
計(jì)算與軟件工程 作業(yè)4
| 作業(yè)要求 | https://edu.cnblogs.com/campus/jssf/infor_computation17-31/homework/10534 |
|---|---|
| 課程的目標(biāo) | 學(xué)會(huì)結(jié)對(duì)編程,完成簡(jiǎn)單軟件功能的開發(fā),會(huì)對(duì)簡(jiǎn)單代碼進(jìn)行審核,學(xué)會(huì)兩人一起合作,會(huì)對(duì)代碼進(jìn)行單元測(cè)試等,分析代碼的利用率 |
| 此作業(yè)在具體方面幫我實(shí)現(xiàn)目標(biāo) | 和隊(duì)友搭檔完成程序開發(fā),進(jìn)行代碼復(fù)審,簡(jiǎn)單修改代碼挺高代碼利用率,學(xué)會(huì)用新的語(yǔ)言進(jìn)行編程 |
| 其他參考文獻(xiàn) | http://www.rzrgm.cn/xinz/archive/2011/08/07/2130332.html http://www.rzrgm.cn/lsdb/p/9201029.html https://blog.csdn.net/fly_egg/article/details/85050346 |
| 作業(yè)正文 | https://i-beta.cnblogs.com/posts/edit;postId=12620402 |
作業(yè)1
評(píng)價(jià)鏈接
1.http://www.rzrgm.cn/kaka123456/p/12442520.html

2.http://www.rzrgm.cn/limin123/p/12455500.html

3.http://www.rzrgm.cn/wanghuiru/p/12460279.html

4.http://www.rzrgm.cn/zxy123456/p/12449427.html

5.http://www.rzrgm.cn/wanghuiru/p/12397287.html

6.http://www.rzrgm.cn/zxy123456/p/12366171.html

7.http://www.rzrgm.cn/limin123/p/12377468.html

8.http://www.rzrgm.cn/liziye/p/12372753.html

總體看法
通過(guò)對(duì)其他同學(xué)代碼的評(píng)價(jià)以及看完其他同學(xué)對(duì)自己代碼的評(píng)價(jià)之后,覺(jué)得自己寫的有很多的不足之處,比如說(shuō)有的代碼未按老師要求實(shí)現(xiàn)具體的功能,也沒(méi)有用markdown編輯器將其框起來(lái),顯得非常的亂,可讀性不是很好,以后要改正這些方面的缺點(diǎn),使自己的代碼更加規(guī)范。
作業(yè)2 結(jié)對(duì)編程
具體要求
1.實(shí)現(xiàn)一個(gè)簡(jiǎn)單而完整的軟件工具(中文文本文件人物統(tǒng)計(jì)程序):針對(duì)小說(shuō)《紅樓夢(mèng)》要求能分析得出各個(gè)人物在每一個(gè)章回中各自出現(xiàn)的次數(shù),將這些統(tǒng)計(jì)結(jié)果能寫入到一個(gè)csv格式的文件。
2.進(jìn)行單元測(cè)試、回歸測(cè)試、效能測(cè)試,在實(shí)現(xiàn)上述程序的過(guò)程中使用相關(guān)的工具。
進(jìn)行個(gè)人軟件過(guò)程(PSP)的實(shí)踐,逐步記錄自己在每個(gè)軟件工程環(huán)節(jié)花費(fèi)的時(shí)間。
使用源代碼管理系統(tǒng) (GitHub, Gitee, Coding.net, 等);
3.針對(duì)上述形成的軟件程序,對(duì)于新的文本小說(shuō)《水滸傳》分析各個(gè)章節(jié)人物出現(xiàn)次數(shù),來(lái)考察代碼。
4.將上述程序開發(fā)結(jié)對(duì)編程過(guò)程記錄到新的博客中,尤其是需要通過(guò)各種形式展現(xiàn)結(jié)對(duì)編程過(guò)程,并將程序獲得的《紅樓夢(mèng)》與《水滸傳》各個(gè)章節(jié)人物出現(xiàn)次數(shù)與全本人物出現(xiàn)總次數(shù),通過(guò)柱狀圖、餅圖、表格等形式展現(xiàn)。
運(yùn)行界面

