
深入解析 JuiceFS 垃圾回收機制
在使用 JuiceFS 的過程中,用戶可能會遇到以下常見問題:
- 刪除文件后,為什么對象存儲空間未能及時釋放?
- 回收站中堆積大量文件,如何高效清理?
- 在短時間內批量刪除文件時,刪除操作為什么這么緩慢或性能下降?
JuiceFS的垃圾回收機制背后的執行流程相對復雜,用戶難以直觀理解文件狀態變更和資源釋放的時機。為幫助用戶深入理解文件刪除與存儲回收的內部邏輯,本文將系統梳理垃圾回收的關鍵流程與實現原理,解析常見問題的成因,并提供高效清理與運維的操作建議。
01 前置知識:JuiceFS 文件存儲結構
JuiceFS 采用異步刪除機制處理文件刪除請求,可在第一時間響應用戶操作,并將清理任務延后至系統空閑時執行,從而削峰降壓、降低系統負載,提升整體穩定性。同時,這種分階段的清理策略也為數據恢復預留了更大的靈活性。
這種機制的高效實現,得益于 JuiceFS 的底層設計架構。JuiceFS 采用元數據與數據分離的存儲架構,并對文件數據進行切塊管理。在執行刪除操作時,系統并不會立即清除實際數據,而是僅在元數據層修改刪除標記;真正的數據回收將在后續異步流程中完成。
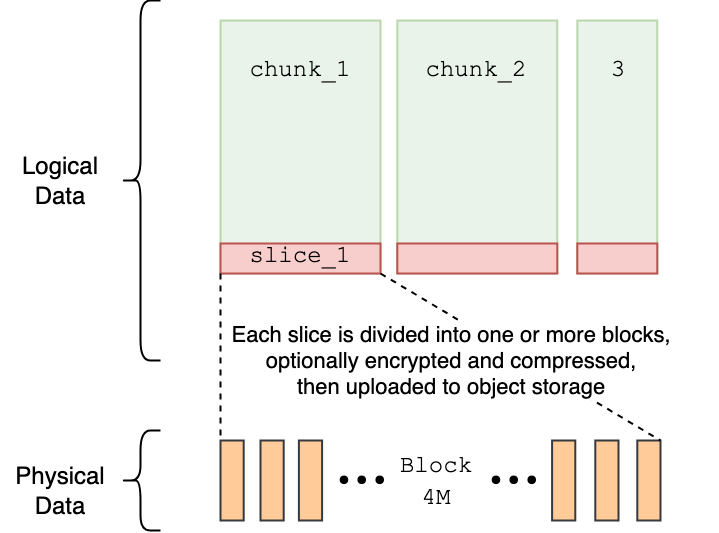
要深入理解異步刪除的執行邏輯,還需要了解 JuiceFS 內部的數據組織方式。系統在底層通過 Chunk、Slice、Block 三層結構來管理文件數據,這一結構不僅決定了文件在存儲與訪問時的性能表現,也直接影響刪除過程中數據的定位、引用計數與清理策略。
- Chunk:每個文件由一個或多個 Chunk 構成,每個 Chunk 最大為 64MB。無論文件大小如何,所有讀寫操作都會根據偏移量定位到對應的 Chunk,提升查找與訪問效率。
- Slice:Chunk 中的實際寫入單位。每次連續寫入生成一個 Slice,Slice 必須完全位于單個 Chunk 內,因此其大小不會超過 64MB。文件寫入過程會產生多個 Slice。
- Block:為提升對象存儲寫入效率,Slice 在寫入前會被進一步拆分成多個 Block(默認最大為 4MB),并通過多線程并發寫入以提高吞吐量。
02 JuiceFS 垃圾回收流程詳解
在了解完前文的背景機制之后,讓我們正式進入文件刪除的主流程。如果進行簡單劃分,JuiceFS 的刪除機制大致可分為三個關鍵過程:回收站管理、文件刪除處理和底層 Slice 清理。
模塊 1:回收站管理
文件刪除流程的起點,始于用戶的刪除請求。當上層接口發起文件刪除操作后,系統并不會立即刪除文件,而是將其移動至回收站(默認開啟)。此過程中,僅有文件父目錄的指向關系發生變更,文件的其他元數據信息和文件內容仍保持不變。
當文件在回收站中存留達到設定的保留期限后,系統通過后臺清理任務或手動方式將其轉為“待刪除文件”,從而進入后續的清理流程。

為更好地理解和管理回收站中的文件,以下將具體說明其目錄結構與工作機制。
回收站的路徑為掛載點下的 .trash 目錄。用戶刪除的文件會被保存到以刪除時間(精確到小時)命名的子目錄中,例如:.trash/2024-01-15-14/。為了避免重名沖突,進入回收站的文件會被自動重命名,重命名規則為:<父目錄ID>_<文件ID>_<原文件名>
