
字體子集化
字體子集化
本教程由做字體網(www.zuoziti.com)友情提供!
本教程是制作手寫字體系列教程,建議從序言部分開始閱讀學習!如需交流,請加微信:goodfont(微信加好友,搜索微信名即可)
什么是字體子集
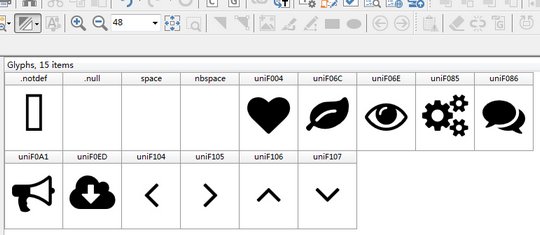
字體子集,就是從一個大字體中分離出的多個獨立的子集字體。比如我們要簡化一個別人的字體,從他的字體中分離自己想要的字。又比如說我們要在網站上展示一些手寫符號,為了優化網站加載速度,web字體需要做的很小,里面僅僅包含了幾十甚至幾個字符,這也得用到字體子集化這個功能。比如下面這個網站web字體只有寥寥幾個字(圖形)。
字體子集化方法-手動方法
前面教程已經教大家安裝了python和fonttools這兩個免費工具,這次我們就是利用fonttools中的pyftsubset命令進行字體子集化。如果你還沒有安裝python和fonttools,請先看我前面的教程:批量篩選超標字符。
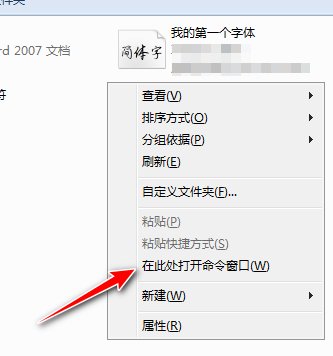
pyftsubset字體子集化有兩種方法,下面一一介紹。先在字體所在目錄空白處按住Shift鍵的同時點擊鼠標右鍵,選擇打開“在此處打開命令窗口”。這是win7的顯示,win10會顯示打開Windows PowerShell窗口。一樣能用。
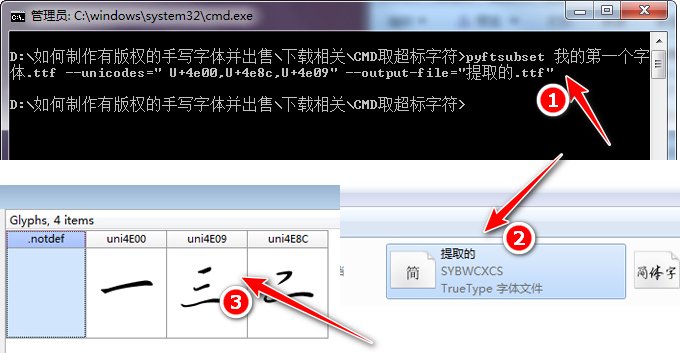
方法一:輸入以下命令回車即可把“我的第一個字體.ttf”這個字體文件中的漢字“一二三”這三個字符提取出來并保存為新字體“提取的.ttf”。“一二三”這幾個字要提前轉換為對應的Unicode,每個字符用英文逗號隔開。
pyftsubset 我的第一個字體.ttf --unicodes="U+4e00,U+4e8c,U+4e09" --output-file="提取的.ttf"
上面的命令執行完畢即可生成"提取的.ttf"。如下圖所示。
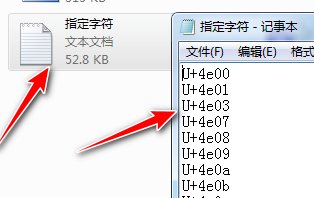
方法二:輸入以下命令回車也能達到方法一的效果。區別就是方法一是在CMD執行窗口中指定字符的Unicode,因窗口命令中有字符數量的限制,所以這種方法適合字數比較少的情況。方法二是用文本文件指定字符的方式,字數限制多少沒做研究,反正6700多字是可以一次性取出的。方法二需要先在字體同目錄下新建一個“指定字符.txt”,里面保存上你要取出的字符的Unicode,一行一個,不留空格和空行。如圖所示。
pyftsubset 我的第一個字體.ttf --unicodes-file="指定字符.txt" --output-file="提取的.ttf"
上面的命令執行完畢即可生成"提取的.ttf"。
字體子集化方法-自動方法
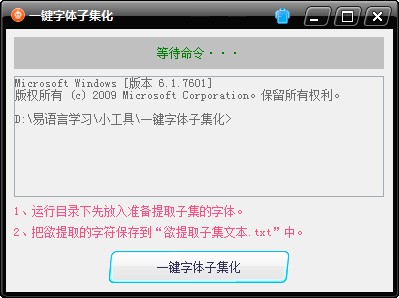
我自己編寫的一鍵字體子集化小軟件,此軟件可以借助Python把TTF字體文件分離出自己需要的字符并重新組合為新字體,簡單、省時省力,如需要請下載使用,前提是安裝了Python和fonttools。
下載本文相關軟件
本人是一個小白開發者,本人的原則是凡是網上能搜索到的軟件本站一律不收費,只有本人原創的一些輔助小軟件才酌情收費,本著量販式的原則用到哪個下載哪個,當然你也可以用其他的一些軟件去替代。開發軟件很艱難、書寫教程很辛苦,希望你能賞我一杯咖啡?,多謝!
一鍵字體子集化下載:https://mbd.pub/o/bread/Zpeck5ht

 浙公網安備 33010602011771號
浙公網安備 33010602011771號