

1、相關(guān)描述
using index 和using where只要使用了索引我們基本都能經(jīng)常看到,而using index condition則是在mysql5.6后新加的新特性,我們先來看看mysql文檔對using index condition的描述

附上mysql文檔鏈接:https://dev.mysql.com/doc/refman/5.7/en/index-condition-pushdown-optimization.html
簡單來說,mysql開啟了ICP的話,可以減少存儲引擎訪問基表的次數(shù)
2、預(yù)備知識
了解這三個參數(shù),首先你需要知道的是,mysql查詢數(shù)據(jù)的流程,已經(jīng)索引的相關(guān)概念,這里的測試表如下
CREATE TABLE `test` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `bid` int unsigned NOT NULL DEFAULT '0', `status` int NOT NULL DEFAULT '1', `rid` int NOT NULL, `createTime` int unsigned NOT NULL, `updateTime` int unsigned NOT NULL, PRIMARY KEY (`id`), KEY `idx_bid_rid_status` (`bid`,`rid`,`status`) ) ENGINE=InnoDB AUTO_INCREMENT=10001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
該表有兩個索引,分別是id(主鍵索引)和idx_bid_rid_status(二級索引),假如說有個查詢是
select * from test where bid = 1;
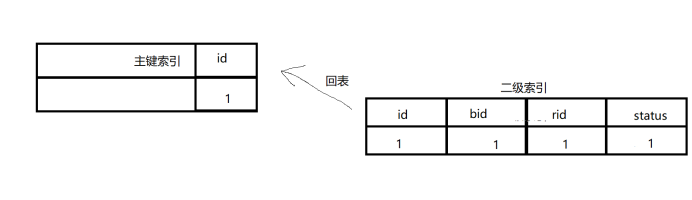
那么其查詢流程如下(只簡單的說明)
1、首先遍歷idx_bid_rid_status索引中的數(shù)據(jù),直到不滿足bid=10的數(shù)據(jù)后,回主鍵索引查詢數(shù)據(jù)(回表),注意這里的回表的概念,這個是等下解釋extra那三個值的重要概念
2、在主鍵索引中查找對應(yīng)的數(shù)據(jù),然后返回,如下圖所示
3、using index,using where,using index condition 分析
- using index:使用覆蓋索引,不需要回表就直接從二級索引返回數(shù)據(jù)
- using where: 需要在服務(wù)層過濾數(shù)據(jù)(mysql分為服務(wù)層和存儲引擎層)
- using index condition:需要回表查詢數(shù)據(jù),但是有部分?jǐn)?shù)據(jù)是在二級索引過濾后,再回表查詢數(shù)據(jù),減少了回表查詢的數(shù)據(jù)行數(shù)
用上面的測試表進(jìn)行驗證說明
創(chuàng)建存儲過程,插入1w條數(shù)據(jù),代碼如下
DROP PROCEDURE IF EXISTS create_service_data$$ create procedure create_service_data(size INT) begin START TRANSACTION; SET @id=0; WHILE @id<size DO SET @bid=@id+1; SET @status = FLOOR(RAND() * 100000); SET @rid = FLOOR(RAND() * 100000); SET @createTime = FLOOR(RAND() * 100000); SET @updateTime = 90000; INSERT INTO test.test(id, bid,status,rid,createTime,updateTime)VALUES(null,@bid,@status,@rid,@createTime,@updateTime); SET @id=@id+1; end while ; COMMIT; end$$ delimiter ;
1、using index

bid,status的數(shù)據(jù)在idx_bid_rid_status中存在(不是*查找所有數(shù)據(jù)),所以能從idx_bid_rid_status直接返回
2、using where

雖然使用了idx_bid_rid_status索引,但是createTime不存在在idx_bid_rid_status索引中,所以回表后才在服務(wù)層過濾createTime
3、using index condition

那么,重點來了,根據(jù)最左前綴原則,idx_bid_rid_status的索引有效范圍只到了bid這個數(shù)據(jù),之后就需要會主鍵索引進(jìn)行過濾,而這個地方,就是icp優(yōu)化的地方,通俗點來說,就是idx_bid_rid_status本來就有status這個數(shù)據(jù),為啥我還非要會主鍵去過濾這個數(shù)據(jù)呢?完全是可以在這個索引上過濾status這個數(shù)據(jù)的,這就是icp,目的就是近可能減少回表查詢的數(shù)據(jù)量。舉個例子,bid=10的數(shù)據(jù)有100條,其中status > 100的數(shù)據(jù)有20條,那么使用icp之后,我只需要在主鍵索引查找20條數(shù)據(jù)返回即可,不需要查100條數(shù)據(jù)
有趣的是,mysql中extra不僅僅值單一輸出一種,有時候會多種混合輸出,如下所示

這個其實就是在二級索引過濾后(使用了icp優(yōu)化),還需要回表在服務(wù)層進(jìn)行過濾數(shù)據(jù)(createTime)再返回
那么,看到這篇博客的小伙伴們可以用以上思路去分析分析下面的這個輸出,歡迎在評論區(qū)中留下你們的分析

Ps 不同版本的mysql explain輸出的內(nèi)容會有差異,本人用的版本是8.0.26
