
教材第一章讀書筆記
教材第一章讀書筆記
by 20201321 周慧琳
學習目標
-
第一章:引言
第一章的引言部分包涵Unix的歷史、Linux的開發和各種版本(沒有提及centOS和openeuler,我們可以自己補充學習),還列出了適用Linux的各種虛擬機。我選用的是VMware因為我覺得它比vitrualbox功能更清晰好用。本章還介紹了文件系統組織、文件系統,和一些常用的命令。我認為這些都需要自己通過實踐去掌握。
-
第二章:編程背景
第二章是關于系統編程需要的背景信息,介紹了vim、gedit、emacs文本編輯器。我認為有必要掌握一種,尤其是vim。另外需要了解程序開發的步驟,包括GCC、靜態動態鏈接、二進制可執行文件的格式和內容、程序執行和終止。
這章還需要我們認識許多基礎知識,包括:函數調用時堆棧的使用,C語言常見錯誤(很多和指針誤用有關),各類數據結構(鏈表、二叉樹等)、還有GNU make工具和Makefile的編寫方法。
此章有一個實踐任務,即設計一個文件系統樹,支持mkdir、rmdir、creat、rm、cd、pwd、ls操作。
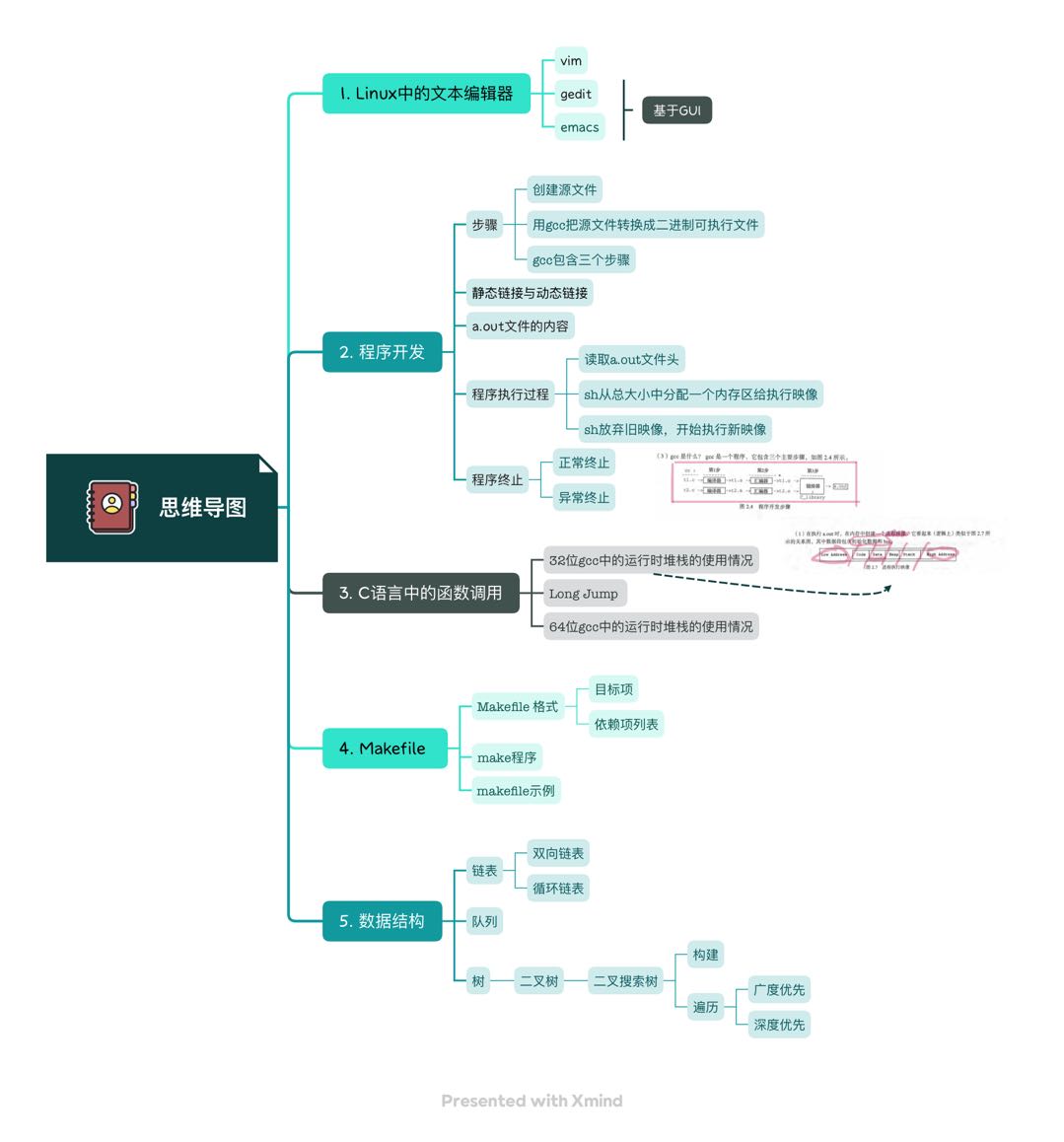
知識圖譜的歸納
對于第二章繁瑣的知識點,利用xmind工具制作了一個知識圖譜來強化知識理解
學習收獲和心得
開始學這本書我感受最大的是這本書給了我們一個完整的學習架構和學習建議,但是要真正掌握其中的一個知識點還是需要實踐。
無論是GNU make工具以及對應的makefile編寫、vim編譯器的實際使用等等,這些只看書是非常抽象的。有些時候,博客或者視頻確實會比書更通俗易懂些。盡管我必須承認這本書提供的知識的嚴謹性是博客和視頻無法比擬的。
以下是我重點學習的內容:
-
Linux文件系統

-
vim使用
【最強Vim新手指南,手把手教你打造只屬于自己的代碼編輯器!-嗶哩嗶哩】 https://b23.tv/L73Zptt
這本書對于vim的介紹比較少,主要是關于emac的,所以我在網上找到了這個視頻。
他首先介紹了vim的定位、設計理念,然后介紹了他自己的vim快捷鍵配置,現在很多ide都有vim模式插件
在簡潔的vim模式下編輯速度大幅提升,vim在現在更多地已經不作為一種具體工具,而是一種習慣模式,實現不用鼠標只用鍵盤編輯代碼。
-
make工具與Makefile的編寫
參考https://blog.csdn.net/weixin_38391755/article/details/80380786進行學習Windows的IDE都為我們做了這一塊的工作,所以很多時候我們都沒有重視這塊知識。但在Unix下的軟件編譯,你就不能不自己寫makefile了。之前我在ide里面也會發現Makefile文件,但是我并不知道這是干什么的。
我看了這本書里面的描述,又去查找了一下相關的博客,現在make和makefile讓我想到了我在“計算機組成原理”里老師讓我們用Verilog語言編寫一個cpu中的寄存器文件,這個項目包括8位寄存器文件、譯碼器文件和選擇器文件,這三個文件需要按一定的順序編譯和傳遞參數。我們需要寫一個編譯文件實例化、指明編譯順序和聯系各個文件的參數。
而Makefile里面的依賴關系,編譯規則,跟這些是底層邏輯差不多的。
makefile關系到了整個工程的編譯規則。一個工程中的源文件不計數,其按類型、功能、模塊分別放在若干個目錄中,makefile定義了一系列的規則來指定,哪些文件需要先編譯,哪些文件需要后編譯,哪些文件需要重新編譯,甚至于進行更復雜的功能操作,因為makefile就像一個Shell腳本一樣,其中也可以執行操作系統的命令。
makefile帶來的好處就是——“自動化編譯”,一旦寫好,只需要一個make命令,整個工程完全自動編譯,極大的提高了軟件開發的效率。make是一個命令工具,是一個解釋makefile中指令的命令工具,一般來說,大多數的IDE都有這個命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可見,makefile都成為了一種在工程方面的編譯方法。
一下是一個自己寫的Makefile文件
CC = gcc
CFLAGS = -O -Wall -m64 -std=gnu89
LIBS = -lm
all: main_max main_min #必須寫成all這樣的形式,否則只會生成前一個可執行文件main_max
main_max: main_max.c bar.o foo.o
$(CC) main_max.c bar.o foo.o -o main_max
