

今天給大家帶來幾款AI語音克隆技術的硬核分享,包括本地部署教程,還有超方便的一鍵啟動整合包。無論你是技術小白還是資深玩家,這篇干貨都能讓你輕松上手,克隆出屬于自己的專屬語音!
1. Index-TTS:語音克隆界的“省心王者”
在AI語音克隆圈子里,Index-TTS絕對是“懶人福音”。它強不強?我說了不算,你們體驗了才知道!
簡介:
只需要一段語音樣本+你的文案,就能直接生成克隆后的語音。比起CosyVoice還得額外輸入語音對應的文本,Index-TTS直接省掉這一步,簡單到飛起,操作更人性化。
官方定位是:工業級可控高效零樣本文本轉語音系統。
亮點:
- 超強技術:基于XTTS和Tortoise打造的GPT風格TTS模型,融合拼音糾錯(漢字發音更準)、標點停頓控制(節奏隨心調)。
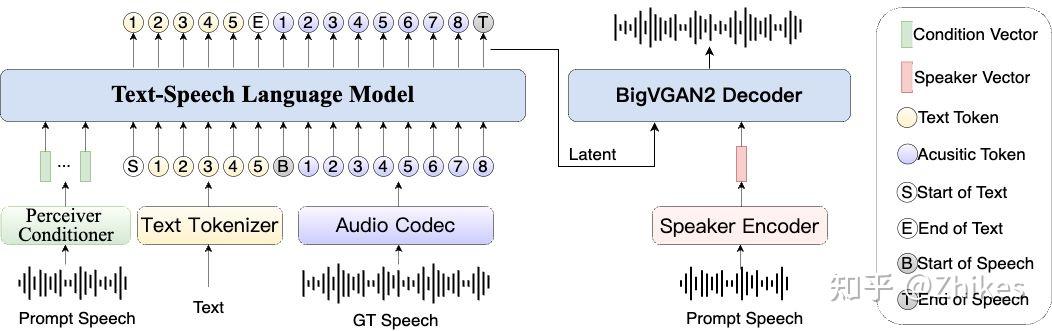
- 升級模塊:優化了說話人特征表示,集成BigVGAN2提升音質,經過數萬小時數據訓練,性能吊打XTTS、CosyVoice2、Fish-Speech和F5-TTS。
- 中文適配:漢字+拼音混合建模,快速修復發音問題;順應條件編碼器+BigVGAN2解碼器,音色相似度拉滿,音質更穩。
本地部署教程:
需要提前準備好Miniconda和git工具
克隆代碼
git clone https://github.com/index-tts/index-tts.git
cd index-tts
創建虛擬環境
conda create -n index-tts python=3.10
conda activate index-tts
打開requirements.txt文件,注釋掉WeTextProcessing
WeTextProcessing會報錯,后面再來單獨安裝它。
pip install -r requirements.txt
安裝torch以及cuda支持的輪子
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
再來安裝WeTextProcessing
pip install WeTextProcessing --no-deps
pip install ffmpeg-python
