

轉(zhuǎn)自知乎:Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/310058362Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/310058362Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/310058362Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/310058362Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/3100583Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/310058362Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/310058362Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/31005
Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/310058362Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/310058362Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/310058362本文主要介紹一下我們最近的一篇工作:Sparse R-CNN - 孫培澤的文章 - 知乎 https://zhuanlan.zhihu.com/p/310058362
Sparse R-CNN: End-to-End Object Detection with Learnable Proposals

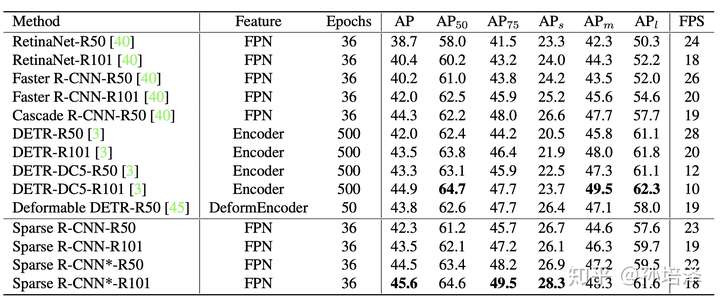
沿著目標(biāo)檢測(cè)領(lǐng)域中Dense和Dense-to-Sparse的框架,Sparse R-CNN建立了一種徹底的Sparse框架, 脫離anchor box,reference point,Region Proposal Network(RPN)等概念,無(wú)需Non-Maximum Suppression(NMS)后處理, 在標(biāo)準(zhǔn)的COCO benchmark上使用ResNet-50 FPN單模型在標(biāo)準(zhǔn)3x training schedule達(dá)到了44.5 AP和 22 FPS。
代碼: https://github.com/PeizeSun/SparseR-CNN
論文鏈接: https://msc.berkeley.edu/research/autonomous-vehicle/sparse_rcnn.pdf
1. Motivation
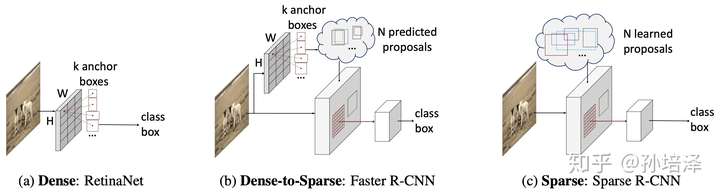
我們先簡(jiǎn)單回顧一下目標(biāo)檢測(cè)領(lǐng)域中主流的兩大類(lèi)方法。
- 第一大類(lèi)是從非Deep時(shí)代就被廣泛應(yīng)用的dense detector,例如DPM,YOLO,RetinaNet,F(xiàn)COS。在dense detector中, 大量的object candidates例如sliding-windows,anchor-boxes, reference-points等被提前預(yù)設(shè)在圖像網(wǎng)格或者特征圖網(wǎng)格上,然后直接預(yù)測(cè)這些candidates到gt的scaling/offest和物體類(lèi)別。
- 第二大類(lèi)是dense-to-sparse detector,例如,R-CNN家族。這類(lèi)方法的特點(diǎn)是對(duì)一組sparse的candidates預(yù)測(cè)回歸和分類(lèi),而這組sparse的candidates來(lái)自于dense detector。
這兩類(lèi)框架推動(dòng)了整個(gè)領(lǐng)域的學(xué)術(shù)研究和工業(yè)應(yīng)用。目標(biāo)檢測(cè)領(lǐng)域看似已經(jīng)飽和,然而dense屬性的一些固有局限總讓人難以滿意:
- NMS 后處理
- many-to-one 正負(fù)樣本分配
- prior candidates的設(shè)計(jì)
所以,一個(gè)很自然的思考方向就是:能不能設(shè)計(jì)一種徹底的sparse框架?最近,DETR給出了一種sparse的設(shè)計(jì)方案。 candidates是一組sparse的learnable object queries,正負(fù)樣本分配是one-to-one的optimal bipartite matching,無(wú)需nms直接輸出最終的檢測(cè)結(jié)果。然而,DETR中每個(gè)object query都和全局的特征圖做attention交互,這本質(zhì)上也是dense。而我們認(rèn)為,sparse的檢測(cè)框架應(yīng)該體現(xiàn)在兩個(gè)方面:sparse candidates和sparse feature interaction。基于此,我們提出了Sparse R-CNN。
Sparse R-CNN拋棄了anchor boxes或者reference point等dense概念,直接從a sparse set of learnable proposals出發(fā),沒(méi)有NMS后處理,整個(gè)網(wǎng)絡(luò)異常干凈和簡(jiǎn)潔,可以看做是一個(gè)全新的檢測(cè)范式。
2.Sparse R-CNN
Sparse R-CNN的object candidates是一組可學(xué)習(xí)的參數(shù),N*4,N代表object candidates的個(gè)數(shù),一般為100~300,4代表物體框的四個(gè)邊界。這組參數(shù)和整個(gè)網(wǎng)絡(luò)中的其他參數(shù)一起被訓(xùn)練優(yōu)化。That's it,完全沒(méi)有dense detector中成千上萬(wàn)的枚舉。這組sparse的object candidates作為proposal boxes用以提取Region of Interest(RoI),預(yù)測(cè)回歸和分類(lèi)。

