
云平臺和虛擬化智慧運維監控,全面提升故障感知與處置能力
 隨著云計算、大數據技術等發展,虛擬化的普及不斷深入,已成為現代IT基礎設施建設中不可或缺的組成部分,成為推動企業數字化轉型的關鍵力量。虛擬化的應用在降低軟硬件成本和復雜性的同時,如何保障虛擬環境的高效運行,也給運維人員帶來了更大的挑戰。虛擬化監控運維方案通過對虛擬化環境的實時監控和深入管理,提高對虛擬化故障的感知、分析、解決能力,保障其性能高可用和環境的穩定。
隨著云計算、大數據技術等發展,虛擬化的普及不斷深入,已成為現代IT基礎設施建設中不可或缺的組成部分,成為推動企業數字化轉型的關鍵力量。虛擬化的應用在降低軟硬件成本和復雜性的同時,如何保障虛擬環境的高效運行,也給運維人員帶來了更大的挑戰。虛擬化監控運維方案通過對虛擬化環境的實時監控和深入管理,提高對虛擬化故障的感知、分析、解決能力,保障其性能高可用和環境的穩定。
隨著云計算、大數據技術等發展,虛擬化的普及不斷深入,已成為現代IT基礎設施建設中不可或缺的組成部分,成為推動企業數字化轉型的關鍵力量。虛擬化的應用在降低軟硬件成本和復雜性的同時,如何保障虛擬環境的高效運行,也給運維人員帶來了更大的挑戰。
北京智和信通虛擬化監控運維方案通過對虛擬化環境的實時監控和深入管理,提高對虛擬化故障的感知、分析、解決能力,保障其性能高可用和環境的穩定。
第1章 靈活的虛擬化監控方式
方案提供兩種方式對虛擬機進行監控,一種是作為宿主機的虛擬機資源進行監控,另一種是將其作為真實主機(操作系統)進行監控。兩種監控方式均通過主動輪詢和日志解析的方式監測虛擬機的常見性能,不同方式的監控范圍和內容有所差異。
