

數(shù)倉設(shè)計之星型模型和雪花模型
們用一種非常易于理解的方式來介紹星型模型和雪花模型。
想象一下,你要分析一家超市的銷售情況。
核心思想:兩種不同的組織方式
這兩種模型都是數(shù)據(jù)倉庫中常見的維度建模方法,目的是為了更高效地查詢和分析數(shù)據(jù),而不是處理日常交易(那是OLTP數(shù)據(jù)庫的活兒)。
它們都圍繞一個核心:“事實”和“維度”。
-
事實 (Fact):發(fā)生了什么事?是可度量的、數(shù)值型的、連續(xù)的數(shù)據(jù)。通常是動詞。
-
例子:賣了1瓶可樂,收入3.5元。這里的“銷售”就是事實。
-
-
維度 (Dimension):誰?什么時間?什么地點?是誰?是描述性的、文本型的、離散的數(shù)據(jù)。通常是名詞。
-
*例子:時間(2023-10-27)、門店(XX超市XX店)、產(chǎn)品(可樂)、顧客(張三)。*
-
一、星型模型 (Star Schema):簡單直接
比喻:一個明星(事實表)被一群粉絲(維度表)直接圍著。
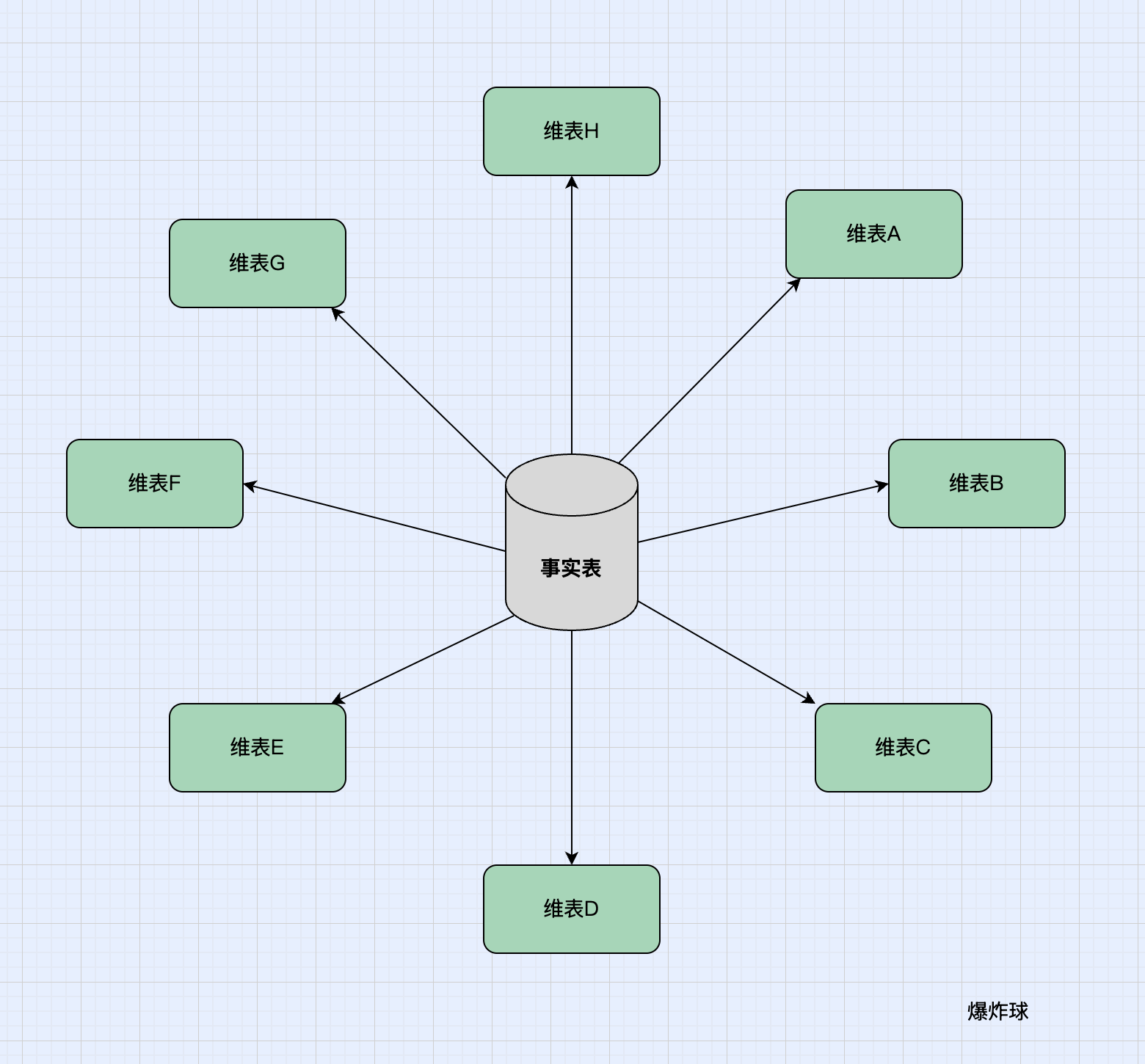
-
一個中心表:叫做事實表(Fact Table)。它記錄了核心業(yè)務(wù)事件。
-
例子:
銷售事實表。它的每一行代表一筆銷售記錄。 -
它包含兩類列:
-
外鍵列:連接各個維度表的外鍵,如
時間鍵、產(chǎn)品鍵、門店鍵、顧客鍵。 -
度量值列:可計算的數(shù)據(jù),如
銷售金額、銷售數(shù)量、成本、利潤。
-
-
-
多個周邊表:叫做維度表(Dimension Table)。它描述了事實的上下文。
-
例子:
時間維度表、產(chǎn)品維度表、門店維度表、顧客維度表。
-
-
所有維度表都直接連接到事實表,維度表之間沒有任何連接。從圖形上看,像一顆星星,所以叫星型模型。
優(yōu)點:
-
查詢非常簡單快速:因為大部分查詢只需要一次大表(事實表) 和 小表(維度表) 的連接(JOIN),甚至數(shù)據(jù)庫優(yōu)化器可以直接跳過某些維度表。
-
易于理解:結(jié)構(gòu)非常清晰,業(yè)務(wù)人員一看就懂。
-
對BI工具非常友好:Tableau、FineBI等工具可以自動識別這種模型,輕松拖拽生成報表。
缺點:
-
數(shù)據(jù)冗余較多:為了避免連接,維度表會存儲所有層級的信息。例如,
產(chǎn)品維度表里,每條產(chǎn)品記錄都會重復(fù)存儲它所屬的品類、部門名稱。如果品類名稱改了,所有相關(guān)產(chǎn)品記錄都要更新。
二、雪花模型 (Snowflake Schema):規(guī)范化
比喻:這個明星的粉絲(維度表)還有自己的粉絲(子維度表)。