提示可能缺少模塊importlib_resources的話
pip install importlib_resources
下載模型到當前目錄的checkpoints目錄下
linux系統指令
wget https://huggingface.co/IndexTeam/Index-TTS/resolve/main/bigvgan_discriminator.pth -P checkpoints
wget https://huggingface.co/IndexTeam/Index-TTS/resolve/main/bigvgan_generator.pth -P checkpoints
wget https://huggingface.co/IndexTeam/Index-TTS/resolve/main/bpe.model -P checkpoints
wget https://huggingface.co/IndexTeam/Index-TTS/resolve/main/dvae.pth -P checkpoints
wget https://huggingface.co/IndexTeam/Index-TTS/resolve/main/gpt.pth -P checkpoints
wget https://huggingface.co/IndexTeam/Index-TTS/resolve/main/unigram_12000.vocab -P checkpoints
Windows系統指令
curl -L https://huggingface.co/IndexTeam/Index-TTS/resolve/main/bigvgan_discriminator.pth -o checkpoints\bigvgan_discriminator.pth
curl -L https://huggingface.co/IndexTeam/Index-TTS/resolve/main/bigvgan_generator.pth -o checkpoints\bigvgan_generator.pth
curl -L https://huggingface.co/IndexTeam/Index-TTS/resolve/main/bpe.model -o checkpoints\bpe.model
curl -L https://huggingface.co/IndexTeam/Index-TTS/resolve/main/dvae.pth -o checkpoints\dvae.pth
curl -L https://huggingface.co/IndexTeam/Index-TTS/resolve/main/gpt.pth -o checkpoints\gpt.pth
curl -L https://huggingface.co/IndexTeam/Index-TTS/resolve/main/unigram_12000.vocab -o checkpoints\unigram_12000.vocab
最后運行gradio網頁
python webui.py
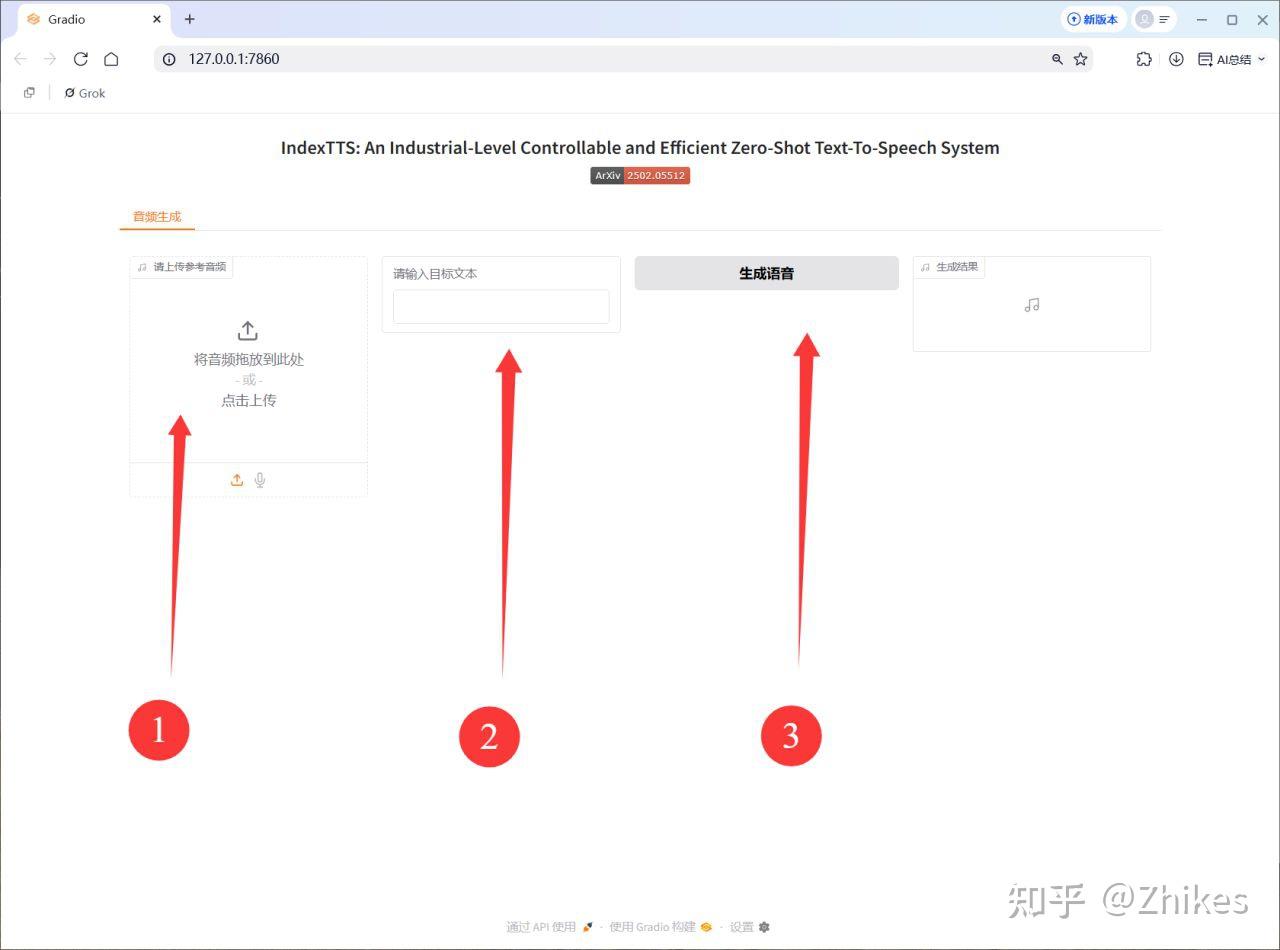
食用教程:
①上傳一段想要克隆音色的參考音頻,②上傳文案。③生成語音即可
2. MegaTTS3:官方限制太多,勸退體驗
我興沖沖地把MegaTTS3部署到本地,結果發現官方直接鎖死了npy音色文件。想用?得先把參考音頻發給他們,他們生成npy文件給你才能用。這操作簡直是“脫褲子放屁”,項目發展基本上被限制得死死的。
部署測試浪費了我不少時間,教程寫了一半直接作廢。直接pass。

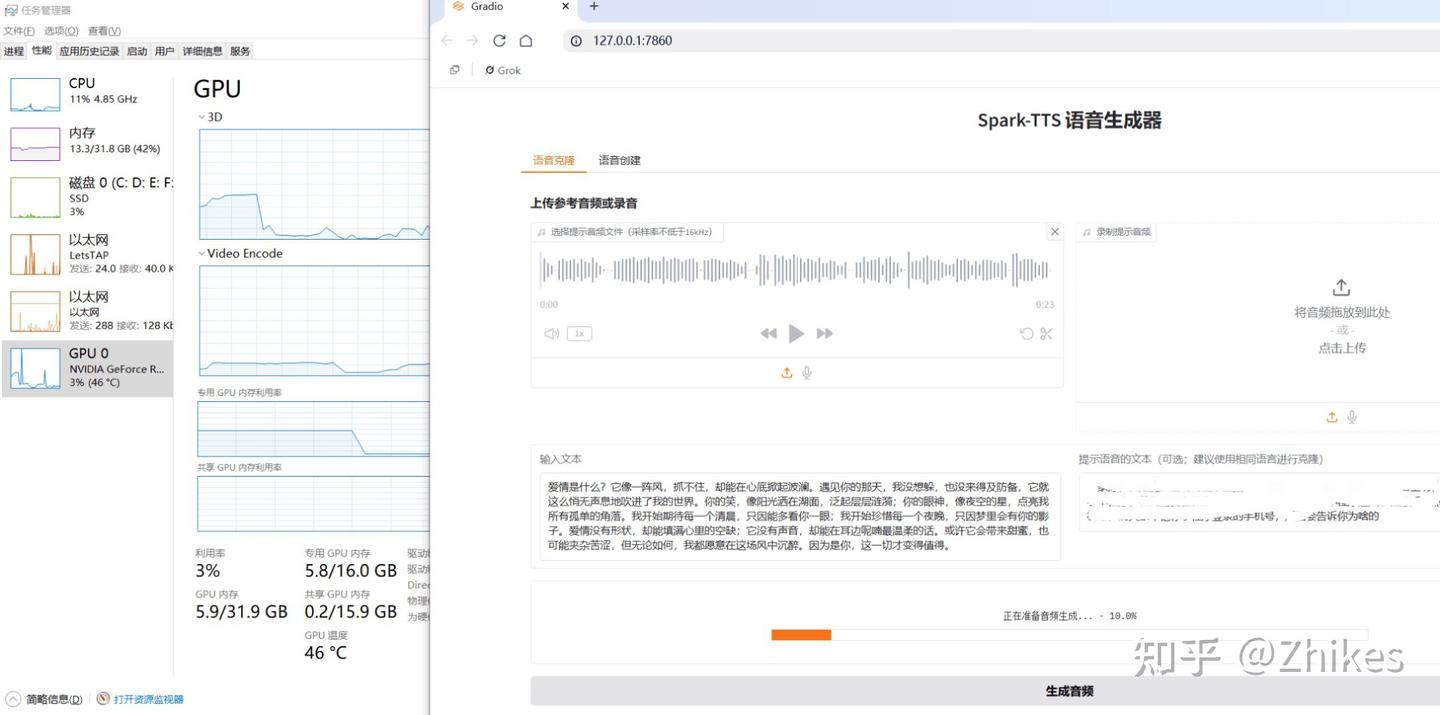
3. Spark-TTS:高效+高質量的語音克隆新星
簡介:
Spark-TTS是基于大型語言模型(LLM)的文本轉語音系統,簡單高效又自然,兼顧研究和生產需求。
亮點:
- 極簡架構:基于Qwen2.5打造,無需流匹配等復雜模型,直接從LLM預測代碼重建音頻,效率拉滿。
- 零樣本克隆:無需特定訓練數據,就能復制說話者音色,支持跨語言和代碼切換,靈活性爆棚。
- 雙語支持:中英文無縫切換,合成自然度超高。
- 可控生成:支持調整性別、音調、語速,輕松打造虛擬說話人。


本地部署教程:
克隆代碼到本地
git clone https://github.com/SparkAudio/Spark-TTS.git
