
排序專題
簡單分析以下排序方法的算法,并分別用Python代碼和C代碼實現升序排列
- 0.先寫一個裝飾器,用于計算排序算法的執行時間
import time
def wrapper(func):
def inner(*args, **kwargs):
start_time = time.time()
v = func(*args, **kwargs)
end_time = time.time()
print("%s running time: %s secs." %(func.__name__, end_time - start_time))
return v
return inner
-
1.冒泡排序
- 算法思想
- 1.從第1個元素開始,逐次比較序列中相鄰的兩個數,如果前面的數更大,則交換彼此。當一趟排序完成后,無序區減少一個數,有序區增加一個數,即處于尾部的最大數
- 2.重復上述步驟共N-1趟(N為序列中元素總個數),可得到排好的序列
- Python代碼
import random from cal_time import wrapper @wrapper def bubble_sort(li): for i in range(len(li) - 1): # 第i趟 exchange = False # 標志變量exchange for j in range(len(li) - i - 1): if li[j] > li[j + 1]: li[j], li[j+1] = li[j+1], li[j] exchange = True # 如果在某趟中沒有發生交換,則代表序列已有序 if not exchange: return li = list(range(10000)) random.shuffle(li) bubble_sort(li)![]()
- C語言代碼
#include <stdio.h> int bubble_sort(int s[], int n){ int i, j, temp, flag; for(i = 0;i < n - 1; i++){ flag = 0; for(j = 0;j < n - i - 1; j++){ if(s[j] > s[j+1]){ temp = s[j]; s[j] = s[j+1]; s[j+1] = temp; flag = 1; } } if(!flag){ return 0; } } return 0; } void print_arr(int s[], int n){ int i; for(i = 0; i < n; i++){ printf("%d ", s[i]); } } int main(){ int a[5], i; printf("請輸入5個序列元素:\n"); for(i = 0;i < 5;i++){ scanf("%d", &a[i]); } printf("排序前的序列為:"); print_arr(a, 5); bubble_sort(a, 5); printf("\n排序后的序列為:"); print_arr(a, 5); return 0; }![]()
- 過程模擬
![]()
- 算法思想
-
2.選擇排序
- 算法思想
- 1.假設無序區的第1個數A1為最小數,遍歷該數后方序列的所有數找到最小數B1(假設B1存在),將A1與B1交換,此時完成了第1趟排序。序列的第1個數為最小數(有序區),后方N-1個數為無序區
- 注意:通過保留數的下標來完成交換
- 2.假設無序區的第1個數A2為最小數(A2即整個序列的第2個數),遍歷此數后方序列的所有數找到最小數B2(假設B2存在),將A2與B2交換,此時完成了第2趟排序。序列的前2個數為最小數與次小數(有序區),后方N-2個數為無序區
- 3.繼續重復上述操作,直到完成第N-1趟排序,可得到排好的序列
- 1.假設無序區的第1個數A1為最小數,遍歷該數后方序列的所有數找到最小數B1(假設B1存在),將A1與B1交換,此時完成了第1趟排序。序列的第1個數為最小數(有序區),后方N-1個數為無序區
- Python代碼
