
NVIDIA Kernel級性能分析工具Nsight Compute入門詳解
1 功能初體驗
1.1 分析實例
仍以之前的vectorAdd程序為分析目標,在新建的工程中只指定編譯好的可執行文件及其輸出report文件,其他部分都保持默認,然后直接點擊“Launch”進行分析。

圖1 Launch界面
運行完畢后生成如下分析結果:

先整體介紹下report結果:
1. 基礎信息(頂部欄)
首先是內核名稱:vectorAdd,向量加法內核;接下來是核函數的執行Size,Grid Size(196, 1, 1),即網格維度,共196個線程塊,Block Size(256, 1, 1),即塊維度,每個線程塊256個線程,總線程數196*256=50176,其中有176個閑置線程,因為源碼中numElements值為50000,只要5萬個線程;再接下來是時間指標Time,內核執行總時間是3.97 us,微秒級;Cycles是GPU核心執行內核函數所消耗的時鐘周期數,這里為6059個周期;GPU是運行當前可執行程序的顯卡,即NVIDIA GeForce RTX 4060 Laptop GPU(移動版 RTX 4060);SM Frequency是頻率,1.52GHz,對應1個周期約為0.65789納秒,乘于周期數6059,則為3986ns,和之前Time 3.97us基本相等。
2. 性能指標(表格列)
Summary選項卡中給出了總結信息:
Estimated Speedup:性能優化潛力(理論加速比),60.45 表示最多可加速 60 倍,表明kernel還有較大改進空間
Function Name:內核函數名 vectorAdd,對應代碼中的 __global__ void vectorAdd(...)
Demangled Name:符號解析后的名稱(編譯器相關,一般無需關注)
Duration:內核執行總時間
Runtime Improvement:運行時優化空間,2.40 表示可通過優化減少 2.4 倍運行時間
Compute Throughput:計算吞吐量 8.63(單位:GFLOP/s 或類似),反映計算密集度
Memory Throughput:內存吞吐量 39.00(單位:GB/s),反映內存訪問效率
# Registers:每個線程使用的寄存器數量 16,屬于比較低的寄存器占用
Grid Size: 196,1,1
Block Size: 256,1,1
3. 優化建議(底部警告)
報告提示了三個主要的性能優化方向:
(1)Achieved Occupancy(估計可提升 29.62%)
問題:理論最大 occupancy 為 100%,實際測量值只有 70.4%,低 occupancy 的原因可能是 warp 調度開銷或 workload 不均衡。
優化方法:調整 block size / grid size,提升 SM 利用率;避免線程塊間負載不均衡。
(2)Long Scoreboard Stalls(估計可提升 60.45%)
問題:平均每個 Warp 有 63.5 cycles 在等待 L1TEX(本地、全局、表面、紋理)數據返回,占總周期的 60.4%,即60.4%時間浪費在指令間的等待上。
優化方法:內存訪問模式(合并訪問、提高數據局部性),將高頻使用的數據移到共享內存(Shared Memroy)。
(3)Tail Effect(尾部效應)
問題:一個 grid 的線程塊不能整除 GPU 可并行調度的“波數”,導致最后一批 thread block 不能充分利用硬件資源,當前配置造成了 最多 50% 的執行浪費。
優化方法:嘗試修改 grid size,使得 block 數量更接近硬件多處理器的倍數,增加 workload(更多線程塊),避免出現“半波”執行。
以上分析表明vectorAdd kernel 在 RTX 4060 上的主要瓶頸是 內存訪問延遲 (Long Scoreboard Stalls) 和 線程調度不足 (Tail Effect + Occupancy 不高)。
1.2 解析
1. 關鍵點
(1)vectorAdd 本質上就是 memory-bound kernel
每個線程只做一次加法(幾乎沒有算術量),主要開銷就是把 A[i],B[i] 從 global memory 讀出來再將和C[i]寫回去,GPU 的帶寬利用率才是限制性能的瓶頸,而不是ALU。即使優化了寄存器或者調度,提升也非常有限。