cd Spark-TTS
創建虛擬環境
conda create -n sparktts -y python=3.10
conda activate sparktts
下載依賴
pip install -r requirements.txt
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
模型下載
通過python下載:
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
通過 git clone 下載:
mkdir -p pretrained_models
(windows下,直接mkdir pretrained_models)
# 你需要先去安裝git lfs工具 (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
調用gradio運行網頁界面
python webui.py --device 0
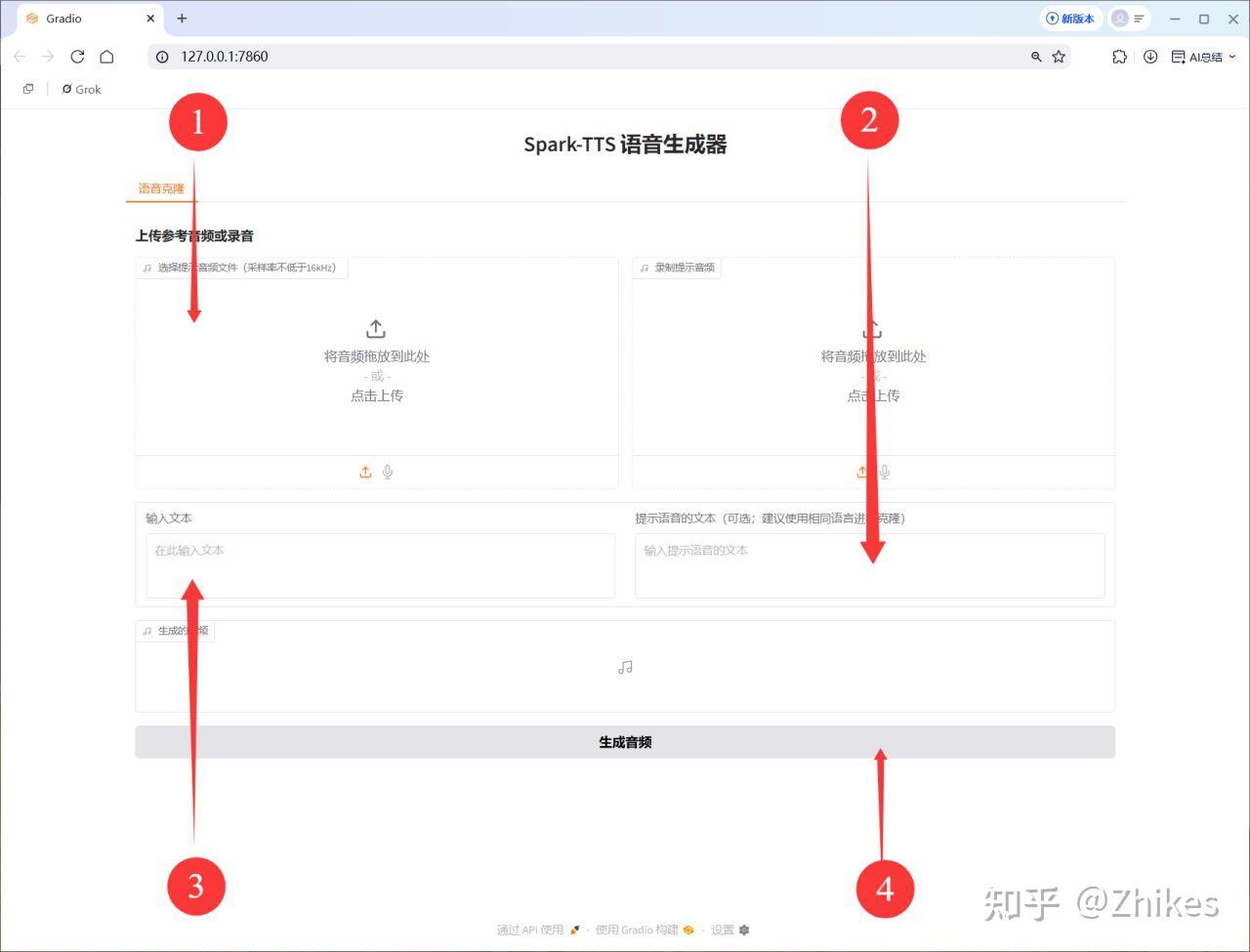
食用教程:
①上傳一段想要克隆音色的參考音頻,②上傳參考音頻的文本內容,③輸入你的文案內容,④生成音頻。 操作過程和CosyVoice類似,都是需要輸入參考音頻文本內容
一鍵整合包
想要省去繁瑣步驟?公眾號回復以下關鍵詞即可獲取對應一鍵包:
- index-tts 或 indexTTS
- Spark-TTS 或 SparkTTS
下載即用,解壓就能跑,無任何限制、不需激活,6G顯存輕松駕馭,放心開搞!
這三款AI語音克隆技術各有千秋,Index-TTS省心高效,Spark-TTS靈活強大,MegaTTS3……嗯,自求多福吧。快動手試試,打造屬于你的專屬語音吧!有任何問題都可以在星球留言快速得到支持,公眾號信息太多看不過來。
另外附上之前的語音克隆文章
CosyVoice
https://mp.weixin.qq.com/s/9jkz-HUAcl3ywTI9PKv9yQ
GPT-SoVITS V2

 浙公網安備 33010602011771號
浙公網安備 33010602011771號