main_min: main_min.c bar.o foo.o
$(CC) main_min.c bar.o foo.o -o main_min
foo.o: foo.c
$(CC) -c foo.c
bar.o: bar.c
$(CC) -c bar.c
.PHONY: clean
clean:
rm *.o main_max main_min
-
數據結構與Linux文件樹模擬
大二上數據結構課我們已經學過鏈表、隊列、二叉樹這些數據結構,它們的描述和定義以及常見的刪除節點、遍歷方法我們都編寫過C語言代碼,在這本書里面給出了這部分代碼,不過我個人覺得要深入理解的話只看這本書肯定不夠。不過還好我們學過所以這里再回顧一遍理解起來并不很難。而要去做一個Linux文件樹模擬相當于寫一個基于二叉樹數據結構的編程項目,里面的一些操作如mkdir、rmdir、creat、rm、cd、pwd、ls其實就是一些功能,我們可以編寫對應的函數去實現它。
參考了一些博客改了改,雖然很多功能很簡陋,最后還是有結果
#include <stdint.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdbool.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <libgen.h>
typedef struct Node{
char name[64];
char type;
struct Node *childPtr, *siblingPtr, *parentPtr;
}Node;
static Node *root, *cwd;
bool ap = false;
int deep = 0;
int num = 0;
static char line[128];
char command[16], pathname[64];
char dname[64], bname[64];
int mkdir_(),rmdir_(),cd(), ls(),pwd(),creat_(),rm(),save(),reload(),menu(),quit();
char *commad_list[] = {"mkdir", "rmdir", "cd", "ls", "pwd", "creat", "rm", "save", "reload", "menu", "quit", NULL};
int (*f_ptr[])() = { (int (*)())mkdir_, rmdir_, cd, ls, pwd, creat_, rm, save, reload, menu, quit };
void get_dir_base(){
char temp[128];
ap = false;
if(pathname[0] == '/') ap = true;
strcpy(temp, pathname);
strcpy(dname, dirname(temp));
strcpy(temp, pathname);
strcpy(bname, basename(temp));
}
void initialie(){
root = (Node*)malloc(sizeof(Node));
root->siblingPtr = root;
root->parentPtr = root;
root->childPtr = NULL;
root->name[0] = '/';
root->name[1] = '\0';
root->type = 'D';
cwd = root;
}
int findCommand(){
int i = 0;
while(commad_list[i]){
if(!strcmp(command, commad_list[i])) return i;
i++;
}
return -1;
}
void getCommand(){
bzero(line, 128);
read(STDIN_FILENO, line, 128);
bzero(command, 128);
line[strlen(line) - 1] = '\0';//kill \n
sscanf(line, "%s %s", command, pathname);
int idx = findCommand();
if(idx == -1) return;
f_ptr[idx]();
}
Node* mk_Node(char type){
Node *p = (Node*)malloc(sizeof(Node));
strcpy(p->name, bname);
p->type = type;