1.1.作為宿主機的虛擬機資源監控
對宿主機可實現如Ping服務成功率、Ping平均響應時間、CPU使用率、內存使用率、磁盤使用率、虛擬機(數量、清單、操作系統)、網絡接口流量帶寬等指標的監控。
對虛擬機資源可實現如CPU使用率、內存利用率、磁盤容量,磁盤使用率、網絡流量等監控;在控制方面可以對虛擬機可以進行重啟、備份、鏡像等操作。
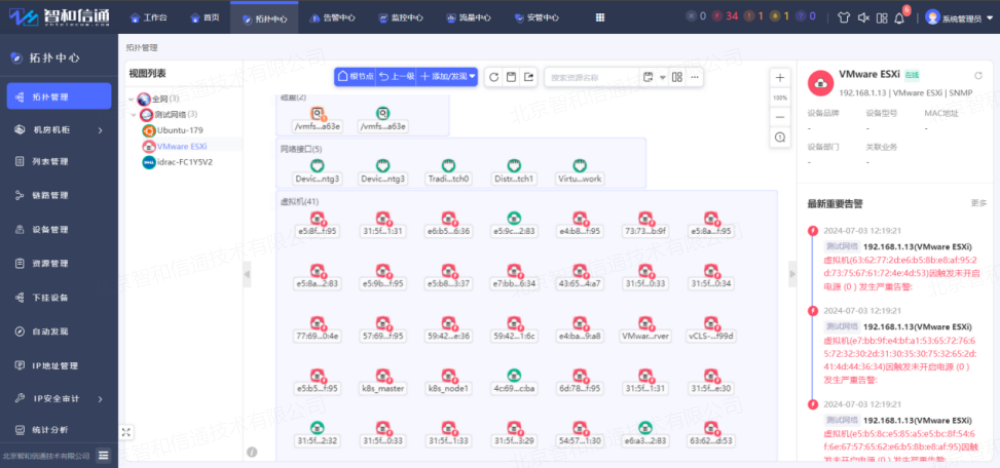
1.2.作為真實的主機(操作系統)監控
在此種方式下,根據虛擬機所安裝的操作系統來進行監控和控制,支持的監控指標和控制能力和對操作系統的監控相同。

監控指標包括ping、CPU使用率、內存使用率、磁盤使用率、網口流量帶寬、進程、服務、TCP連接數、端口等。控制能力包括一鍵開關機、重啟、進程管理、應用管理、容量管理等。
第2章 豐富的虛擬化監控范圍與指標
方案以實時監控和可視化呈現為核心,通過高精準的數據采集和智能數據分析處理機制,實現對虛擬化環境的全面監測和秒級故障預警。
2.1.虛擬化監控模型及指標擴展
資源監控是對虛擬化環境進行運維管理的關鍵,方案通過構建對VMware、Xenserver、Hyper-V、KVM、K8s(Kubernates)等關鍵指標的監控,幫助運維人員了解虛擬機的工作負載定位其性能瓶頸,并采取相應措施優化其性能。
同時采取用戶自定義擴展虛擬化類型、版本及其資源的方式,賦予用戶強大的適配能力,其他虛擬化也可通過靈活可配的模型庫進行擴展適配,最大可能地實現對不同品牌、不同版本虛擬化的管控;支持自定義虛擬化類型、虛擬化資源、故障監視器、性能監視器、TRAP監視器等。
