
一張圖讀懂阿里云數(shù)據(jù)庫架構(gòu)與選型
背景
阿里云RDS已經(jīng)發(fā)展超過十年,在演進的過程中,其架構(gòu)和規(guī)格已經(jīng)變得比較復(fù)雜,本文嘗試通過一張架構(gòu)圖,較為完整的概況RDS所支持的主要的架構(gòu)類型、規(guī)格,幫助開發(fā)者從高可用、成本、可靠性等角度選擇適合自己業(yè)務(wù)的RDS類型與規(guī)格。
具體的信息可以看:一張圖讀懂阿里云數(shù)據(jù)庫架構(gòu)與選型,或則關(guān)注公眾號  ,能夠第一時間了解行業(yè)動態(tài)。
,能夠第一時間了解行業(yè)動態(tài)。
01 阿里云RDS的架構(gòu)與規(guī)格大圖
下圖從高可用類型、數(shù)據(jù)可靠性、資源復(fù)用率、規(guī)格大小、規(guī)格代碼等角度,較為完整的概況了當前RDS主要的架構(gòu)與規(guī)格:
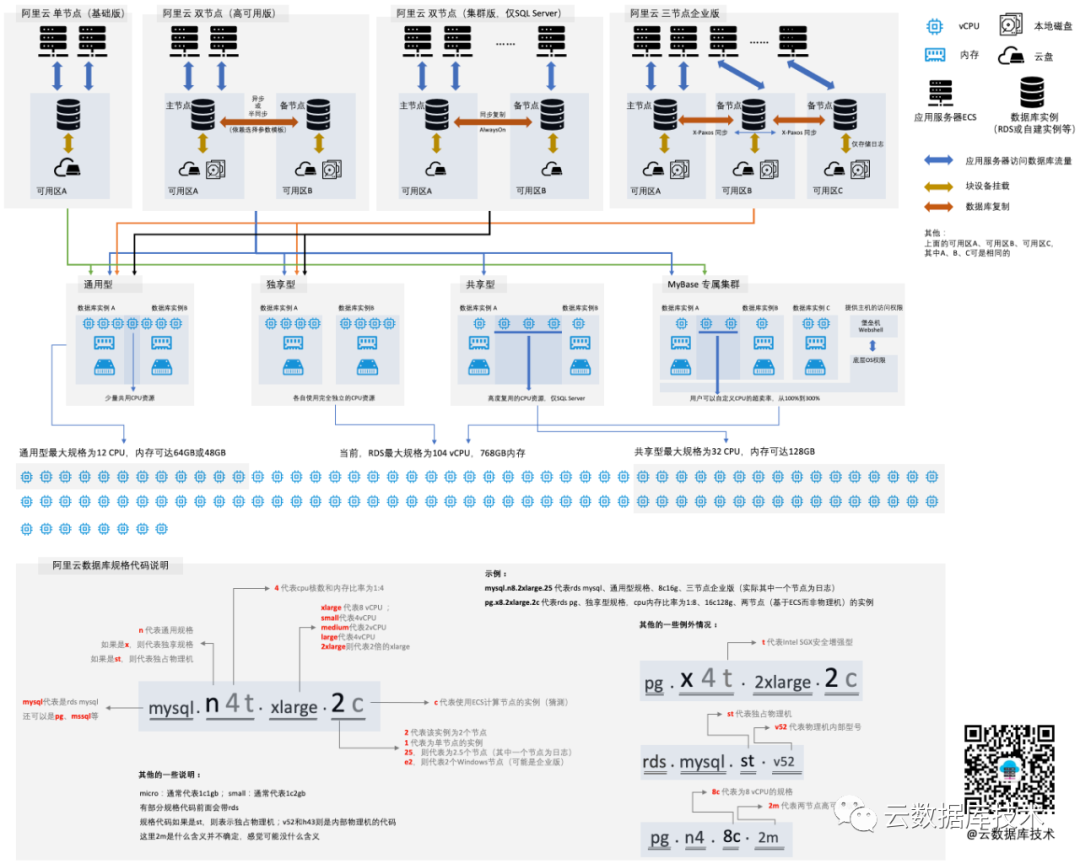
從高可用區(qū)架構(gòu)上,分為單節(jié)點(基礎(chǔ)版)、雙節(jié)點(高可用版)以及三節(jié)點企業(yè)版、集群版(僅SQL Server AlwaysOn)。從資源共享與隔離上,則分為通用型、獨享型、共享型和獨占物理機(可以理解為是特殊的獨享型)。從磁盤使用上的不同,則分為云盤版和本地盤版。
當前,RDS最大規(guī)格為104核CPU,768GB內(nèi)存。其中通用型,最大為12核CPU;共享型最大為32核CPU。
02 主要的架構(gòu)類型
數(shù)據(jù)庫通常是企業(yè)業(yè)務(wù)架構(gòu)中的核心組件,數(shù)據(jù)庫的可用性與業(yè)務(wù)可用性直接相關(guān)。所以,高可用是云數(shù)據(jù)庫架構(gòu)選型第一個需要關(guān)注的內(nèi)容。
從高可用角度,阿里云數(shù)據(jù)庫提供了基礎(chǔ)版(即單節(jié)點)、雙節(jié)點高可用版、三節(jié)點企業(yè)版。不同的版本,則是在成本、可用性、數(shù)據(jù)可靠性之間的平衡:
-
單節(jié)點通過簡單的架構(gòu),以最低的成本提供了基本可用的云數(shù)據(jù)庫服務(wù)
-
雙節(jié)點高可用版則是適合絕大多數(shù)業(yè)務(wù)場景的模式,兩個節(jié)點分布于一個地區(qū)的兩個可用區(qū),故障時,切換速度較快,數(shù)據(jù)雙副本,可靠性也比較高
-
三節(jié)點企業(yè)版,則通過X-Paxos實現(xiàn)底層數(shù)據(jù)一致,并以三副本(兩份數(shù)據(jù)+一份日志)保障數(shù)據(jù)可靠性
2.1 基礎(chǔ)版(即單節(jié)點版本)
阿里云基礎(chǔ)版使用阿里云云盤作為數(shù)據(jù)庫存儲,掛載在數(shù)據(jù)庫的計算節(jié)點上,實現(xiàn)了存儲與計算的分離。這使得,計算節(jié)點出現(xiàn)故障的時候,重新使用一個新的計算節(jié)點,再重新掛載原來的數(shù)據(jù)庫存儲,即可啟動數(shù)據(jù)庫,恢復(fù)出現(xiàn)故障的數(shù)據(jù)庫。所以,在計算節(jié)點發(fā)生故障的時候,RPO通常小于1分鐘,RTO則為5分鐘~一小時。當整個可用區(qū)發(fā)生故障的時候,RPO和RTO的值則依賴數(shù)據(jù)庫備份的頻率情況。
2.2 高可用版
兩節(jié)點高可用是用戶使用最多的版本,也是數(shù)據(jù)庫最為常見的架構(gòu)。數(shù)據(jù)庫有主備兩個節(jié)點組成,通過數(shù)據(jù)庫層的邏輯日志進行復(fù)制。相比單節(jié)點,無論是在數(shù)據(jù)可靠性、服務(wù)的可用性都有非常大的提升。由于主備節(jié)點都在同一個大region,日志延遲通常都非常小,所以發(fā)生單節(jié)點故障時,高可用版的數(shù)據(jù)可靠性通常是比較高的。注意到,AWS對應(yīng)的雙節(jié)點版本的RPO是零,那么阿里云數(shù)據(jù)庫怎樣呢?