《紅樓夢(mèng)》人物出場(chǎng)次數(shù)統(tǒng)計(jì)
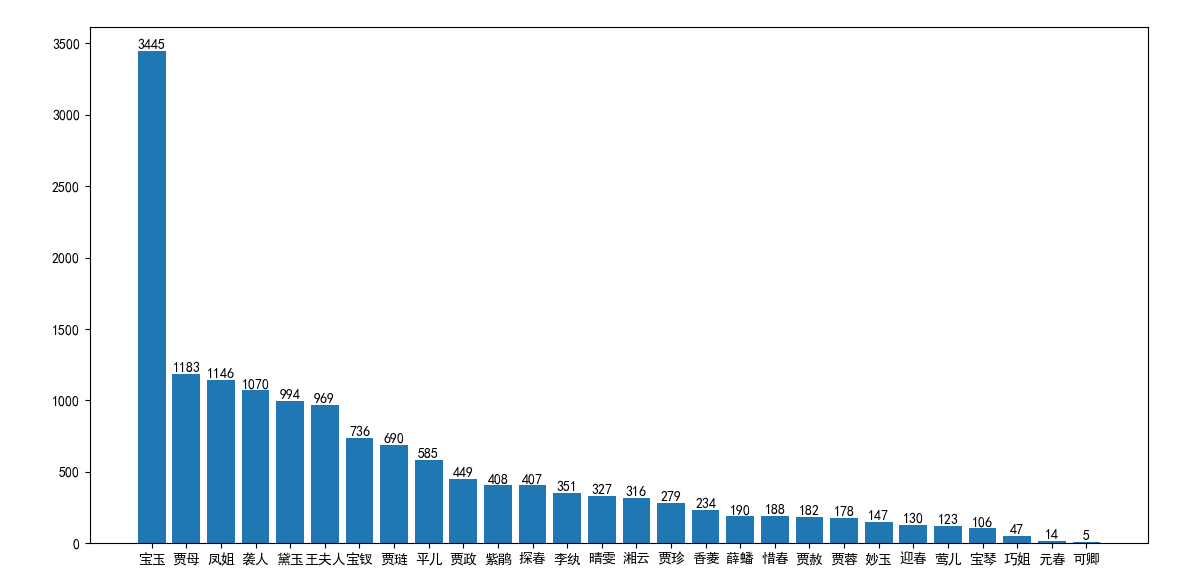

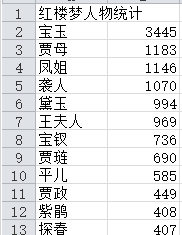
csv格式輸出統(tǒng)計(jì)
運(yùn)行界面

《水滸傳》人物出場(chǎng)次數(shù)統(tǒng)計(jì)
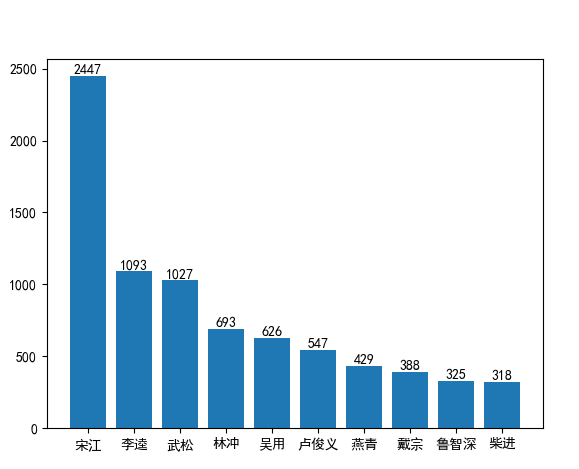
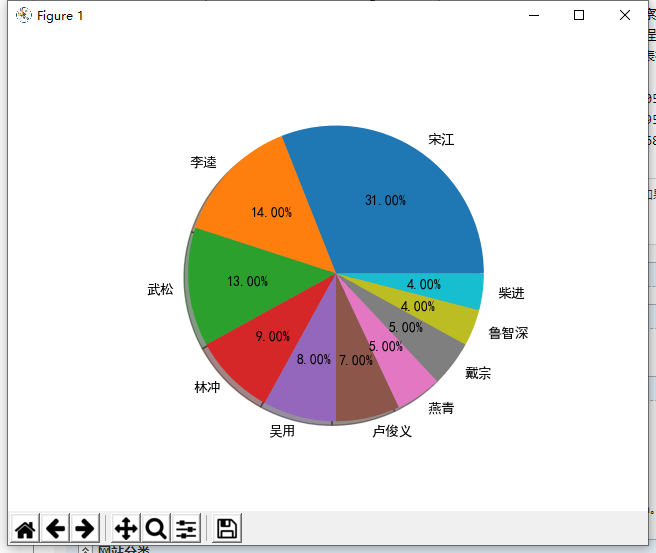
csv格式輸出統(tǒng)計(jì)