2.2.常見虛擬機監測點和指標
本方案通過主動輪詢和日志解析的方式對虛擬機常見性能指標,如響應時間、CPU使用率、內存使用情況、磁盤IO性能以及網絡吞吐量等進行監控,同時除內置的常見指標外,其他資源和指標也可以通過模型庫不斷進行拓展。
|
資源監測點 |
監測指標 |
|
|
宿主機 |
基礎信息 |
品牌、名稱、版本等 |
|
Ping |
連接狀態、響應時長、服務成功率等 |
|
|
CPU |
CPU使用量、CPU使用率等 |
|
|
內存 |
內存使用率、活動內存、內存總量等 |
|
|
磁盤 |
磁盤使用率、磁盤總容量、磁盤讀IO、磁盤寫IO、磁盤讀速率、磁盤容量預測等 |
|
|
網口接口 |
接收/發送流量、接收/發送數據包數量、接收/發送丟包率、接收/發送速率等 |
|
|
虛擬機 |
虛擬機清單、運行的虛擬機個數、關閉的虛擬機個數、其他狀態的虛擬機個數等、CPU、內存、磁盤等 |
|
|
虛擬機 |
基礎信息 |
操作系統、電源狀態等 |
|
Ping |
連接狀態、響應時長等 |
|
|
CPU |
CPU使用量、CPU使用率、CPU個數等 |
|
|
內存 |
內存使用率、活動內存、內存總量等 |
|
|
磁盤 |
磁盤使用率、磁盤總容量、磁盤讀IO、磁盤寫IO、磁盤讀速率、磁盤容量預測等 |
|
|
網口接口 |
接收/發送流量、接收/發送數據包數量、接收/發送丟包率、接收/發送速率等 |
|
|
進程 |
狀態、ID、名稱、路徑、參數、系統進程數、運行進程數、空閑進程數、CPU占用率 內存占用率等 |
|
|
文件系統 |
狀態、總空間、剩余空間、文件類型、文件修改、文件數量等 |