具體的,對阿里云RDS MySQL,阿里云的兩節(jié)點高可用,根據(jù)所選擇的參數(shù)模板分為如下三類:
-
高性能:sync_binlog=1000, innodb_flush_log_at_trx_commit=2, async
-
異步模式:sync_binlog=1, innodb_flush_log_at_trx_commit=1, async
-
默認:sync_binlog=1, innodb_flush_log_at_trx_commit=1, semi-sync
其中,“高性能”版本和“異步”版本,都是異步復(fù)制,在發(fā)生主節(jié)點故障時,因為復(fù)制為異步的,可能會有少部分的事務(wù)日志沒有傳到備節(jié)點,則可能會丟失少部分事務(wù)。也就是說,這兩個版本為了實現(xiàn)更好的性能,在數(shù)據(jù)庫的RPO上做了小的讓步。“默認”版本,使用了半同步復(fù)制,通常,數(shù)據(jù)可靠性會更高。但因為半同步可能會有退化的場景,所以,該模式下數(shù)據(jù)復(fù)制還是在極端的情況下,還會有數(shù)據(jù)丟失的可能性。
那么,既然“異步”模式和“高性能”都有數(shù)據(jù)丟失的風(fēng)險,他們的區(qū)別是什么什么呢?簡單的概括,“異步”產(chǎn)生微小數(shù)據(jù)丟失的可能性更小。因為,主備節(jié)點通過設(shè)置sync_binlog=1, innodb_flush_log_at_trx_commit=1,可以最大可能性的保障,主節(jié)點的數(shù)據(jù)可靠性。
事實上,高可用版本是可以滿足絕大多數(shù)業(yè)務(wù)場景的需要的,一方面同一個可用區(qū)內(nèi)數(shù)據(jù)傳輸延遲非常小,日志傳輸通常都非常通暢,即便主節(jié)點發(fā)生故障,實際的情況中,通常不會出現(xiàn)日志延遲。另外,主節(jié)點失敗后,通常可以通過重啟等方式恢復(fù),云廠商的硬件都有著較為標準的硬件過保淘汰的機制,硬件完全不可用的情況也并不多。另外,底層磁盤會通過硬RAID或者軟RAID的方式,保障磁盤數(shù)據(jù)存儲的可靠性,數(shù)據(jù)即便是在一臺機器上,也會保存在兩塊盤上。
兩節(jié)點高可用版本在某些特殊場景下,數(shù)據(jù)還是存在一些不可用風(fēng)險,例如,當其中一個節(jié)點發(fā)生故障,而本地數(shù)據(jù)量又非常大時,需要重新在一臺新的機器上搭建備節(jié)點時,因為數(shù)據(jù)量較大,重建時間通常會比較長,而這時候,主節(jié)點則會一直單節(jié)點運行,如果不幸主節(jié)點再出現(xiàn)故障,則會出現(xiàn)不可用或者數(shù)據(jù)丟失。如果,對數(shù)據(jù)的安全性有更高的要求,則可以考慮選擇“三節(jié)點企業(yè)版”。
2.3 三節(jié)點企業(yè)版
當前僅RDS MySQL有該版本。三節(jié)點企業(yè)版使用了基于X-Paxos[^4]的一致性協(xié)議實現(xiàn)了數(shù)據(jù)的同步復(fù)制,適用于數(shù)據(jù)安全可靠性要求非常高的場景,例如金融交易數(shù)據(jù)等。三節(jié)點中,有一個節(jié)點僅存儲日志,以此實現(xiàn)接近于兩個節(jié)點的成本與價格,實現(xiàn)更高的數(shù)據(jù)安全與可靠性。