對于已被移入回收站的文件,系統也提供了靈活的恢復機制。詳見回收站文檔
移動到回收站的文件不會一直保留,JuiceFS 的回收站清理機制主要包括兩種方式:
- 自動清理由系統的每小時定期觸發的后臺任務(cleanupTrash),按照設定的保留天數逐步清理,將文件標記刪除。
- 手動清理,可通過操作系統的
rm命令或 JuiceFS 提供的juicefs rmr工具直接刪除回收站中的文件或目錄。手動清理相比后臺任務能更快地回收空間,但整個過程依然是異步的(實際回收對象存儲的動作由后續其他任務執行,詳見后文)。
此外,回收站清理的性能受到單個客戶端處理能力的限制。當需要刪除大量文件時,建議在多個客戶端上同時掛載?JuiceFS?并行執行手動清理,從而顯著提升大規模刪除操作的整體效率。
模塊 2:文件刪除
在這一階段,系統首先判斷文件是否仍處于使用中。若文件尚未關閉(例如仍被某些進程占用),則會被暫時置于“暫緩刪除”狀態(sustained file),等待相關使用關系釋放后再重新進入清理流程。若文件已關閉,系統會將其標記為“可清理文件”(內部狀態 delfile),表示該文件可進入刪除隊列處理。
隨后,系統嘗試將這些標記為“可清理”的文件(delfile)加入“文件刪除隊列”。該隊列用于緩存待清理文件,但為了避免影響系統性能,其容量受到限制。若隊列已滿,普通文件的刪除操作將暫時跳過,等待后臺清理任務接手。

對于回收站中的文件,若用戶執行了手動刪除操作,而此時刪除隊列已滿,該操作將同步阻塞,直到隊列空出位置為止。這一策略可確保手動刪除行為在當前流程中完成入隊,不會被跳過。
為保障所有可清理文件最終都能被處理,JuiceFS 提供了一個每小時運行一次的后臺任務 cleanupDeletedFiles,該任務會掃描仍處于“可清理狀態”的文件(delfile),并將它們批量加入刪除隊列,確保清理流程持續推進。
一旦文件成功進入刪除隊列,系統會掃描其關聯的所有 chunk,并對每個 chunk 所包含的 slice 執行引用計數減一操作,然后清理 chunk 元數據。引用計數為 0 的 slice 將被標記為“待清理”,進入后續的 slice 清理階段。
模塊 3:slice 清理與空間回收
在上一模塊中,文件關聯的每個 slice 已完成引用計數更新操作。此階段,系統會繼續判斷這些 slice 當前的引用計數:若引用計數仍大于 0,說明該 slice 仍被其他文件所使用,不會執行清理操作;若引用計數已經降至 0,則意味著該 slice 已完全失效,系統會將其加入 slice 刪除隊列,進入下一步的清理流程。
后臺定時任務 cleanupSlices 會定期掃描該隊列并完成批量清理操作,用戶也可以通過手動觸發 GC 來主動清除這些無效 slice。進入該流程的 slice 會被系統準確定位到對象存儲中的物理 block,并完成實際的刪除操作,從而釋放存儲空間。
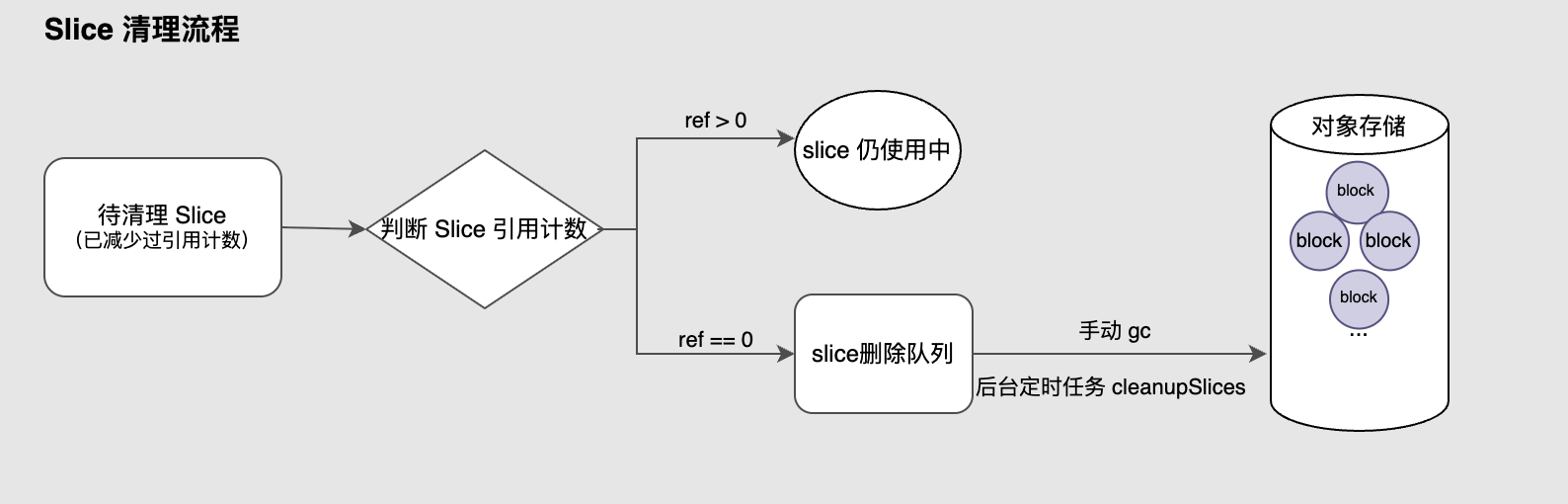
需要注意的是,slice 刪除隊列本身也受到并發與容量的限制。系統支持通過 --max-deletes 參數調整并發線程數量,以控制同時進行的刪除操作數,從而在資源占用與清理效率之間取得平衡。
