
龍信年終技術考核wp
龍信年終技術考核wp
容器密碼:MjAyNeWKoOayuQ==
假期里打的第一場取證比賽,一開始名次還挺高,后面服務器不太會做了,排名直接狂掉,獲獎的名額太少了。其實上學期打的第一場取證也是龍信辦的龍信杯,真的好難,還是這個友好。
1. 分析手機備份文件,該機主的QQ號為?(標準格式:123)
1203494553
手機備份文件里面內容比較少,只能分析出一點點內容。
所以直接看微信,因為微信可以綁定qq號,這里可以看見關聯了一個qq賬號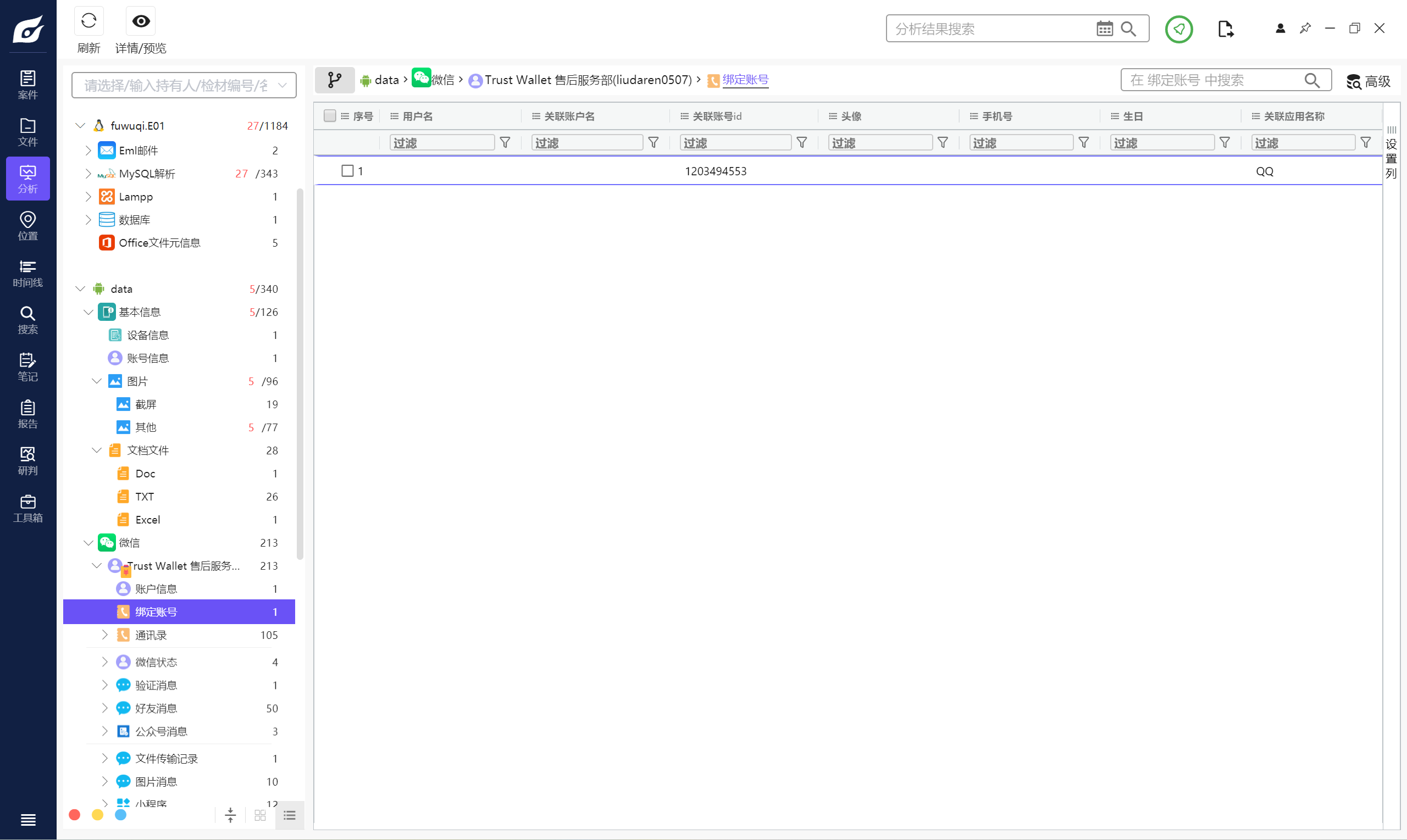
2. 分析手機備份文件,該機主的微信號為?(標準格式:abcdefg)
liudaren0507
直接就是用戶id這個,后面那個是微信為每個用戶分配的內部ip,就是如果創建了一個新微信,它的微信號就是這個內部id。但是這里顯然是前面這個用戶id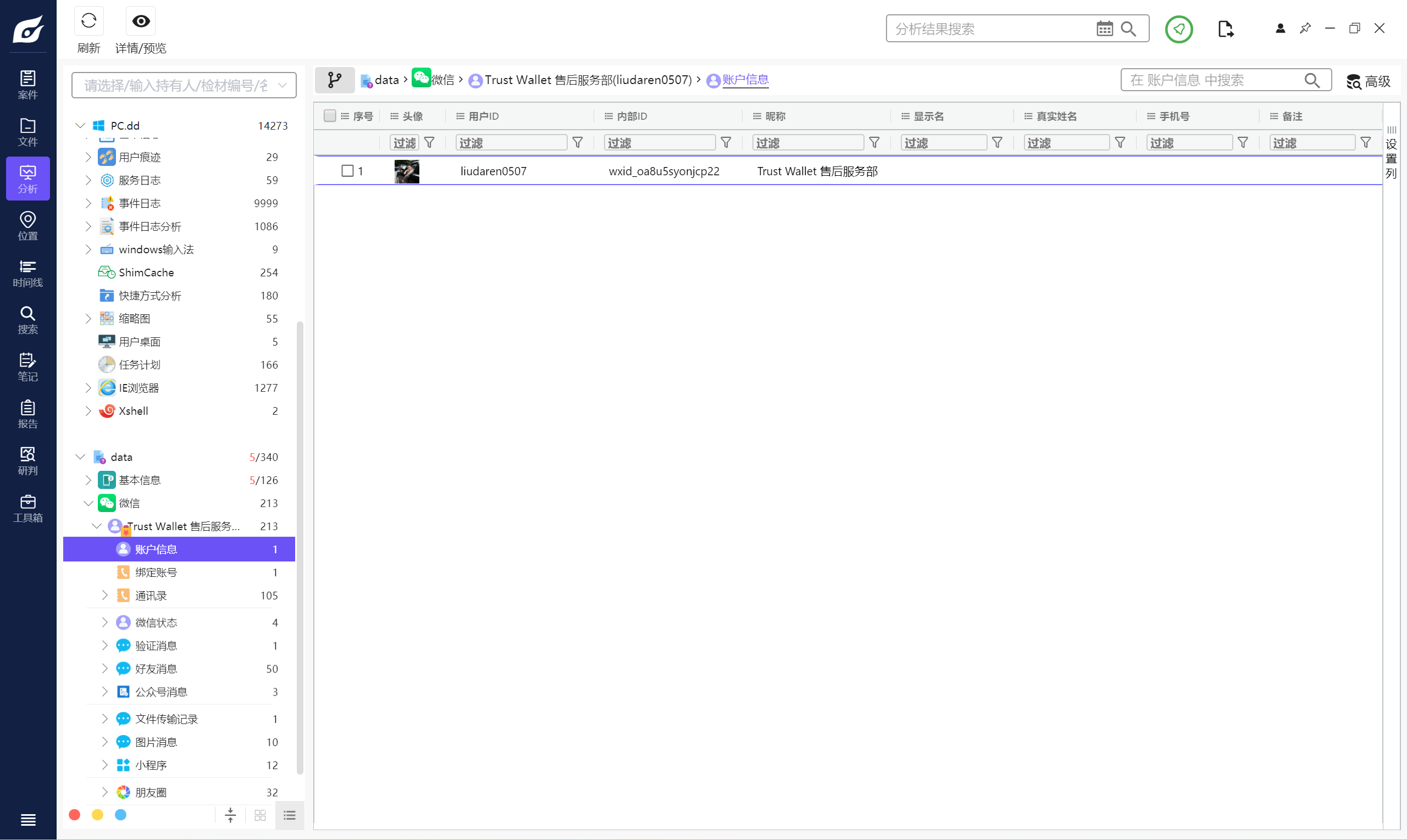
3. 請問該手機機主微信共有_____個現有好友?(標準格式:12)
15
現在回來復現才發現比賽的時候這道題做錯了,好友列表里面16個用戶,包括機主,所以是15個好友。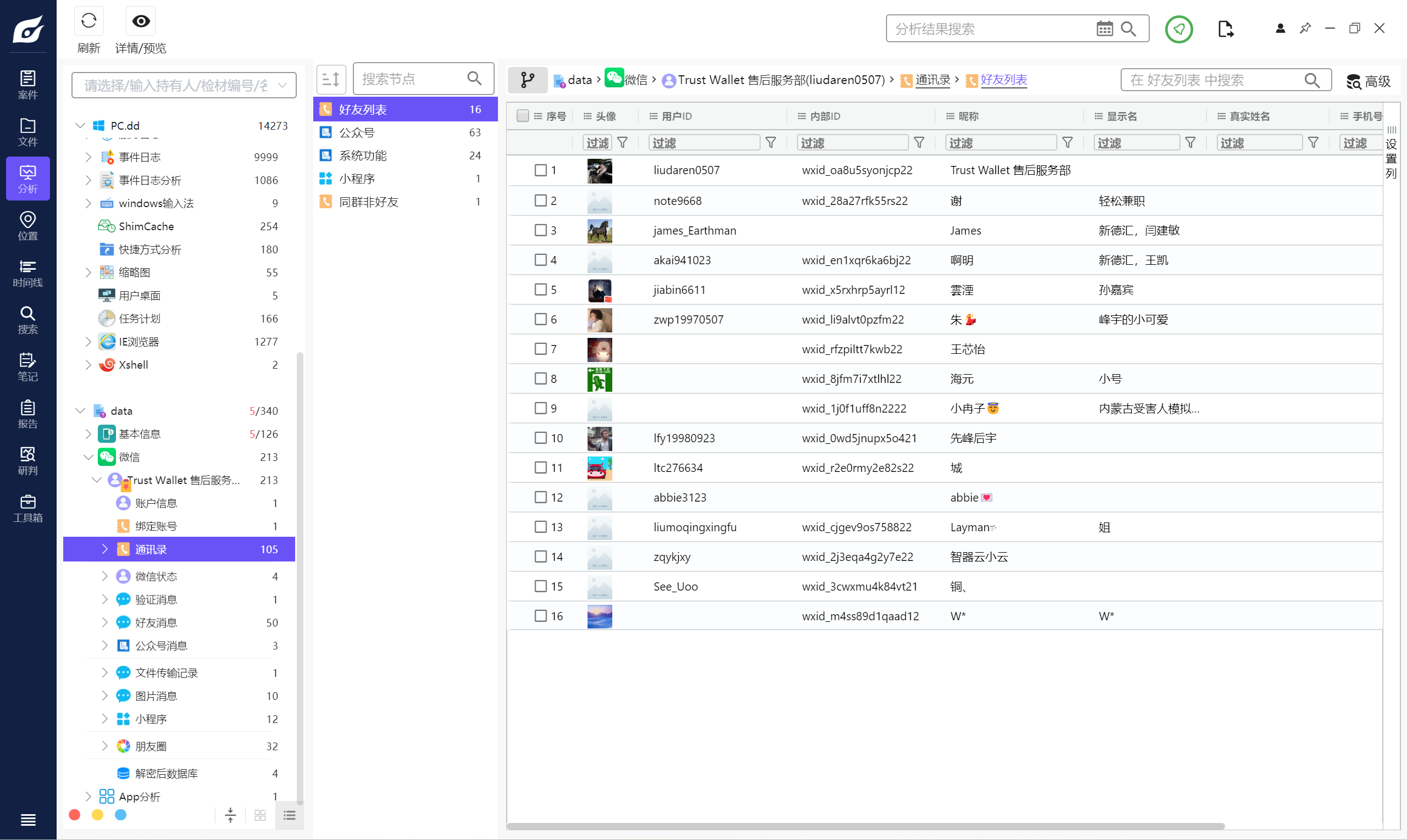
4. 請分析機主的銀行卡卡號是多少?(標準格式:按照實際值填寫)
6231276371853671344
手機檢材里面沒有多少信息了,直接看看沒有被分析出來的內容,發現有個可疑的包,應該就是勇哥發過來的那個apk了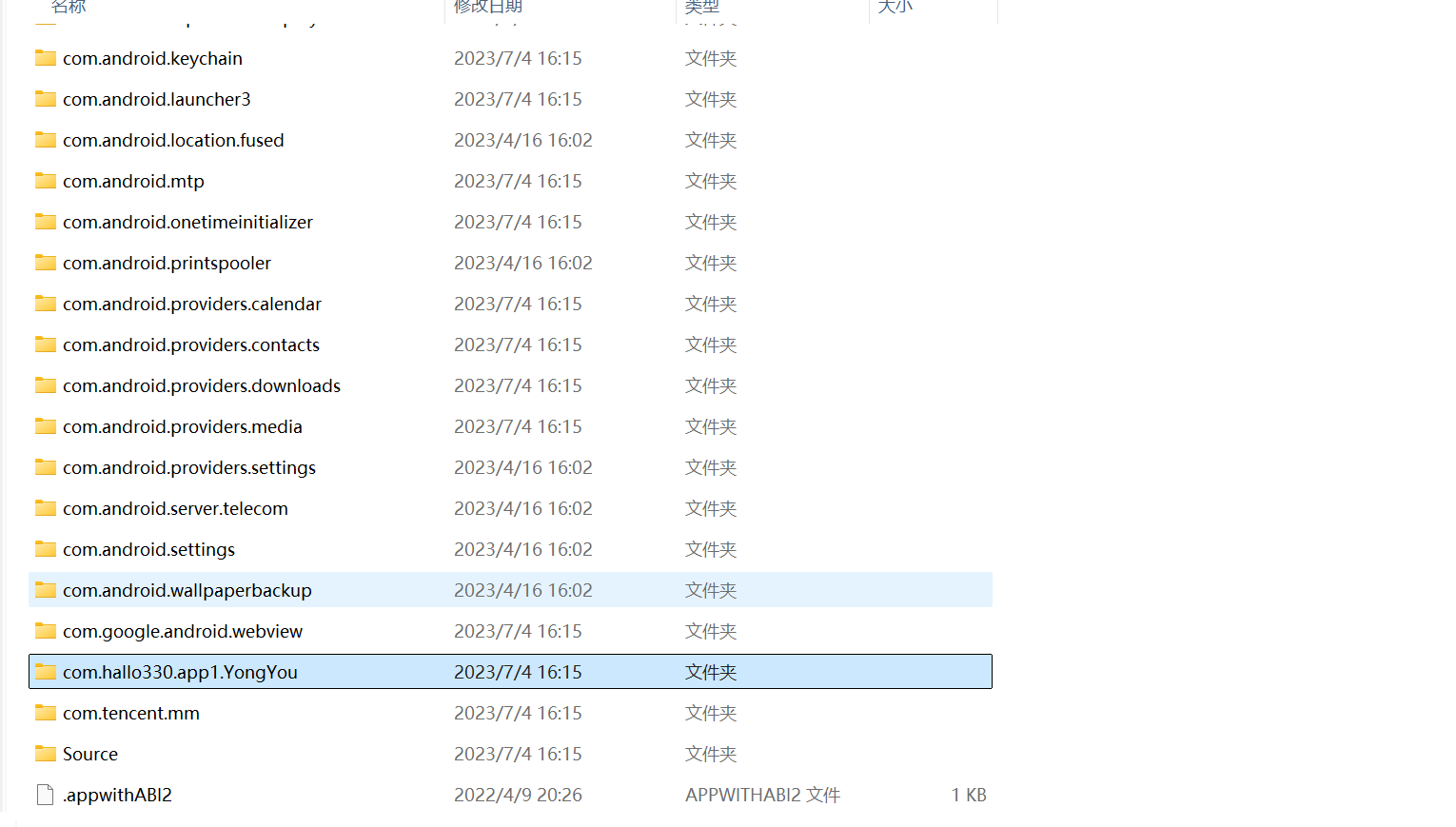
找到數據庫,稍微分析一下聊天記錄,發現第一個就是機主的銀行卡號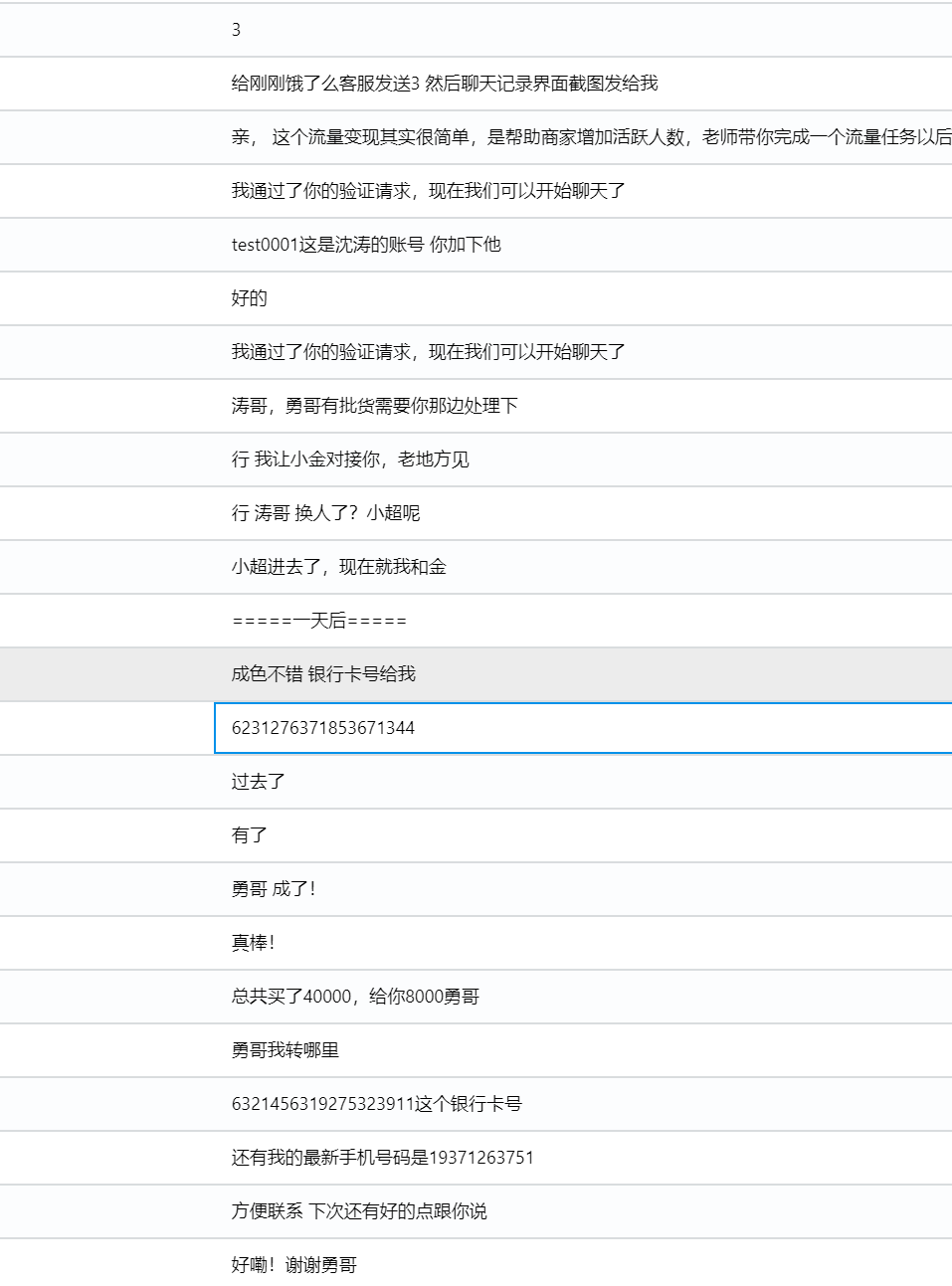
5. 請分析出幕后老大王子勇的最新手機號碼是多少?(標準格式:1234567)
19371263751
接上題最后一張圖,說了最新的手機號
6. 請分析幕后老大的可疑的銀行卡卡號是多少?(標準格式:按照實際值填寫)
6321456319275323911
同樣的位置,就是上面手機號的上一行聊天記錄
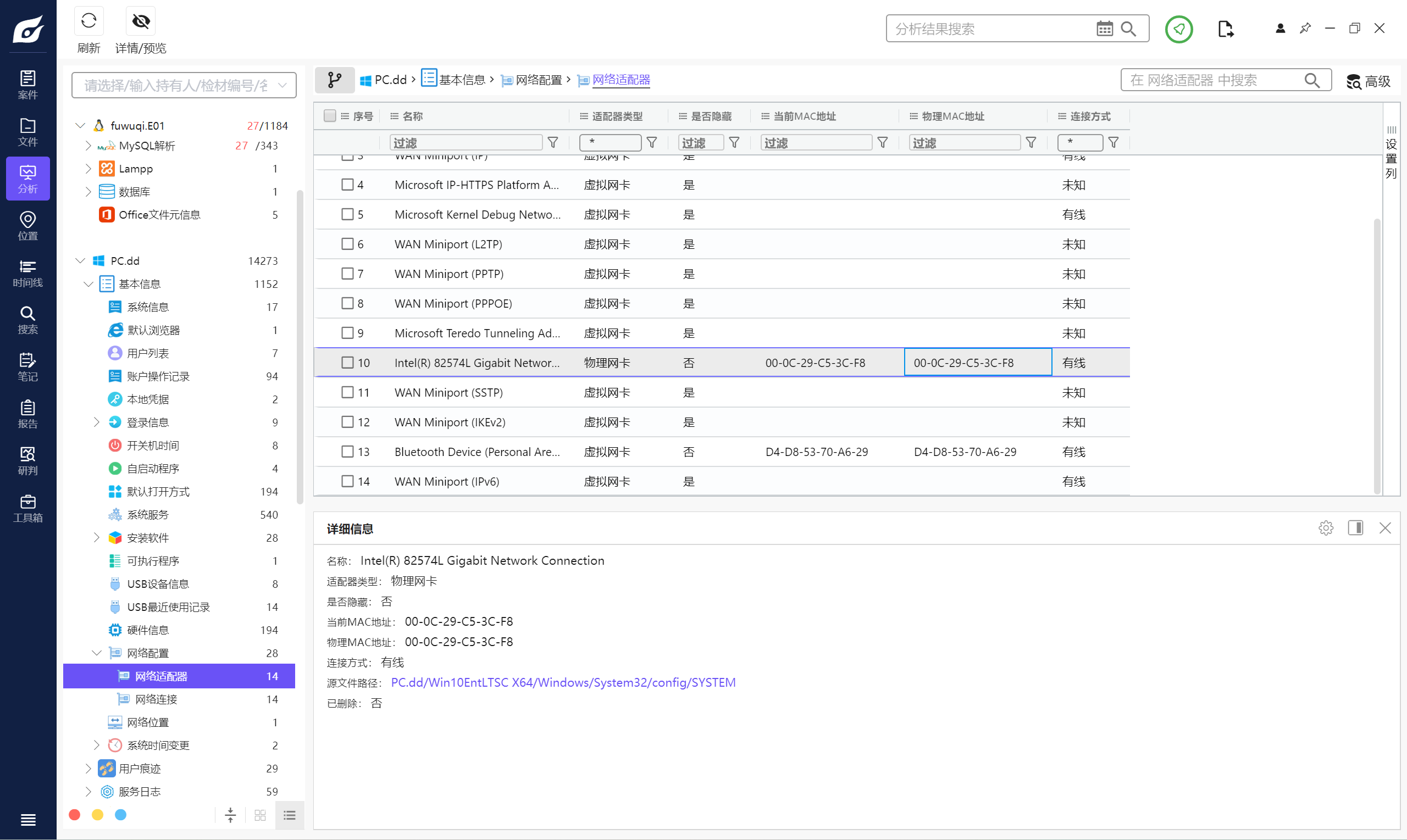
7. 請問計算機的網卡MAC地址是多少 。(標準格式:00-0S-25-C6-E3-5F)
