
第5章 數組
運行環境以Dev-C++、Visual Studio 2022、MacOS的命令行和Xcode為主
0.章節引言
-
1.截至目前所學的數據類型均為簡單數據類型,只能存放一個值,如
int a = 1; int b = 2;。隨著用戶程序功能的擴展,有時需要一個變量能存儲多個值,如將上述a、b、c的值存儲在一個變量中,這種變量的類型屬于構造類型 -
2.C語言中的數組是一種構造類型,由基本數據類型按照一定規則組成的新類型
-
3.數組中每個值的類型必須與數組的類型相同,使用數組名和下標來唯一確定數組中的元素
1.一維數組的定義和使用
-
1.1 一維數組的定義
-
一般格式:
類型說明符 數組名[常量表達式] -
注意事項
-
1.數組名的命名規則與變量名相同,遵循標識符命名規則,即只能由字母、數字和下劃線組成且數字不能開頭
-
2."常量表達式"表示數組元素的個數,定義數組時必須指定該值,然后系統才能根據數組的類型和長度向內存申請空間
-
3.引用元素時下標從 0 開始,所以長度為 N 的元素下標范圍為 0 ~ N - 1
-
C語言不對下標做越界檢查,強行訪問下標為 N 或其后的元素時,有的編譯器不會報錯,但這是個邏輯錯誤,可能會造成程序或系統崩潰等嚴重的后果
-
以下代碼因越界訪問而造成“死循環”
#include <stdio.h> int main() { int i = 0; int arr[10] = {5, 6, 7, 8, 9, 0, 11, 23, 25, 55}; for (i = 0; i <= 12; i++) { arr[i] = i + 1; printf("test\n"); } return 0; } -
-
4.在
C89和C90標準中,"常量表達式"包括基本常量和符號常量(含宏常量,如#define N 7 int a[N]是允許的),不能包含變量,這一點與switch結構中case的使用相似
// 以下代碼若在C99之前的標準下編譯會報錯 // 在C99及其之后的標準中,"常量表達式"允許包含變量,下述代碼編譯通過 int n = 0; scanf("%d", &n); int a[n]; int n = 0; scanf("%d", &n); int a[n] = {0}; // 報錯,不能對可變數組初始化![]()
// 可通過賦值的方式對可變數組進行初始化 int i = 0, n = 5; int a[n]; for (i = 0; i < 5; i++) { a[i] = i; printf("%d ", a[i]); }- 5.定義數組時,C語言分配足夠的內存來存放所有元素,且元素在內存中連續存放,數組名本身表示內存的首地址。數組的下標相當于某個元素相對于數組首地址的偏移量
-
-
關于數組的地址
- 1.數組名表示數組在內存中的首地址
#include <stdio.h> int main(){ int a[5]; printf("數組a在內存中的首地址為%x\n", a); return 0; }![]()
-
2.數組名的位移與數組元素的地址
-
數組名表示數組在內存空間中存儲的首地址,首地址處存儲的恰好是下標為0的數組元素
-
數組名向下偏移時增量的物理意義為:
增量值 * sizeof(數組類型)。代碼中a+1的值與a+0的值相差4而不是1,因為整型數組a中每個元素均為整型,在內存中占用4B
-
#include <stdio.h> int main(){ int a[5]; printf("數組a在內存中的首地址為%x\n", a); printf("基于數組名的偏移量取地址: %x %x %x\n", a+0, a+1, a+2); printf("基于數組元素取地址: %x %x %x\n", &a[0], &a[1], &a[2]); return 0; }![]()
![]()
-
-
1.2 一維數組元素的引用
-
一般格式:
數組名[下標]; []為下標引用操作符,數組名和下標為[]運算符的操作數,優先級為1 -
注意事項
-
1.C語言中只能逐個引用數組元素,不能一次引用整個數組
-
2."下標"可以是整型常量或整型表達式,不要越界
-
3.對數組部分元素或所有元素批量讀寫是常規操作,常配合循環語句一起使用
-
-
案例分析
- 1.輸入10個學生的成績,先計算它們的總分,再輸出它們的平均分