import random from cal_time import wrapper @warpper def select_sort(li): for i in range(len(li) - 1): # i是第幾趟 min_loc = i # 記錄無序區的第1個位置 for j in range(i + 1, len(li)): if li[j] < li[min_loc]: min_loc = j if min_loc != i: # 找到了更小的數。該行可省 li[i], li[min_loc] = li[min_loc], li[i] # 將無序區最小的數與本輪第1個數交換 li = list(range(10000)) random.shuffle(li) print(li) select_sort(li) print(li)![]()
- C語言代碼
#include <stdio.h> void select_sort(int s[], int n){ int i, j, temp, min_loc; for(i = 0;i < n - 1; i++){ min_loc = i; for(j = i + 1; j < n; j++){ if(s[j] < s[min_loc]){ min_loc = j; } } if(min_loc != i){ temp = s[min_loc]; s[min_loc] = s[i]; s[i] = temp; } } } void print_arr(int s[], int n){ int i; for(i = 0; i < n; i++){ printf("%d ", s[i]); } } int main(){ int a[7], i; printf("請輸入7個序列元素:\n"); for(i = 0; i < 7; i++){ scanf("%d", &a[i]); } printf("排序前的序列為:"); print_arr(a, 7); select_sort(a, 7); printf("\n排序后的序列為:"); print_arr(a, 7); return 0; }![]()
- 過程模擬
![]()
![]()
- 算法思想
-
3.插入排序
- 算法思想
- 0.運行過程與打牌非常相似,第1張牌拿到后,后續牌的位置基于現有排好序的牌插入
- 1.假設序列中的第1個數為有序區,后方N-1個數為無序區。用第2個數和有序區(第1個數)比較,找到合適的位置插入,此時完成了第1趟排序
- 2.序列中的前2個數為有序區,后方N-2個數為無序區。用第3個數和有序區(前2個數)比較,找到合適的位置插入,此時完成了第2趟排序
- 3.繼續重復上述操作,直到完成第N-1趟排序,可得到排好的序列
- 注意:插入新數到有序區時,有序區可能會后移,此時會覆蓋待插入的數,因此待插入數據要暫存;后移的算法和課本上案例5-12的算法一致,也算是課本案例的應用與擴充
- Python代碼
import random from cal_time import wrapper def insert_sort(li): for i in range(1, len(li)): # i表示待插入數據的下標 tmp = li[i] # 暫存待插入數據,防止有序區數據后移而覆蓋 j = i - 1 # j表示有序區最后一個數的下標 while j >= 0 and li[j] > tmp: # 情形1:在有序區之間找到了插入位置 情形2:有序區的數都比待插入數據大,j會減到-1導致越界 li[j + 1] = li[j] # 有序區數據從后往前依次后移 j -= 1 li[j + 1] = tmp # 將待插入數據存入 li = list(range(10000)) random.shuffle(li) print(li) insert_sort(li) print(li)![]()
- C語言代碼
#include <stdio.h> void insert_sort(int s[], int n){ int i, j, temp; for(i = 1; i < n; i++){ j = i - 1; temp = s[i]; while(j >= 0 && s[j] > temp){ s[j + 1] = s[j]; j --; } s[j + 1] = temp; } } void print_arr(int s[], int n){ int i; for(i = 0; i < n; i++){ printf("%d ", s[i]); } } int main(){ int a[7], i; printf("請輸入7個序列元素:\n"); for(i = 0; i < 7; i++){ scanf("%d", &a[i]); } printf("排序前的序列為:"); print_arr(a, 7); insert_sort(a, 7); printf("\n排序后的序列為:"); print_arr(a, 7); return 0; }![]()