(2)Long Scoreboard Stalls
Nsight 顯示大部分時間在等 L1TEX(global load/store 的 scoreboard 依賴),vectorAdd 這種 pattern 不容易通過 cache 命中率優化來改善,因為幾乎就是一次性讀寫。
(3)Occupancy ~71%(理論 100%)
Nsight 提示 Launch 配置(196 個 block × 256 線程)導致最后一個 "wave" 不滿,tail effect 占了 50%,如果 grid size 和 GPU SM 數量不匹配,就會有一部分 SM 沒有被充分利用。這里Wave是 GPU 調度的基本單位:在 AMD GPU中稱為“Wavefront”(32 個線程),在 NVIDIA GPU 中對應 “Warp”(線程束,同樣是 32 個線程)。
2. 優化
vectorAdd的 kernel 已經是 “最簡單、最輕量”的形式,瓶頸在內存帶寬。除非:
- 使用更大數據規模去真正壓滿GPU內存帶寬
- 改用pinned memory + cudaMemcpyAsync pipeline做數據傳輸 overlap
- 改寫 kernel,讓每個線程做 更多計算(算力 bound 而不是帶寬 bound)
否則vectorAdd程序的Nsight的報告不會顯示太大差別。
(1)增大數據規模
增大向量個數,再 profile 看 memory throughput 是否接近 GPU 理論帶寬,同時看下Report結果是否有變化。修改后程序如下:
#include <cuda_runtime.h> #include <stdio.h> #include <stdlib.h> #define N (1 << 26) // 64M elements,大約 256 MB 數據 #define THREADS_PER_BLOCK 256 __global__ void vectorAdd(const float* A, const float* B, float* C, int n) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < n) { C[idx] = A[idx] + B[idx]; } } int main() { size_t size = N * sizeof(float); float* h_A, * h_B, * h_C; float* d_A, * d_B, * d_C; // ==================== 查詢 GPU 理論帶寬 ==================== cudaDeviceProp prop; int device; cudaGetDevice(&device); cudaGetDeviceProperties(&prop, device); double memClockMHz = prop.memoryClockRate * 1e-3; // kHz -> MHz double busWidthBits = prop.memoryBusWidth; // 位寬 (bits) double theoreticalBW = 2.0 * memClockMHz * (busWidthBits / 8.0) / 1000.0; // GB/s GDDR6 是 雙倍速率 (DDR),所以要乘 2 printf("GPU: %s\n", prop.name); printf("Memory Clock: %.0f MHz, Bus Width: %.0f bits\n", memClockMHz, busWidthBits); printf("Theoretical Memory Bandwidth = %.2f GB/s\n\n", theoreticalBW); // 分配 host 內存 h_A = (float*)malloc(size); h_B = (float*)malloc(size); h_C = (float*)malloc(size); // 初始化數據 for (int i = 0; i < N; i++) { h_A[i] = 