#include <stdio.h> int main() { // 1.定義變量 int i = 0; float scores[10] = {0}; float sum = 0.0f, avg = 0.0f; printf("請輸入10個學生的成績:\n"); // 2.數據輸入 for (i = 0; i < 10; i++) { scanf("%f", &scores[i]); } // 3.數據處理 for (i = 0; i < 10; i++) { sum += scores[i]; } avg = sum / 10; // 4.數據輸出 printf("平均分=%.2f\n", avg); return 0; } // 簡化版代碼,在數據輸入的同時完成累加 #include <stdio.h> int main() { int i = 0; float scores[10] = {0}; float sum = 0.0f, avg = 0.0f; printf("請輸入10個學生的成績:\n"); for (i = 0; i < 10; i++) { scanf("%f", &scores[i]); sum += scores[i]; } printf("平均分=%.2f\n", sum/10); return 0; }
-
-
1.3 一維數組的初始化
- 1.為全部元素賦值,元素值的類型必須與數組類型匹配,
{}中值的個數不能超過數組長度
int a[5] = {5, 4, 3, 2, 1};- 2.為部分元素賦值,其余未賦值元素值默認為0
int a[10] = {5, 4, 3, 2, 1}; // a[5] ~ a[9]值均為0 int a[10] = {1*10}; // a[0] = 10, a[1] ~ a[9]值均為0- 3.若
{}中指定了所有元素值,則數組長度可省略,編譯器根據賦值的個數自動定義數組的長度。當并未指定所有元素值時長度不能省略
int a[] = {5, 4, 3, 2, 1}; // 數組長度5可省略 scanf("%f", scores); // 該語句只能實現對第1個(下標為0)元素的輸入,且新值一直在覆蓋舊值。scores等價于&scores[0]- 4.求數組元素個數
int arr[10] = {1, 2, 3, 4, 5}; printf("數組a占用內存空間%dB\n", (int)sizeof(arr)); printf("數組a中共有%d個元素\n", (int)sizeof(arr)/(int)sizeof(arr[0]));![]()
-
5.案例分析
- 1.輸出斐波那契數列的前10個數
// 分析:定義長度為10的整型數組a存儲數列的前10個數。斐波那契數列從第3項(數組中下標為2的元素)開始,每個數等于前兩個數之和 // 通項公式:a[i] = a[i - 1] + a[i - 2](i >= 2) #include <stdio.h> int main() { int i = 0, a[10] = {1, 1}; for (i = 2; i < 10; i++) { a[i] = a[i - 1] + a[i - 2]; } for (i = 0; i < 10; i++) { printf("%4d", a[i]); } return 0; }
- 1.為全部元素賦值,元素值的類型必須與數組類型匹配,





2.二維數組的定義和使用
-
2.1 二維數組的定義及引用
-
一般格式
-
定義:
類型說明符 數組名[常量表達式1][常量表達式2]; -
引用:
數組名[行標][列標];
-
-
注意事項
-
1.常量表達式的規則和一維數組相同,可使用宏常量
-
2.C語言采用行優先的方式來存儲二維數組(順序存儲第1行、第2行...第M行的所有元素),邏輯上是一張M行N列的表格,物理上在內存中仍然是順序存儲
-
3.二維數組的輸入和輸出通常結合雙重循環使用
- 第1行元素:
c[0][0] c[0][1] c[0][2] c[0][3] c[0][4] - 第2行元素:
c[1][0] c[1][1] c[1][2] c[1][3] c[1][4] - 第3行元素:
c[2][0] c[2][1] c[2][2] c[2][3] c[2][4]
- 第1行元素:
// 從宏觀上看,總共有3行,行標遍歷了0、1、2 ---> 外循環 // 從微觀上看,每一行的列標均遍歷了0、1、2、3、4 ---> 內循環 // 每固定到一行,列標遍歷了0 ~ 4所有的數,總共遍歷3行,執行邏輯恰好符合雙重循環 for (i = 0; i < ROWS; i++) { for (j = 0; j < COLS; j++) { scanf("%d", &c[i][j]); } } for (i = 0; i < ROWS; i++) { for (j = 0; j < COLS; j++) { printf("%d ", c[i][j]); } }- 4.一維數組是普通單個字面量的集合,而二維數組相當于多個一維數組的組合,邏輯上的每一行可以看做一個一維數組,