00-0C-29-C5-3C-F8
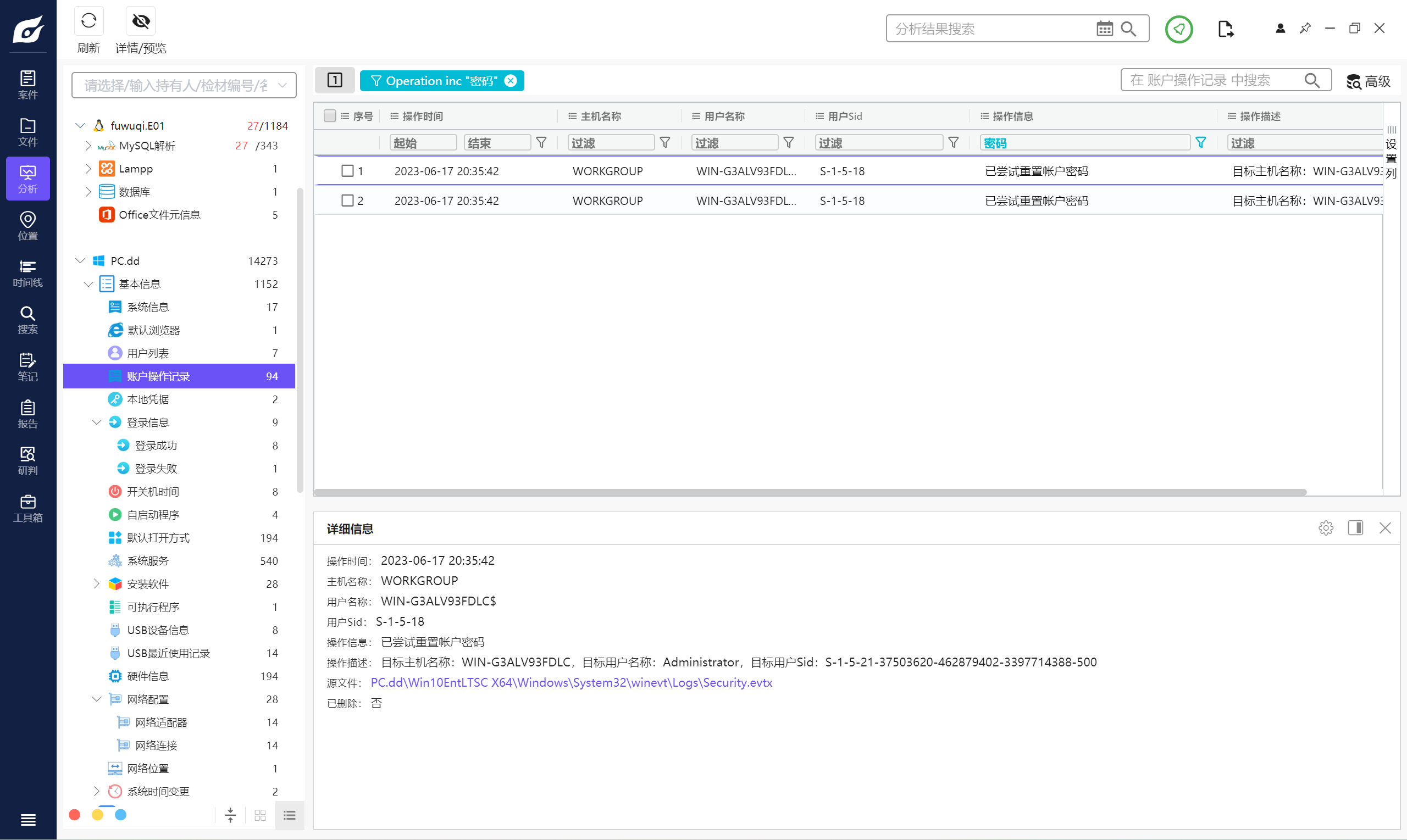
8. 請問計算機管理員用戶的設置密碼時間是什么時候 。(標準格式:1970/06/17 23:25:41)
2023/06/17 20:35:42
9.請分析數據文件夾中的表格文件共有有多少個兩個字的姓名人數。(標準格式:10)
908
直接ai跑腳本然后就行了,下面幾題同理
import pandas as pd
import os
def count_two_character_names(excel_files):
two_character_names_count = 0
for file in excel_files:
try:
# 驗證文件是否存在
if not os.path.exists(file):
print(f"警告: 文件 {file} 不存在")
continue
# 讀取Excel文件
df = pd.read_excel(file)
# 檢查是否存在姓名列,假設列名為 '姓名'
if '姓名' in df.columns:
# 篩選出姓名為兩個字的行
two_character_names = df[df['姓名'].apply(lambda x: isinstance(x, str) and len(x) == 2)]
# 統計數量
two_character_names_count += len(two_character_names)
else:
print(f"警告: 文件 {file} 中不存在 '姓名' 列")
except Exception as e:
print(f"錯誤: 無法讀取文件 {file},錯誤信息: {e}")
print(f"當前工作目錄: {os.getcwd()}")
return two_character_names_count
# 獲取腳本所在目錄
script_directory = os.path.dirname(os.path.abspath(__file__))
# 構造文件的絕對路徑
excel_files = [
os.path.join(script_directory, 'fake_data_1_prefix_1.xlsx'),