1.0f; h_B[i] = 2.0f; } // 分配 device 內存 cudaMalloc((void**)&d_A, size); cudaMalloc((void**)&d_B, size); cudaMalloc((void**)&d_C, size); // 拷貝數據到 device cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice); // 設置 kernel launch 配置 int blocksPerGrid = (N + THREADS_PER_BLOCK - 1) / THREADS_PER_BLOCK; // CUDA event 計時 cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); cudaEventRecord(start); // 啟動 kernel vectorAdd << <blocksPerGrid, THREADS_PER_BLOCK >> > (d_A, d_B, d_C, N); cudaEventRecord(stop); cudaEventSynchronize(stop); float milliseconds = 0; cudaEventElapsedTime(&milliseconds, start, stop); // 計算實際帶寬:每個元素讀 A,B 并寫 C (共 3 次訪問) double totalBytes = 3.0 * size; // bytes double bandwidthGBs = (totalBytes / (milliseconds / 1000.0)) / 1e9; printf("VectorAdd size = %d elements\n", N); printf("Time = %.3f ms\n", milliseconds); printf("Effective memory bandwidth = %.2f GB/s\n", bandwidthGBs); // 清理 cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost); cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); free(h_A); free(h_B); free(h_C); return 0; }
編譯后重新用Compute對程序進行分析,結果如下:
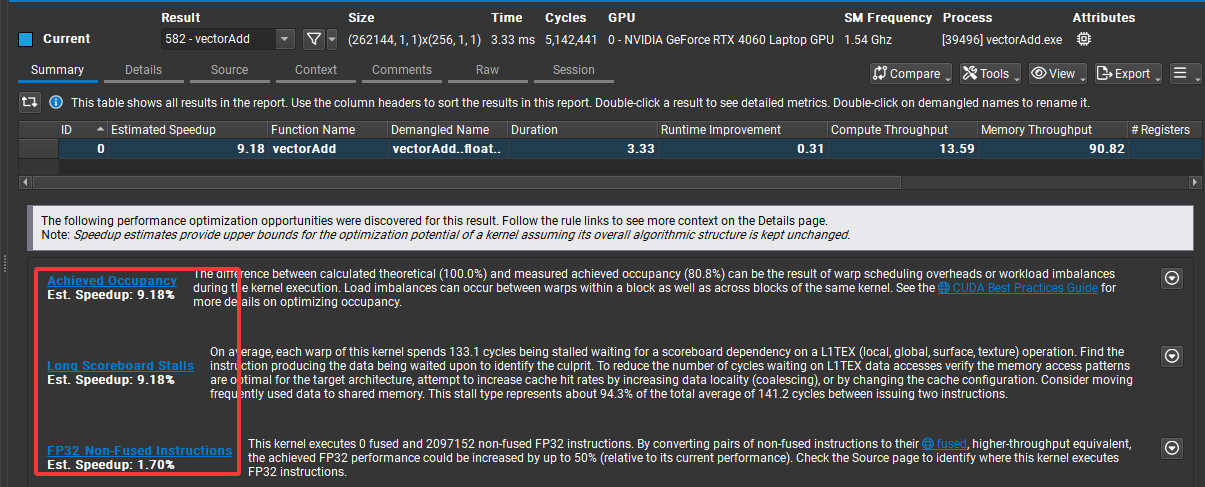
可以看出增大向量規模的情況下,程序可優化的空間已經大大減小,而且實際內存帶寬利用率已經很接近理論值:
(2)pinned memory(頁鎖定內存)
默認 malloc 出來的 host 內存是 pageable(可分頁)的,GPU 在拷貝時可能需要額外的staging(暫存緩沖區),速度會打折扣。用 cudaMallocHost() 或 cudaHostAlloc() 分配 頁鎖定內存,CUDA 就能直接 DMA 到顯卡,帶寬更高。另外cudaMemcpy 是阻塞的,拷貝完成前 CPU 會停在那里,cudaMemcpyAsync + stream 可以異步執行,拷貝和 kernel 可以 并行 overlap。最后借助Pipeline(流水線)技術,把大數據分成多塊 (chunk),拷貝第 N 塊時,GPU 可以同時計算第 N-1 塊,實現計算與拷貝重疊,提升吞吐率。修改后程序如下:
#include <cuda_runtime.h> #include <stdio.h> #define N (1 << 26) // 64M elements #define THREADS_PER_BLOCK 256 #define CHUNK_SIZE (1 << 20) // 每塊 1M 元素 __global__ void vectorAdd(const float *A, const float *B, float *C, int n) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < n) { C[idx] = A[idx] + B[idx]; } } int