- 過程模擬
![]()
- 算法思想
-
4.快速排序
- 算法思想
- 0.選擇序列中某個元素作為“基準數”,將所有小于基準數的數移到其左側,將所有大于基準數的數移到其右側
- 設定索引i指向序列中第1個元素,索引j指向序列中最后一個(第N個)元素,第1個元素同時作為“基準數”并暫存到temp中
- j往左移動的過程中找到比“基準數”小的數后,將該數移動到i的位置;i往右移動的過程中找到比“基準數”大的數后,將該數移動到j空出來的位置。直到i與j相遇,結束循環,此時“基準數”的位置剛好是分界線,返回“基準數”的下標mid
- 1.遞歸左子序列(left ~ mid - 1 )和右子序列(mid + 1 ~ right)
- 0.選擇序列中某個元素作為“基準數”,將所有小于基準數的數移到其左側,將所有大于基準數的數移到其右側
- Python代碼
import random from cal_time import wrapper @wrapper def partition(li, left, right): tmp = li[left] # 將left指向的數作為“基準數”暫存 while left < right: while left < right and li[right] >= tmp: # 從右邊找比tmp小的數 right -= 1 li[left] = li[right] # 將找到的數寫到左邊left所在空位上,空位上原數已暫存 while left < right and li[left] <= tmp: # 從左邊找比tmp大的數 left += 1 li[right] = li[left] # 將找到的數寫到右邊right的空位上 li[left] = tmp # 將tmp歸位 return left def _quick_sort(li, left, right): if left < right: # 待排序序列中至少有2個元素 mid = partition(li, left, right) # 返回“基準數”的索引 _quick_sort(li, left, mid - 1) # 以基準數為中軸線左右兩邊遞歸 _quick_sort(li, mid + 1, right) @wrapper def quick_sort(li): _quick_sort(li, 0, len(li) - 1) li = list(range(10000)) random.shuffle(li) quick_sort(li) print(li)![]()
- C語言代碼
#include <stdio.h> int partition(int a[], int left, int right){ int temp = a[left]; while(left < right){ while(left < right && a[right] >= temp){ right --; } a[left] = a[right]; while(left < right && a[left] <= temp){ left ++; } a[right] = a[left]; } a[left] = temp; return left; } void quick_sort(int a[], int left, int right){ int mid; if(left < right){ mid = partition(a, left, right); quick_sort(a, left, mid - 1); quick_sort(a, mid + 1, right); } } void print_arr(int a[], int n){ int i; for(i = 0; i < n; i++){ printf("%d ", a[i]); } } int main(){ int s[7], i; printf("請輸入7個序列元素:\n"); for(i = 0; i < 7; i++){ scanf("%d", &s[i]); } printf("排序前的序列為:"); print_arr(s, 7); quick_sort(s, 0, 6); printf("\n排序后的序列為:"); print_arr(s, 7); return 0; }![]()
- 過程模擬