c[0]、c[1]、c[2]可看做一維數組的數組名。由于數組名也是地址,所以c[0]、c[1]、c[2]為每行元素開始存儲時的首地址,也就是c[0][0]、c[1][0]、c[2][0]的首地址,具體可通過以下代碼驗證
#include <stdio.h> #define M 3 #define N 5 int main(){ int c[M][N] = {{1, 2, 3, 4, 5}, {6, 7, 8, 9, 10}, {11, 12, 13, 14, 15}}; printf("每一行元素的首地址分別為: %x %x %x\n", c[0], c[1], c[2]); printf("每一行第一個元素的首地址分別為: %x %x %x", &c[0][0], &c[1][0], &c[2][0]); return 0; }![]()
-
5.實際應用中可采用按列優先訪問方式,具體代碼如下:
- 第1列元素:
c[0][0] c[1][0] c[2][0] - 第2列元素:
c[0][1] c[1][1] c[2][1] - 第3列元素:
c[0][2] c[1][2] c[2][2] - 第4列元素:
c[0][3] c[1][3] c[2][3] - 第5列元素:
c[0][4] c[1][4] c[2][4]
- 第1列元素:
// 從宏觀上看,總共有5列,列標遍歷了0、1、2、3、4 ---> 外循環 // 從微觀上看,每一列的行標均遍歷了0、1、2 ---> 內循環 // 每固定到一列,行標遍歷了0 ~ 2所有的數,總共遍歷5列,執行邏輯恰好符合雙重循環 for (i = 0; i < COLS; i++) { for (j = 0; j < ROWS; j++) { scanf("%d", &c[j][i]); // 注意行標為j,列標為i } } for (i = 0; i < COLS; i++) { for (j = 0; j < ROWS; j++) { printf("%d ", c[j][i]); } } -
-
-
2.2 二維數組的初始化
- 1.分行全部賦值,直觀易懂,容易看出各元素的值,推薦使用該賦值方式
int a[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}};- 2.分行部分賦值,未賦值的元素值為0
int a[3][4] = {{1, 2}, {9, 10, 11}}; // 下標為2的行不賦值 int a[3][4] = {{1, 2}, {}, {9, 10, 11}} // 下標為1的行不賦值- 3.按一維數組的形式(部分)賦值
int a[3][4] = {1, 2, 3, 4, 5} // 缺乏直觀性,可讀性差,不推薦使用該賦值方式- 4.若為全部元素賦值,定義數組時可省略第一維的長度,但第二維長度不能省略,系統根據數據的總數分配內存
int a[][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}}; int a[][4] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}- 5.若采用分行部分賦值形式初始化數組,也可省略第1維長度
int a[][4] = {{1, 2}, {}, {9, 10, 11}}; // 系統可確定為3行4列-
6.案例分析
- 1.輸入一個 3 * 4 矩陣,找出矩陣中負數的個數并輸出
// 分析:1.3行4列的二維數組也可稱作3行4列的矩陣 // 2.題目的本質在于通過雙重for循環對數組賦值后遍歷,找到負數并計數 #include <stdio.h> int main() { int matrix[3][4] = {0}; int i = 0, j = 0, count = 0; printf("輸入一個3×4矩陣:\n"); for (i = 0; i < 3; i++) { for (j = 0; j < 4; j++) { scanf("%d", &matrix[i][j]); // 如果當前元素是負數,則計數器加1 if (matrix[i][j] < 0) { count++; } } } // 輸出矩陣中負數的個數 printf("矩陣中負數的個數是: %d\n", count); return 0; }