各個(gè)模塊安裝界面




實(shí)驗(yàn)總結(jié)
本次實(shí)驗(yàn)因?yàn)閷W(xué)過(guò)的c++語(yǔ)言和Java語(yǔ)言無(wú)法高效率的統(tǒng)計(jì)中文出現(xiàn)字?jǐn)?shù),所以我轉(zhuǎn)而進(jìn)行了Python的下載和使用,但是一開始遇到了很多的問(wèn)題,比如說(shuō)缺少各種模塊,導(dǎo)致結(jié)果運(yùn)行不出來(lái),最后在百度以及同學(xué)的幫助下順利實(shí)現(xiàn)了這個(gè)代碼。對(duì)于兩人結(jié)對(duì)編程而言,剛開始還不太習(xí)慣,但是慢慢地到了后來(lái)各自分工明確,效率也逐漸提高了。
未解決的問(wèn)題:因?yàn)閯傞_始學(xué)習(xí)Python語(yǔ)言,還未真正的學(xué)懂,所以也沒(méi)有實(shí)現(xiàn)分章節(jié)統(tǒng)計(jì)《紅樓夢(mèng)》和《水滸傳》里人物出場(chǎng)的次數(shù),以后還會(huì)陸續(xù)改進(jìn)。
附錄
# coding=utf-8
import jieba
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
class HlmNameCount():
# 此函數(shù)用于繪制條形圖
def showNameBar(self,name_list_sort,name_list_count):
#條形數(shù)量
x = np.arange(len(name_list_sort))
#此語(yǔ)句用來(lái)處理中文亂碼
plt.rcParams['font.sans-serif'] = ['SimHei']
#繪制條形圖
bars = plt.bar(x,name_list_count)
#給每個(gè)條形起名
plt.xticks(x,name_list_sort)
#顯示條形具體的數(shù)量
i = 0
for bar in bars:
plt.text((bar.get_x() + bar.get_width() / 2), bar.get_height(), '%d' % name_list_count[i], ha='center', va='bottom')
i += 1
#畫圖
plt.show()
# 此函數(shù)用于繪制餅狀圖
def showNamePie(self, name_list_sort, name_list_fracs):
#此語(yǔ)句用來(lái)處理中文亂碼
plt.rcParams['font.sans-serif'] = ['SimHei']
# 繪制餅狀圖
plt.pie(name_list_fracs, labels=name_list_sort, autopct='%1.2f%%', shadow=True)
#畫圖
plt.show()
def getNameTimesSort(self,name_list,txt_path):
# 將所有人名臨時(shí)添加到j(luò)ieba所用字典,以使jieba能識(shí)別所有人名
for k in name_list:
jieba.add_word(k)
# 打開并讀取txt文件
file_obj = open(txt_path, 'rb').read()
# jieba分詞
jieba_cut = jieba.cut(file_obj)
# Counter重新組裝以方便讀取
book_counter = Counter(jieba_cut)
# 人名列表,因?yàn)橐幚眸P姐所以不直接用name_lis
name_dict ={}
# 人名出現(xiàn)的總次數(shù),用于后邊計(jì)算百分比
name_total_count = 0
for k in name_list:
if k == '熙鳳':
# 將熙鳳出現(xiàn)的次數(shù)合并到鳳姐
name_dict['鳳姐'] += book_counter[k]
else:
name_dict[k] = book_counter[k]
name_total_count += book_counter[k]
# Counter重新組裝以使用most_common排序
name_counter = Counter(name_dict)
# 按出現(xiàn)次數(shù)排序后的人名列表
name_list_sort = []
name_list_fracs = []
name_list_count = []
for k,v in name_counter.most_common():
name_list_sort.append(k)
name_list_fracs.append(round(v/name_total_count,2)*100)
name_list_count.append(v)
# print(k+':'+str(v))
# 繪制條形圖
self.showNameBar(name_list_sort, name_list_count)
# 繪制條形圖
self.showNamePie(name_list_sort,name_list_fracs)
if __name__ == '__main__':
