
思源:秒級體驗百億級數據量監控鉆取
編者薦語:
當業務量快速增長的時候,業務保障平臺就要應運而生,預判問題發出告警,越快越好,從宏觀到微觀一路下鉆響應越快越好,尤其是交易量暴漲的高峰時段。怎么做到?看思源的現身說法:
以下文章來源于云縱達摩院 ,作者劉勤紅
——業務保障平臺性能提升走過的那些路
禧云信息/研發中心/劉勤紅(思源) 2019年11月
業務保障平臺需從多維度去監控業務的可靠性,快速定位問題并自動解決或推薦出解決方案,所以時效性顯得非常重要。接下來我將從以下三個維度展開如何將百億級數據量監控鉆取從十幾秒提升到秒級體驗:
· 工具升級:OpenTSDB-->Druid
· 調用鏈收集的優化
· 聚合查詢的優化
一、背景回顧
· 禧云的團餐業務發展非常迅速,短短幾個月的時間,日交易量就從數百萬拉高到千萬級,隨著調用鏈追蹤得愈發細致,業務數據量也從億級上升到百億級別。
· 團餐的高峰交易量比外賣更集中,外賣可以提前預訂,而團餐的早中晚就餐非常集中,全國的學生幾乎都是一個點兒下課,從下單到吃完也就集中在20-30分鐘內,下圖0為交易量的曲線圖,坡度幾乎是直線上升,真是爭分奪秒!
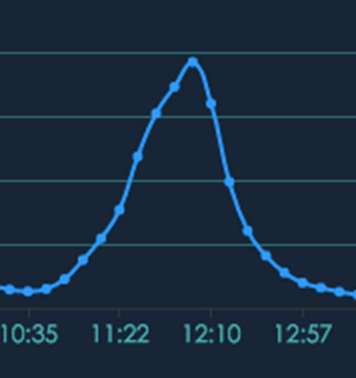
圖0 團餐高峰期爭分奪秒不容有失
在這種高強度業務場景下,業務保障平臺應運而生,它主要是多場景多維度實時監控大盤,從設備終端到服務端全鏈路監控,讓技術團隊從事后追查和整改,轉變為事前預警和快速判定根因。它主要涉及交易、業務調用鏈路、網絡監控、設備運行指標、業務日志等維度數據。架構如下圖1所示。
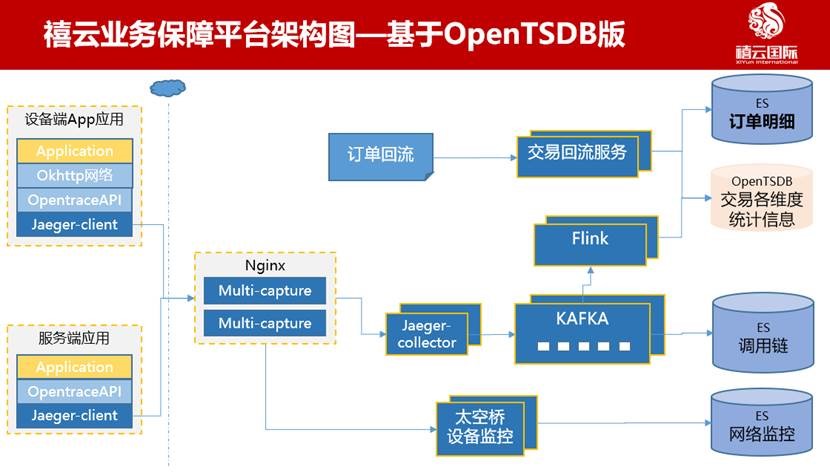
圖1 基于OpenTSDB版的大致架構
· 千萬級日交易數據:從各業務系統或支付網關回流的交易數據—>交易回流服務—>多維度聚合入庫OpenTSDB和ElasticSearch集群;
· 十億級業務調用鏈數據:基于Jaeger Trace植入-->Nginx多路分發-->經Jaeger-collector收集到Kafka-->被多組消費者處理(Flink實時寫入OpenTSDB,批量寫入ES);
· 百億級網絡和設備指標數據:主要是智能設備上報的各種監控指標:基于HTTP/HTTPS層監視-->Nginx-->太空橋(我司IoT平臺)設備監控-->批量入庫ES。
技術棧為:
· 鏈路采集:Uber開源的Jaeger
· 基礎數據存儲:ES
· 指標數據存儲:OpenTSDB
· 削峰填谷的消息隊列:Kafka
· 實時計算:Flink
二、工具升級:OpenTSDB升級到Druid
在禧云業務保障平臺上,OpenTSDB確實沒有太好的性能表現,查詢數據量在百萬級的時候,速度還是可以的,在暑假交易額低谷期并未暴露出OpenTSDB的性能問題。但是進入9月開學季之后,數據延時和查詢緩慢的問題立馬就暴露出來了,中途也寄希望于升級OpenTSDB版本,但依然效果不佳。
A. OpenTSDB性能表現不佳的原因
第一個原因,Rowkey設計過長的問題。Rowkey第一大設計原則是保證唯一性,否則原先的數據會被覆蓋掉,第二大設計原則是長度原則,Rowkey是一個二進制,它的長度建議設計在10~100個字節,越短越好。Rowkey如果過長,對性能有以下影響:
1)HBase的持久化文件HFile是按照KeyValue存儲的,如果Rowkey過長,比如500個字節,1000萬列數據,光Rowkey就要占用500*1000萬=50億個字節,將近1G數據,這會極大影響HFile的存儲效率。
2)MemStore緩存部分數據到內存,如果Rowkey字段過長,內存的有效利用率會降低,系統無法緩存更多的數據,這會降低檢索效率。
需要指出的是不僅Rowkey的長度越短越好,列族名、列名等也盡量使用短名字,因為這些名字都是會寫入HFile中的,過長的Rowkey、列族名、列名都會導致整體的存儲量成倍增加。
第二個原因,業務監控業務場景非常多,涉及到不同業務線的多個維度,比如多機房、多支付渠道、商戶/門店/設備/碼等多維度聚合,很難設計出一個滿足全場景的Rowkey方案。在任意維度的組合查詢下,OpenTSDB 查詢效率會明顯降低。
比如對于組合條件查詢使用的就是scan方式,在使用時有以下幾點值得注意:
1)通過setCaching、setBatch方法提高速度,以空間換時間;
2)通過setStartRow與setEndRow來限定范圍,范圍越小,性能越高;
3)通過setFilter方法添加過濾器,這也是分頁、多條件查詢的基礎,比如使用SingleColumnValueFilter。
以上優化當遇到真正海量數據時,會消耗很大的資源,每次都需要花較長的時間處理。
B. 升級為Druid
我司其他技術團隊已經試用了Druid, 其核心是通過數據預先聚合提高查詢性能,針對預先定義好的Schema,因此適合實時分析的場景,結果返回時間在亞秒級。
我們切換到Druid之后,響應速度上確實有一個數量級的提升,查詢千萬級的數據范圍基本秒級響應。
三、調用鏈收集的優化
調用鏈收集的數據流為:jaeger-collector-->Kafka-->jaeger-ingester 消費-->入庫ES。下面講一下如何優化。
A. 第一階段:Kafka消息堆積高峰期由千萬級降到百萬級
強調一點,合理的分區設置很重要。
剛開始我們嘗試調整每次拉取的消息條數,將ingester.parallelism由1000調整為6000,消息堆積似乎好了一點,但效果不明顯。
考慮到可能是因為并發數不夠,所以通過擴充Kafka的分區數去提高并發。先將分區數由5個擴到8個,消息堆積由千萬級降到百萬級。但繼續將分區擴到10個,就幾乎沒有什么效果了。
B. 第二階段:Kafka的版本選擇不可忽視
莫名其妙的是jaeger-ingester消費非常不穩定,頻繁與kafka斷開重連,嘗試去消費其他分區消息,導致消費速率上不去。
后來發現,當Kafka版本為v2.3時,多個jaeger-ingester節點會反復觸發kafka的消費再平衡機制,結果導致jaeger-ingester只能單點消費。
所以我們又將Kafka版本回退到了v2.2,調整jaeger-ingester實例個數和Kafka分區數為1:1,可橫向擴容支持高并發。
C. 第三階段:消息堆積高峰期由百萬降到萬級,延時秒級已可接受
我們觀察到ES的負載已經很高了,單節點高峰期CPU負載達到16。之前為了方便定位問題,給網絡請求實時加上了traceId標記,調用的是jaeger原生的trace鏈路計算。現在分析發現查詢QPS太高,所以嘗試優化查詢邏輯,一方面改為自定義的邏輯直接查詢ES,一方面調整好批量閾值查詢(指的是1次查多少,目前是按時間10ms和數據條數100條一個批次去查ES)。
