
九識智能:基于 JuiceFS 的自動駕駛多云億級文件存儲
九識智能 Zelos 是一家專注于自動駕駛與無人配送技術的高新技術企業,具備自動駕駛系統及 AI 芯片的自主研發與規模化落地能力。公司核心產品已在全國 200 多個城市廣泛部署,整車銷售市占率超過 90%,在中國 L4 城配自動駕駛領域持續領先。
隨著業務迅速擴展,公司數據體量從 TB 級快速增長至 PB 級,原有基于 Ceph 的存儲方案面臨高昂成本與維護壓力,同時在處理小文件、元數據、高并發及延遲等方面逐漸出現性能瓶頸,影響仿真和訓練效率。
此外,隨著算法迭代加速和跨地域業務部署,多云環境下的數據流轉與資源調度需求日益頻繁,但存在數據分散、遷移成本高和調度復雜等問題。部分存儲工具社區支持有限、響應慢,進一步增加了運維難度。
面對這些挑戰,九識智能亟需構建一套具備高性價比、強擴展性和易運維能力的云原生存儲架構。在系統評估了 Alluxio、CephFS 等方案后,最終選擇采用 JuiceFS 作為統一的存儲基礎設施。目前,九識已將生產、仿真、訓練與推理等核心業務數據全面遷移至 JuiceFS,構建起一個高效、靈活、統一的存儲底座,全面支撐自動駕駛多場景下的海量數據處理需求。
01 自動駕駛訓練流程與存儲挑戰
九識智能目前致力于 L4 級別自動駕駛技術的研發,主要聚焦于城市智能配送物流場景的應用。在自動駕駛模型的訓練過程中,會產生大量數據,并涉及復雜的處理流程。以下為我們自動駕駛訓練的基本步驟:
- 數據采集與上傳:在車輛上開展標定工作以采集數據,隨后將采集到的數據上傳。
- 算法處理:算法部門提取相關數據用于模型訓練或算法改進,之后將結果交由仿真環節進行打分。
- 仿真驗證與修改:若仿真失敗,返回算法部門進行修改;若仿真成功,則進入模擬環境驗證階段。
- 測試車輛驗證:在模擬環境驗證通過后,在測試車輛上進行測試。若測試失敗,再次返回修改環節;若測試成功,則發布到 OTA。
在整個流程中,數據量急劇增長。每輛車每日約上傳十幾 GB 數據,隨著車輛規模擴大,總數據量已達 PB 級別,尤其在模型訓練階段需高效提取和使用海量數據,對存儲系統的性能、擴展性和穩定性提出了極高要求。
為滿足自動駕駛研發全流程對數據的需求,九識智能需要建立一個具備以下特性的存儲平臺:
- 高性能 I/O:能夠在訓練和仿真階段支撐海量數據的高并發讀取與低延遲訪問。
- 彈性擴展性:可隨著車輛規模擴大靈活擴展至 PB 級甚至更高的數據存儲需求。
- 跨云兼容性:支持多云與自建環境的統一接入,保障數據在不同環境間的流轉與一致性。
- 易運維性:提供簡化的管理與監控能力,降低運維復雜度,確保系統長期穩定運行。
- 成本效益:在保證性能和穩定性的同時,控制總體存儲成本,實現資源利用最大化。
02 存儲選型:JuicsFS、Alluxio、 CephFS
我們曾嘗試使用多種存儲方案,包括 Alluxio、JuiceFS 和 CephFS。
Alluxio 通過 Master 來進行元數據管理,熟悉難度較高。需要單獨部署 Master、Worker 集群,運維復雜度高,且在社區版使用中遇到了諸如卡死、I/O 異常等問題。