03 碎片整理機制
上文介紹了文件刪除與回收的完整流程。然而,在 JuiceFS 中還存在另一類“隱性垃圾”——即重復或無用的文件碎片。由于文件在存儲時會被劃分為固定大小的 chunk,每個 chunk 內又包含若干個 slice。若用戶對同一文件進行頻繁的覆蓋寫入或隨機寫入,將導致某些 chunk 中 slice 的排列變得非常零散、不連續。這種情況就稱為碎片化。

盡管碎片化并不會影響文件的正常讀取,但它會帶來多項性能與資源上的負面影響:
- 讀取放大:讀取一個 chunk 時,需要拼接多個分散的 slice,增加了 I/O 操作復雜度。
- 資源占用增加:碎片越多,對應的元數據和對象存儲空間占用也隨之上升,加重系統負擔,降低整體性能。
為優化碎片化問題,JuiceFS 提供了碎片整理功能,通過識別并合并 chunk 中冗余或分散的 slice,將其重構為結構更緊湊的大塊數據,從而顯著減少碎片數量并提升存儲效率。JuiceFS 支持以下兩種整理機制。
自動觸發:系統在文件讀寫過程中會監測 chunk 中 slice 的數量。當某個 chunk 內部的 slice 數達到設定閾值時,系統會自動啟動一個異步任務,執行整理操作。該過程包括:
- 在元數據層申請一個新的 slice ID,用于構建連續的合并數據。
- 從對象存儲中依次讀取舊的 slice 數據,并將其寫入新的連續數據塊中。
- 原有slice引用計數減一。如果開啟了回收站功能,則這部分 Slice 會標記為延遲處理,交由后臺任務進行引用計數更新與清理操作。
手動觸發:用戶可使用 juicefs compact 命令主動對指定路徑進行全面掃描與并發整理。其中 --threads 參數用于控制并發線程數,可根據業務壓力靈活調整,以平衡性能與資源使用。詳細的使用方法,請查看命令文檔。
# 對一個或多個路徑發起整理;可指定并發
juicefs compact /mnt/jfs/pathA /mnt/jfs/pathB --threads 16
# 簡寫
juicefs compact /mnt/jfs/path --p 16
此外,為了輔助用戶了解當前系統中碎片的處理情況,JuiceFS 提供了監控手段幫助用戶通過 juicefs status 命令查看關鍵碎片相關指標,詳見下一章節。
04 垃圾回收相關工具原理與使用建議
GC 工具
GC(Garbage Collection)是 JuiceFS 中用于手動清理的輔助工具,支持多種操作方式,包括僅檢查(dry-run)、掃描并清理等。該工具的核心原理是基于元數據和對象存儲數據的掃描對比,識別并處理那些不再被引用或管理的對象,確保系統數據一致性并釋放無效占用的底層空間。
在某些異常場景或人為操作失誤下,對象存儲中可能會存在脫離 JuiceFS 元數據管理的數據片段,形成所謂的“對象存儲泄露”。雖然發生概率較低,但一旦出現,可通過 GC 工具進行掃描與清除。除此之外,GC 還可用于清理元數據中遺留的無效記錄,例如清理流程中未被完全移除的文件或 slice 信息,以及加速垃圾回收過程中的各個流程,如手動碎片整理、手動清理 “可清理文件”(delfile) 等。