第3章 虛擬化實時監控和預警管理
針對各類虛擬化場景建立全面的監控運維體系,深入監控其內部資源和整體運行狀態,提升虛擬化環境可靠性,保障業務系統穩定運行。
3.1.自動發現虛擬化設備
智和信通具備獨特的自動發現技術,在網絡可達范圍內,僅需輸入IP范圍即可自動發現網絡中的宿主機和虛擬機,識別虛擬機類型、版本、操作系統等信息,獲取宿主機和虛擬機內部資源,匹配故障與性能監視器,并自動發現虛擬機與其他設備的連接關系,生成可視化鏈路,通過可視拓撲動態展示虛擬化、鏈路的運行狀態。
3.2.自動生成網絡拓撲
方案以圖形拓撲的形式展現虛擬機在網絡中和其他設備間的拓撲關系,支持樹形結構和平面結構的聯動展示,也可以按片區、按地域、按層級等多種布局方式劃分網絡,在拓撲中以不同顏色圖標、光效展現虛擬化的實時狀態信息。
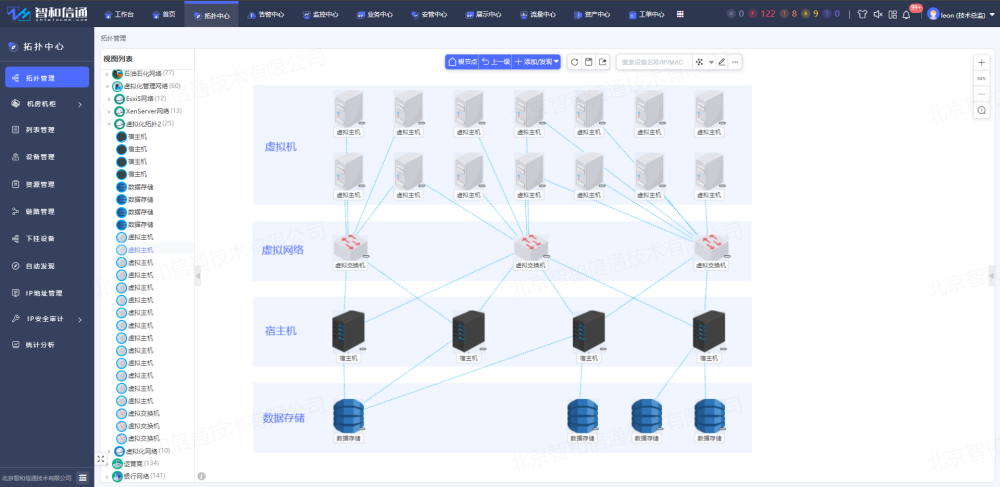
在拓撲圖的基礎上,進一步展示虛擬化的內部細節,以圖形方式展示虛擬機CPU使用率、內存使用情況、磁盤IO性能以及網絡吞吐量等關鍵指標,對虛擬機進行細化監控,實時告警,事前管理,降低故障發生率。
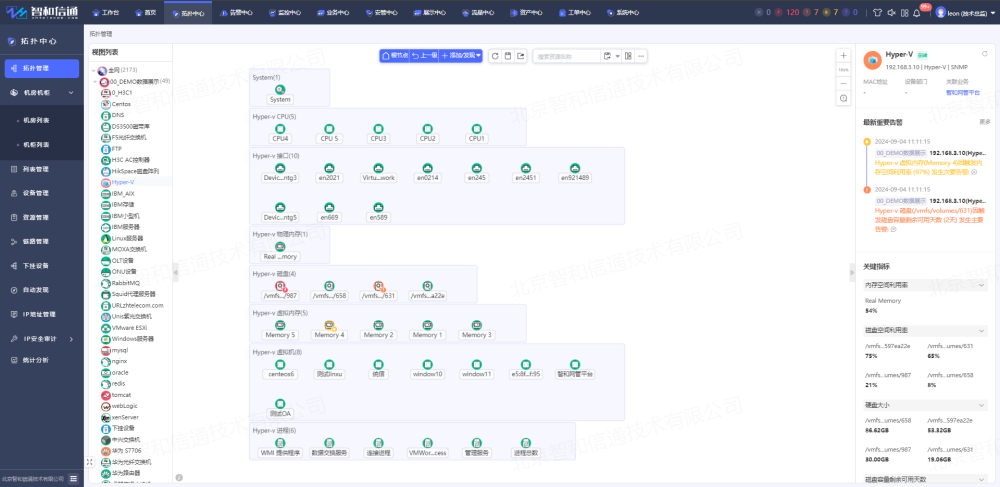
3.3.虛擬機性能態勢感知
全面采集虛擬機的各項性能指標,如CPU使用率、CPU就緒時間、內存使用量、內存頁交換率、磁盤讀寫請求、磁盤延遲時間與隊列長度、網絡接口的吞吐量、包傳輸錯誤以及丟棄包等,并按照時間范圍、資源類型、性能指標等多種維度,以圖形、表格等多種形式進行展示。
