論文導讀:從 TSMC ISSCC 看 SRAM 存算發展
上次集中學習存算工作還是一年半以前,時光如梭,SRAM CIM 范式對比記憶又有新花樣。本篇 blog 針對 ISSCC 2024 34.4 TSMC 的 3 nm 數字 SRAM 近存算 Macro 個例分析[1]。
RAM 的物理-邏輯映射形式化表示
ISSCC CIM Session 相比 Accelerator Session 顯得“稀疏”許多,而 TSMC 的文章更是“惜字如金”,文字和結構都是能省盡省,有一定閱讀門檻。因此在引入文章前,有必要補充一下 SRAM Macro 的形式化描述,用一種符號化、規范化的語言表達 Macro 的物理-邏輯結構映射關系。SRAM 屬于 RAM 的一種,以下分析對所有 RAM 都應是大致適用的。
RAM 包含兩個層面的定義:
- 物理結構:傳統使用陣列 (Array) 即行和列交織的結構組織 cell 進行布局,這是一個二維結構
[Row, Col],各類技術比如 Column Multiplexing, Flying BL 等會對這兩個維度做進一步切分,但不會脫離二維的組織范疇。 - 邏輯結構:即對外暴露出來的邏輯接口,傳統也是一個二維結構
[Depth, Bitwidth],Depth 維度在時間上串行訪問,而 Bitwidth 維度在并行訪問。
用多維張量的思想定義了物理-邏輯維度,不妨繼續借用愛因斯坦標記法[2]定義二者映射關系,所謂物理-邏輯映射,即是以下維度變換關系:
舉個例子,比如一個 64 行,64 列的陣列,列上使用 Column Multiplexing 拆分為 16 x 4 ,每次通過 Col Decoder 選擇 64 列中的 16 列交互。則其物理-邏輯映射關系為 :
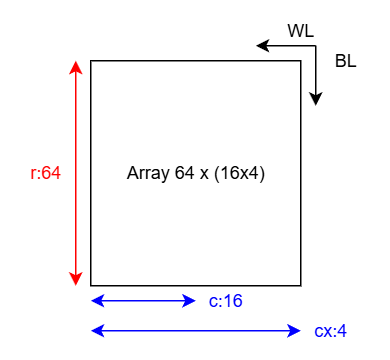
cell 數量為各維度乘積 \(cell=cx\times r \times c\) , bitwidth 為 \(c\),depth 為 \(cx\times r\)。正如之前 blog 所說[3] —— RAM 是一種通過犧牲在 depth 上的并行讀取從而節約讀寫外圍電路面積開銷進而實現高密度存儲數據的結構,以時間換空間。體現在參數上,即是 cell 數量(或稱為存儲內部帶寬)和 bitwidth (存儲 IO 帶寬) 的不對稱,RAM 的高密度和 IO 不對稱二者來源同一;體現在電路上,則是超長的 Bit Line 以及為了防止讀出時 cell 驅動超長的 Bit Line 破壞穩態,采用微擾動以及 Sense Amplifier 結構捕捉變化。
特殊技術分析
結合論文,具體分析存算使用的特殊技術以及如何用上述方法表示。TSMC 架構圖如下,注意34.4.2 右側電路圖(1) 省略了 cell 結構,cell 仍然使用 6 T 結構,(2)本圖相比一般畫法轉置了一下,BL 方向為橫向,后續 Row 和 Col 術語仍然是按前文語義分析而非圖轉置結構。

讀寫異構
讀和寫的邏輯并一致。可能由于存儲介質特性導致,比如 ReRAM 寫慢讀快;有些是特殊架構需求,廣義上來說 CIM 如果不考慮重構為純 Buffer 的需求,其相對于讀出計算單元則是讀出,高讀帶寬低寫帶寬。
一般來說讀寫異構有兩個用途
- 讀寫帶寬不一致,從架構特性上 Data-Locality 理論上僅存在“高讀帶寬-低寫帶寬”的設計,從存儲介質上來看目前也主要是“高讀帶寬-低寫帶寬”
- 重構 cell 組織 layout。
比如論文中寫入帶寬是讀出帶寬的 1/4,解釋理由是方便布線: “Moreover, only one WL in a macro is selected and 4:1 multiplexer is used in the LIO write circuitry to mitigate routing congestion”。
Local IO 以及存算異構
Local IO 中的 IO 是相對于計算單元而非整體存算 macro 而言。前文提到 “存儲內部高帶寬- IO 低帶寬”是 RAM 的底層邏輯,而 SRAM CIM 就是利用 GEMM 中 reduce 操作,在存儲內進行 reduce 將低帶寬的 reduce 結果 (partial sum)暴露到 IO,從而完成算法-架構的映射。換言之,乘加器輸入利用的是存儲內帶寬,怎么會和 IO 概念扯上聯系呢?
