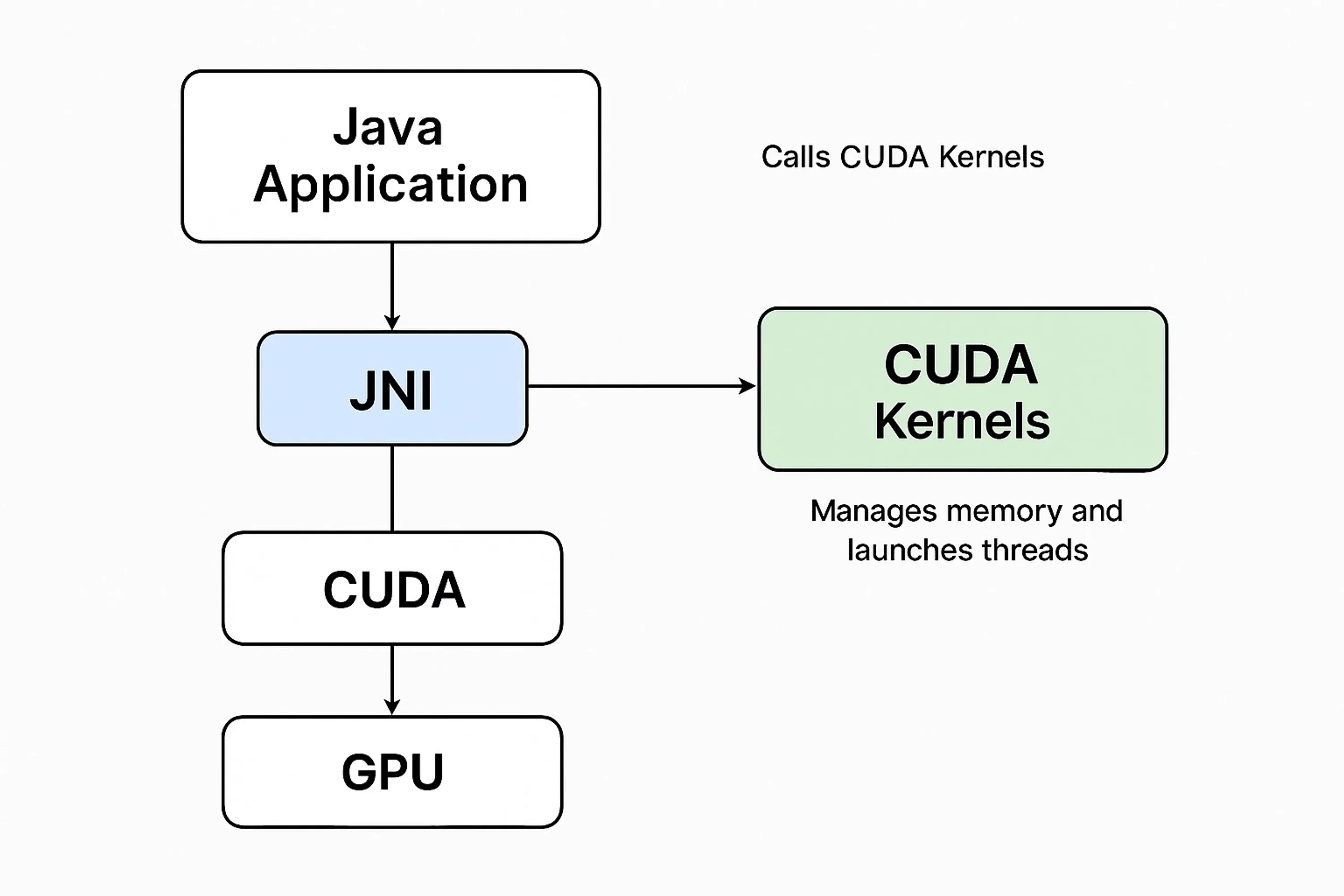
圖 1:通過 JNI 的 Java–CUDA 集成架構
Java 應用層
這是一套標準的 Java 服務,可能是日志框架、分析管道或任何高吞吐企業模塊。與其僅依賴線程池或 Fork/Join 并發框架,計算密集型負載通過本地調用被卸載到 GPU。
在這一層,Java 負責準備輸入數據、觸發到本地后端的 JNI 調用,并將結果集成回主應用流程。例如,你可以把面向 SSH 的加密或安全密鑰哈希在每秒數千會話的場景下卸載給 GPU,從而釋放 CPU 以處理 I/O 與編排工作。
JNI 橋
JNI 是連接 Java 與本地 C++ 代碼(包含 CUDA 邏輯)的橋梁。它負責聲明本地方法、加載共享本地庫(.so、.dll)、并在 Java 堆與本地緩沖區之間傳遞內存。最常見的方式是使用原始類型數組進行高效數據傳輸。
必須謹慎處理內存管理與類型轉換(如 jintArray 到 int*)。此處的錯誤會導致段錯誤或內存泄漏,因此防御式編程與資源清理至關重要。該層通常包含日志與校驗邏輯,以防不安全操作傳播至 GPU 層。
CUDA 內核(C/C++)
并行魔法發生在這里。CUDA 內核是輕量的 C 風格函數,旨在同時在成千上萬的 GPU 線程中運行。內核用 .cu 文件編寫,使用 CUDA C API,并通過熟悉的 <<<blocks, threads>>> 語法啟動。
每個內核在來自 JNI 層的緩沖區上執行大規模并行操作,無論是字符串加密、字節數組哈希還是矩陣變換。共享與全局內存被用于提速,并盡量就地處理以避免不必要的傳輸。例如,可以將 SHA-256 或 AES 加密邏輯應用于整批會話令牌或文件負載。
GPU 執行
內核啟動后,CUDA 負責線程調度、隱藏內存延遲與基本同步。然而,性能調優仍需手動基準測試與謹慎的內核配置。
集成 CUDA 的 Java 開發者必須關注塊與線程的配置、盡量減少內存拷貝瓶頸,并使用諸如 cudaGetLastError() 或 cudaPeekAtLastError() 的 CUDA API 做好錯誤處理。這一層開發階段通常不可見,但在運行時性能與故障隔離中至關重要。
返回流程
處理完成后,結果(如加密鍵、計算數組)返回到 JNI 層,再轉發給 Java 應用進行后續處理——入庫、下游傳遞或在 UI 展示。
集成步驟摘要
- 編寫符合業務邏輯的 CUDA 內核
- 創建暴露內核并支持 JNI 綁定的 C/C++ 包裝器
- 使用
nvcc編譯并生成.so(Linux)或.dll(Windows) - 編寫包含本地方法并通過
System.loadLibrary()加載庫的 Java 類 - 在 Java 與本地代碼之間干凈地處理輸入/輸出與異常
企業用例——用 Java 與 CUDA 加速批量數據加密
為展示在 Java 環境中啟用 GPU 級加速的影響,我們來看一個實際的企業場景:規模化的批量數據加密。許多后端系統常態化處理敏感信息,如用戶憑據、會話令牌、API 密鑰與文件內容,這些通常需要高吞吐地進行哈希或加密。
傳統上,Java 系統依賴 javax.crypto 或 Bouncy Castle 等基于 CPU 的庫來完成這些操作。它們雖然有效,但在每小時需要處理數百萬條記錄或必須保持低延遲響應的環境中,可能難以跟上。這正是 CUDA 并行加速成為吸引人的替代方案的原因。
GPU 對這類工作負載尤為適合,因為加密或哈希邏輯(如 SHA-256)是無狀態、統一且高度可并行化的。無需線程間通信,內核操作可以高效批處理,在某些場景下相較單線程 Java 實現可帶來高達 50 倍的延遲改善。