main() { size_t size = N * sizeof(float); // 使用 pinned host memory float *h_A, *h_B, *h_C; cudaMallocHost((void**)&h_A, size); cudaMallocHost((void**)&h_B, size); cudaMallocHost((void**)&h_C, size); for (int i = 0; i < N; i++) { h_A[i] = 1.0f; h_B[i] = 2.0f; } // device 內存(只分配一塊 chunk 的大小) float *d_A, *d_B, *d_C; size_t chunkBytes = CHUNK_SIZE * sizeof(float); cudaMalloc((void**)&d_A, chunkBytes); cudaMalloc((void**)&d_B, chunkBytes); cudaMalloc((void**)&d_C, chunkBytes); // 創建 stream cudaStream_t stream; cudaStreamCreate(&stream); // 計時 cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); cudaEventRecord(start, 0); for (int offset = 0; offset < N; offset += CHUNK_SIZE) { int chunkElems = min(CHUNK_SIZE, N - offset); int blocks = (chunkElems + THREADS_PER_BLOCK - 1) / THREADS_PER_BLOCK; // 異步拷貝 H2D cudaMemcpyAsync(d_A, h_A + offset, chunkElems * sizeof(float), cudaMemcpyHostToDevice, stream); cudaMemcpyAsync(d_B, h_B + offset, chunkElems * sizeof(float), cudaMemcpyHostToDevice, stream); // 啟動 kernel vectorAdd<<<blocks, THREADS_PER_BLOCK, 0, stream>>>(d_A, d_B, d_C, chunkElems); // 異步拷貝 D2H cudaMemcpyAsync(h_C + offset, d_C, chunkElems * sizeof(float), cudaMemcpyDeviceToHost, stream); } cudaEventRecord(stop, stream); cudaEventSynchronize(stop); float milliseconds = 0; cudaEventElapsedTime(&milliseconds, start, stop); printf("VectorAdd with pinned memory + async pipeline\n"); printf("Size = %d elements, Time = %.3f ms\n", N, milliseconds); // 校驗結果 for (int i = 0; i < 10; i++) { if (h_C[i] != 3.0f) { printf("Error at %d: %f\n", i, h_C[i]); break; } } // 釋放 cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); cudaFreeHost(h_A); cudaFreeHost(h_B); cudaFreeHost(h_C); cudaStreamDestroy(stream); cudaEventDestroy(start); cudaEventDestroy(stop); return 0; }
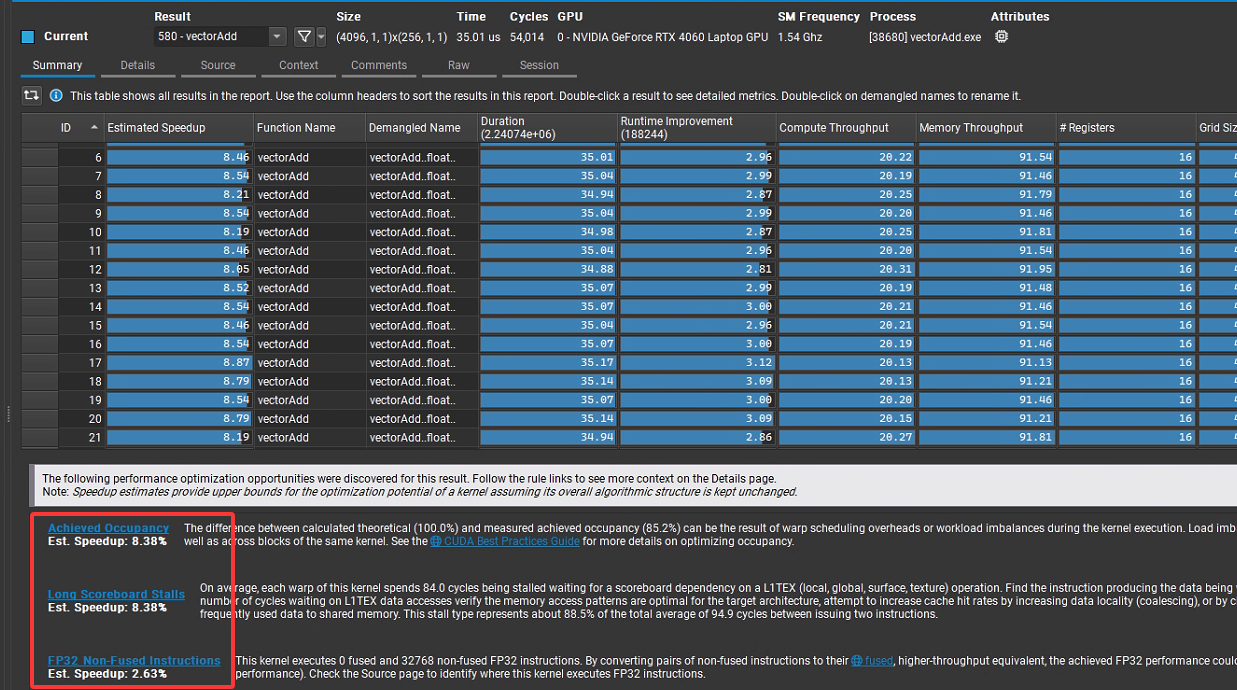