CephFS 方面,其元數據存儲在自有 MDS 中,而數據則存放于 RADOS 中,相比之下, JuiceFS 支持多種后端存儲(如 S3、OSS 等),元數據可依托外部數據庫(如 Redis、TiKV)管理,架構更為靈活。
此外,CephFS 的部署和調優極為復雜,需專業團隊深度參與。我們在自建 Ceph 集群時發現,擴展 OSD 及數據再均衡耗時漫長,小文件寫入性能較差,出現寫入速度低下等問題,且因其架構復雜,調優困難,最終決定放棄該方案。

JuiceFS 能夠將各類對象存儲接入本地,并支持跨平臺、跨地域的多主機同時讀寫。采用數據與元數據分離存儲的設計,文件數據經切分后存儲于對象存儲,而元數據可保存在 Redis、MySQL、TiKV 或 SQLite 等多種數據庫中,用戶可根據實際場景和性能需求靈活選擇,并且極大簡化了運維工作。
相比之下,JuiceFS 在多方面表現更為出色。尤其在小文件高并發讀取場景中,性能符合我們的需求,因此約一年前我們全面轉向 JuiceFS,并在多云架構中廣泛應用。
03 JuiceFS 在多云環境中的應用與實踐
JuiceFS 采用元數據與數據分離的存儲架構:元數據層支持多種數據庫引擎,包括 Redis、MySQL、TiKV、SQLite 等,用戶可根據業務規模與可靠性需求靈活選擇;數據層則基于主流對象存儲,實現與不同存儲系統的無縫對接。

目前,我們的系統部署覆蓋聯通、電信、火山、移動、AWS 等多個云平臺,均采用 JuiceFS 作為核心存儲組件。在不同環境中,我們靈活搭配后端存儲與元數據引擎。在自建 IDC 機房中,采用 MinIO 作為對象存儲,配合 Redis 管理元數據;在公有云環境中,則使用 OSS 與 Redis 組合。這一架構不僅提升了系統靈活性,而且在一年多來的實際運行中表現穩定,完全滿足業務需求,具備良好的可用性和用戶體驗。
在 Kubernetes 集群中,我們基于 JuiceFS 提供的 CSI 驅動進行了部署,整體方案與Kubernetes 兼容性良好。我們直接使用官方提供的 Helm Charts 來創建和管理 JuiceFS 存儲卷,并根據不同業務的需求,配置了對應的 Chart,分別對接后端的 Redis 及 OSS 存儲。
在節點本地,我們為 JuiceFS 緩存分配了 NVMe 高速固態硬盤,將其掛載至 /data 目錄。用作緩存層,可顯著提升讀取性能:一旦數據被緩存,后續讀取同一文件的請求可直接從本地 NVMe 盤中獲取,讀寫效率極高。
實踐1-JuiceFS 在訓練平臺的應用:面向上億規模文件的高并發訪問與彈性擴展
我們的訓練平臺架構整體分為多層。底層為基礎設施層,涵蓋存儲資源、網絡資源、計算資源以及若干數組服務機和硬件設備。其上為容器化層,基于 Kubernetes 集群構建,用于支撐各類服務。平臺提供深度 GPU 計算支持、多種開發語言環境及主流深度學習框架。