# 參與統(tǒng)計(jì)的人名列表
name_list = ['寶玉', '黛玉', '寶釵', '元春', '探春', '湘云', '妙玉', '迎春', '惜春', '鳳姐', '熙鳳', '巧姐', '李紈', '可卿', '賈母', '賈珍', '賈蓉', '賈赦', '賈政', '王夫人', '賈璉', '薛蟠', '香菱', '寶琴', '襲人', '晴雯', '平兒', '紫鵑', '鶯兒']
# 紅樓夢(mèng)txt文件所在路徑
txt_path = 'F:\紅樓夢(mèng).txt'
hnc = HlmNameCount()
hnc.getNameTimesSort(name_list,txt_path)
# coding=utf-8
import jieba
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
class HlmNameCount():
# 此函數(shù)用于繪制條形圖
def showNameBar(self,name_list_sort,name_list_count):
# x代表?xiàng)l形數(shù)量
x = np.arange(len(name_list_sort))
# 處理中文亂碼
plt.rcParams['font.sans-serif'] = ['SimHei']
# 繪制條形圖,bars相當(dāng)于句柄
bars = plt.bar(x,name_list_count)
# 給各條形打上標(biāo)簽
plt.xticks(x,name_list_sort)
# 顯示各條形具體數(shù)量
i = 0
for bar in bars:
plt.text((bar.get_x() + bar.get_width() / 2), bar.get_height(), '%d' % name_list_count[i], ha='center', va='bottom')
i += 1
# 顯示圖形
plt.show()
# 此函數(shù)用于繪制餅狀圖
def showNamePie(self, name_list_sort, name_list_fracs):
# 處理中文亂碼
plt.rcParams['font.sans-serif'] = ['SimHei']
# 繪制餅狀圖
plt.pie(name_list_fracs, labels=name_list_sort, autopct='%1.2f%%', shadow=True)
# 顯示圖形
plt.show()
def getNameTimesSort(self,name_list,txt_path):
# 將所有人名臨時(shí)添加到j(luò)ieba所用字典,以使jieba能識(shí)別所有人名
for k in name_list:
jieba.add_word(k)
# 打開并讀取txt文件
file_obj = open(txt_path, 'rb').read()
# jieba分詞
jieba_cut = jieba.cut(file_obj)
# Counter重新組裝以方便讀取
book_counter = Counter(jieba_cut)
# 人名列表,因?yàn)橐幚砝铄铀圆恢苯佑胣ame_list
name_dict ={}
# 人名出現(xiàn)的總次數(shù),用于后邊計(jì)算百分比
name_total_count = 0
for k in name_list:
if k == '黑旋風(fēng)':
# 將黑旋風(fēng)出現(xiàn)的次數(shù)合并到李逵
name_dict['李逵'] += book_counter[k]
else:
name_dict[k] = book_counter[k]
name_total_count += book_counter[k]
# Counter重新組裝以使用most_common排序
name_counter = Counter(name_dict)
# 按出現(xiàn)次數(shù)排序后的人名列表
name_list_sort = []
# 按出現(xiàn)次數(shù)排序后的人名百分比列表
name_list_fracs = []
# 按出現(xiàn)次數(shù)排序后的人名次數(shù)列表
name_list_count = []
for k,v in name_counter.most_common():
name_list_sort.append(k)
name_list_fracs.append(round(v/name_total_count,2)*100)
name_list_count.append(v)
# print(k+':'+str(v))
# 繪制條形圖
self.showNameBar(name_list_sort, name_list_count)
# 繪制餅狀圖
self.showNamePie(name_list_sort,name_list_fracs)
if __name__ == '__main__':
# 參與統(tǒng)計(jì)的人名列表
name_list = ['宋江', '李逵', '武松', '吳用', '林沖', '魯智深', '戴宗', '盧俊義', '燕青','柴進(jìn)']
# 紅樓夢(mèng)txt文件所在路徑
txt_path = 'F:/水滸傳.txt'
hnc = HlmNameCount()
hnc.getNameTimesSort(name_list,txt_path)

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)