編譯后重新用Compute對程序進行分析,結果如下:
(3)kernel計算復雜度提高
把算術強度 (Arithmetic Intensity, FLOPs/Byte) 提高——讓每個線程在只讀一次 A[i], B[i] 的前提下,做大量浮點運算(比如成千上萬次 FMA),這樣瓶頸就從“顯存帶寬”轉移到“FP32 計算單元”,從而變成 compute-bound。源碼如下:


#include <stdio.h> #include <stdlib.h> #include <math.h> #include <cuda_runtime.h> //--------------------- 可調參數 --------------------- #define NUM_ELEMENTS 50000 #define TPB 256 // 每塊線程數 #define WORK_ITERS 4096 // 每個元素的計算迭代次數(越大越 compute-bound) // 說明:本 kernel 每次迭代做 3 次 FMA(每次 FMA=2 FLOPs),所以每迭代=6 FLOPs //--------------------------------------------------- // 簡單錯誤檢查宏 #define CUDA_CHECK(call) do { \ cudaError_t err__ = (call); \ if (err__ != cudaSuccess) { \ fprintf(stderr, "CUDA error %s at %s:%d\n", \ cudaGetErrorString(err__), __FILE__, __LINE__);\ exit(EXIT_FAILURE); \ } \ } while (0) // 原始向量加法(保留以便對照/測試) __global__ void vectorAdd(const float* A, const float* B, float* C, int n) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n) C[i] = A[i] + B[i]; } // 計算密集版:對每個元素執行大量 FMA(算力受限) __global__ void vectorAdd_computeHeavy(const float* A, const float* B, float* C, int n, int iters) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i >= n) return; // 只從全局內存取一次 float a = A[i]; float b = B[i]; // 累加器 float acc = 0.0f; // 讓編譯器展開一部分循環,提高指令吞吐 #pragma unroll 4 for (int k = 0; k < iters; ++k) { // 3 次 FMA;每次 FMA 記作 2 FLOPs acc = fmaf(a, b, acc); // acc += a*b acc = fmaf(acc, 1.000001f, 1e-7f); // 輕微擾動,避免常量折疊 b = fmaf(b, 0.9999993f, -1e-7f); // 變化寄存器值,避免被優化 } // 寫回一次 C[i] = acc; } // CPU 端復現實驗,驗證正確性(與 GPU 相同的算法) void computeHeavy_cpu(const float* A, const float* B, float* C, int n, int iters) { for (int i = 0; i < n; ++i) { float a = A[i]; float b = B[i]; float acc = 0.0f; for (int k = 0; k < iters; ++k) { acc = fmaf(a, b, acc); acc = fmaf(acc, 1.000001f, 1e-7f); b = fmaf(b, 0.9999993f, -1e-7f); } C[i] = acc; } } int main() { const int N = NUM_ELEMENTS; const size_t bytes = N * sizeof(float); // Host 內存 float *hA = (float*)malloc(bytes); float *hB = (float*)malloc(bytes); float *hC = (float*)malloc(bytes); float *hRef = (float*)malloc(bytes); if (!hA || !hB || !hC || !hRef) { fprintf(stderr, "Host malloc failed\n"); return 1; } // 初始化 for (int i = 0; i < N; ++i) { hA[i] = (float)i * 0.001f + 1.0f; hB[i] = (float)i * 0.002f + 2.0f; } // Device 內存 float *dA, *dB, *dC; CUDA_CHECK(cudaMalloc(&dA, bytes)); CUDA_CHECK(cudaMalloc(&dB, bytes)); CUDA_CHECK(cudaMalloc(&dC, bytes)); CUDA_CHECK(cudaMemcpy(dA, hA, bytes, cudaMemcpyHostToDevice)); CUDA_CHECK(cudaMemcpy(dB, hB, bytes, cudaMemcpyHostToDevice)); // 啟動配置 int blocks = (N + TPB - 1) / TPB; // 計時事件 cudaEvent_t start, stop; CUDA_CHECK(cudaEventCreate(&start)); CUDA_CHECK(cudaEventCreate(&stop)); printf("N=%d, TPB=%d, blocks=%d, WORK_ITERS=%d\n", N, TPB, blocks, WORK_ITERS); // --- 跑計算密集內核 --- CUDA_CHECK(cudaEventRecord(start)); vectorAdd_computeHeavy<<<blocks, TPB>>>(dA, dB, dC, N, WORK_ITERS); CUDA_CHECK(cudaEventRecord(stop)); CUDA_CHECK(cudaEventSynchronize(stop)); float msec = 0.f; CUDA_CHECK(cudaEventElapsedTime(&msec, start, stop)); // 統計 GFLOP/s: // 每元素 FLOPs = WORK_ITERS * 6(3 次 FMA × 2 FLOPs) const double flops_total = (double)N * WORK_ITERS * 6.0; const double gflops = (flops_total / (msec / 1e3)) / 1e9; // 統計內存訪問字節:每元素只做 2 讀 1 寫(各 4B),總 12B const double bytes_total = (double)N * 12.0; const double bw_GBps = (bytes_total / (msec / 1e3)) / 1e9; printf("Kernel time: %.3f ms\n", msec); printf("Throughput: %.2f GFLOP/s (flops=%g)\n", gflops, flops_total); printf("Memory BW (effective for kernel body): %.2f GB/s\n", bw_GBps); printf("Arithmetic Intensity: %.2f FLOPs/Byte\n", (WORK_ITERS * 6.0) / 12.0); // 拷回結果并驗證(CPU 端做同樣的運算) CUDA_CHECK(cudaMemcpy(hC, dC, bytes, cudaMemcpyDeviceToHost)); computeHeavy_cpu(hA, hB, hRef, N, WORK_ITERS); // 