3.字符數組的定義和使用
-
3.1 字符數組的定義及元素引用
- 一般格式:定義方式與一維數組相似,只是數組和元素類型為
char
char s[6]; // 字符數組s,長度為6B,元素為s[0] ~ s[5]-
注意事項
- 1.C語言中不存在字符串類型,用字符數組來存儲字符串
char s1[10] = {'f', 'a', 's', 'h', 'i', 'o', 'n'} // 定義字符數組s1存放字符串"fashion"- 2.C語言規定字符
'\0'作為字符串的結束標志符,存儲字符串常量時自動在其末尾添加'\0'。'\0'表示對字符'0'進行轉義,轉義之后表示特殊的含義,ASCII碼值為0。該標志用于判斷字符串是否結束,而不是用字符串數組長度
for (i = 0; s[i] != '\0'; i++) { putchar(s[i]); }-
3.實際應用中更關注字符串的長度,而不是字符數組的長度。由于字符串末尾有默認的
'\0',所以在為字符數組賦值時,要預留出1個字符的位置放置'\0' -
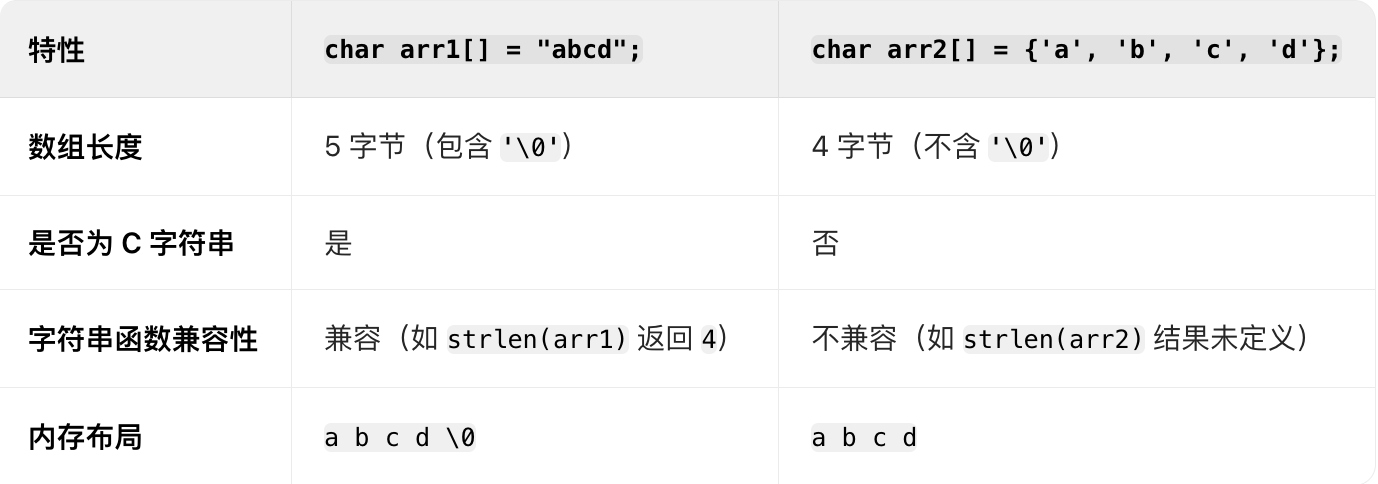
4.字符串字面量初始化與字符列表初始化的區別
// 代碼1 #include <stdio.h> int main(){ char arr1[] = "abcd"; char arr2[] = {'a', 'b', 'c', 'd'}; // 末尾不含'\0' printf("%s\n", arr1); printf("%s\n", arr2); return 0; } char arr3[5] = {'a', 'b', 'c', 'd', '\0'}; // 等價于 char arr3[] = "abcd";![]()
![]()
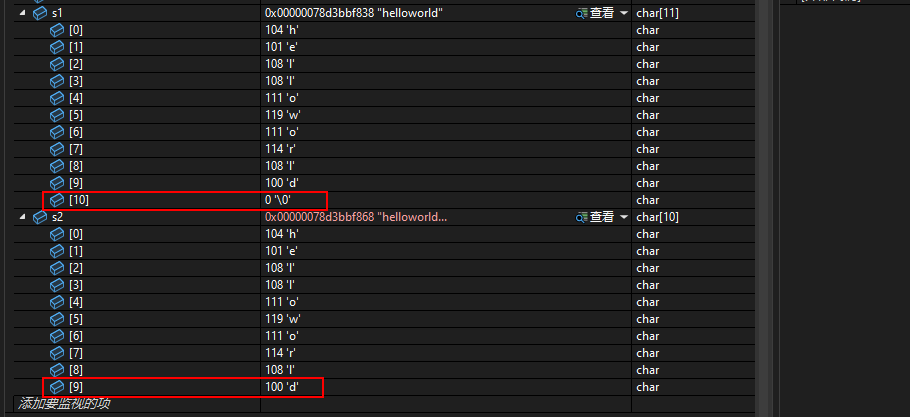
// 代碼2 #include <stdio.h> int main() { char s1[] = "helloworld"; char s2[] = {'h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd'}; puts(s1); puts(s2); return 0; } // 以上代碼在Visual Studio 2022中的運行結果如下圖,有亂碼(下圖1) // Visual Studio 2022中在嘗試打印s2時會有異常提示,因為省略字符數組長度以字符形式賦值時,不包含'\0'(下圖2) // 調試階段查看s1和s2的值,發現s1實際上是11個字符,最后有'\0';而s2只有賦值的10個字符,不含'\0'(下圖3)![]()
![]()
![]()
-
5.區分
0 '0' '\0'-
數字
0,int型字面量,值為0 -
字符
'0',字符常量,ASCII碼為48 -
字符
'\0',空字符,ASCII碼為0
![]()
-
- 一般格式:定義方式與一維數組相似,只是數組和元素類型為
-
3.2 字符數組的初始化
- 1.字符列表初始化,對部分(或全部)字符賦值,其余元素為零值(即ASCII碼為0的字符)。若
{}內字符個數超過數組長度會報語法錯誤
char s1[10] = {'f', 'a', 's', 'h', 'i', 'o', 'n'}; // s1[7] ~ s1[9]的結果均為'\0',這是不完全初始化帶來的默認初始化- 2.字符串字面量初始化,字符個數應少于數組長度,書寫簡潔
char s2[10] = {"fashion"}; // s1[7]~s1[9]的結果均為'\0'- 3.省略一維長度,字符串長度由賦值號右邊字符串常量的字符個數決定
char s3[] = {"perfect"}; char s4[] = "perfect"; // 數組長度為8 - 1.字符列表初始化,對部分(或全部)字符賦值,其余元素為零值(即ASCII碼為0的字符)。若
-
3.3 字符數組的輸入/輸出
- 1.逐個處理字符數組元素
char s[10] = {0}; for (i = 0; i < 10; i++) { scanf("%c", &s[i]); } for (i = 0; i < 10; i++) { printf("%c", s[i]); }-
2.使用格式符
%s整體輸入與輸出字符數組- 使用scanf()函數整體輸入