在深度學習平臺中,用戶可通過 Notebook 或 VR 界面提交訓練任務。任務提交后,系統將通過 Training Operator 進行資源調度與分配。存儲方面,我們基于 PVC(Persistent Volume Claim)預配置了存儲資源,并借助 JuiceFS 實現底層存儲的自動關聯與供給。
我們將 JuiceFS 集成于 Kubeflow 機器學習平臺中,用于模型訓練任務。在 Notebook 環境中創建訓練任務時,系統會自動關聯至后端 JuiceFS 提供的 StorageClass,實現存儲資源的動態分配與管理。同時,集群中部署了監控系統,對存儲性能進行實時觀測。目前監測到讀取吞吐約在 200MB/s 左右,寫入請求量較低,這與我們訓練推理場景中讀多寫少的 I/O 特性較為吻合——讀取操作遠高于寫入。
在性能調優過程中,我們參考了JuiceFS 社區的相關分享,對比了 Redis 與 TiKV 作為元數據引擎的表現。測試結果顯示,TiKV 在讀密集型場景下性能顯著優于 Redis。因此,我們計劃將部分訓練集群的元數據引擎逐步遷移至 TiKV,以進一步提升讀取效率。
目前,我們一個存儲桶中已存有約 700TB 的數據,文件數量達 6 億個。其中存在大量小文件,典型于 AI 訓練任務中常見的數據組織形式。在實際使用中,JuiceFS 在面對高并發的小文件讀寫時表現穩定出色,未出現任何異常,完全滿足生產需求。
在仿真場景中,數據規模已達到 PB 級別,存儲桶以大文件為主。底層存儲資源依托于移動云對象存儲,主要用于仿真數據的集中存放。在實際使用過程中,該存儲方案同樣表現穩定,能夠支撐大規模仿真任務的持續運行。
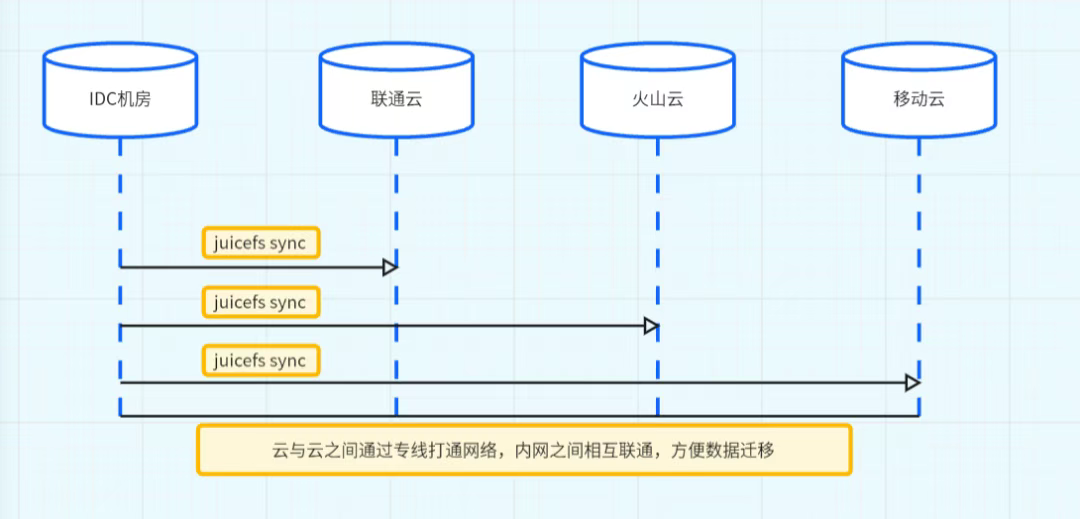
實踐2:JuiceFS 在多云環境中的數據同步
為實現多云環境下的數據同步,我們在多個云服務商之間部署了多條專線,并預先完成了跨云網絡打通。對于需要在不同云中保持一致的訓練數據,我們自主開發了同步工具,該工具底層集成 JuiceFS Sync 命令,能夠高效地將同一份數據同步至多個云環境中。此外,盡管支持跨云掛載,但由于其高度依賴網絡穩定性,我們并不推薦該方式。跨云數據同步的核心挑戰在于網絡可靠性,一旦出現網絡波動,同步過程易受影響,因此需謹慎使用。
04 小結
在生產、仿真、訓練和推理等關鍵環節中,JuiceFS 依托靈活的元數據引擎選擇、多樣化的對象存儲對接方式,以及與 Kubernetes、Kubeflow 的良好兼容性,有效支撐了小文件高并發訪問、跨云數據流轉和性能擴展等場景需求。在大規模數據場景下,JuiceFS 運行穩定,顯著降低了運維復雜度和總體成本,并在系統擴展性方面滿足了當前業務規模。
未來,隨著 TiKV 等元數據引擎的逐步應用以及跨云同步機制的持續優化,JuiceFS 的整體性能和適應性仍有提升空間,將為九識智能在自動駕駛研發中的海量數據處理提供持續支撐。
我們希望本文中的一些實踐經驗,能為正在面臨類似問題的開發者提供參考,如果有其他疑問歡迎加入 JuiceFS 社區與大家共同交流。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號