os.path.join(script_directory, 'fake_data_1_prefix_2.xlsx'),
os.path.join(script_directory, 'fake_data_1_prefix_3.xlsx'),
os.path.join(script_directory, 'fake_data_1_prefix_4.xlsx'),
os.path.join(script_directory, 'fake_data_1_prefix_5.xlsx'),
os.path.join(script_directory, 'fake_data_1_prefix_6.xlsx'),
os.path.join(script_directory, 'fake_data_1_prefix_7.xlsx'),
os.path.join(script_directory, 'fake_data_1_prefix_8.xlsx'),
os.path.join(script_directory, 'fake_data_1_prefix_9.xlsx'),
os.path.join(script_directory, 'fake_data_1_prefix_10.xlsx')
]
# 打印文件路徑以確認
for file in excel_files:
print(f"文件路徑: {file}")
# 統計并打印結果
result = count_two_character_names(excel_files)
print(f"十個Excel文件中姓名為兩個字的總數: {result}")
10.請分析數據文件夾中表格共有表格共有多少個男性。(標準格式:10)
479
import pandas as pd
import os
import re
# 文件前綴和后綴
file_prefix = 'fake_data_1_prefix_'
file_extension = '.xlsx'
# 男性計數
total_male_count = 0
# 遍歷所有文件
for i in range(1, 11): # 假設文件名從 1 到 10
file_name = f"{file_prefix}{i}{file_extension}"
print(f"正在檢查文件: {file_name}") # 調試信息