對實時、歷史性能數據進行統計分析,通過曲線圖、柱狀圖或表格等形象化地展示,按天、星期、月查看性能指標變化。運維人員能隨時把握虛擬化性能變化態勢,防患于未然。
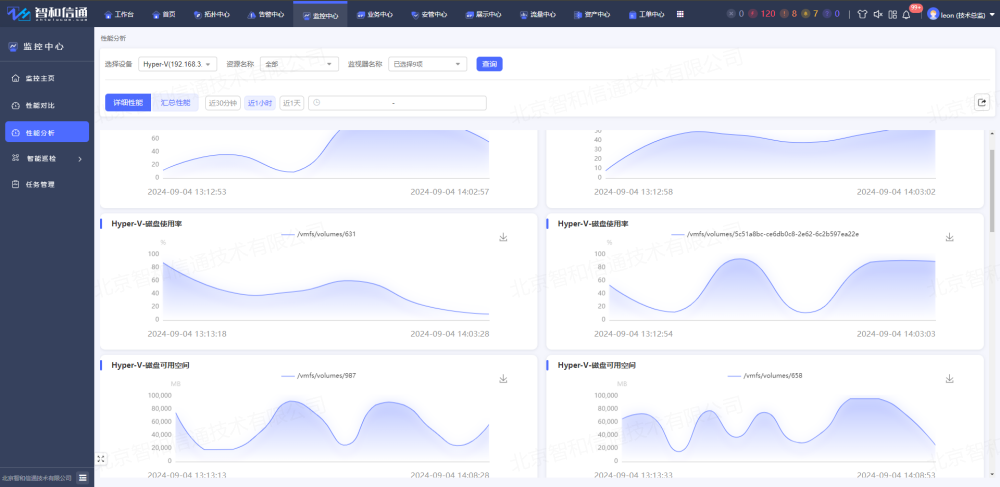
方案支持選擇多臺虛擬機進行同維度性能數據分析,提供可視化性能對比視圖,通過性能對比分析虛擬機性能變化趨勢。

3.4.虛擬機自動巡檢
可自定義虛擬機的巡檢策略,預設時間自動執行虛擬機巡檢,定期巡查虛擬機實時運行狀態,并向指定郵箱發送結果報告,可自行選擇要統計的虛擬機所屬網絡、虛擬機類型、虛擬機資源、虛擬機支撐的業務、虛擬機關聯的鏈路等范圍類型,生成巡檢報表。

3.5.日志與事件管理
接收虛擬機主動發送如非正常關機、意外重啟、內存管理錯誤、進程調度問題、服務無法正常啟動、應用程序異常終止、應用運行錯誤、登錄失敗、權限變更等事件與日志消息,集中存儲、解析處理后,將錯誤、告警、攻擊行為等異常信息及時地通知用戶。
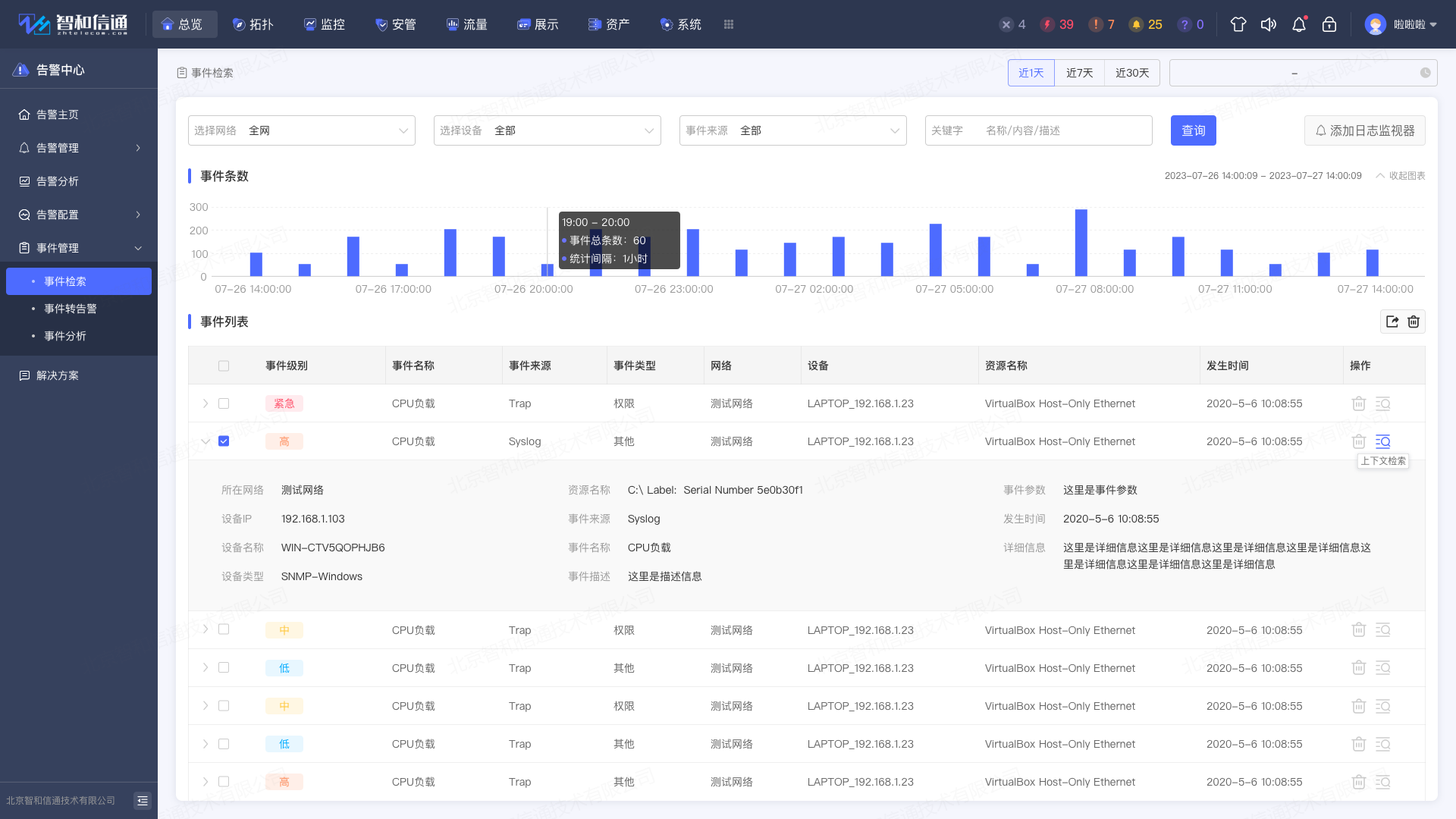
通過實時監控虛擬機的日志和事件信息,運維人員能夠準確得知虛擬機資源的使用情況、用戶行為、應用程序錯誤、系統故障等關鍵信息,在統一界面集中管理,及時發現和解決虛擬機故障、觀察系統運行情況、預測系統的使用情況,作為性能瓶頸和故障排查的重要依據,幫助運維人員更好地維護和管理虛擬化環境。
3.6.故障告警與智能收斂
搭載多種告警機制,自定義配置告警閾值,具備主動的故障監控功能,從眾多的事件和狀態中,系統地將零散的狀態信息總結成為當前狀態,并對異常狀態進行告警,第一時間獲取準確的告警信息,快速標示已執行操作的告警,迅速定位產生告警的虛擬機,提升告警處理效率,極大降低因虛擬化故障帶來的損失。