為驗證這一方法,我們實現了一個簡單的原型管道:Java 層準備用戶數據或會話令牌數組,通過 JNI 傳給本地 C++ 層;隨后 CUDA 內核對數組中每個元素執行 SHA-256 哈希;完成后結果以字節數組形式返回給 Java,準備安全傳輸或存儲。
性能對比
| 方法 | 吞吐(條目/秒) | 備注 |
|---|---|---|
| Java + Bouncy Castle | ~20,000 | 單線程基線 |
| Java + ExecutorService | ~80,000 | 8 核 CPU 并行 |
| Java + CUDA(經 JNI) | ~1,500,000 | 3,000 個 CUDA 線程 |
?? 免責聲明:以上為示意性的合成基準數據。真實結果取決于硬件與調優。
現實收益
將加密工作負載卸載給 GPU 可釋放 CPU 資源以處理應用邏輯與 I/O,非常適合高吞吐微服務。此模式在安全 API 網關、文檔處理管道以及任何需要規模化認證或哈希數據的系統中尤為有效。批處理也變得高效——每次內核啟動可輕松哈希數以萬計的記錄,實現真正的并行安全操作。
最佳實踐與注意事項——讓 Java + CUDA 滿足生產要求
將 Java 與 CUDA 集成開啟了新的性能層級,但強大帶來復雜性。如果你打算在這套棧上構建企業級系統,這里有關鍵考量以保持方案的可靠、可維護與安全。
內存管理
不同于 Java 的垃圾回收運行時,CUDA 需要顯式內存管理。忘記釋放 GPU 內存不僅會泄漏,還可能在負載下迅速耗盡顯存并導致系統崩潰。
使用 cudaMalloc() 與 cudaFree()(均由 CUDA Runtime API (cuda_runtime.h) 定義)顯式管理 GPU 內存。確保每個 JNI 入口點都有相應清理步驟。
在典型集成中,這些方法包裝在本地 C++ 層并通過 JNI 暴露給 Java。例如,你的 Java 類可能定義類似 public native long cudaMalloc(int size) 的本地方法,它在 C++ 內部調用真實的 cudaMalloc() 并把設備指針以 long 返回給 Java。
或者,開發者也可使用 JCuda 或 JavaCPP CUDA 預設等庫在不手寫 JNI 的情況下訪問 CUDA 功能。這些庫提供與 CUDA C API 直接映射的 Java 包裝器與類定義,簡化 JVM 內的內存管理與內核啟動。
Java 與本地代碼的數據編組
通過 JNI 在 Java 與 C/C++ 之間傳遞數據不只是語法問題;若處理不當會成為嚴重的性能瓶頸。堅持使用原始類型數組(int[]、float[] 等)而非復雜對象,并使用 GetPrimitiveArrayCritical() 以獲得低延遲、對 GC 友好的本地內存訪問。注意字符串編碼差異:Java 內部使用修訂版 UTF-8,若處理不當會與標準 C 風格字符串不兼容。為降低開銷,盡量一次性分配本地緩沖并跨多次調用復用。
線程安全
多數 Java 服務本質上是多線程的,這在向下調用本地代碼時會引入風險。除非明確同步,否則不應在跨線程共享 GPU 流與 JNI 句柄。相反,設計你的 JNI 接口為無狀態,并在并發啟動 GPU 內核時依賴線程本地緩沖。synchronized 可助一臂之力,但應謹慎使用,因為它會引入競爭。清晰的狀態分離與每線程資源常常能帶來更安全、更可擴展的 GPU 集成。
原生代碼的測試與調試