- 注意:圖中不同顏色的框可看成不同層次的遞歸在內存中的分布
![]()
- 注意:圖中不同顏色的框可看成不同層次的遞歸在內存中的分布
- 算法思想
-
5.堆排序
- 鋪墊知識
- 1.樹是一種可以遞歸定義的數據結構,是由n個節點組成的集合。如果n=0,則這是一個空樹;如果n>0,那存在1個節點作為樹的根節點,其他節點可以分為m個集合,每個集合本身又是一棵樹
- 2.節點與深度
- 根節點:位于第0層的節點,也稱樹根
- 葉子結點:沒有子節點的節點
- 孩子節點與父節點:若A結點是B結點的父結點,則稱B結點是A結點的子結點,也稱孩子結點
- 子樹:從一棵樹中抽取出來的一棵新樹,包含了一個原始樹中某個節點及其所有的子節點。子樹可以是原始樹的任意一部分,包括單個節點、整個樹,或者是位于樹的某個分支上的一部分
- 節點的度:當前節點的向下分叉數(孩子數)
- 樹的深度(高度):樹的層數
- 樹的度:所有節點的度中最大的一個
- 3.二叉樹:度不超過2的數,每個節點最多有2個孩子節點,被區分為左孩子節點和右孩子節點
- 4.滿二叉樹:每一層的節點數都達到最大值的二叉樹
- 5.完全二叉樹
- 葉節點只能出現在最下層和次下層,并且最下層的節點都集中在該層最左邊的若干位置的二叉樹
- 如果用列表(順序存儲方式)來存儲完全二叉樹,若父節點的索引為i,則左孩子節點索引為
2 * i + 1,右孩子節點索引為2 * i + 2;若孩子節點索引為i,則父親節點索引為(i - 1) // 2
- 6.堆及其調整
- 堆是一種特殊的完全二叉樹結構,大根堆滿足任意節點都比其孩子節點大,小根堆滿足任意節點都比其孩子節點小
- 堆的向下調整:假設節點的左右子樹都是堆,但自身不是堆。當根節點的左右子樹都是堆時,可以通過一次向下的調整來將其變換成一個堆
- 算法思想
- 0.堆是邏輯上的概念,物理上采用列表或數組來實現
- 1.構造堆,從最后一個有孩子節點的非葉子結點開始,由下往上遍歷調整所有相關節點,否則會導致二叉樹結構被破壞
- 2.取得堆頂元素,為最大(最小)元素
- 3.去掉堆頂,將堆中最后一個元素放到堆頂,此時可通過一次調整重新使堆有序
- 4.此時堆頂為第2大的元素,重復步驟2-3,直到堆變空
- Python代碼
import random def sift(li, low, high): """ :param li: 列表 :param low: 堆的根節點位置,不一定是索引為0的節點,也可能是子樹的根節點 :param high: 堆的最后1個元素的位置 """ i = low # i最開始指向根節點 j = 2 * i + 1 # j最開始是i的左孩子 tmp = li[low] # 暫存堆頂元素 while j <= high: # 只要j所在的位置有數 if j + 1 <= high and li[j + 1] > li[j]: # 如果右孩子存在并且比較大 j = j + 1 # j指向右孩子 if li[j] > tmp: li[i] = li[j] i = j # 往下看一層 j = 2 * i + 1 # j繼續指向下一個孩子節點 else: # tmp更大,把tmp放到i的位置 li[i] = tmp # 把tmp放到某一級領導的位置 break else: li[i] = tmp # 把tmp放到葉子結點上 @wrapper def heap_sort(li): n = len(li) # 從最后一個葉節點的父節點開始建堆,索引為n - 1節點的父節點,下標為(n - 1 - 1) // 2 for i in range((n - 2) // 2, -1, -1): # i表示建堆的時候調整子樹的根的下標 sift(li, i, n - 1) # high指向n - 1,即最后一個位置 # 上述for循環結束后建堆完成了 for i in range(n - 1, -1, -1): # i指向當前堆的最后一個元素 li[0], li[i] = li[i], li[0] # 堆頂和最后一個元素做交換 sift(li, 0, i - 1) # i - 1是新的high li = [i for i in range(10000)] random.shuffle(li) heap_sort(li) print(li)![]()
- C語言代碼