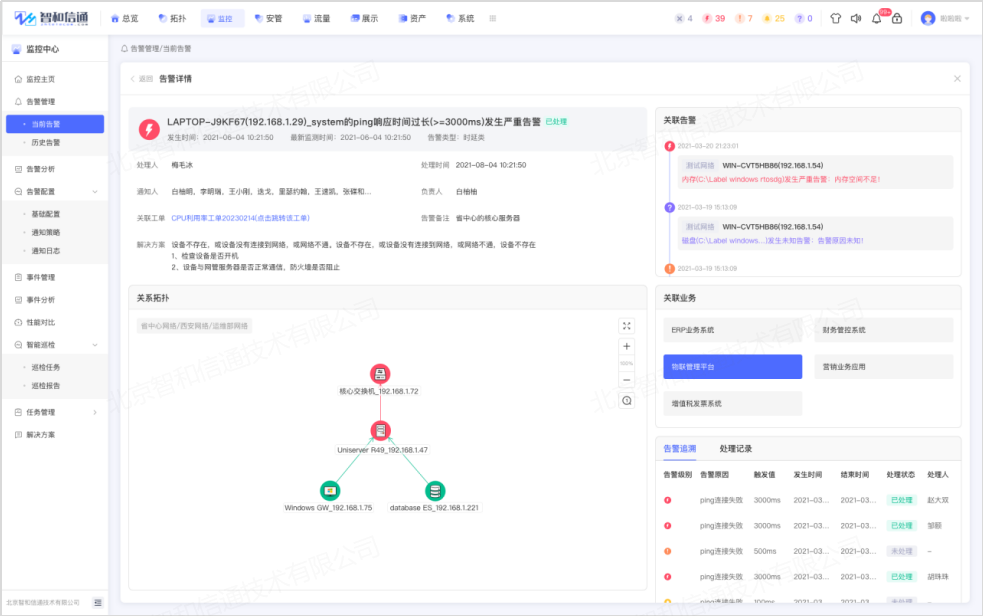
告警管理采用自動去重、風暴抑制、關聯聚合、維護期時間屏蔽、依賴屏蔽等多種智能告降噪機制,通過AI算法,對各類告警進行自動壓縮收斂,減少90%的無效告警,抑制告警風暴,有效避免誤報和漏報,直達故障根因。
第4章 虛擬機承載的業務狀態撥測
針對虛擬機所支撐的業務應用性能與用戶體驗進行檢測分析,無需安裝插件就可以為用戶提供開箱即用的企業級主動撥測式業務監測。以拓撲形式展示每個業務流程中的每臺相關設備,支持設備邏輯視圖和面板視圖,展示業務流程中涉及的所有的設備之間的鏈路關系,流程方向。

構建包含各業務整體流程的調用依賴關系圖譜,展示業務部署中網絡設備間多維度關系拓撲。對從業務的前臺受理到真正完成的整個業務流程所依賴的業務應用、虛擬化、操作系統等進行實時監控分析,呈現業務各節點的實時運行狀態,包括用戶體驗、節點可用性、節點負載等狀態信息,快速定位業務瓶頸根因,并可根據用戶自愈策略,觸發自動運維實現故障自愈。
第5章 統計報表和大屏展示
通過定義虛擬機相關數據報表的能力,實現虛擬機性能和狀態的靈活展現和統計分析,通過對比、TOPN等分析方式并結合報表排序規則、過濾規則等能力,周期自動生成報表,幫助用戶更好地了解虛擬機的各項負載情況和運行態勢,為優化資源配置和性能調整提供依據。
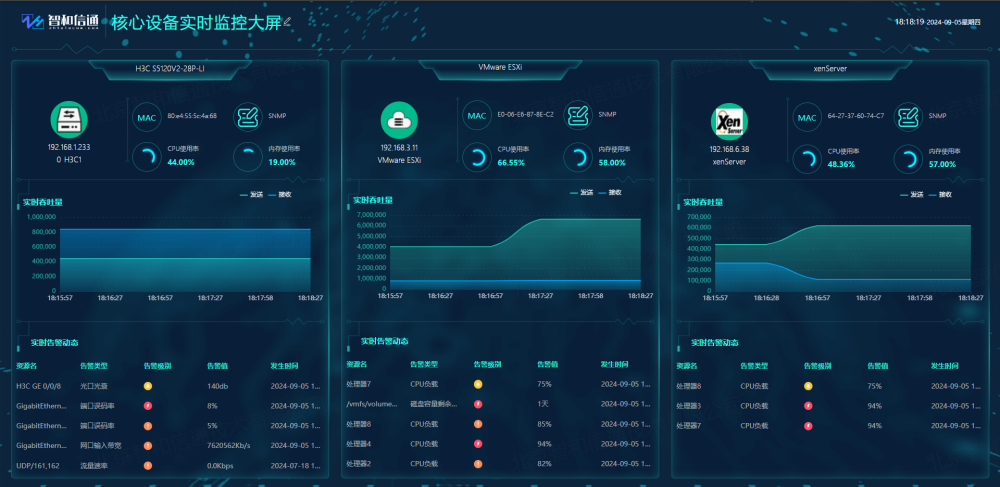
通過大屏展示核心運維數據態勢,細粒度可達網絡中虛擬機、虛擬機資源和鏈路。所有的網絡故障與性能瓶頸都一目了然地呈現,大大降低了管理成本,同時也提高了運維人員處理故障的能力,節省的故障處理時間,為運維人員管理網絡提供了可靠的保證。