在實際運行過程中,GC 命令會顯示進度條,便于用戶實時查看任務執行狀態。進度條中呈現的各類狀態信息可以與前文提到的圖示內容一一對應,幫助用戶更清晰地理解垃圾回收流程。有些用戶在使用過程中,特別是在資源計費相關操作中,曾表示對這些狀態項的含義感到困惑。而結合圖示與狀態信息進行對照解讀,可以有效提升理解力,幫助掌握整個垃圾回收機制的運作邏輯。
GC 各項指標說明:
- Pending deleted files/data: 待刪除文件數/ 數據量
- Cleaned pending files/data:本次 GC 已刪除文件數/數據量
- Listed slices:文件系統中的所有 slice 數量
- Trash slices:回收站內的 slice
- Cleaned trash slices/data:本次 GC 已清理的回收站 slice/數據量
- Scanned objects:對象存儲中的所有對象
- Valid objects/data: 對象存儲中的有效對象/數據量
- Compacted objects/data::經過碎片整理壓縮后的對象/數據量
- Leaked objects/data:泄漏的對象/數據量
- Skipped objects/data:GC 中跳過的對象/數據量
狀態指標
juicefs status 可用來查看 JuiceFS 的所有狀態,其中與垃圾回收相關的內容在下方羅列。這些指標對應了清理流程中的不同階段,能夠作為判斷系統清理進度與任務狀態的重要依據。如果發現某類碎片數量持續增長、后臺處理能力無法及時響應,用戶可考慮使用手動清理方式加速處理過程,避免系統性能受損。
- Trash Files:回收站中的暫存文件
- Pending Deleted Files:已標記為待刪除的文件
- To be sliced:待整理的碎片任務
- Trash Slices:回收站中的隱藏碎片(來自 compact),可用于數據恢復
- Pending Deleted Slices:引用計數已歸零、等待清理的 slice
最后,我們也為用戶總結了一些基礎且實用的操作建議,幫助在日常使用中更高效地管理 JuiceFS 系統資源,降低運維風險。
- 建議根據具體業務場景設置合理的回收站保留時長,以在數據可恢復性與存儲成本之間取得平衡。對于文件更替頻繁或對存儲成本較為敏感的系統,可適當縮短保留周期,以減少空間浪費。
- 推薦運維人員定期使用
juicefs status等工具,監控關鍵清理指標,如 Pending Delete 文件數、Delayed Slice 數量、Trash 空間占用等,以便及時發現潛在的清理滯后或資源積壓問題。 - 如果系統未啟用自動后臺任務,則應定期執行 GC 操作或相關清理命令,主動清除元數據與對象存儲中的無效殘留,避免長期閑置帶來的性能風險和資源浪費。
- 所有清理類任務應盡量避開業務高峰時段執行,以減少對正常讀寫操作的干擾,保障系統整體穩定性。通過上述策略,用戶可以更有節奏地管理系統生命周期中的刪除與回收過程,實現資源利用效率的持續優化。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號