隨機抽查 int bad = -1; for (int i = 0; i < 10; ++i) { int idx = (i * 9973) % N; if (fabs(hC[idx] - hRef[idx]) > 1e-2f) { bad = idx; break; } } if (bad >= 0) { printf("Verification FAILED at %d: gpu=%f cpu=%f\n", bad, hC[bad], hRef[bad]); } else { printf("Verification PASSED (spot check)\n"); } // 清理 CUDA_CHECK(cudaFree(dA)); CUDA_CHECK(cudaFree(dB)); CUDA_CHECK(cudaFree(dC)); free(hA); free(hB); free(hC); free(hRef); CUDA_CHECK(cudaEventDestroy(start)); CUDA_CHECK(cudaEventDestroy(stop)); return 0; }
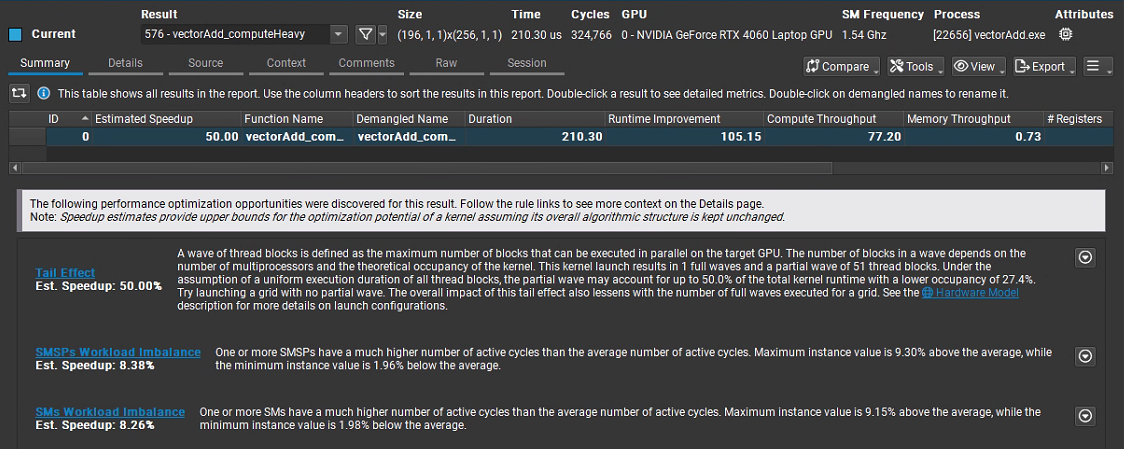
為了能使得Compute快速分析,代碼中又將向量個數改回50000,編譯后運行結果如圖所示,可見除了第一個我們已知原因的告警外,其他速度提升空間很有限:
2 界面詳解
2.1 Launch界面
如第1節中的圖1所示,圖中上半部分內容顯而易見不再進行說明,以下對下半部分內容進行說明。
1. Activity
支持四種分析模式:
Profile:常規的性能分析模式,使用命令行分析器(command line profiler ),會序列化所有 GPU 工作負載(即按順序分析 GPU 上的任務,便于精準采集每個 Kernel 等的性能數據 );“Attach is not supported for this activity” 表示該模式不支持 Attach 方式,只能通過 Launch 啟動程序分析;“Supported APIs: CUDA, OptiX” 說明支持分析基于 CUDA(NVIDIA 通用并行計算架構)和 OptiX(光線追蹤引擎)開發的程序。
Interactive Profile:交互式分析模式,相比常規 Profile ,能讓你在分析過程中更靈活地探索數據,比如交互式查看不同 Kernel、不同指標的性能表現,進行實時的篩選、對比等操作。
Occupancy Calculator:專注于計算 GPU 內核(Kernel)的占用率相關指標,像活躍線程塊數量、 warp 調度情況等,幫助你分析硬件資源利用是否充分,了解 Kernel 啟動配置(如線程塊大小等)對資源占用的影響 。
System Trace:系統級追蹤模式,不僅關注 CUDA 程序本身,還會采集系統層面的事件,比如 CPU 線程調度、GPU 與 CPU 之間的數據傳輸時序等,用于分析程序在整個系統環境中與其他進程、硬件交互的性能瓶頸 。
2. 分析具體配置
這里僅介紹最常用的Profile模式下的具體配置。
Output File:設置性能分析結果文件的輸出路徑和命名規則,如D:\work\cuda\cuda-samples-12.5\bin\win64\Release\result%i,%i占位符可在生成分析結果時對report文件自動添加遞增的標號,防止覆蓋上一次的分析結果文件。
Force Overwrite:設置是否強制覆蓋已存在的輸出文件,選 Yes 則當輸出路徑下有同名文件時直接覆蓋,選 No 則會提示文件已存在,需手動處理避免覆蓋,如果在之前輸出文件路徑最后以增加%i,則該配置可忽略。
Target Processes:選擇要分析的目標進程范圍,All 會分析所有與指定應用程序相關聯的進程,這不僅包括你主打的 CUDA 應用程序進程本身,還可能涵蓋一些輔助進程,例如在應用程序運行期間啟動的子進程等;這里還有另外一個選項Application Only,此選項下,Nsight Compute只會聚焦于指定的應用程序可執行文件所對應的主進程,會忽略掉在應用程序運行過程中啟動的其他輔助進程,僅僅針對主應用程序的 GPU 活動、CPU - GPU 交互等進行性能分析。