第6章 虛擬機遠程控制和編排式配置
方案提供虛擬機遠程控制的能力,采用“監控+運維+控制”的方式,將不同系統、不同版本的虛擬機統一納入控制管理。通過智能算法對虛擬機的資源配置進行智能動態調整,當虛擬機出現性能瓶頸時,自動調優資源配置,優化虛擬機運行環境,當虛擬機發生故障時,自動啟動自愈機制,快速恢復虛擬機的正常運行。
6.1.虛擬機遠程配置執行
將周期性、重復性、規律性的大量日常虛擬機維護工作,如一鍵開關機、重啟、備份、鏡像、進程管理、應用管理、容量管理等運維工作,轉化為依托于平臺的自動執行工作流,實現對虛擬機的批量、定時自動化控制管理。
6.2.運維編排──以(VMware ESXi虛擬機磁盤擴容為例)
以虛擬機實時監控和日志、事件管理為基礎,通過多指標聚合檢測動態識別虛擬機運行狀態,根據真實運維場景和流量編排自動化運維作業流程,減少人工干預,提高運維效率。
下面以VMware ESXi虛擬機磁盤擴容為例,介紹如何通過智和網管平臺實現虛擬機運維編排。
效果要求:當虛擬機磁盤容量不足時,進行告警提示,運維人員可在核驗后一鍵進行虛擬機磁盤擴容。
第一步:將需要管理的虛擬機納入平臺進行監控,并設置虛擬機磁盤容量監視器,虛擬機磁盤空閑率小于10%時進行告警。
第二步:進入安管模塊的運維編排菜單,創建【VMware ESXi虛擬機磁盤擴容】策略。根據真實虛擬機磁盤擴容過程,通過進行策略節點拖拽編排的方式規劃擴容流程。
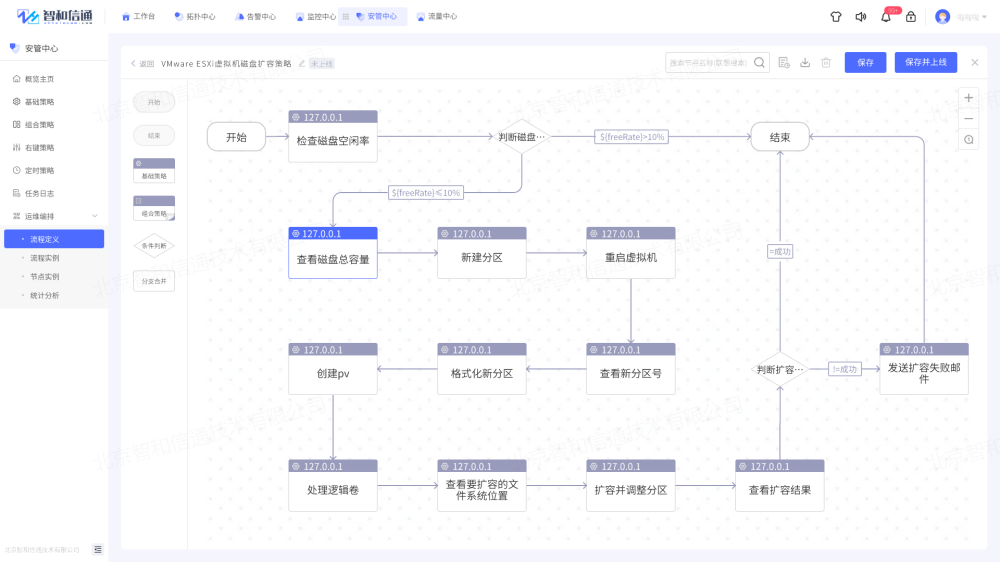