優化完成后,消息堆積又下降一個數量級。目前高峰期堆積非常少,秒級消費已可接受。
四、聚合查詢的優化
A. 散點圖 vs 柱狀圖
對于調用鏈宏觀展示來說,慣常使用散點圖,它可以表達出一段時間內請求的耗時分布情況,如下圖2所示。

圖2 調用鏈散點圖
但是存在一個問題,當時間區間選得比較大的時候,服務端查詢的數據過多而響應變慢,客戶端要渲染的點太多也會非常卡。所以點要抽樣。抽樣方式能想得到的有:
a.過濾出耗時長的數據;
b.取最近一段時間的數據;
c.只取指定數量的數據;
d.對相同耗時進行聚合展示等等。
這些調整可謂犧牲了監控者的真實需求,因為有些數據監控者看不了,或者很難看全。
我們對比了阿里云日志服務的設計,他山之石可以攻玉,借鑒了以下兩點:
第一點,人們看問題的方式總是從宏觀一路下鉆到微觀,所以我們加了柱狀圖做為時間段聚合,方便從宏觀上看到請求量的規模分布。下圖3是某區域的訂單趨勢柱狀圖。

圖3 訂單趨勢柱狀圖
第二點,如果數據量非常大,可繼續點擊柱圖,展開當前時間條件下的子柱狀圖。系統根據數據量規模,自動展示出散點圖,方便用戶瀏覽耗時分布。這樣一層層穿刺下鉆,既滿足了人的操作習慣,又提高了處理速度,做到了秒級響應。
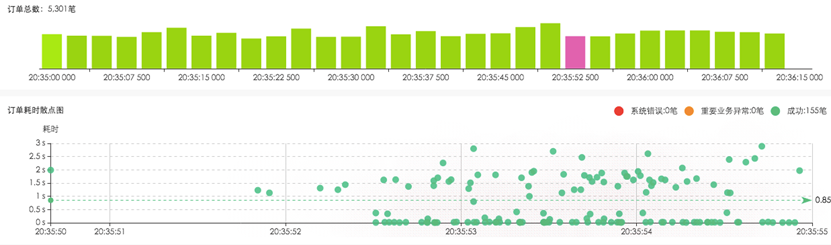
圖4柱狀圖下鉆
B. 從宏觀到微觀,化繁為簡
就宏觀到微觀的監控下鉆,下面講三個案例。
案例一,單一維度下鉆
其實多數時候人們只想關注某一維度的分布情況,比如按應用、按工程、按服務IP、按請求URL、按商戶、按門店、按設備看分布。對于ES來說,單一條件聚合速度很快,秒級響應。
案例二,網絡質量監察
我司在全國大江南北分布著大量餐飲中心(即食堂),如何快速定位出哪些食堂網絡環境糟糕呢?不能等客戶告訴我們。
我們從請求量級篩選(系統推薦和自定義)、dns/http/ssl/tcp/mqtt耗時情況、趨勢發展等諸多因子中分析出餐飲中心網絡情況,哪怕是學校食堂的一次網絡抖動,都可以被我們偵查到。不僅能分析出網絡問題,而且還能下鉆到請求鏈路上的任何階段,比如是DNS、TCP、SSL、首包等,并分析出受影響的終端設備。依然是秒級響應,如下圖5所示。
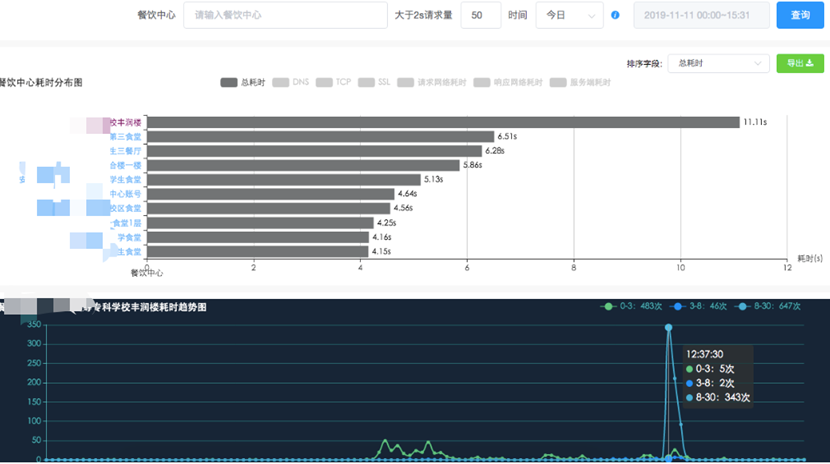
圖5 設備耗時下鉆
案例三,找出掉單
當用戶已支付而商戶未收款時,如何從千萬級訂單中快速找到丟失的那一筆訂單呢?內部稱sos訂單:
- 秒級偵查出來;
- 快速定位在哪個環節出了問題;
- 系統自我修復能力
具體做法為:
第一步,將內部可能發生的業務場景圈出來,通過Flink實時計算形成閉環,當其中一個鏈條斷了,就會立馬把待排查的sos訂單壓入隊列任務,然后不斷主動查詢第三方支付渠道確認支付狀態。
第二步,對于一些疑難問題如短時間內系統無法解決時,比如第三方支付渠道出現了故障,就會發出告警消息給客服,客服預先跟進,減少用戶投訴處理時間。
總結一下:
OpenTSDB切換為Druid,明顯提升了從宏觀下鉆到微觀的響應時間,基本能做到百億級數據量秒級響應。高峰時段Kafka消息堆積也大幅降低。下鉆方式做了優化,更符合工程師探查習慣。
-完-
歡迎關注公眾號:老兵筆記


 浙公網安備 33010602011771號
浙公網安備 33010602011771號