

Intention-Aware Online POMDP Planning for Autonomous Driving in a Crowd
一、論文信息
發表日期:2015年
發表機構:新加坡國立大學,計算機科學系
二、論文內容
1.解決問題:無人車在人員密集處的速度規劃算法
2.方法:前向仿真+強化學習概念
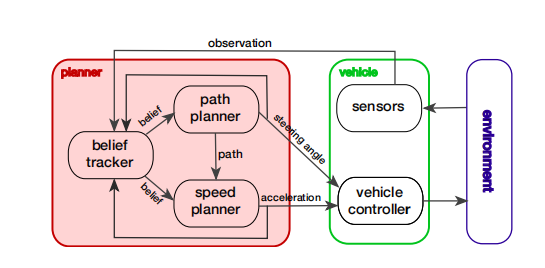

①.路徑規劃和速度規劃進行解耦,進行速度規劃之前路徑已確定。
②.速度規劃采取部分可觀測馬爾可夫決策過程,借用了強化學習的動作價值函數思想,S, A, Z, T, O, R, γ。設計狀態變量、動作空間、動作價值函數。觀測變量包括自車的狀態變量(x,y,theta,v等)和行人的狀態變量(x,y,v)。狀態變量由觀測值推出,基本與觀測變量相同,但是需要由行人時序信息推測出其目的地goal(可能有多個)。動作價值函數考慮與行人距離、與目的地距離、快速性以及行駛的平穩性。動作空間為加速(0.5m/s^2)、減速(-0.5m/s^2)、勻速(0m/s^2)。在每個規劃周期離線向前推導若干步,計算每個動作的價值函數,選取最大的一個進行執行。

三、方法性能分析
優點:具有較好的前瞻性,能夠閉環模擬若干步
缺點:動作空間離散,引起動作不平順;計算量大,無法及時響應突發情況;在論文中只把該算法和一種較為低級的反應式算法進行對比,無法真正證明此算法的優越性;代碼未開源


 浙公網安備 33010602011771號
浙公網安備 33010602011771號