// 1.數組s最多接收9個字符 // 2.當輸入的字符串中存在空格、制表符或回車符,因為scanf()的存在,上述字符會作為字符串的輸入結束標志 char s[10] = {0}; scanf("%s", s); // 若輸入"thank you",則只有"thank"會被接收 scanf("%s", &s); // 錯誤寫法,s本身已經是地址- 使用printf()函數整體輸出
// 若數組以字符形式對全部元素賦值,且元素中不包含'\0',采用"%s"輸出時,由于檢測不到結束標志,可能會額外輸出亂碼字符。即3.1注意事項部分第4點提及的內容 char str[] = "perfect"; printf("%s", str); // 系統檢測到第一個'\0'即停止輸出,打印"perfect" char str[] = "hello!\0ab"; printf("%s", str); // 系統檢測到第一個'\0'即停止輸出,打印"hello!" printf("ab0d"); // 打印"ab0d" printf("abc\0ef"); // 打印"abc" printf("abc\\0ef"); // 打印"abc\0ef" -
3.使用gets()函數或puts()函數整體輸入與輸出字符數組
- 使用gets()函數整體輸入
// gets(字符數組名); 從鍵盤上輸入一個字符串賦給該數組 char s[20] = {0}; gets(s); // gets()函數以回車符作為數據輸入結束的標志,因此空格可以作為字符串的一部分輸入,這一點與scanf()函數完全不同- 使用puts()函數整體輸出
// puts(字符數組名); puts(字符串常量); 將字符數組或字符串輸出 char str[20] = {"One Two \0 Three"}; printf("%s", str); puts(str); puts("thank you! \0 abc "); // puts()函數和printf()函數都能輸出字符串中第一個'\0'(不含)之前的所有字符,不同的是puts()函數輸出字符串后會自動換行
-
3.4 字符串處理函數
-
1.求串長函數strlen(s)
-
作用:計算字符串
s的長度,即首次出現'\0'之前的字符個數,s可以為字符串常量或字符數組 -
案例分析
char s2[20] = {"One\0 Two \0 Three"}; // strlen(s2)為3 char s3[] = "thank&you!\0 abc"; // strlen(s3)為10 strlen("abc\t1234\123\n"); // 結果為10,'\t'和'\n'均為轉義字符 strlen("C:\test\628\test.c"); // 結果為14,'\62'是一個轉義字符,'8'是單獨的字符,八進制中不包含8- 代碼實現:編寫代碼計算字符串
str的長度,從第一個字符開始遍歷,逐次累加基數變量,直到當前字符為'\0'
#include <stdio.h> int main() { char str[] = "hello\0abc"; int length = 0; while (str[length] != '\0') { length++; } printf("%d", length); return 0; } -
-
2.串賦值函數strcpy(s1, s2)
-
作用:將字符串
s2的內容復制到字符串s1中,復制方向為第2個參數賦值給第1個參數,s1必須是容量足夠大的字符數組,s2可以是字符串常量或字符數組 -
案例分析
char s1[20] = "thank you!", s2[] = "hello!"; strcpy(s1, s2); // 此時s1為"hello!" // 字符串之間的賦值不能通過普通變量賦值語句a = b;實現,因為字符數組名是地址常量- 代碼實現:編寫代碼實現字符串的復制,遍歷源字符數組,依次將讀取的字符復制到目標數組中,直到源數組讀取到
'\0',注意目標數組的結束符\0
#include <stdio.h> int main() { char src[20] = "thank you!", dest[20] = {0}; int i = 0; while (src[i] != '\0') { dest[i] = src[i]; i++; } // dest[i] = '\0'; return 0; } -
-
3.串連接函數strcat(s1, s2)
-
作用:將字符串