三節(jié)點企業(yè)版在創(chuàng)建的時候,可以選擇分布在1~3個可用區(qū)。如果需要跨可用區(qū)的容災(zāi),則可以讓三個副本分布于三個可用區(qū),如果需要更高的性能,則可以讓三個副本都在同一個可用區(qū)。
2.4 關(guān)于MySQL的參數(shù)sync_binlog, innodb_flush_log_at_trx_commit
在阿里云RDS的高可用參數(shù)模板選擇中,不同的參數(shù)模板,最主要的區(qū)別就是這兩個參數(shù)的不同配置。這是MySQL和InnoDB在數(shù)據(jù)安全性上最重要的兩個參數(shù)。雙1設(shè)置(sync_binlog=1, innodb_flush_log_at_trx_commit=1)是數(shù)據(jù)安全性最高的配置。
數(shù)據(jù)庫是日志先行(WAL)的系統(tǒng),通過事務(wù)日志的持久化存儲來保障數(shù)據(jù)的持久化。在一般的Linux系統(tǒng)中,數(shù)據(jù)寫入磁盤的持久化需要通過系統(tǒng)調(diào)用fsync來完成,相對于內(nèi)存操作,fsync需要將數(shù)據(jù)寫入磁盤,這是一個非常“耗時”的操作。而上面這兩個參數(shù)就是控制MySQL的二進制日志和InnoDB的日志何時調(diào)用fsync完成數(shù)據(jù)的持久化。所以,這兩個參數(shù)的配置很大程度上反應(yīng)了MySQL在性能與安全性方面的平衡。
其中,sync_binlog代表了,MySQL層的日志(即二進制日志)的刷寫磁盤的頻率,如果設(shè)置成1,則代表每個二進制日志寫入文件后,都會進行強制刷盤。如果設(shè)置成0,則代表MySQL自己不會強制要求操作系統(tǒng)將緩存刷入磁盤,而由操作系統(tǒng)自己來控制這個行為。如果設(shè)置成其他的數(shù)字N,則代表完成N個二進制日志寫入后,則進行一次刷寫數(shù)據(jù)的系統(tǒng)調(diào)用。
innodb_flush_log_at_trx_commit則控制了InnoDB的日志刷寫磁盤的頻率。取值可以是0,1,2。
-
其中1最嚴格,代表每個事務(wù)完成后都會刷寫到磁盤中。
-
如果該參數(shù)設(shè)置成0,那么在事務(wù)完成后,InnoDB并不會立刻調(diào)用文件系統(tǒng)寫入操作也不會調(diào)用磁盤刷寫操作,而是每隔1秒才調(diào)用一次文件系統(tǒng)寫入操作和磁盤刷寫操作。那么,在操作系統(tǒng)崩潰的情況下,可能會丟失1秒的事務(wù)。
-
如果該參數(shù)設(shè)置成2,那么,每次InnoDB事務(wù)完成的時候,都會通過系統(tǒng)調(diào)用write將數(shù)據(jù)寫入文件(這時候可能只是寫入到了文件系統(tǒng)的緩存,而不是磁盤),但是每隔1秒才會進行一次刷寫到磁盤的操作。那么,在操作系統(tǒng)崩潰的情況下,可能會丟失1秒的事務(wù)。相比設(shè)置成0,該設(shè)置會讓InnoDB更加頻繁的調(diào)用文件系統(tǒng)寫入操作,數(shù)據(jù)的安全性要比設(shè)置成0高一些。