結(jié)構(gòu)特點:
-
它仍然有一個事實表作為中心。
-
但它的維度表是規(guī)范化的。這意味著一些維度表不會直接連接事實表,而是通過其他維度表間接連接。
-
例如,在星型模型中,
產(chǎn)品維度表直接包含了品類ID和品類名稱。 -
在雪花模型中,
產(chǎn)品維度表只包含品類ID,而品類ID又連接到另一個獨立的品類維度表(里面存品類名稱、部門ID),部門ID可能又連接到部門維度表。 -
從圖形上看,維度表像雪花一樣分叉開來,所以叫雪花模型。
-
優(yōu)點:
-
減少數(shù)據(jù)冗余:信息只存儲在一個地方。例如,
品類名稱只存在品類表里,而不是在每個產(chǎn)品記錄里重復(fù)存儲。節(jié)省了存儲空間。 -
易于維護:更新數(shù)據(jù)更方便。比如更改品類名稱,只需要在
品類表里修改一條記錄即可。
缺點:
-
查詢性能相對較低:因為需要連接更多的表(例如:事實表 -> 產(chǎn)品表 -> 品類表 -> 部門表)才能得到想要的信息,復(fù)雜的JOIN會影響查詢速度。
-
結(jié)構(gòu)更復(fù)雜:對業(yè)務(wù)用戶和BI工具不如星型模型友好,理解和使用起來更費勁。
對比總結(jié)與如何選擇
| 特性 | 星型模型 (Star Schema) | 雪花模型 (Snowflake Schema) |
|---|---|---|
| 結(jié)構(gòu) | 簡單,扁平 | 復(fù)雜,分層 |
| 數(shù)據(jù)冗余 | 多 | 少(更規(guī)范化) |
| 查詢性能 | 高(連接少) | 低(連接多) |
| 易用性 | 高(易于理解) | 低(更復(fù)雜) |
| 存儲效率 | 低 | 高 |
| 維護 | 相對困難(更新冗余數(shù)據(jù)) | 相對容易 |
如何選擇?
-
絕大多數(shù)情況下,選擇【星型模型】。
-
理由:數(shù)據(jù)倉庫的核心目標是快速查詢和分析。存儲成本通常遠低于計算成本和時間成本。用一點點存儲空間換取巨大的性能提升,是非常劃算的。 這也是為什么星型模型是數(shù)據(jù)倉庫領(lǐng)域最主流、最受歡迎的設(shè)計。
-
-
僅在特定情況下,考慮【雪花模型】:
-
維度表本身非常巨大:例如,一個
客戶維度表有上億行,并且其屬性(如地址、行業(yè))有復(fù)雜的多層結(jié)構(gòu)。這時規(guī)范化它可以節(jié)省可觀的存儲空間。 -
工具要求:某些ETL工具或BI工具在處理某些特定邏輯時,雪花模型可能更合適。
-
業(yè)務(wù)邏輯本身是高度分層的:并且業(yè)務(wù)用戶習(xí)慣按這種層級去查詢。
-
一句話記住它們:
想要速度快、簡單粗暴,就用【星型模型】。
想省點硬盤空間、不怕查詢慢點,就用【雪花模型】。(但通常不建議)

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號