if os.path.exists(file_name):
try:
# 讀取 Excel 文件
df = pd.read_excel(file_name)
# 檢查是否存在身份證號列
if '身份證號' not in df.columns:
print(f"警告: 文件 {file_name} 中缺少身份證號列")
continue
# 確保身份證號列中的所有值都是字符串
df['身份證號'] = df['身份證號'].astype(str)
# 定義一個函數來根據身份證號判斷性別
def get_gender_from_id(id_number):
if len(id_number) == 18: # 確保是18位身份證號
gender_digit = int(id_number[16]) # 第17位
return '男' if gender_digit % 2 != 0 else '女'
return None
# 應用函數到身份證號列,創建性別列
df['性別'] = df['身份證號'].apply(get_gender_from_id)
# 統計男性數量
male_count = (df['性別'] == '男').sum()
print(f"文件 {file_name} 中男性數量為: {male_count}")
# 累加男性數量
total_male_count += male_count
except Exception as e:
print(f"錯誤: 在處理文件 {file_name} 時發生錯誤: {e}")
else:
print(f"警告: 文件 {file_name} 不存在")
# 打印總男性數量
print(f"數據文件夾中所有表格的男性總數為: {total_male_count}")
11.請分析數據文件夾中表格共有多少姓陳的人。(標準格式:10)
106
import pandas as pd
# 初始化計數器
chen_count = 0
# 假設表格文件名是 'table1.xlsx', 'table2.xlsx', ..., 'table10.xlsx'
for i in range(1, 11):
file_name = f'fake_data_1_prefix_{i}.xlsx'
# 讀取Excel文件
try:
df = pd.read_excel(file_name)
# 檢查是否存在“姓名”列
if '姓名' in df.columns:
# 統計姓“陳”的人數
chen_count += df[df['姓名'].str.startswith('陳')].shape[0]
else:
print(f"警告:文件 {file_name} 中沒有“姓名”列。")
except FileNotFoundError:
print(f"警告:文件 {file_name} 未找到。")
except Exception as e:
print(f"錯誤:讀取文件 {file_name} 時出錯:{e}")
# 輸出統計結果
print(f"總共有 {chen_count} 個姓陳的人。")
12.請分析數據文件夾中表格共有1950年至1970年的人數是多少。(標準格式:10)
419
import pandas as pd
import os
import re
file_prefix = 'fake_data_1_prefix_'
file_extension = '.xlsx'
total_count = 0 # 用于統計1950年至1970年出生的總人數
# 正則表達式用于從18位身份證號中提取出生年份
birth_year_pattern = re.compile(r'(\d{6})(\d{8})(\d{3}[\dXx])')
for i in range(1, 11):
file_name = f"{file_prefix}{i}{file_extension}"
if os.path.exists(file_name):
try:
df = pd.read_excel(file_name)
# 檢查身份證號列是否存在
if '身份證號' not in df.columns:
print(f"警告: 文件 {file_name} 中缺少身份證號列")
continue
# 確保身份證號列中的所有值都是字符串
df['身份證號'] = df['身份證號'].astype(str)
# 提取出生年份
def extract_birth_year(id_number):
match = birth_year_pattern.match(id_number)
if match:
birth_date_str = match.group(2)[:4] # 提取YYYY部分
return int(birth_date_str)
return None
df['出生年份'] = df['身份證號'].apply(extract_birth_year)
# 篩選出1950年至1970年出生的記錄
mask = (df['出生年份'] >= 1950) & (df['出生年份'] <= 1970)
# 統計符合條件的記錄數
total_count += mask.sum()
except Exception as e:
print(f"錯誤: 在處理文件 {file_name} 時發生錯誤: {e}")
else:
print(f"警告: 文件 {file_name} 不存在")
print(f"1950年至1970年間出生的總人數為: {total_count}")
13. 請問計算機映射盤的掛載位置盤符是什么 。(標準格式:B)
Z
仿真起來直接看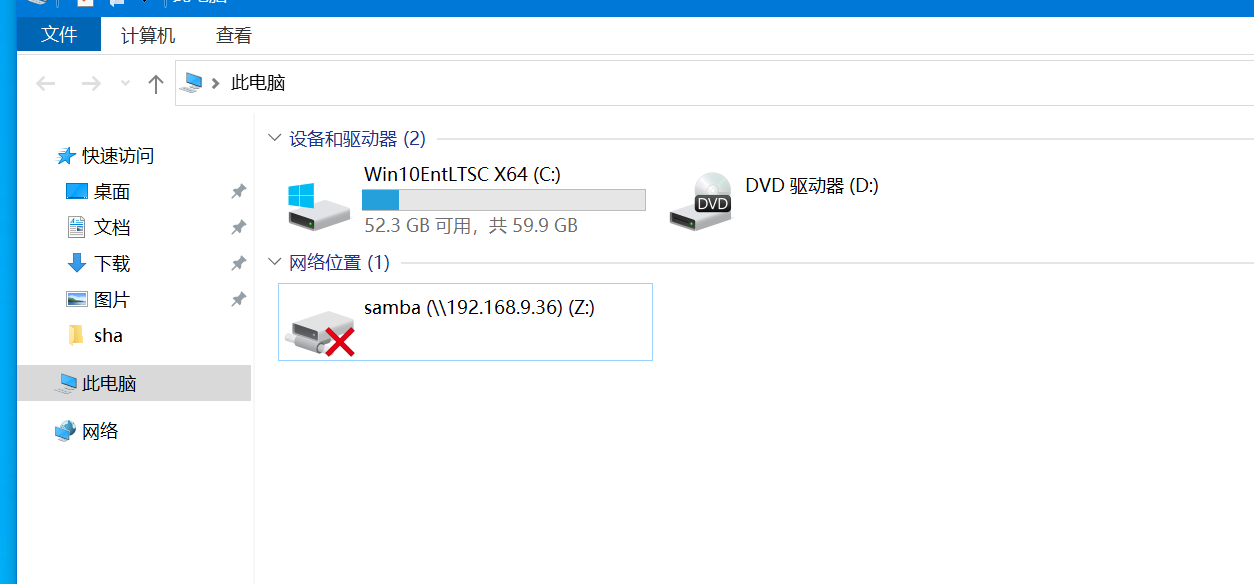
14. 請問機主郵箱賬號的顯示名稱是什么 。(標準格式:abcd)
kkkk
仿真服務器,然后發現計算機里面有網絡映射,連上去,打開foxmail
15. 請問機主郵箱的定時收取郵件是間隔多少分鐘 。(標準格式:10)
15
在郵箱設置里面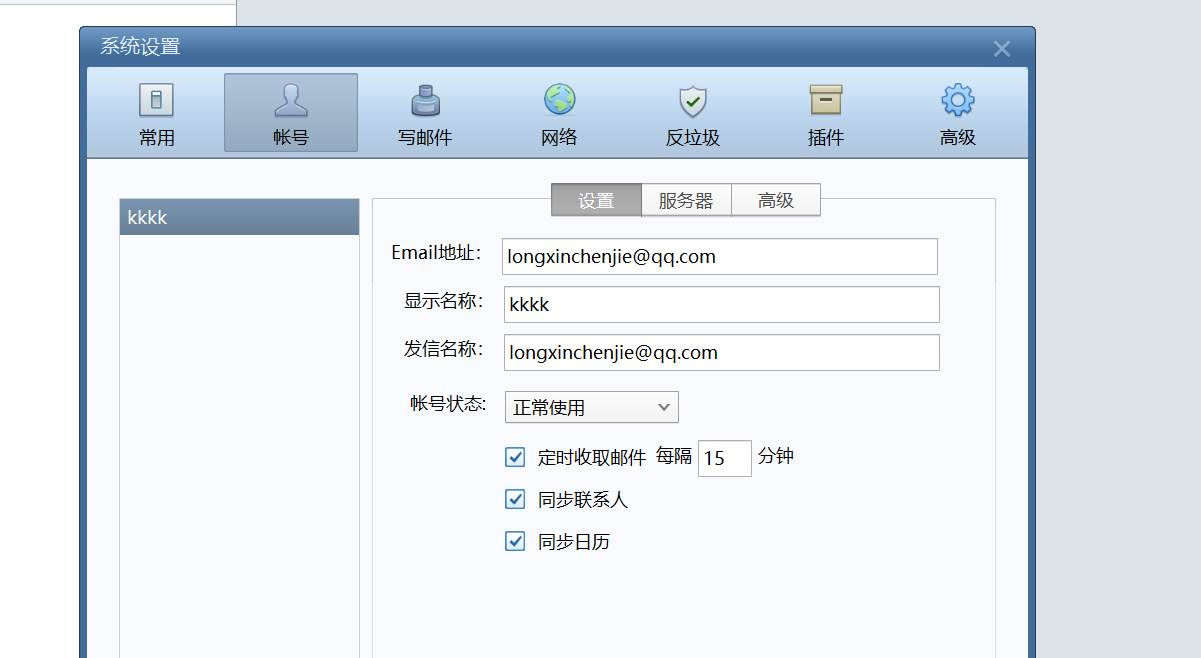
16. 請問機主郵箱最近?次發送郵件的主題是什么 。(標準格式:按照實際值填寫)
我是臥龍
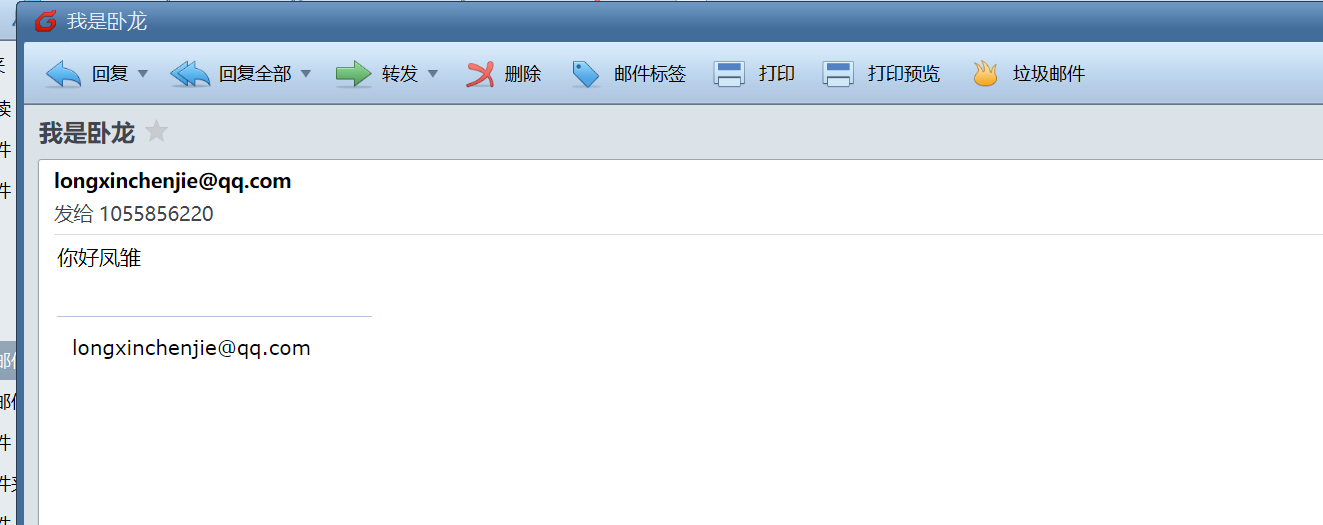
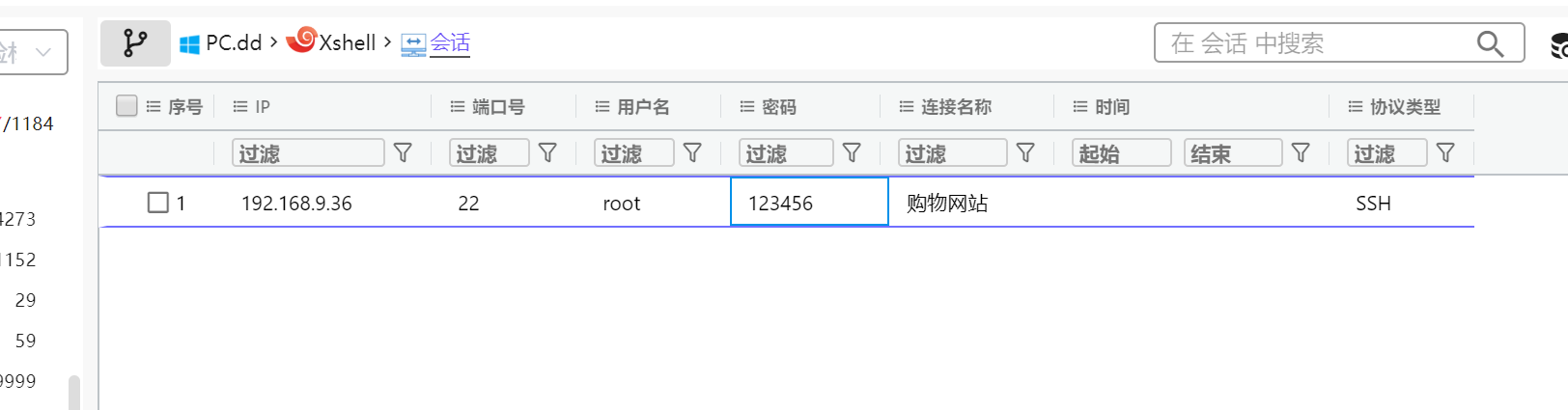
17. 請問購物網站服務器的root密碼是什么 。(標準格式:按照實際值填寫)
123456
18. 請問購物網站管理后臺admin用戶的密碼是什么 。(標準格式:按照實際值填寫)
longxin
要找密碼,就需要找數據庫,先連上寶塔,面板里沒看見有數據庫,日志里可以發現是把數據庫刪了
所以需要去找這個數據庫文件,注意到文檔目錄下面有一個一個G大小的js文件,結合桌面上有vc軟件,推測這是加密容器,然后在服務器里面有miyao.txt文件,于是用密鑰文件解密容器的方法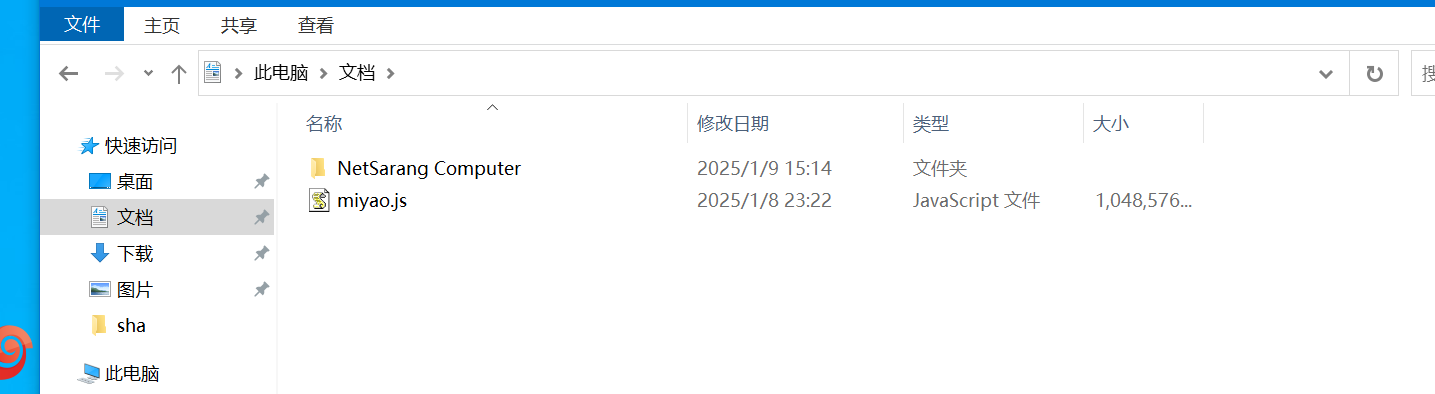