我們可以通過下圖來理解這兩個參數(shù)的含義,以及在操作系統(tǒng)中對應(yīng)的“寫入文件系統(tǒng)”與“刷寫數(shù)據(jù)到磁盤”的含義。首先,在數(shù)據(jù)庫的事務(wù)處理過程中,會產(chǎn)生binlog日志和InnoDB的redo日志,這兩個日志分別在MySQL Server層面和InnoDB引擎層面保障了事務(wù)的持久性。在事務(wù)提交的時候,數(shù)據(jù)庫會先將數(shù)據(jù)“寫入文件系統(tǒng)”,通常文件系統(tǒng)會先將數(shù)據(jù)寫入文件緩存中,該緩存是在內(nèi)存中,這樣就意味著,如果發(fā)生操作系統(tǒng)級別的宕機,那么寫入的日志就會丟失。為了避免這種數(shù)據(jù)丟失,數(shù)據(jù)庫接著會通過系統(tǒng)調(diào)用,“刷寫數(shù)據(jù)到磁盤”中。此時,即可以認為數(shù)據(jù)已經(jīng)持久化到磁盤中。
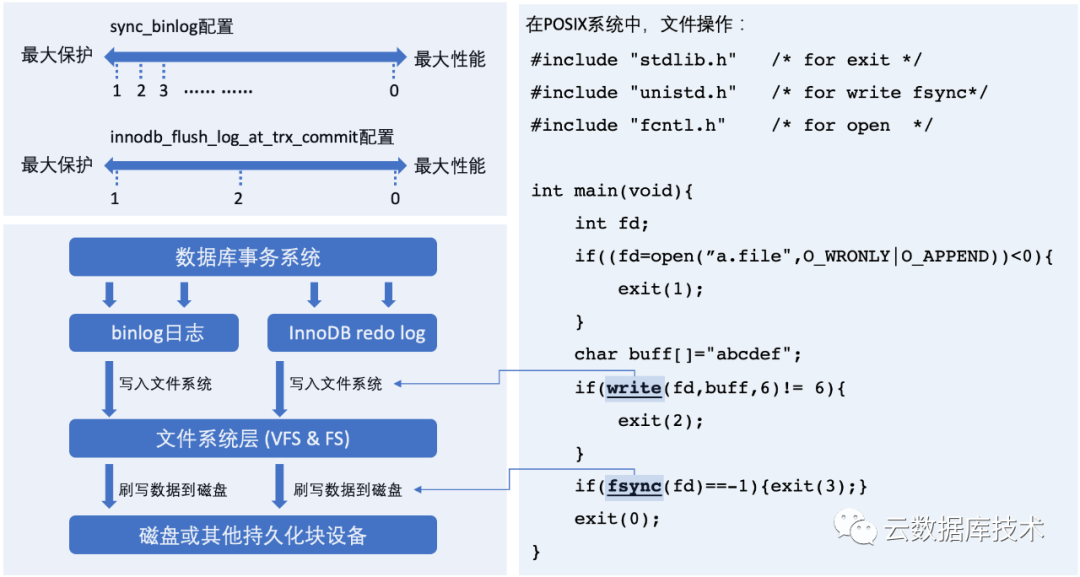
這時,再回頭看看阿里云RDS的參數(shù)模板。在高性能模板中,”sync_binlog=1000, innodb_flush_log_at_trx_commit=2, async”,代表了在寫入1000個binlog日志后再進行刷寫數(shù)據(jù)到磁盤的操作,InnoDB的日志則都會先寫入文件系統(tǒng),然后每隔一秒進行一次刷寫數(shù)據(jù)到磁盤。在“默認模式下,“默認:sync_binlog=1, innodb_flush_log_at_trx_commit=1, semi-sync”,則是最嚴格的日志模式,也就是會保障每個事務(wù)日志安全的刷寫到磁盤。
日志的刷寫模式對性能有非常大的影響。如果不去關(guān)注這些參數(shù),就直接去測試不同云廠商的性能,則會發(fā)現(xiàn),云廠商之間的RDS有著非常大的性能差異。通常,這些差異并不是廠商之前的技術(shù)能力導(dǎo)致的,更多的是由于他們在對于安全性和性能的平衡時,選擇的不同的平衡點。
03資源復(fù)用與規(guī)格
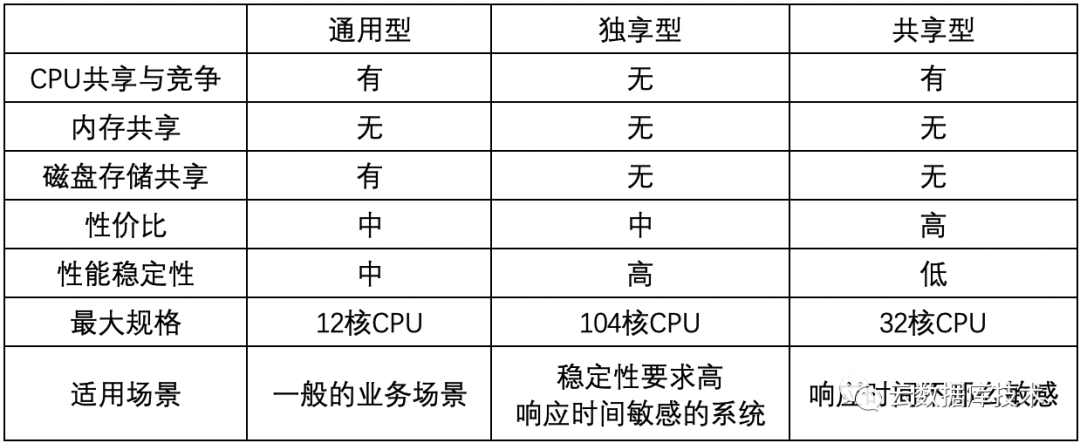
從資源共享與隔離上,RDS又分為:通用型、獨享型和共享型。具體的:
-
“通用型”適合一般的業(yè)務(wù)使用場景,但有一定的CPU共享率,也就說是,有一定的概率實例的資源可能會被其他實例爭搶而導(dǎo)致性能的波動 。
-
“獨享型”則使用完全獨享的CPU的資源和內(nèi)存資源,不會共享其他人的資源,自己的資源也不會被其他人共享,所以,有更穩(wěn)定的性能。
-
“共享型”則與通用型類似CPU資源會被共享,并且共享率更高,所以性價比更高,同時受到資源爭搶的影響的可能性也更大,當前僅SQL Server支持。