p->childPtr = NULL;
p->siblingPtr = NULL;
return p;
}
Node* find_d(){
get_dir_base();
char *s;
Node* per ;
per = cwd;
if(ap) per = root;
Node* cur = per->childPtr;
if(strcmp(dname, ".")){
s = strtok(dname, "/");
while(s){
while(cur){
if(!strcmp(s, cur->name) && cur->type == 'D'){
per = cur;
break;
};
cur = cur->siblingPtr;
}
if(cur == NULL) return NULL;
cur = per->childPtr;
s = strtok(NULL, "/");
}
}
return per;
}
int _pwd(Node* p, int fd){
char *s[deep];
char tmp[1024];
bzero(tmp, 1024);
Node* cur = p;
int i = 0;
int off = 0;
for(;i < deep && cur != root; i++){
s[i] = cur->name;
cur = cur->parentPtr;
}
tmp[off++] = '/';
while(i--){
int size = strlen(s[i]);
memcpy(tmp + off, s[i], size);
off += size;
if(i) tmp[off++] = '/';
}
tmp[off++] = '\n';
tmp[off] = '\0';
write(fd, tmp, strlen(tmp));
return 0;
}
int pwd(){
return _pwd(cwd, STDOUT_FILENO);
}
int save(){
int fd = open(pathname, O_RDWR|O_CREAT|O_TRUNC, 0666);
Node *stack[num];
Node* cur = root->childPtr;
if(cur == NULL) return -1;
int i = 0;
stack[i++] = cur;
while(i > 0){
cur = stack[--i];
write(fd, &cur->type, 1);
write(fd, " ", 2);
_pwd(cur, fd);
if(cur->siblingPtr) stack[i++] = cur->siblingPtr;
if(cur->childPtr) stack[i++] = cur->childPtr;
}
close(fd);
return 0;
}
int cd(){
Node* per = find_d();
Node* cur = per->childPtr;
while(cur){
if(!strcmp(bname, cur->name) && cur->type == 'D') break;
cur = cur->siblingPtr;
}
if(cur == NULL) return -1;
cwd = cur;
return 0;
}
int _rmdf(char type){
Node* per = find_d();
Node* cur = per->childPtr;
while(cur){
if(!strcmp(bname, cur->name) && cur->type == type) break;
per = cur;
cur = cur->siblingPtr;
}
if(cur == NULL) return -1;
if(type == 'D' && cur->childPtr != NULL) return -1;
if(per->childPtr == cur){
free(cur);
per->childPtr = NULL;
}else{
per->siblingPtr = cur->siblingPtr;
free(cur);
}
return 0;
}
int ls(){
Node* per = find_d();
if(per == NULL) return -1;
Node* cur = per->childPtr;
while(cur){
printf("type : %c name : %s \n", cur->type, cur->name);
cur = cur->siblingPtr;
