關于為什么使用 ASCII GBK Unicode編碼
關于為什么使用 ASCII GBK Unicode編碼
由來:大家都知道計算機最早是美國人為了更加便捷的存儲和計算數據發明的,但是呢計算機底層都是硬件,只能存儲像0101這樣的二進制數據,那美國人為了讓計算機能夠存儲他們所使用的字符(字母,數字,標點符號,特殊字符等),他們就對這些字符進行了編號,從0 開始一直到127,一共128個字符。 比如字符0的十進制編碼就是48,字符a的十進制編碼是97,字符A十進制編碼為65。我們把這些字符稱之為碼點,可以理解為是字符的唯一標識,那么這一套碼點下來,也就組成了一個字符集,就是我們使用ascii字符集。
ASCII(美國信息交換標準代碼)
接著上面說,但是上面的十進制字符集還是不能在計算機中進行存儲,所以美國人對這些碼點進行了編碼,直接把這些碼點轉成了他們對應的二進制形式,也就是7 位01組合 'xxxxxxx' ,但是這樣就不能滿足計算機的最小01組合(計算機的最小存儲單元就是1byte 8位01組合 ),所以在這些碼點的二進制前面補了一位0,正好變成了1字節用來表述字符。
標準的ASCII使用一個字節存儲一個字符,首位是 0 (0 被當作標識符),總共可以表示128個字符,這些對美國人來說完全是夠用了
ascii編碼形式:0xxxxxxx
GBK(漢字內碼擴展規范)
接著上面說,隨著計算機普及和發展,我們中國人也開始使用計算機。那么當我們中國人看到這個ASCII字符表的時候,只說了一句話,emmm,"還不夠我塞牙縫的!" ,這是由于我們的字符實在是太多了,ASCII沒有辦法再包含我們的字符,所以我們中國人就自己研發了一種新的GBK編碼,叫做 漢字編碼字符集。
GBK字符集包含二萬多個漢字等字符,GBK一個中文字符編碼是以兩個字節的形式存儲。
注意:這里需要注意GBK字符集是需要去兼容ascii的。
GBK編碼后的形式:1xxxxxxx xxxxxxxx 十五位 32768個字符,其中有二萬多個漢字字符
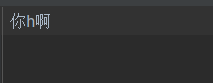
那么在GBK中,英文字符和漢字在計算機中如何進行解碼。比如:你h啊
編碼之后:xxxxxxxx xxxxxxxx|0xxxxxxx|xxxxxxxx xxxxxxxx
那么計算機在對底層的01比特解碼的時候如何去識別漢字和字母的編碼呢??
這里規定漢字的第一個字節的第一位必須是 1 ,ascii字節是第一位是0 ,那么計算機在解碼時就會根據字節的首位去判斷,當字節的第一位是1之后,就知道接下來的15位01比特表示了一個漢字,當字節的第一位是0時,就知道接下來的7位01比特表示一個ascii中的一個字符。
Unicode字符集(統一碼,也叫萬國碼)
接著上面說,當我們中國人看到ascii字符集無法表示中國漢字,就研發了GBK,那么當世界上其他國家也為他們的語言進行編碼之后,就會出現各種各樣的字符集編碼。 這樣的話,當計算機在世界流通,信息交換的時候,就會很麻煩。比如:當我們把用GBK編碼的字符發給美國,美國人用ascii編碼打開的時候,就會產生亂碼,無法解析我們的內容。
此時國際組織就站出來了,并且搞了一套全世界通用的字符集編碼unicode,也就是最早的是UTF-32 ,并且國際組織,呼吁各個國家使用unicode編碼,這樣就可以解決交流不通的問題了。
//utf-32
Unicode是國際組織制定的編碼,可以容納世界上所有的文字,符號的字符集
最早的 UTF-32
用4個字節表示32位表示一個字符,當初這樣設計的思想就是有容乃大(2^32足矣表示世界上的所以文字,想法很狂野,但不現實)
但是這樣以32位編碼的字符集并不被其他國家所認可,大家都認為這種編碼方案過太于"奢侈!" ,因為四個字節表示一個字符的編碼方式,占用存儲空間,并且使通信效率變低。比如:我們要表示一個字母就是 xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx,那么這樣的編碼方案,最終沒有被各個國家采用。
緊接著就誕生了 一個非常重要的 字符集編碼 UTF-8 (目前我們在使用的編碼一般都是這個編碼,比我我們在使用編譯器的時候默認就是使用utf-8)
UTF-8
utf-8 是Unicode字符集的一種編碼方案,采取可變長編碼方案,一共分為四個長度區 :1個字節,2個字節,3個字節,4個字節(按照需要去相應的使用)
那么英文字符、數字、漢字字符,在unicode中如何編碼呢?
在unicode中英文字符、數字 只占用一個字節(兼容ascii),漢字占用三個字節。
比如:n好a 0xxxxxxx|1110xxxxx 10xxxxxx 10xxxxxx|0xxxxxxx
那么解碼的時候如何區分呢?
這里規定的是,英文字符在進行存儲的時候就是一個以 0 開頭的字節,如果是兩個字節存儲時候,要求第一個字節是以110 第二個字節需要以10開頭,以此類推,至此我要講的編碼原理就結束了。

注意1:我們程序員一般使用 utf-8編碼
注意2:字符的編碼解碼需要使用同一種字符集,否則解碼的時候會出現亂碼的請
注意3: 英文和數字,一般不會亂碼,因為很多字符都兼容了ascii編碼
比如在pycharm編碼的時候使用的就是 utf-8
測試:使用不兼容編碼解析文本
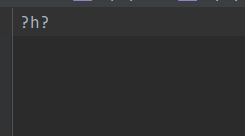
在pycharm中對 你h啊 進行解碼(編碼使用的是unicode--utf-8)
我們用ascii進行解碼
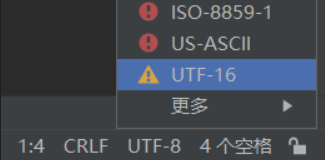
出現提示,我們是否要用ascii解析Unicode編碼
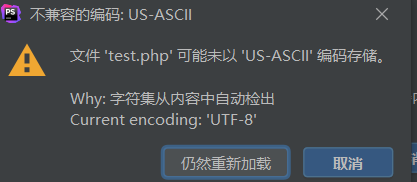
解析結果就出現了 ?h?,由于ascii不兼容Unicode編碼,所以在解碼的時候出現了亂碼。在ctf比賽中因解析問題出現的 ?就是這個原因
本文來自博客園,作者:Liberty碼農志,轉載請注明原文鏈接:http://www.rzrgm.cn/zhiliu/p/16858033.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號