不同于 Java 異常,原生 C++ 或 CUDA 代碼的崩潰會終止整個 JVM。這讓測試與調試變得至關重要且更具挑戰。持續使用 CUDA 的錯誤檢查 API,如 cudaGetLastError() 與 cudaPeekAtLastError(),盡早捕獲靜默失敗。早期開發階段將所有本地步驟記錄到單獨文件以隔離問題,避免混入應用日志。保持 CUDA 內核的模塊化,并在 Java 調用之前用 C++ 編寫原生單元測試,可在更廣系統受影響前捕捉底層缺陷。
安全與隔離
涉及加密、令牌生成或密鑰派生等敏感工作負載時,必須將本地代碼視為你的威脅面的一部分。始終在 Java 側驗證輸入后再調用 JNI。避免在 CUDA 內核中動態內存分配,以減少不可預測行為。盡可能減少本地模塊中的依賴,以縮小攻擊面。
提示:為獲得更好的隔離,將本地代碼運行在沙箱化容器(如帶 GPU 訪問的 Docker)中,以限制系統暴露并提升可審計性。
部署與可移植性
部署 GPU 加速的本地代碼遠不止打一個 JAR。你需要處理 GPU 驅動兼容性、CUDA 運行時依賴、本地庫鏈接(.so、.dll)與操作系統差異。如果不加管理,這些細節很容易導致跨環境碎片化。
為確保一致性與可移植性,建議使用 CMake 等構建工具,并通過 nvidia-docker 容器化你的部署,在開發與生產之間對齊 CUDA 版本與系統庫。
快速清單——讓 Java + CUDA 滿足企業級要求
以下是生產級最佳實踐的快速參考:
- 內存:正確使用
cudaMalloc()/cudaFree(),手動管理內存防止泄漏,盡可能復用分配。 - JNI 橋:保持 JNI 層線程安全與無狀態。優先使用原始數組進行數據編組。
- 測試:使用模塊化的 CUDA 內核,并用
cudaGetLastError()或類似診斷驗證每一步。 - 安全:在傳入本地代碼前始終清洗 Java 側輸入。減少 C++ 依賴以降低攻擊面。
- 部署:使用容器化(如 nvidia-docker),并確保 CUDA 版本與驅動在各環境一致。
結論與接下來
Java 與 CUDA 的組合或許并不主流,但在得當的運用下,它能為企業系統解鎖全新的性能門類。無論你是在每秒處理數百萬記錄、卸載安全計算,還是構建近實時分析管道,GPU 級加速都能帶來僅靠 CPU 無法匹敵的速度提升。
在本指南中,我們通過理解并發、并行與多進程之間的基礎差異,探討了如何彌合 Java 與 CUDA 之間的鴻溝;我們走查了基于 JNI 與 CUDA 的實用集成模式,并以一個真實的加密用例與合成基準展示了性能提升;最后,我們覆蓋了企業級最佳實踐,以確保在各環境中的內存安全、運行穩定、可測試與部署可移植性。
為什么這很重要
Java 開發者不再受限于線程池與執行器服務。通過橋接到 CUDA,你可以突破 JVM 核心數量的限制,將 HPC 風格的執行帶入標準企業系統,而無需重寫整個技術棧。
下一步
在后續文章中,我們將探討:
- Java 側的 CPU-GPU 混合調度模式
- 基于 ONNX 的 AI 模型在 GPU 上的推理(含 Java 綁定)
- 采用外部函數與內存 API(JEP 454),它被定位為 JNI 的替代。該 API 提供更安全、更現代的本地庫調用方式。隨著其演進,可能顯著簡化并改善 Java 與 CUDA 之間的互操作。
本文翻譯自:https://www.infoq.com/articles/cuda-integration-for-java/ ,作者:Syed Danish Ali

 浙公網安備 33010602011771號
浙公網安備 33010602011771號