s2的內容連接到字符串s1的后面構成一個新的字符串并存入字符串s1中。連接方向為第2個參數到第1個參數,s1必須是容量足夠大的字符數組,s2可以是字符串常量或字符數組 -
案例分析
// 連接時,系統自動刪除 s1 后的 '\0',然后將 s2 的內容連接到 s1 后方,并在新字符串末尾添加 '\0' char s1[20] = "thank ", s2[] = "you!"; strcat(s1, s2); // 此時s1為"thank you!"- 代碼實現
#include <stdio.h> int main() { char src[20] = "very much!", dest[20] = "thank you "; int dest_index = 0, src_index = 0; // 找到目標字符串的結束位置 while (dest[dest_index] != '\0') { dest_index++; } // 將源字符串復制到目標字符串的末尾 while (src[src_index] != '\0') { dest[dest_index] = src[src_index]; dest_index++; src_index++; } // 添加字符串結束符 dest[dest_index] = '\0'; return 0; } -
-
4.串比較函數strcmp(s1, s2)
-
作用:比較字符串s1和s2內容的大小,s1、s2可以是字符串常量或字符數組
-
比較標準
-
字符串比較并不是比較它們的長度,而是對兩個字符串從左至右依次比較對應的字符(比較標準為ASCII碼值),直到遇到不同字符為止
-
只有全部字符相同時才認為兩字符串相等,否則以遇到的第一個不同字符的相對大小來確定大小關系
-
若strcmp(s1, s2)的返回結果小于0,則s1 < s2;若返回結果大于0,則s1 > s2;否則s1 = s2
-
-
案例分析
"abc"大于"ABC",因為'a' > 'A' "abCdef"小于"abcd",因為'C' < 'c' "COM"小于"COMPUTER",因為'\0'小于'P'- 代碼實現:寫代碼實現兩個字符串的比較功能
// 情況1:"thank you" VS "thaNk you" // 情況2:"hello" VS "Welcome" // 情況3:"chinese" VS "chineseGOOD" // 情況4:"english" VS "english" #include <stdio.h> int main() { char s1[20] = "thank you!", s2[20] = "thaNk you"; int i = 0; for (i = 0; s1[i] != '\0' && s2[i] != '\0'; i++) { if (s1[i] != s2[i]) { printf("%d\n", s1[i] - s2[i]); return 0; } } printf("%d\n", s1[i] - s2[i]); return 0; } #include <stdio.h> int main() { char s1[20] = "thank you!", s2[20] = "thaNk you"; int i = 0; int sub = 0; for (i = 0; s1[i] != '\0' && s2[i] != '\0'; i++) { if (s1[i] != s2[i]) { break; } } sub = s1[i] - s2[i]; if (sub > 0) { printf("s1 > s2\n"); } else if(sub < 0) { printf("s1 < s2\n"); } else { printf("s1 == s2\n"); } return 0; } -
-




4.數組的應用舉例
- 1.找出10個學生中成績低于平均成績的人數并輸出
// 分析:1. 定義一個長度為10的浮點型數組scores,存儲10個學生成績。for循環 scanf()輸入
// 2. 計算出平均成績。為簡化程序代碼量,可以在成績輸入的同時將其累加到變量avg中
// 3. 計算平均成績,統計低于平均成績的人數。遍歷 for循環中嵌入if 計數變量 printf()打印輸出
#include <stdio.h>
#define NUM 10
int main(int argc, const char * argv[]) {
// insert code here...