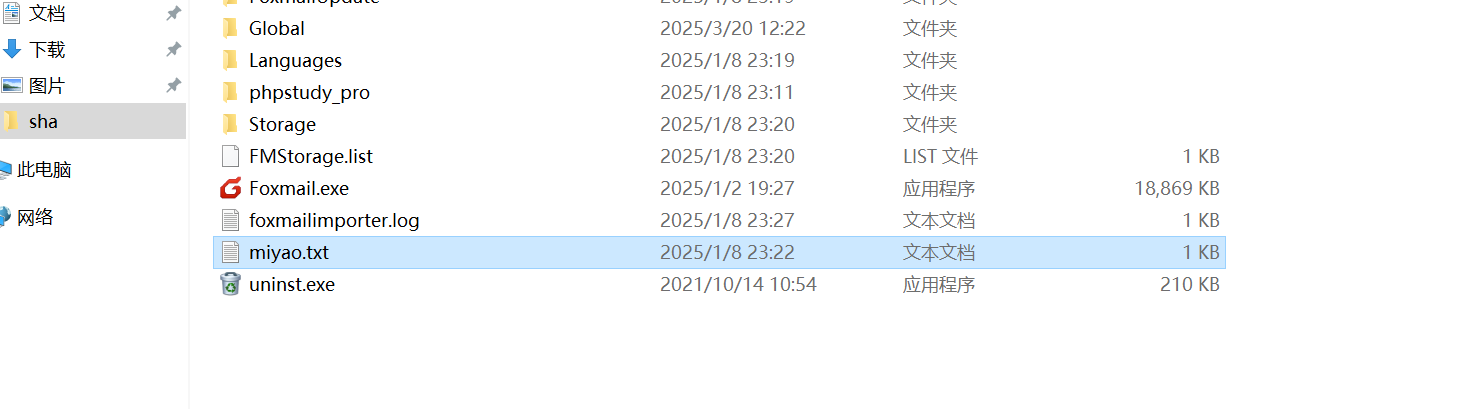
恢復數據庫,找到加密的密鑰
找一下密碼加密邏輯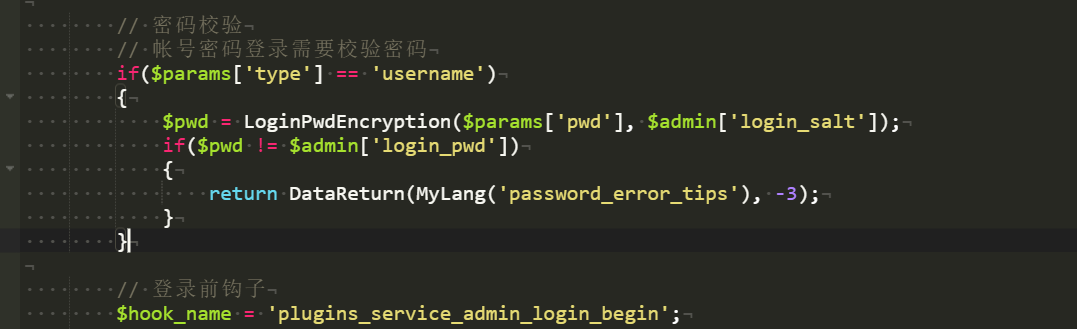
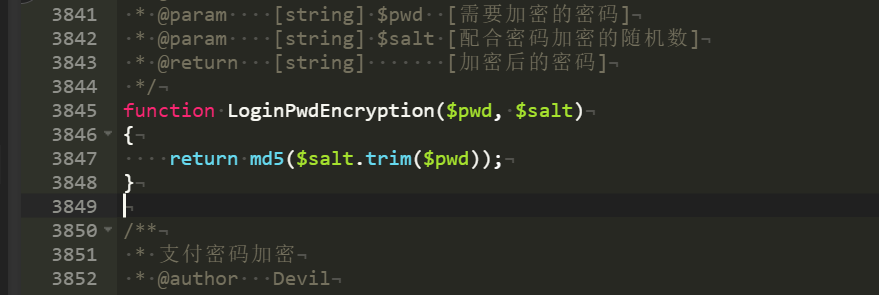
cmd5說這是需要付費的內容,這里考慮用hashcat爆破密碼,理論上應該需要從少的位數慢慢爆到大的位數以及嘗試多種密碼組合可能,但是這里已知是知道答案復原過程,主要是了解工具使用。
hashcat.exe -m 20 -a 3 -w 4 hash.txt "?l?l?l?l?l?l?l"
-m 指定哈希類型
-a 代表攻擊模式(attack mode)
-w 代表 工作負載級別(workload profile),影響計算性能: 1 -> 最低,占用最少的 CPU/GPU 資源 2 -> 適中(默認) 3 -> 高 4 -> 最大性能,但可能會導致系統卡頓 hash.txt 存放待破解的哈希值。 格式示例(如果是 MD5($salt.$pass),通常是 salt:hash 形式)
?l?l?l?l?l?l?l 掩碼模式(mask attack),表示密碼的格式: ?l -> 小寫字母(a-z) ?u -> 大寫字母(A-Z) ?d -> 數字(0-9) ?s -> 特殊字符(!@#$%^& 等) * ?a -> 所有字符(?l?u?d?s 組合) ?l?l?l?l?l?l?l 表示: 7 位的小寫字母密碼(例如:abcdefg, qwertyu)

19. 該購物網站上架了幾個支付方式 。(標準格式:10)
4
導入數據庫,然后修改配置文件
這里卡了好一會,數據庫都導入對了,但是網站起不來,發現是ip有問題,網站起來之后找后臺地址,日志中翻翻就找到了,密碼是上一題爆破出來的密碼
找到支付方式,本來以為是五種,發現有一種沒有啟用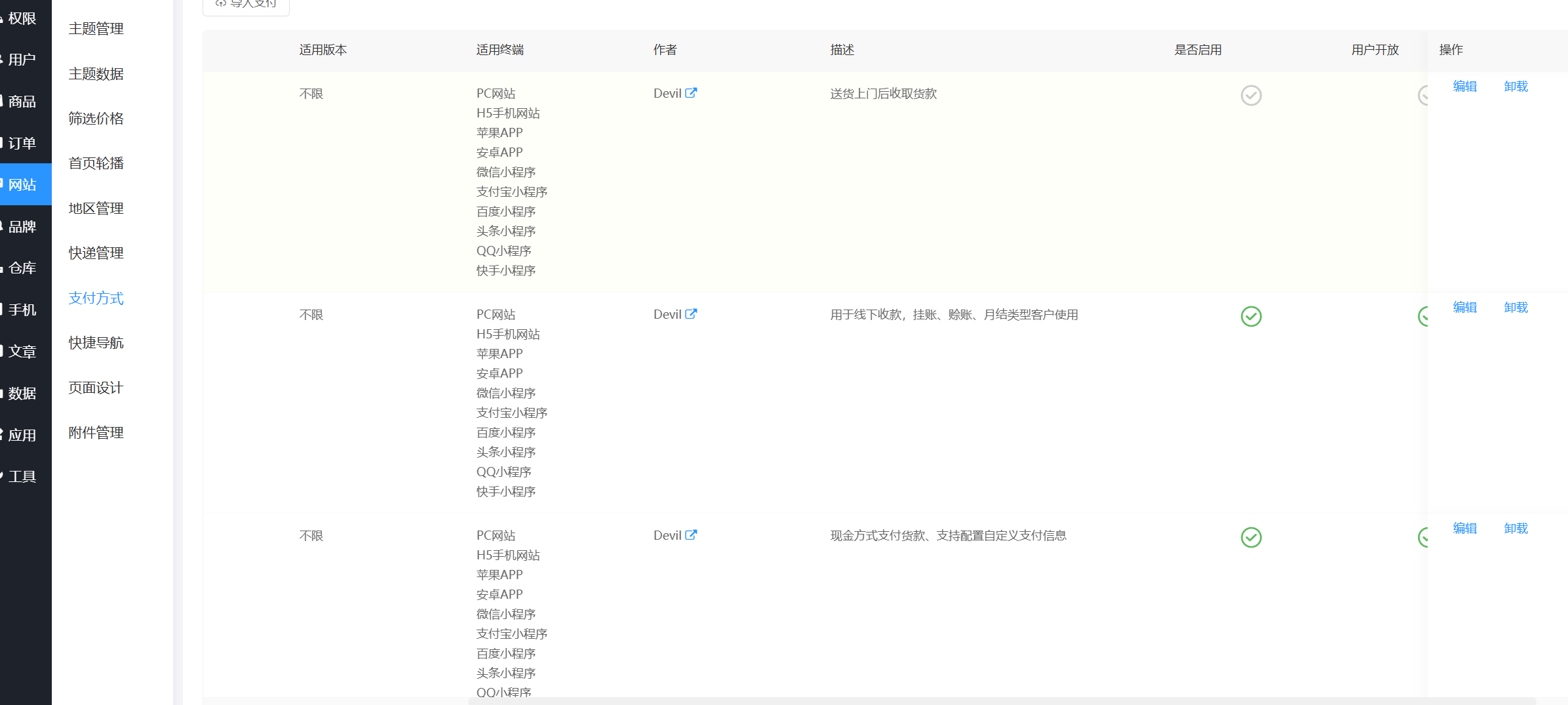
20.該購物網站管理后臺的登錄地址是什么 。(標準格式:/adminxx5?=admin/admin.html)
/adminnxp5dt.php?s=admin/logininfo.html
接上題
21. 該購物網站共上架多少商品 。(標準格式:10)