#include <stdio.h> void sift(int a[], int low, int high){ int i, j, temp; i = low; j = 2 * i + 1; temp = a[low]; while(j <= high){ if(j + 1 <= high && a[j + 1] > a[j]){ j = j + 1; } if(a[j] > temp){ a[i] = a[j]; i = j; j = 2 * i + 1; } else { break; } } a[i] = temp; } void heap_sort(int a[], int n){ int i, temp; for(i = (n - 2) / 2; i >= 0; i--){ sift(a, i, n - 1); } for(i = n - 1; i >= 0; i--){ temp = a[0]; a[0] = a[i]; a[i] = temp; sift(a, 0, i - 1); } } void print_arr(int a[], int n){ int i; for(i = 0; i < n; i++){ printf("%d ", a[i]); } } int main(){ int s[7], i; printf("請輸入7個序列元素:\n"); for(i = 0; i < 7; i++){ scanf("%d", &s[i]); } printf("堆序前的序列為:"); print_arr(s, 7); heap_sort(s, 7); printf("\n堆排序后的序列為:"); print_arr(s, 7); return 0; }![]()
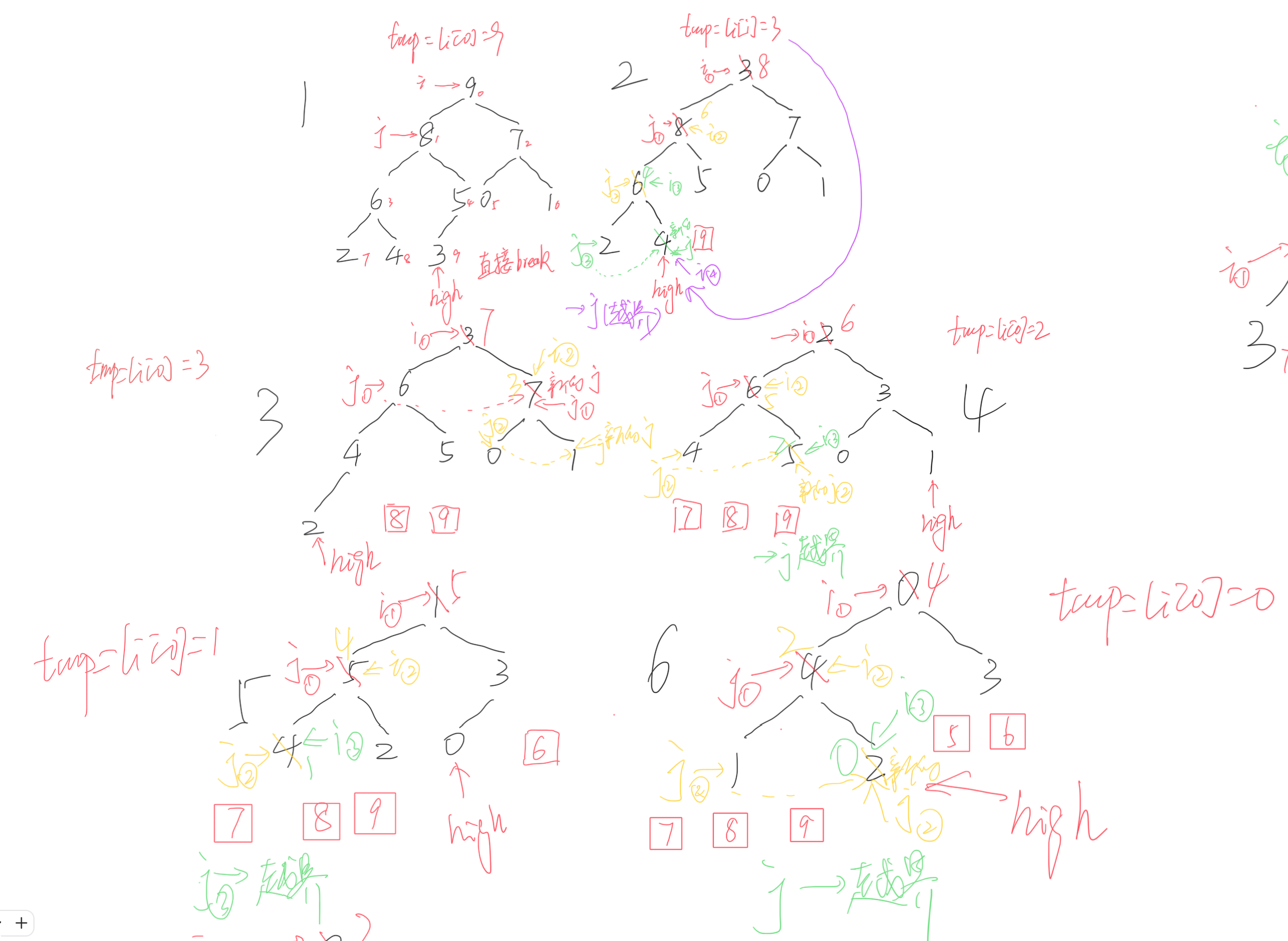
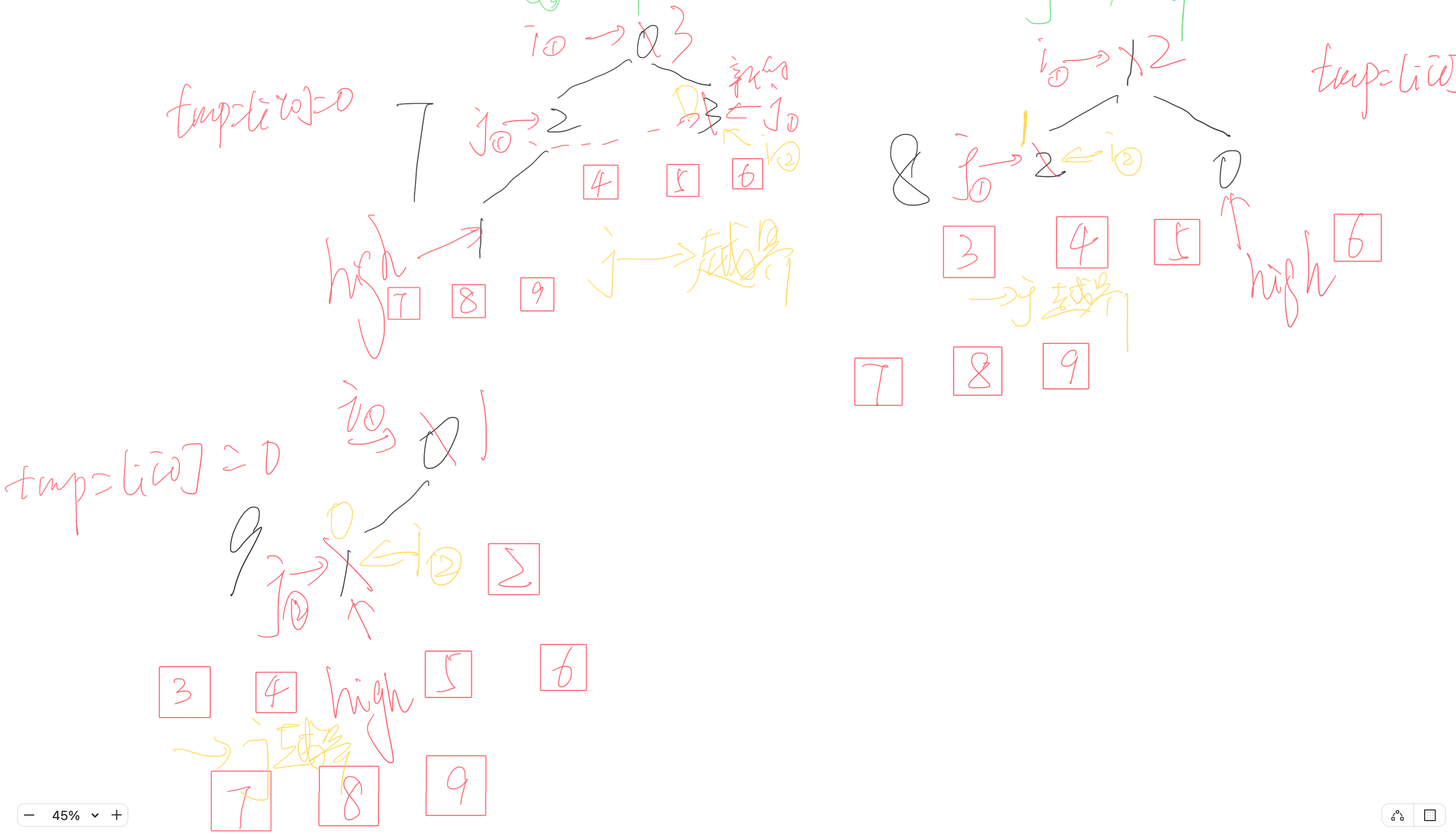
- 過程模擬
- 內容比較潦草,后期優化
- 根據代碼運行過程詳細記錄了每一次建堆過程的運行情況
- i和j右下角的①②③④是移動的輪數
- j發出的虛線是右孩子的值比左孩子大,更新j的值
- 紅色方框中的數是原堆頂的數,即有序序列
![]()
![]()
- 鋪墊知識
-
6.歸并排序
- 算法思想
- 分解:將一個大的序列越分越小,直至分成一個元素,單元素序列默認為有序
- 合并:從單元素序列開始,逐次將分解期間得到的序列歸并,序列長度擴充,直到最終合并為一個有序序列
- Python代碼
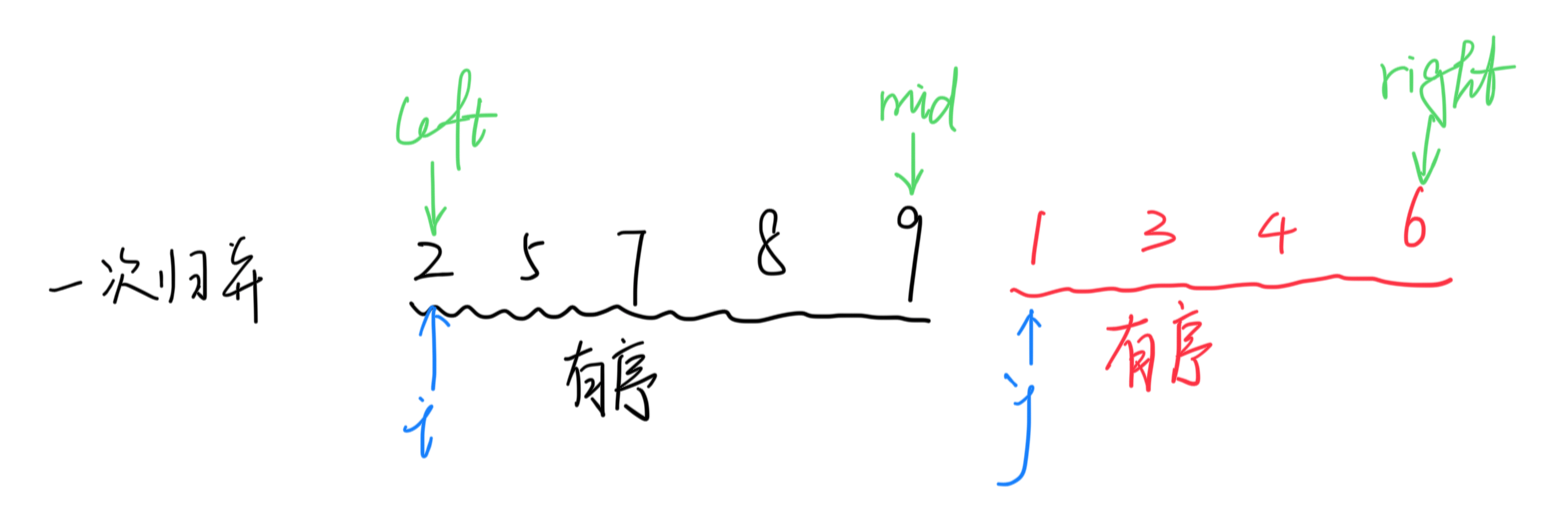
import random from cal_time import wrapper def merge(li, low, mid, high): # 假設列表分兩段有序,逐步遍歷兩段合成一個有序列表 i = low j = mid + 1 li_tmp = [] while i <= mid and j <= high: # 只要左右兩邊都有數 if li[i] < li[j]: li_tmp.append(li[i]) i += 1 else: li_tmp.append(li[j]) j += 1 # while退出時,至少有一段序列遍歷完畢 while i <= mid: li_tmp.append(li[i]) i += 1 while j <= high: li_tmp.append(li[j]) j += 1 li[low: high + 1] = li_tmp # 將暫存的有序序列再寫回到原序列中 def _merge_sort(li, low, high): if low < high: # 至少有2個元素,遞歸 mid = (low + high) // 2 _merge_sort(li, low, mid) _merge_sort(li, mid + 1, high) merge(li, low, mid, high) @wrapper def merge_sort(li, low, high): _merge_sort(li, low, high) li = list(range(1000)) random.shuffle(li) print(li) merge_sort(li, 0, len(li) - 1) print(li)![]()
- C語言代碼