int i = 0, count = 0;
float scores[NUM] = {0.0f};
float avg = 0.0f;
printf("請輸入%d位學生成績:", NUM);
for (i = 0; i < NUM; i++) {
scanf("%f", scores + i);
avg += scores[i];
}
avg /= NUM;
printf("\n平均成績:%.1f\n", avg);
for (i = 0; i < NUM; i++) {
if (scores[i] < avg) {
count++;
}
}
printf("低于平均成績的人數為: %d\n", count);
return 0;
}
-
2.輸入 5 個學生的 3 門課程成績,求每個學生的平均成績和每門課程的平均成績
-
1.明確本題與上一題的差別,維度升為"二維"。因為成績是由<學生,科目>共同決定的,因此定義二維數組
scores[5][3]存儲各學生各科成績,需要用到雙層for循環、scanf語句 -
2.各學生的平均成績 vs 各門課的平均成績,剛好是
scores[5][3]的兩個分量維度——科目和學生。科目有多門,學生也有多個,可分別用一維數組avg_stu[5]和avg_course[3]存儲- 2.1 求解平均成績,應當先求總成績,包括每位學生的總成績和每門科目的總成績,參考下圖:需求轉化為計算各行數據的平均值 + 各列數據的平均值
![]()
-
2.2 此問題本質上依然是二維數組的遍歷,因此雙重for循環必不可少,只是雙重循環內要做的是按行循環加和與按列循環加和。以按列循環為例,累加的對象是
s[0][0]、 s[1][0]、 s[2][0]、 s[3][0]、 s[4][0]……以此類推。在行列標中,列號是不變的,所以它充當了外循環,行號依次遞增,所以它充當了進入外循環后的內循環 -
2.3 遍歷avg_stu[5]和avg_course[3],輸出各元素值,使用for循環、printf
#include <stdio.h> #define NUM 10 int main(int argc, const char * argv[]) { // insert code here... float scores[5][3] = {0}; float avg_stu[5] = {0}, avg_course[3] = {0}; int i = 0, j = 0; printf("輸入5個學生的3門課程成績:\n"); for (i = 0; i < 5; i++) { for (j = 0; j < 3; j++) { scanf("%f", &scores[i][j]); avg_stu[i] += scores[i][j]; } avg_stu[i] /= 3; } for (i = 0; i < 3; i++) { // 由于數組avg_course已經初始化,此處無需再加語句 avg_course[i] = 0; for (j = 0; j < 5; j++) { avg_course[i] += scores[j][i]; // 注意此處的行列標順序為j i而非i j } avg_course[i] /= 5; } printf("每個學生的平均成績為:\n"); for (i = 0; i < 5; i++) { printf("%-8.2f", avg_stu[i]); } printf("\n每門課程的平均成績為:\n"); for (i = 0; i < 3; i++) { printf("%-8.2f", avg_course[i]); } return 0; } // 本題的另一種非數組解法在第4章第4小節的循環嵌套案例2已提到 -
-
3.已有一個排好序的序列,輸入一個數插入到該序列中,使之仍然保持有序。例如將15插入到有序序列 {3, 7, 10, 12, 18, 20} 中
-
將有序序列保存在一個數組中,逆序遍歷序列,凡是大于待插入數據
x的數依次后移動。"移動"是重復動作且次數不確定,此處選擇while循環 -
情形1:待插入數據比所有數據都大
-
以 25 為例,逆序遍歷時先判斷
a[5](值為20) < x(值為25),所以a[5]前方的數據都不需要再判斷,循環直接結束,將25寫在a[5]后方的存儲位置,即a[6] -
整個過程沒有數組元素的移動,直接將 25 覆蓋掉了
a[6]位置上原始的0(定義時數組長度為20)。故插入一個大于所有數組元素的數時不存在異常情況
-
-
情形2:待插入數據比所有數據都小
-
以 1 為例,它小于所有數,
a[5] ~ a[0]的數均需依次后移一個位置(a[5]的值移動到a[6],a[4]的值移動到a[5],依次類推) -
當
