
大模型RAG學習筆記
RAG概念
RAG(Retrieval Augmented Generation)檢索增強生成,通過檢索外部數據,增強大模型的生成效果。
RAG為LLM提供了從某些數據源檢索到的信息,并基于此修正生成的答案。RAG基本上是Search + LLM提示,通過大模型回答查詢,并將搜索算法所找到的信息作為大模型的上下文,查詢和檢索到的上下文都會被注入到發送到LLM的提示語中
RAG 和 Fine-tuning的區別
(1)RAG檢索增強生成,是把內部的文檔數據先進行embedding,借助檢索先獲得大致的知識范圍答案,再結合prompt提示詞給到LLM,讓LLM生成最終的答案
(2)Fine-tuning微調,是用一定量的數據集對LLM進行局部參數的調整,以期望LLM更加理解我們的業務邏輯,有更好的zero-shot能力。
擴展:
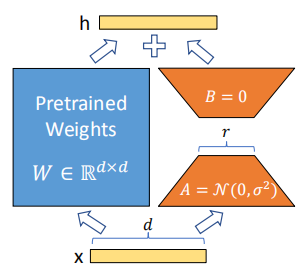
大模型微調方法中,LoRA(Low-Rank Adaptation)微調是當前大模型領域最常用的高效參數微調方法之一,在不改變原始模型權重結構的基礎上,只引入少量可訓練參數(<1%),效果卻逼近全量微調效果
參考網址:【微調實踐】大語言模型LoRA微調細節全解析-CSDN博客
RAG工作流程
(1)知識庫構建:將文本分割成較小的片段(chunks),使用文本嵌入模型(如Sentence-Transformer、Nomic-Embed-Text)將這些片段轉換成向量,并將這些向量存儲在向量數據庫
(2)檢索模塊設計:首先將用戶的輸入問題進行向量化(使用相同的文本嵌入模型), 然后在向量數據庫中檢索與問題向量最相似的知識庫片段(例如通過余弦相似度計算向量相似度),最后根據相似度得分對檢索到的結果進行排序,選擇最相關的片段作為后續生成的輸入
(3)生成模塊設計:首先將檢索到的相關片段與原始問題合并(形成更豐富的上下文信息),再使用大語言模型基于上述上下文信息生成回答

Embedding模型的目標:將語義相似的文本映射到相近的向量空間
向量知識庫(Vector Database):是專門用于存儲、管理、索引和檢索高維向量(Embedding向量)的數據庫系統,根據向量距離查找最相關或相似的數據。向量數據庫向量數據再大模型中起到了連接”知識“和”理解“的橋梁作用。
擴展:向量知識庫的檢索評價標準
(1)準確率(Precision)
準確率 = 檢索相關的向量 / 檢索出的向量總數
(2)召回率(Recall)
召回率 = 檢索相關的向量 / 向量數據庫中相關的向量總數
(3)每秒平均吞吐(QPS)
Query Per Second,QPS是每秒查詢數,每秒向量數據庫能夠處理的查詢請求次數
(4)平均相應延遲(Latency)
向量數據庫的請求平均響應時間
RAG系統搭建流程
RAG具體實現流程:加載文件 => 讀取文本 => 文本分割 =>文本向量化 =>輸?問題向量化 =>在文本向量中匹配出與問題向量最相似的 top k 個 =>匹配出的文本作為上下文和問題?起添加到 prompt 中 =>提交給 LLM 生成回答
索引(indexing):

文本切分成chunks,通常有以下幾種方式:
(1)基于句子的分塊 (Sentence Splitting):核心思想是先切分成句子,再合并句子成塊。
(2)基于遞歸字符分塊 (Recursive Character Text Splitting):核心思想是根據段落、換行等分隔符遞歸地分割文本,盡可能維持文本的邏輯結構。
(3)基于文檔結構的分塊 (Document Structure-aware Chunking):核心思想是利用文檔本身的結構信息進行分割,例如 HTML 的 <div>, <p>, <li> 標簽,Markdown 的標題 #, ##, 列表 -, *,或者 JSON/YAML 的層級結構。
RAG痛點問題策略分析
1.RAG提取的上下文與答案無關
(1)增加召回數量
增加召回的 topK 數量,也就是說,例如原來召回前3個知識塊,修改為召回前5個知識塊。不推薦此種方法,因為知識塊多了,不光會增加token消耗,也會增加大模型回答問題的干擾。
(2)重排(Reranking)
該方法的步驟是,首先檢索出 topN 個知識塊(N > K,過召回),然后再對這 topN 個知識塊進行重排序,取重排序后的 K 個知識塊當作上下文。重排是利用另一個排序模型或排序策略,對知識塊和問題之間進行關系計算與排序。
2.更好的Prompt設計
通過Prompts,讓大模型在找不到答案的情況下,輸出“根據當前知識庫,無法回答該問題”等提示。這樣的提示,就能鼓勵模型承認自己的局限,并更透明地向用戶傳達它的不確定。雖然不能保證 100% 準確度,但在清潔數據之后,精心設計 prompt 是最好的做法之一

 浙公網安備 33010602011771號
浙公網安備 33010602011771號