#include <stdio.h> // 實現歸并的過程,中間位置是mid void merge(int s[], int left, int mid, int right){ int i = left, j = mid + 1, k = 0; const int LEN = right - left + 1; char s_temp[LEN]; while(i <= mid && j <= right){ // 只要左右兩個有序的子數組都有數 if(s[i] < s[j]){ s_temp[k++] = s[i++]; } else{ s_temp[k++] = s[j++]; } } // while執行完畢,至少有1個有序子數組遍歷完成 while(i <= mid){ s_temp[k++] = s[i++]; } while(j <= right){ s_temp[k++] = s[j++]; } i = 0, j = left; while(i < LEN && j <= right ){ s[j] = s_temp[i]; i++; j++; } // 將暫存的有序數組再寫回到原數組中 } // 使用歸并的特征完成真正的排序 void merge_sort(int s[], int left, int right){ int mid; if(left < right){ // 只要數組中至少存在2個數就繼續遞歸 mid = (left + right) / 2; merge_sort(s, left, mid); // 遞歸左邊 merge_sort(s, mid + 1, right); // 遞歸右邊 merge(s, left, mid, right); // 左邊和右邊合并 } } void print_arr(int s[], int n){ int i; for(i = 0; i < n; i++){ printf("%d ", s[i]); } } int main(){ int a[7], i; printf("請輸入7個序列元素:\n"); for(i = 0; i < 7; i++){ scanf("%d", &a[i]); } printf("歸并序前的序列為:"); print_arr(a, 7); merge_sort(a, 0, 6); printf("\n歸并排序后的序列為:"); print_arr(a, 7); return 0; }![]()
- 過程模擬
- 根據代碼運行過程詳細記錄了遞歸調用與返回的運行情況
- 遞歸的層次通過不同顏色的方框區分
- 不同級別的標題也可表示不同深度的遞歸
![]()
![]()
![]()
- 算法思想
-
7.希爾排序
- 算法思想
- 0.希爾排序是一種特殊的分組插入排序算法
- 1.首先取1個整數d1 = n / 2,將元素分為d1個組,每組相鄰兩元素之間距離為d1,在各組內進行直接插入排序
- 2.接著取第2個整數d2 = d1 / 2,重復上述分組排序過程,直到di = 1,即所有元素在同一組內時,進行最后一次直接插入排序,此時序列即有效序列
- 注意:在希爾排序過程中,每排完一輪并不使某些元素有序,而是使整體數據越來越接近有序
- Python代碼
import random from cal_time import wrapper def insert_sort_gap(li, gap): for i in range(gap, len(li)): tmp = li[i] j = i - gap while j >= 0 and li[j] > tmp: li[j + gap] = li[j] j -= gap li[j + gap] = tmp @wrapper def shell_sort(li): d = len(li) // 2 while d >= 1: insert_sort_gap(li, d) d = d // 2 li = list(range(10000)) random.shuffle(li) print(li) shell_sort(li1) print(li)![]()
- C語言代碼
#include <stdio.h> void insert_sort_gap(int s[], int n, int gap){ int i, j, temp; for(i = gap; i < n; i++){ temp = s[i]; j = i - gap; while(j >= 0 && s[j] > temp){ s[j + gap] = s[j]; j -= gap; } s[j + gap] = temp; } } void shell_sort(int s[], int n){ int d = n / 2; while(d >= 1){ insert_sort_gap(s, n, d); d /= 2; } } void print_arr(int s[], int n){ int i; for(i = 0; i < n; i++){ printf("%d ", s[i]); } } int main(){ int a[7], i; printf("請輸入7個序列元素:\n"); for(i = 0; i < 7; i++){ scanf("%d", &a[i]); } printf("希爾排序前的序列為:"); print_arr(a, 7); shell_sort(a, 7); printf("\n希爾排序后的序列為:"); print_arr(a, 7); return 0; }![]()
- 過程模擬
- 示例中d的值從分3組到分1組,相當于執行了2次shell_sort方法中的while循環
- j往左的虛線表示j的左移過程,temp的虛線表示temp賦值到合適的位置
- 當d為1,i指向8、9、14時未發生移動
![]()
- 算法思想
-
8.計數排序
- 算法思想
- 0.已知序列A中數的范圍都在0到100之間,設計時間復雜度為O(n)的排序算法
- 1.將索引0-100在序列B對應位置的值初始化為0,每遍歷到序列A中的某個數i,就將序列B中索引i對應位置的值加1,例如
- 序列A
- 數值:1 4 2 3 2 4 4 6 2
- 序列B
- 下標:0 1 2 3 4 5 6 下標為0-6是因為序列A中最大值為6
- 數值:0 1 3 1 3 0 1 數值為序列B下標值序列A的數值中出現的次數
- 序列A
- 2.依次遍歷序列B的數值,假設某次得到數值i,則打印i對應的下標,共計i次。因為下標逐漸變大,得到的序列便是原序列A的有序排列
- Python代碼
import random import copy from cal_time import wrapper @wrapper def count_sort(li, max_count=100): count = [0 for _ in range(max_count + 1)] for val in li: count[val] += 1 li.clear() for ind, val in enumerate(count): # enumerate 將下標和值做了對應 for i in range(val): li.append(ind) @wrapper def sys_sort(li): li.sort() li = [random.randint(0, 100) for _ in range(10000)] li1 = copy.deepcopy(li) li2 = copy.deepcopy(li) count_sort(li1) sys_sort(li2) print(li1)![]()
- C語言代碼
#include <stdio.h> #include <stdlib.h> #include <time.h> #define MAX 300 void print_arr(int s[], int n){ int i; for(i = 0; i < n; i++){ printf("%d ", s[i]); } } void set_zero(int s[], int n){ int i; for(i = 0; i < n; i++){ s[i] = 0; } } void count_sort(int s[], int c[], int m){ int i = 0, index, times; for(index = 0; index < m; index++){ times = c[index]; while(times != 0){ s[i++] = index; times--; } } } int main(){ int s[MAX] = {0}, count[101] = {0}, i; srand(time(NULL)); for(i = 0; i < MAX; i++){ s[i] = rand() % 101; count[s[i]]++; } set_zero(s, MAX); count_sort(s, count, 101); print_arr(s, MAX); return 0; }![]()
- 過程模擬
![]()
- 算法思想
-
9.桶排序
- 算法思想
- 0.在計數排序中,如果元素的范圍比較大(比如在1到1億之間)則算法效率顯著降低,如何改造算法?