while循環判斷a[0] > x(即 3 > 1)時依然成立,繼續執行循環體會使得下標i減 1,就會判斷a[-1] > x,產生邏輯錯誤。故插入一個小于所有數組元素的數時存在下標越界的異常情況 -
在
while循環中加一個i >= 0的條件表達式防止下標越界
-
#include <stdio.h> int main() { int a[20] = {3, 7, 10, 12, 18, 20}; int x = 1, n = 6; int i = n - 1; while(i >= 0 && a[i] > x) { a[i + 1] = a[i]; i--; } a[i + 1] = x; n ++; for(i = 0; i < n; i ++) { printf("%-4d", a[i]); } return 0; }- 邏輯錯誤分析:它不一定會導致程序運行錯誤或崩潰,但可能會產生嚴重的后果
-
數組下標為 -1 的地址是越界訪問,該地址是有意義的,即所申請的數組存儲空間的首地址向前偏移一個單位所對應的地址
-
該地址未隨數組空間一起初始化,其中的數據值不確定。若是正在被系統或其他APP使用中的地址空間,則可以被訪問,其數據的意義取決于系統或APP所寫入的數據,訪問后可能會引起系統或APP異常
-
沒有被使用的地址被稱為"野地址",其數據隨機且無意義,因此數組中的 -1 下標應當避免,如以下代碼
-
// 以下代碼在MacOS的Xcode中運行為死循環,直接原因是下標越界,根本原因是變量 i 的地址恰巧與 arr[-5] 的地址一致 #include <stdio.h> int main(int argc, const char * argv[]) { int i = 0; int arr[6] = {6, 5, 4, 3, 2, 1}; // printf("i: %p\n", &i); for (i = 5; i >= -5; i--) { arr[i] = 0; printf("循環內\n"); // printf("&arr[%d]: %p\n", i, &arr[i]); } printf("循環外\n"); return 0; }![image]()
-
-
4.編寫一個程序,將字符串轉置并輸出。例如"abcde"——>"edcba"


// 方法1:使用兩個字符數組 s 和 t,倒序遍歷 s,依次將從 s 中讀取到的字符順序寫入 t 中。此方法中 s 的下標從后往前,t的下標從前往后,理清下標的變化關系
#include <stdio.h>
#include <string.h>
#define MAX 100
int main() {
char s[MAX] = {0};
char t[MAX] = {0};
int i = 0, j = 0;
int n = 0;
printf("請輸入字符串:");
gets(s);
n = strlen(s);
i = n - 1;
while(i >= 0) {
// t[j++] = s[i--];
t[j] = s[i];
i--;
j++;
}
// 由于數組 t 最開始已初始化為0, 此處無需再加"t[j] = '\0';",若未初始化則需要加上。建議無論是數組還是普通變量在定義的同時直接初始化
printf("轉置后的字符串為:");
puts(t);
return 0;
}
// 方法2:僅使用一個字符數組s,就地轉置,即 s 中第 1 個字符和最后一個字符交換,第 2 個字符和倒數第 2 個字符交換,以此類推。定義 i 作為下標從前往后移動,定義 j 作為下標從后往前移動
// 以長度為奇數位的字符串"score"為例,'s'與'e'交換,'c'與'r'交換,'o'沒必要再與自身交換,即 i 后移到'o'、j 前移到'o'時循環退出,此時 i == j
// 以長度為偶數位的字符"orange"為例,'o'與'e'交換,'r'與'g'交換,'a'與'n'交換,此時已完成逆序操作。當 i 后移到 'n',j 前移到 'a' 時循環退出,此時 i > j
// 綜上,循環繼續的條件為以上兩種情況取并集(i >= j)后的補集,即 i < j
#include <stdio.h>
#include <string.h>
#define MAX 100
int main() {
char s[MAX] = {0};
char temp = 0;
int i = 0, j = 0;
int n = 0;
printf("請輸入字符串:");
gets(s);
n = strlen(s);
j = n - 1;
while(i < j) {
temp = s[i];
s[i] = s[j];
s[j] = temp;
i++;
j--;
}
printf("轉置后的字符串為:");
puts(s);
return 0;
}

 浙公網安備 33010602011771號
浙公網安備 33010602011771號