
Python爬蟲:用BeautifulSoup進行NBA數據爬取
爬蟲主要就是要過濾掉網頁中沒用的信息。抓取網頁中實用的信息
一般的爬蟲架構為:
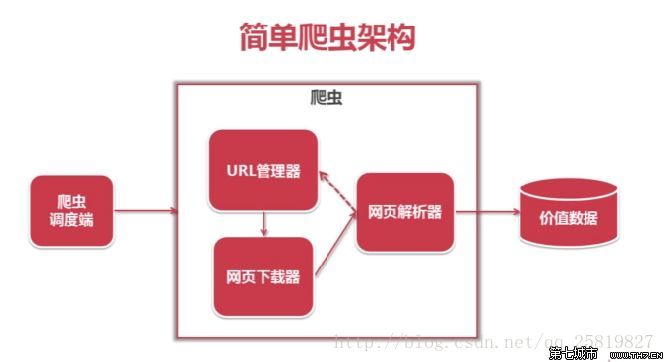
在python爬蟲之前先要對網頁的結構知識有一定的了解。如網頁的標簽,網頁的語言等知識,推薦去W3School:
W3school鏈接進行了解
在進行爬蟲之前還要有一些工具:
1.首先Python 的開發環境:這里我選擇了python2.7,開發的IDE為了安裝調試方便選擇了用VS2013上的python插件,在VS上進行開發(python程序的調試與c的調試幾乎相同較為熟悉)。
2.網頁源代碼的查看工具:盡管每個瀏覽器都能進行網頁源代碼的查看。但這里我還是推薦用火狐瀏覽器和FirBug插件(同一時候這兩個也是網頁開發者必用的工具之中的一個);
FirBug插件的安裝能夠在右邊的加入組件中安裝;
其次來看試著看網頁的源代碼,這里我以我們要爬取的籃球數據為例:
如我要爬取網頁中的Team Comparison表格內容為例:

先右鍵選中如我要爬取的比分32-49。點擊右鍵選擇選擇用firBug查看元素,(FirBug的另一個優點是在查看源代碼時會在網頁上顯示源代碼所顯示的樣式,在網頁中我的位置及內容)網頁下方就會跳出網頁的源代碼以及32-49比分所在的位置及源代碼例如以下圖:
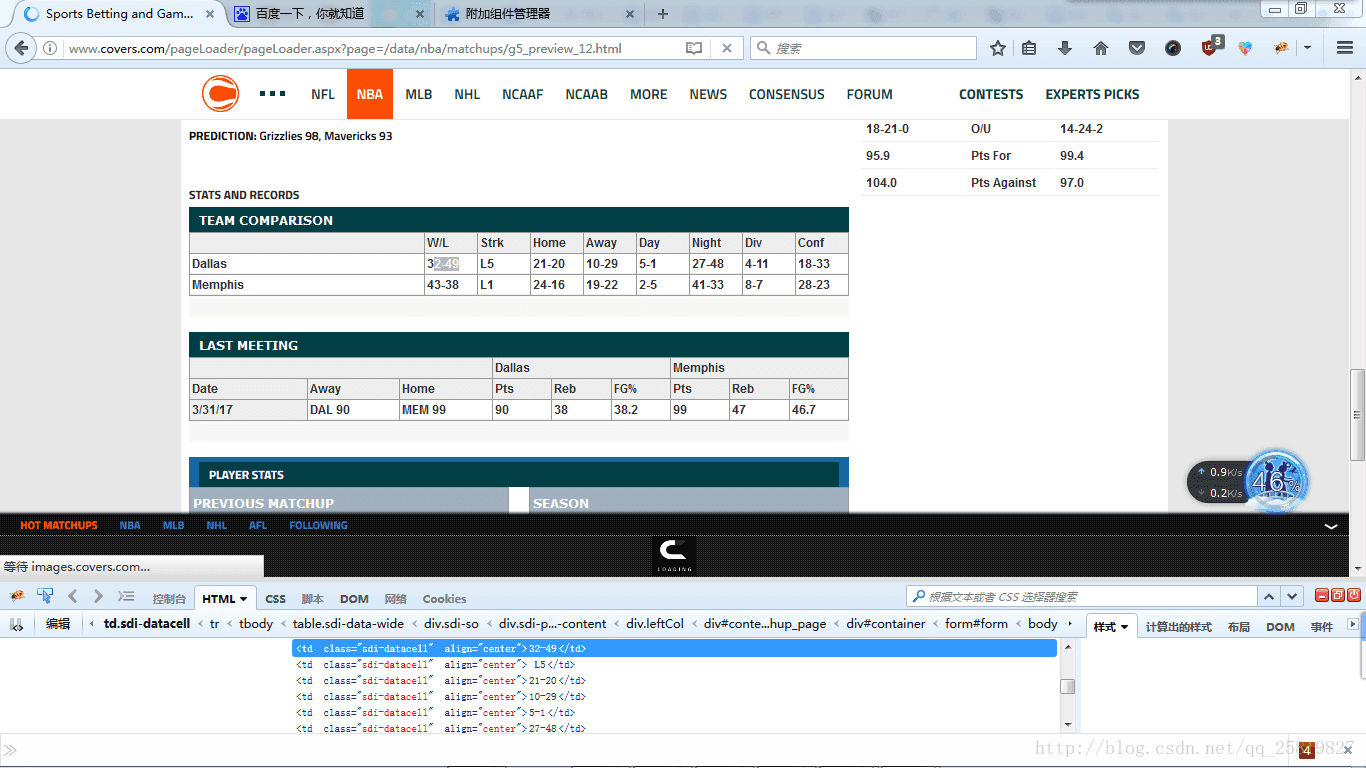
能夠看到32-49為網頁的源代碼為:
<td class="sdi-datacell" align="center">32-49</td>當中td為標簽的名字,class為類的名字,align為格式,32-49為標簽的內容,為我們要爬取的內容;
但相似的標簽以及類的名字在同一個網頁中有非常多,光靠這兩個元素無法爬下我們所須要的數據,這時就須要查看這一標簽的父標簽,或再上一級的標簽來提取很多其它我們要爬取數據的特征。來過濾其它我們所不要爬取的數據。如我們這里選取這張表格所在的標簽作為我我們進行篩選的第二個
特征:
<div class="sdi-so">
<h3>Team Comparison</h3>再來我們來分析網頁的URL:
如我們要爬取的網頁的URL為:
http://www.covers.com/pageLoader/pageLoader.aspx?page=/data/nba/matchups/g5_preview_12.html由于有搭站點的經驗,所以能夠這里
www.covers.com為域名。
/pageLoader/pageLoader.aspxpage=/data/nba/matchups/g5_preview_12.html。可能為放在服務器上的網頁根文件夾的/pageLoader/pageLoader.aspx?
page=/data/nba/matchups/地址中的網頁。
為了管理方便。同樣類型的網頁都會放在同一個文件夾下。以相似的命名方式命名:如這邊的網頁是以g5_preview_12.html命名的所以相似的網頁會改變g5中的5,或者_12 中的12,通過改變這兩個數字,我們發現相似網頁能夠改變12數字來得到,
再來學習爬蟲:
這里python爬蟲主要用到了
urllib2
BeautifulSoup
這兩個庫。BeautifulSoup的具體文檔能夠在下面站點中查看:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
在爬取網頁時:
先要打開網頁,然后在調用beautifulSoup庫進行網頁的分析,再用如.find函數找到要剛剛我們分析的特征所在的位置,并用.text來獲取標簽的內容即我們所要爬取的數據
如我們對比下面代碼來進行分析:
response=urllib2.urlopen(url)
print response.getcode()
soup=BeautifulSoup(
response,
'html.parser',
from_encoding='utf-8'
)
links2=soup.find_all('div',class_="sdi-so",limit=2)
cishu=0
for i in links2:
if(cishu==1):
two=i.find_all('td',class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
file.save('NBA.xls')
cishu=cishu+1urllib2.urlopen(url)為打開網頁;
print response.getcode()為測試網頁能否被打開;
soup=BeautifulSoup(
response,
‘html.parser’,
from_encoding=’utf-8’
)
為代用Beautiful進行網頁的分析。
links2=soup.find_all(‘div’,class_=”sdi-so”,limit=2)為進行特征值的查詢與返回
當中我們要查找’div’,class_=”sdi-so”,的標簽,limit=2為限制找兩個(這是為過濾其它相似的標簽)
for i in links2:
if(cishu==1):
two=i.find_all('td',class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1為在找到的’div’,class_=”sdi-so”,的標簽中再進行對應的如’td’,class_=”sdi-datacell”標簽的查找;
q.text為返回我們所要的數據
這里 row=row+1,row=row+1為我們將數據寫入到excel文件時文件格式的整理所用的;
接下來是對抓取數據的保存:
這里我們用了excel來保存數據用到了包:
xdrlib,sys, xlwt
函數:
file=xlwt.Workbook()
table=file.add_sheet(‘shuju’,cell_overwrite_ok=True)
table.write(0,0,’team’)
table.write(0,1,’W/L’)
table.write(row,col,q.text)
file.save(‘NBA.xls’)
為最主要的excel寫函數,這里不再累述;
最后我們爬下來數據保存格式后樣式為:

NICE


 浙公網安備 33010602011771號
浙公網安備 33010602011771號