}
return 0;
}
int rmdir_(){
if(!_rmdf('D')){
deep--;
return 0;
}
return -1;
}
int rm(){
return _rmdf('F');
}
int _mkdf(char type){
Node* per = find_d();
if(per == NULL) return -1;
Node* cur = per->childPtr;
if(cur == NULL){
per->childPtr = mk_Node(type);
per->childPtr->parentPtr = per;
num++;
return 0;
}
while(cur){
if(!strcmp(bname, cur->name) && cur->type == 'D') return -1;
per = cur;
cur = cur->siblingPtr;
}
per->siblingPtr = mk_Node(type);
per->siblingPtr->parentPtr = per->parentPtr;
num++;
return 0;
}
int reload(){
struct stat st;
if(stat(pathname, &st) == -1) return -1;
int fd = open(pathname, O_RDONLY);
char buf[st.st_size];
char tmp[128];
char type;
int i = 0;
int off = 0;
while((i = read(fd, buf + off, st.st_size - off)) > 0){
off += i;
}
close(fd);
i = 0;
int j = 0;
while(i < off){
if(buf[i] != '\n') i++;
else{
bzero(tmp, 128);
memcpy(tmp, buf + j, i - j);
sscanf(tmp, "%c %s",&type , pathname);
if(type == 'D') mkdir_();
else if(type == 'F') creat_();
else return -1;
j = ++i;
}
}
return 0;
}
int menu(){
printf("mkdir dirpath\n");
printf("rmdir dirpath\n");
printf("cd dirpath\n");
printf("ls dirname\n");
printf("pwd \n");
printf("cteat filepath\n");
printf("rm filepath\n");
printf("save filepath\n");
printf("reload filepath\n");
printf("quit\n");
return 0;
}
int creat_(){
return _mkdf('F');
}
int mkdir_(){
if(!_mkdf('D')){
deep++;
return 0;
}
return -1;
}
int quit(){
sprintf(pathname, "text.txt");
save();
exit(0);
return 0;
}
void show(){
printf("welcom to !\n");
printf("command menu show commands\n");
}
int main()
{
//scanf("%*[^\n]%*c");
initialie();
show();
while(1){
//fflush(stdin);
getCommand();
}
return 0;
}
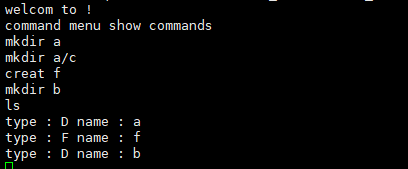
這個是運行的最終結果
-
通過這個項目,我又重新過手了C語言,看來C語言確實比較底層的語言,編寫Linux文件系統原來和我們數據結構的課程實驗是如此相像。
-
因為時間比較緊促,這個項目的細節還需要好生消化一下,這個程序的邏輯本身并不難,就是用樹狀結構模擬文件系統。尤其是二叉樹的遍歷等部分的代碼,在網上都有現成的,但是自己在已知邏輯的情況下能否靠自己寫出來,其實自己嘗試以后才知道。
posted on 2022-09-04 15:03 20201321周慧琳 閱讀(40) 評論(0) 收藏 舉報

 浙公網安備 33010602011771號
浙公網安備 33010602011771號