這組學(xué)習(xí)到的proposal boxes可以理解為圖像中可能出現(xiàn)物體的位置的統(tǒng)計(jì)值,這樣coarse的表征提取出來(lái)的RoI feature顯然不足以精確定位和分類(lèi)物體。于是,我們引入一種特征層面的candidates,proposal features,這也是一組可學(xué)習(xí)的參數(shù),N*d,N代表object candidates的個(gè)數(shù),與proposal boxes一一對(duì)應(yīng),d代表feature的維度,一般為256。這組proposal features與proposal boxes提取出來(lái)的RoI feature做一對(duì)一的交互,從而使得RoI feature的特征更有利于定位和分類(lèi)物體。相比于原始的2-fc Head,我們的設(shè)計(jì)稱(chēng)為Dynamic Instance Interactive Head.
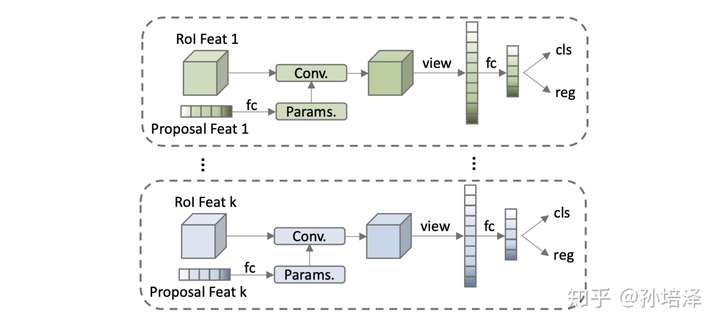
Sparse R-CNN的兩個(gè)顯著特點(diǎn)就是sparse object candidates和sparse feature interaction,既沒(méi)有dense的成千上萬(wàn)的candidates,也沒(méi)有dense的global feature interaction。Sparse R-CNN可以看作是目標(biāo)檢測(cè)框架從dense到dense-to-sparse到sparse的一個(gè)方向拓展。
3. Architecture Design
Sparse R-CNN的網(wǎng)絡(luò)設(shè)計(jì)原型是R-CNN家族。
- Backbone是基于ResNet的FPN。
- Head是一組iterative的Dynamic Instance Interactive Head,上一個(gè)head的output features和output boxes作為下一個(gè)head的proposal features和proposal boxes。Proposal features在與RoI features交互之前做self-attention。
- 訓(xùn)練的損失函數(shù)是基于optimal bipartite matching的set prediction loss。

從Faster
R-CNN(40.2 AP)出發(fā),直接將RPN替換為a sparse set of learnable proposal
boxes,AP降到18.5;引入iterative結(jié)構(gòu)提升AP到32.2;引入dynamic instance
interaction最終提升到42.3 AP。
4. Performance
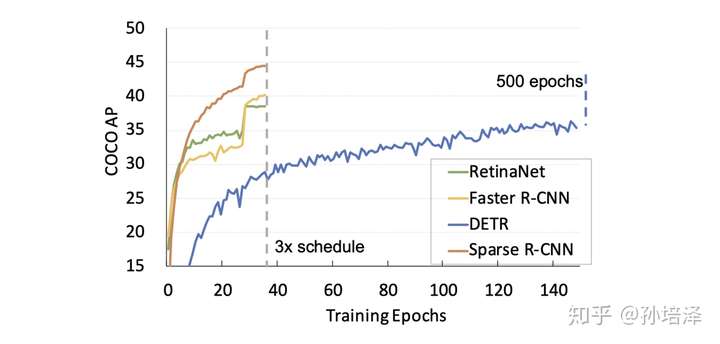
我們沿用了Detectron2的3x training schedule,因此將Sparse R-CNN和Detectorn2中的detectors做比較(很多方法沒(méi)有報(bào)道3x的性能,所以沒(méi)有列出)。同時(shí),我們也列出了同樣不需要NMS后處理的DETR和Deformable DETR的性能。Sparse R-CNN在檢測(cè)精度,推理時(shí)間和訓(xùn)練收斂速度都展現(xiàn)了相當(dāng)有競(jìng)爭(zhēng)力的性能。
5. Conclusion
R-CNN和Fast R-CNN出現(xiàn)后的一段時(shí)期內(nèi),目標(biāo)檢測(cè)領(lǐng)域的一個(gè)重要研究方向是提出更高效的region proposal generator。Faster R-CNN和RPN作為其中的佼佼者展現(xiàn)出廣泛而持續(xù)的影響力。Sparse R-CNN首次展示了簡(jiǎn)單的一組可學(xué)習(xí)的參數(shù)作為proposal boxes即可達(dá)到comparable的性能。我們希望我們的工作能夠帶給大家一些關(guān)于end-to-end object detection的啟發(fā)。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)