這不得不提一個存算比的概念,其實看早期 SRAM CIM 如果不考慮“存算-存儲”功能重構只作為存算模塊存在,是不存在 SA 結構的,存儲單元和乘法單元的配比是 1:1 ,乘法器輸入帶寬完全對應存儲內帶寬[4],每個 cell 有根單獨連線連接乘法器。

而 TSMC 這篇文章實際是 18 個 row 復用一個乘法器,存儲到計算連線是 “cell->bitline -> latch -> LIO -> logic”,需要經過一根公共的 bitline 讀出。存儲單元和乘法單元的配比是 18:1,即存算比提高了。對于每 18 行的小 segmentation 來說,便是通過相對低帶寬的 IO 讀出。如果非要定義血緣,這類計算應該算“近存計算”,cell 和 logic 再次被 local IO 隔開。不同路線數字 SRAM 存算定義如下:
| 路線 | cell 對乘法器比例 | 特點 |
|---|---|---|
| 存算一體 | = 1 | 不存在共用結構,cell 和計算直接連接 |
| 近存算 | > 1 | local IO 隔開 cell 和計算,相當于將多個小 SRAM 和 logic 一起做后端,以 Macro 形態整體交付 |
| 傳統存算分離 | >> 1 | IO 隔開 cell 和計算 |
近存算雖然本質拓撲上和傳統存算分離一致,但參數變化也會導致電路設計收斂到不同的設計選項,比如文章中提到由于 BL 很短,刪除了 SA ,“We eliminated sense amplifiers because there are only 18 Rows in each segment and the BL discharge period is short. This simplifies the read path In LIO circuitry and minimizes the area and read energy ”,讀出路徑改為了一個反饋電路(猜測是 full-swing)和單邊非差分的鎖存器結構。
這篇工作存儲部分使用了高電壓+hvt ,而計算部分使用低電壓 +lvt,存儲和計算是電壓域異構設計。SRAM 和 logic 的器件特性存在差異,隨著節點縮放,SRAM 面積縮放落后于 logic[5]。我猜測 IDEM 2022 的報告是在相同電壓下提取 SRAM Macro 和邏輯的數據,SRAM 犧牲額外的面積應該是為了換取時序性能,即 SRAM 的延時特性是劣于 logic 的,也許是因為 SRAM 超長的 BL?此處電壓域異構設計應該是匹配 SRAM 和 logic 的時序特性。
Flying BL
和 Column Multiplexing 原理思路類似,傳統派 BL 都是并排擺放,為了布局方便將一對 Segmentation 上下擺放,即圖中的 Top 和 Bottom 結構。
ISSCC 24 34.4 的形式化描述
Macro 有 18 個 segments ,每個 segment 結構是個小 SRAM 可以單獨控制,需要將上述公式添加一維擴展到多個 SRAM :
- 總 cell 數量是 \(\text{Seg}\times \text{Depth} \times \text{Bitwidth}\)
- 總控制選擇信號數量是 \(\text{Seg}\times \text{Depth}\)
- 最大讀出帶寬是 \(\text{Seg}\times \text{Bitwidth}\)
注意 Seg 維度同時分配到選擇信號和讀出帶寬信號上,這似乎和前文“串行 Depth-并行 Bitwidth” 思想矛盾。這里代表一種 reconfigurable 能力,既可以充分利用控制信號以小粒度讀寫帶寬交互,也可以充分利用帶寬,而此時減少控制信號自由度。多 SRAM 的這種控制特性和 Byte Enable 信號本質是一樣的。
而在布局上, Seg 映射到行還是列不太清楚,只存在兩種可能,Row=2 Col =9 或者 Row = 18,后文 Row 和 Col 變量實際指一個 Seg 內的物理結構。
ISSCC 34.4 存算的形式化描述如下:
各變量數值和含義如下
| 符號 | 數值 | 含義 |
|---|---|---|
| s | 18 | Segments 的數量 |
| r | 18 | 行數量 |
| ci | 4 | 映射到 Ch In 維度, 也是寫入的 4:1 Mux |
| co | 4 | 映射到 Ch Out 維度 |
| c | 12 | 寫入粒度 12 bit |
如果補充完整的計算結構映射,對于 GEMM 維度 \([T, C_{in}, C_{out}]\) 以及單位精度 \(P\) SRAM CIM 做 weight stationary,故只有 weight 相關維度 \([C_{in}, C_{out},P]\)。
本篇工作表達式為:
這里 GEMM 表示的是空間維度,即一個周期讀出數據,故時間維度的 r 沒有體現最后的維度,此維度可跟據需要選擇映射到輸入或輸出維度之上。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號