29
一共29個商品都是上架了的,或者在前臺也能看一共的商品數量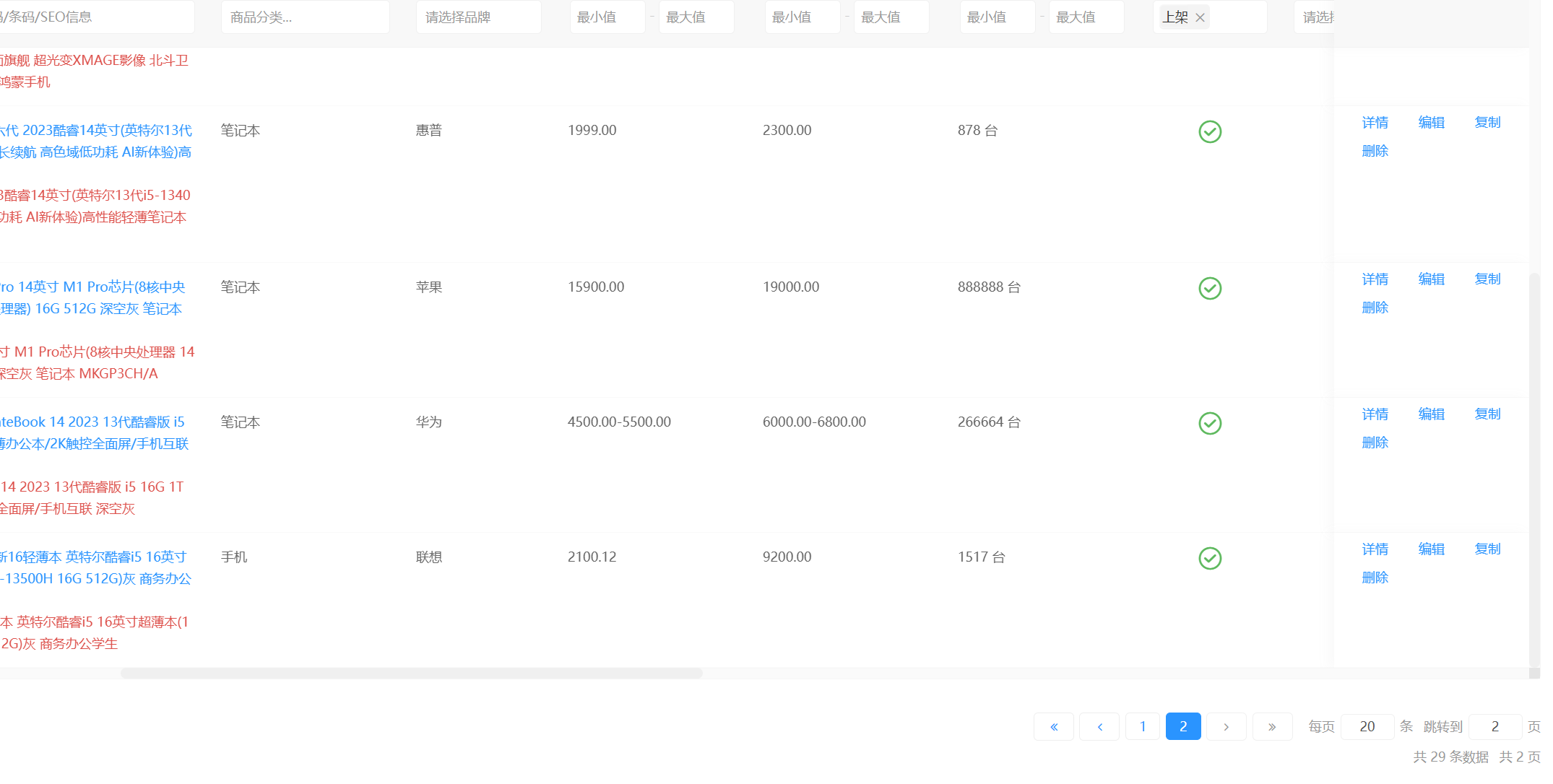
22. 該購物網站的數據庫配置的文件名是什么 。(標準格式:db.php)
database.php
前面出現過
23. 該購物網站上架的最新的商品的上架時間是什么 。(標準格式:2025-01-01 11:11:11)
2025-01-08 22:03:50
看了很多wp都說是后面那個更新時間,個人感覺不對,創建時間就是上架時間,我進入編輯之后保存了,沒有進行任何修改,更新時間已經變成剛剛進行更改的時間了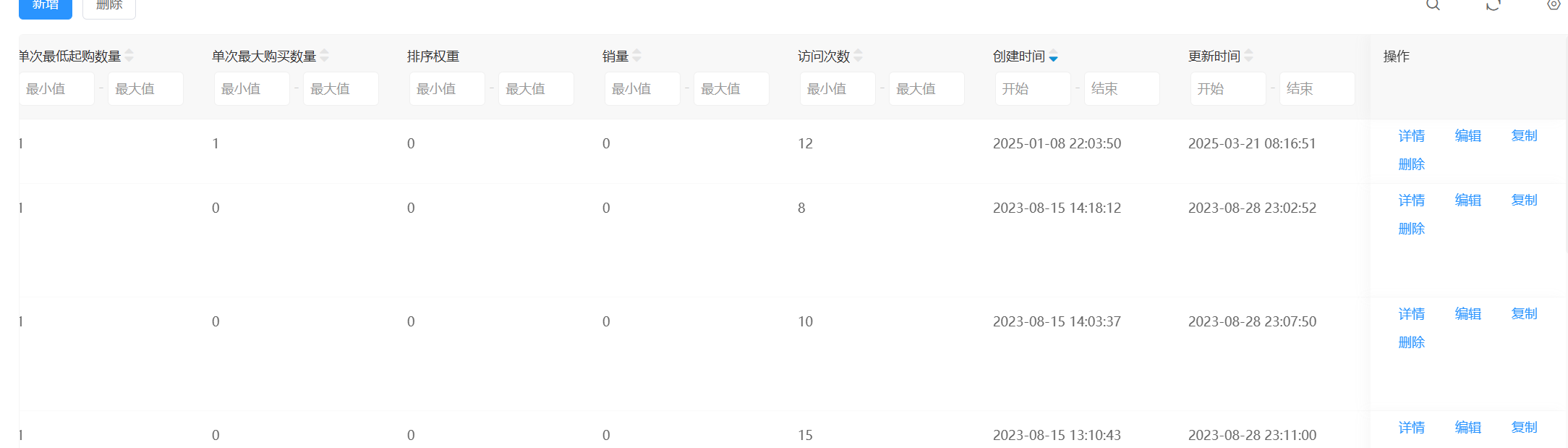
24. 服務器的ssh對外端口是什么 。(標準格式:22)
22

25. Java網站備份文件中配置文件(*.properties) 的SHA256校驗值后六位是什么 。(標準格 式:全小寫)
4dd523
這題我當時直接在服務器里面找到了內容,但是發現不對,應該服務器里面里面是已經起了的東西。根據川佬的博客,可以在寶塔的備份文件夾里面找到一個gz壓縮文件。發現文件損壞,修改文件頭,解壓。還是能發現兩個文件的差別的,計算文件的sha256值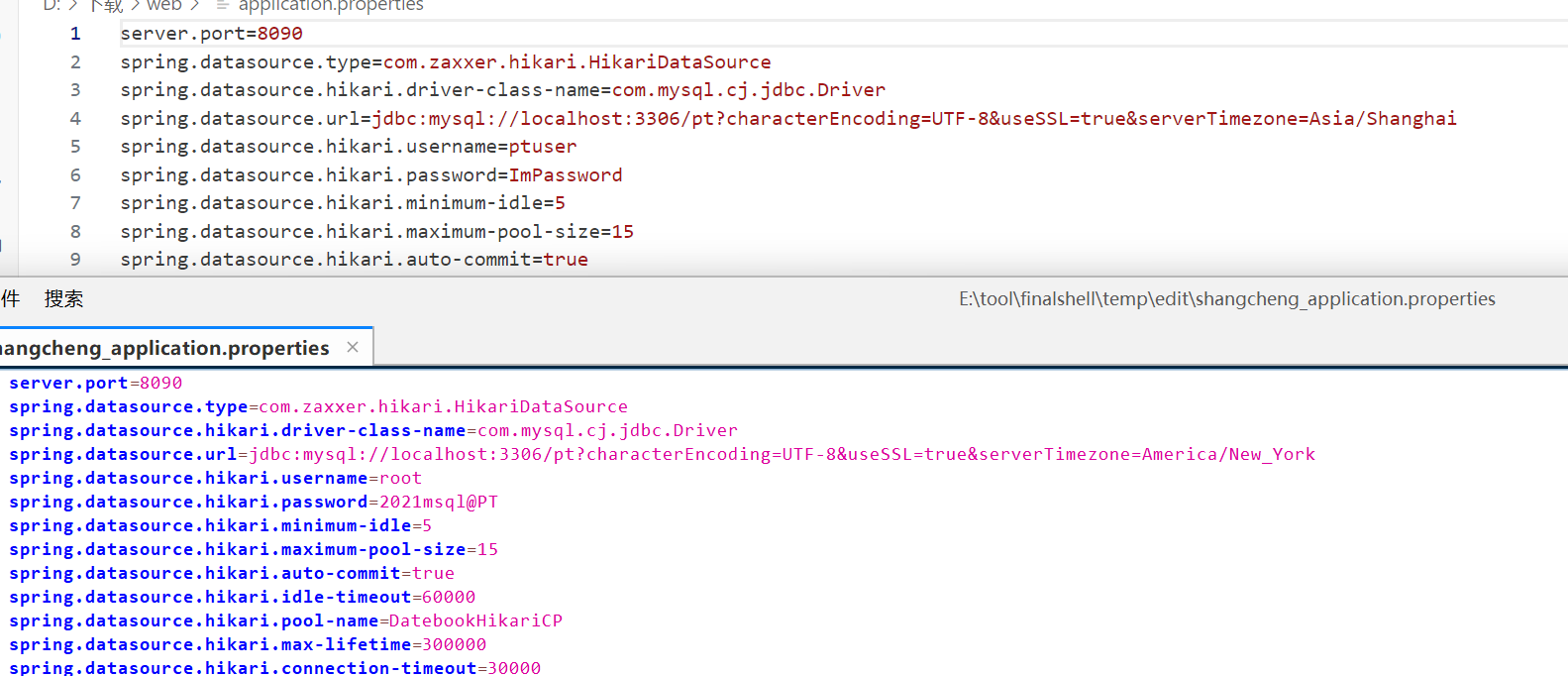
26. Java網站使用的MySQL數據庫名稱為() 。(標準格式:按照實際值填寫)
pt

27. Java網站數據庫表sys_user中的用戶類型為user的用戶數為() 。(標準格式:按照實際值填寫)
6
火眼可以搜到這個文件
找到同目錄下面還有一共ibd文件,本來還在思考如何恢復這兩個文件,發現火眼里面已經把這個恢復了
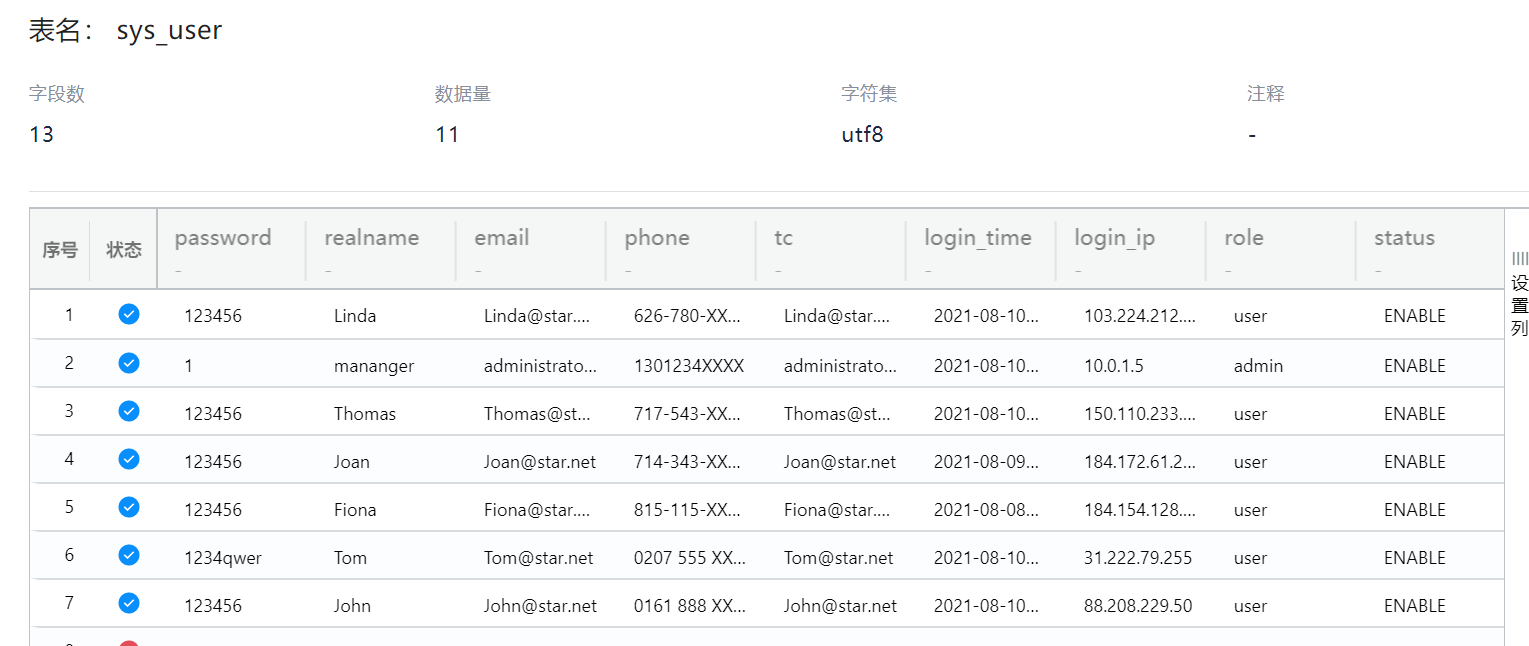
28. 請問md5值為831d75f88a50f736d3da7c929cf17580的文件名是什么 。(標準格式:按照實際值填寫)
831D75F88A50F736D3DA7C929CF17580
稍微算算就出了,不知道為什么當時沒有做這題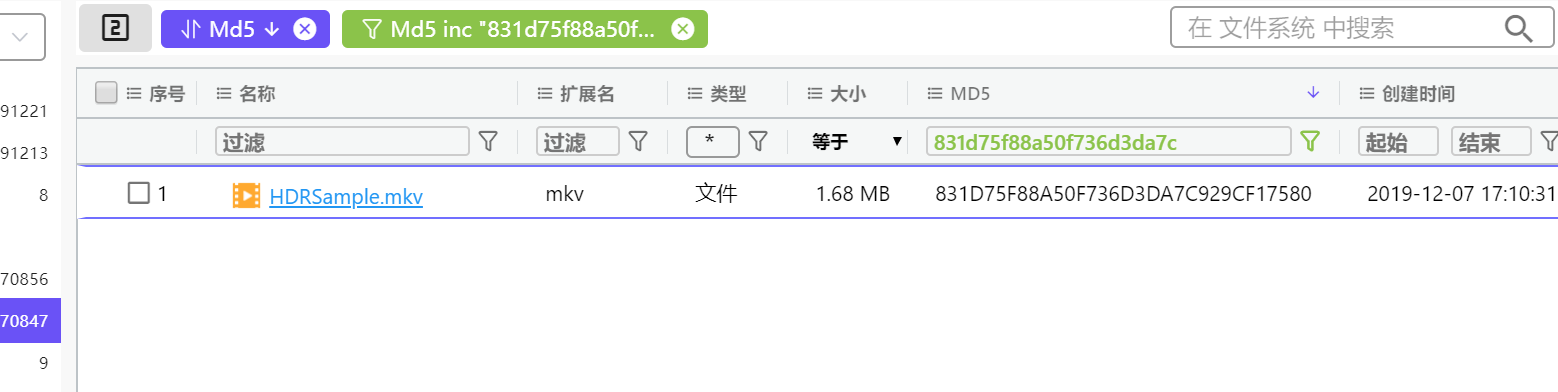

 浙公網安備 33010602011771號
浙公網安備 33010602011771號