- 1.可以先將元素分在不同的桶中,再對每個桶中的元素排序
- 注意:桶排序用的不多,重要性低于前面幾種排序方法;桶排序的表現取決于數據的分布,對不同的數據排序時需要采取不同的分桶策略
- Python代碼
import random from cal_time import wrapper @wrapper def bucket_sort(li, n=100, max_num=10000): # n表示桶的數量,數據的最大值為10000 buckets = [[] for _ in range(n)] # 創建桶 for var in li: # 桶號范圍為0 ~ n - 1,max_num/n的值是桶的數量,i表示var放到幾號桶里 # 9999放到99號桶里,當var=10000時越界,沒有100號桶,所以放到99號桶 i = min(var // (max_num // n), n - 1) buckets[i].append(var) # 將var加到桶中 # 追加一個數后,通過冒泡排序的過程保持桶內的順序 # 從桶中最后一個元素開始與前面的元素比,一直到數組中下標為1的數 for j in range(len(buckets[i]) - 1, 0, -1): if buckets[i][j] < buckets[i][j - 1]: buckets[i][j], buckets[i][j - 1] = buckets[i][j - 1], buckets[i][j] else: break sorted_li = [] for buc in buckets: sorted_li.extend(buc) return sorted_li li = [random.randint(0, 10000) for i in range(100000)] li = bucket_sort(li) print(li)![]()
- C語言代碼
- 算法思想
-
10.基數排序
- 算法思想
- Python代碼
- C語言代碼





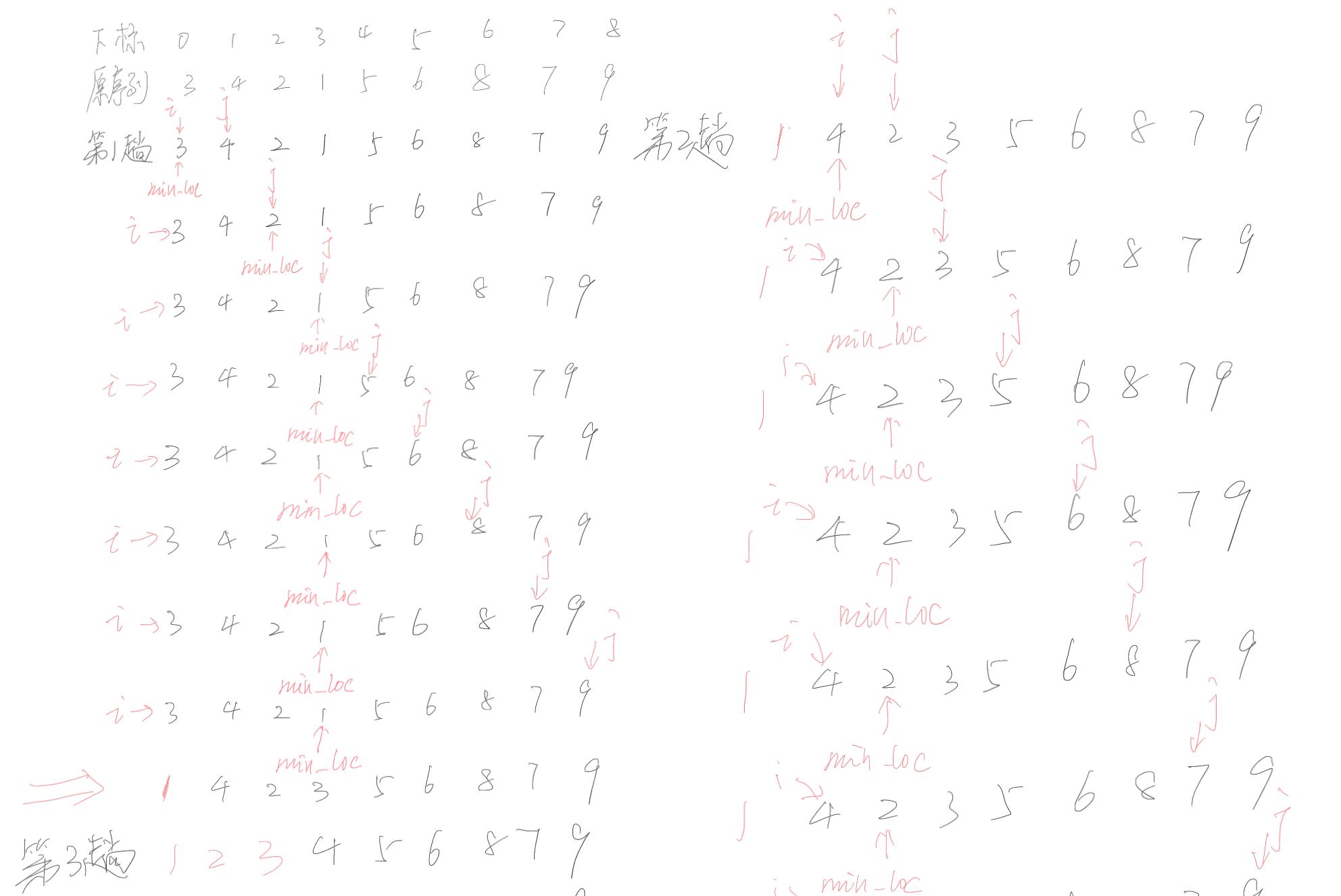





















 浙公網安備 33010602011771號
浙公網安備 33010602011771號