除了,上述主要規(guī)格類型之外,阿里云還提供了“獨占物理機”規(guī)格,選擇該規(guī)格的用戶可以完全的獨占一臺物理機的資源:
04數(shù)據(jù)庫專屬集群MyBase
專屬集群MyBase是阿里云推出的一種特殊的形態(tài)。可以理解為,是一種全托管RDS與自建數(shù)據(jù)庫的中間形態(tài)。在全托管的RDS基礎(chǔ)上,提供了兩個重大的能力:
-
允許用戶登錄數(shù)據(jù)庫所在的主機
-
允許用戶配置數(shù)據(jù)庫實例CPU的“超配比”
當然,要求是用戶一次購買一個非常大的、可以容納多個RDS實例的“大集群”,專屬集群則提供了以上兩個能力,以及RDS其他的基本能力,包括安裝配置、監(jiān)控管理、備份恢復(fù)等一系列生命周期管理能力。
使用這種規(guī)格,用戶具備更大的自由度。一方面可以登錄主機,觀測主機與數(shù)據(jù)庫的狀態(tài),或者將自己原有的監(jiān)控體系部署到專屬集群中。另一方面,用戶可以根據(jù)自己的業(yè)務(wù)特點,控制集群內(nèi)的CPU資源的超配比。對于核心的應(yīng)用,則使用資源完全不超配的集群;對于響應(yīng)時間沒有那么敏感的應(yīng)用,例如開發(fā)測試環(huán)境,則可以配置高達300%的CPU超配比,以此大大降低數(shù)據(jù)庫的成本。
05關(guān)于本地盤與云盤版
阿里云的主要版本都會支持本地SSD和高性能云盤。他們的差異在于計算節(jié)點與磁盤存儲是否在同一臺物理機器上,對于使用高性能云盤的規(guī)格,通常是通過掛載一個同地區(qū)的網(wǎng)絡(luò)塊設(shè)備作為存儲。
對于阿里云廠商來說,未來主推的將是云盤版。原因是云盤相對于本地盤來說,有很多的優(yōu)勢:
-
統(tǒng)一使用云盤版,讓云廠商的供應(yīng)鏈管理變得簡單。如果使用本地盤版本,意味著數(shù)據(jù)庫機型定制性會增強,供應(yīng)鏈的困難會增加產(chǎn)品的成本,最終影響價格。另外,簡單的供應(yīng)鏈也會讓產(chǎn)品的部署更加標準化,更加敏捷地實現(xiàn)多環(huán)境多區(qū)域的部署。
-
使用云盤版,也可以理解為是“存儲計算分離”的架構(gòu),那么如果計算節(jié)點故障,則可以快速通過使用一臺新的計算節(jié)點并掛載云盤,而實現(xiàn)高可用。這種方式有著非常好的通用性,無論是哪種數(shù)據(jù)庫都可以使用,而無需考慮數(shù)據(jù)庫種類之間的差異。無論是MySQL還是PostgreSQL、Oracle都可以使用這種方式實現(xiàn)高可用。
-
云盤版本身提供了一定的高可用與高可靠能力。云盤本身數(shù)據(jù)可以通過RAID或者EC算法實現(xiàn)數(shù)據(jù)的冗余與高可用,并且可以將數(shù)據(jù)分片到不同的磁盤與機器上,整體的吞吐會更高。
-
云盤版本身是分布式的,可以提供更高的吞吐,通常還可以提供更大的存儲空間。例如,各個云廠商的云盤存儲都可以提供12TB或32TB的存儲空間,基本上可以滿足各類業(yè)務(wù)需要。
當然,使用云盤也有一些缺點,例如,相比本地盤,云盤的訪問延遲更大,需要通過網(wǎng)絡(luò)訪問,而對于數(shù)據(jù)庫這類IO極其敏感的應(yīng)用,本地磁盤的IO性能的穩(wěn)定性通常會更強一些