第三步:配置觸發方式。策略支持自動觸發和手動觸發兩種方式,根據用戶實際運維場景和工作流程,本策略適宜選擇手動觸發的形式進行虛擬機磁盤擴容。
編排流程配置完成后,當出現虛擬機磁盤空閑率告警時,用戶手動觸發策略對告警進行校驗,如空閑率低于預設閾值,則自動進行磁盤擴容。并在執行過程中,對每一步處置操作進行記錄形成日志,確保有跡可查。
第7章 應用價值
北京智和信通虛擬機監控運維方案,通過集中運維的功能,將分布在不同物理服務器上的虛擬化環境進行統一管理,在全量監控的同時,簡化運維流程、降低運維難度。運維人員可以在智和網管平臺的統一界面上,實時監控虛擬環境的運行狀態,并進行性能調優、故障排查等操作,大大提高工作效率。
通過方案的實施實現對虛擬化環境的深入監控,運維團隊能夠及時獲取虛擬機狀態、系統性能等關鍵信息,整體運維工作從傳統的被動響應模式轉變為積極主動的預防策略。一旦系統檢測到異常信息,便會立即觸發告警機制,并結合自動化運維能力,快速實現故障自愈。這種轉變不僅顯著減少了因虛擬機故障導致的宕機時間,也極大地降低了上層業務中斷的風險。
得益于方案強大的監控模型能力,不僅可以將虛擬機作為宿主機的資源進行管理,也可以將其作為獨立的服務器進行運維。這樣一來就給虛擬機的監控和控制提供了更多的可能,如自動化部署、磁盤擴容、備份恢復等等,進一步降低運維成本,釋放設備價值。
同時,通過對虛擬化環境的精確監管、全面覆蓋的功能、智能化的運維編排和強大的模型擴展能力,智和信通虛擬化監控運維方案正在成為越來越多用戶優化IT運維、提升業務連續性的選擇。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號