06關(guān)于通用型與獨享型的性能
獨享型規(guī)格的資源完全由用戶獨立使用,價格通常更貴。而通用型則因為部分資源的共享,會導(dǎo)致性能在某些不可預(yù)期的情況下發(fā)生一些不可預(yù)期的波動。而獨享型規(guī)格也更貴,更多的企業(yè)級場景,也會推薦使用獨享型,會有很多人會認為獨享型的性能也更高。而實際上,如果做過實際測試就會發(fā)現(xiàn),一般來說,相同的規(guī)格,通用型的性能與吞吐通常都會更高。
所以,實際情況是,通用型的價格更加便宜,性能也會更好。缺點在于,可能會出現(xiàn)一些不可預(yù)期的性能波動,而因為大多數(shù)數(shù)據(jù)庫應(yīng)用都是IO密集型的,所以,實際場景中,這種不可預(yù)期的波動并不是非常多。
所以,這兩個版本的選擇,需要用戶根據(jù)自己的實際情況去選擇。如果,可以接受偶爾的性能波動,則一定是建議選擇通用型的;如果應(yīng)用對數(shù)據(jù)庫的響應(yīng)時間極其敏感,則應(yīng)該選擇獨享型。另外,當前,通用型最大規(guī)格僅支持12核CPU,所以對于壓力非常大系統(tǒng),則只能選擇獨享型。
07關(guān)于超配比
對于在線數(shù)據(jù)庫應(yīng)用來說,通常是IO或者吞吐密集型的。CPU資源在很多時候,會有一定的冗余。對于云廠商來說,則可以通過超配CPU的售賣率來降低成本,同時也降低數(shù)據(jù)庫資源的價格,這就是通用型背后重要的邏輯。
而一般來說,可以超配的通常只有CPU資源。磁盤資源雖然可以超配,但是實際使用中,是不能重合的,當用戶的磁盤占用增到購買值的時候,資源則不可以共享,這與CPU的超配并不相同。內(nèi)存資源則更加是獨享的,Buffer Pool的通常是滿的,無論這些內(nèi)存頁是否被實際使用,數(shù)據(jù)庫總是會盡力在內(nèi)存中存儲盡可能多的數(shù)據(jù)。
MyBase提供的一個重要配置項,就是可以用戶自定義底層資源的超配比,該比率取值從100%~300%。也就是說,一個32核CPU的資源,最多可以分配給12個8核CPU的實例使用,看起來是96=12*8個CPU被使用,即實現(xiàn)了300%的超配比。
參考文檔
-
阿里云RDS for MySQL 發(fā)布三節(jié)點企業(yè)版 @阿里云開發(fā)者社區(qū)
-
RDS 使用參數(shù)模板 @阿里云數(shù)據(jù)庫文檔
-
sync_binlog @MySQL Documentation
-
innodb_flush_log_at_trx_commit @MySQL Documentation
-
實例規(guī)格族 @ 阿里云數(shù)據(jù)庫文檔
-
高清無水印大圖下載:
https://cloud-database-tech.github.io/images/aliyun-instance-type-code-without-qr-code.png
超配比有時候也會被稱為超賣率。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號