Replay Mode:重放模式,這里有4種選項:
Application Replay Match:應用程序重放匹配方式,Grid 以線程網格(Grid,CUDA 中 Kernel 啟動時的線程組織頂層結構 )為單位進行重放匹配,用于關聯重放數據和原始程序的網格執行邏輯 。
Application Replay Buffer:應用程序重放緩沖區設置,File表示將重放相關的數據暫存到文件中,也可選擇其他存儲方式(如內存等,不同選項適配不同場景和性能需求 ),影響重放過程中數據的存儲和讀取效率 。
Application Replay Mode:應用程序重放模式,Strict 表示嚴格按照程序原始執行順序、參數等進行重放,盡可能還原真實運行場景來分析性能,保證分析數據的準確性對應原始執行邏輯 。
Graph Profiling:圖形分析配置,Node 以節點(可理解為 Kernel 或相關計算單元在性能分析圖中的節點表示 )為單位進行圖形化性能分析,用于構建、展示程序性能的拓撲結構,輔助識別性能關鍵路徑 。
Command Line:顯示最終執行性能分析的命令行內容,工具會根據你前面配置的各項參數,拼接成完整的命令行指令,用于調用底層的分析器(如 ncu.exe 等 NVIDIA 性能分析命令行工具 )執行分析。
2.2 Result界面
1. Summary
這部分之前已經介紹過,不再詳細說明。
2. Details
該部分內容最為全面,下面進行詳細說明:
(1)GPU Speed Of Light Throughput(GPU光速吞吐量,也稱為SOL分析)
含義:提供SM和內存利用率的概覽,快速識別主要瓶頸。
用途:作為性能分析的起點,判斷是計算還是內存受限。
場景:快速診斷程序性能瓶頸。
下圖是最原始vectorAdd程序的分析結果,從圖中柱狀圖可以直觀的看出,Compute(SM) Throughput(計算吞吐量)代表 GPU 流多處理器(SM, Streaming Multiprocessors )計算資源的利用率,數值是 “實際計算性能 / 理論最大計算性能” 的百分比僅為9.21%,說明計算資源只用了不到10%,遠沒有觸達GPU理論計算上限,計算資源還有較高的挖掘潛力。而對于Memory Throughput [%](內存吞吐量),即 GPU 內存子系統(含顯存、緩存等)的帶寬利用率,是 “實際內存帶寬 / 理論最大內存帶寬” 的百分比,在圖中是41.11%,雖然內存帶寬用了四成左右,但是也還有進一步優化空間。優化時首先應從這兩個指標入手,其他指標在更以進一步優化時考慮。從這兩個指標來看,可以認為memory throughput dominated,即計算受限,說明程序卡在GPU計算能力沒有跑滿,Kernel里計算邏輯簡單,線程并行度不夠,SM上的CUDA Core沒有被充分利用,導致計算吞吐量上不去。如果要對該程序進行優化,方向就是增加kernel函數中的計算復雜度,同時增大向量規模,前者能使得CUDA Core盡可能的”忙碌“起來,后者會使得內存訪問也變得更加頻繁起來。

作為對比,可以看下上一節最后一個程序相應的分析結果,由于增加了kernel函數中計算復雜度,導致計算吞吐量顯著增大,相對的內存訪問反而更加”清閑“,導致其吞吐量進一步降低。需要說明的是這種情況仍是”計算受限“模型,因為在存儲很清閑的情況下,”計算“仍沒有被”喂飽“,所以是計算受限。

(2)PM Sampling(性能監控采樣)
含義:通過性能監控 (Performance Monitoring) 采樣,收集硬件計數器數據。
用途:提供實時性能數據,分析硬件級行為。
場景:深入分析硬件性能瓶頸。
以圖中Average Active Warps Per Cycle指標為例,第2列中90.77 warp表示,在某個Cycle內平均活躍Warps達到kernel運行期間的最高水平90.77個,0表示縱軸最小值為0,從圖中還可看出在kernel運行的不到4us內各個時刻的平均活躍Warp數是不同的,大體上成正態分布(兩頭少,中間多),對于這里使用的RTX 4060來說,maxThreadsPerMultiProcessor=1536,即每個周期活躍warp最大個數為1536/32=48,這里統計值竟然是90.77,暫時沒搞清楚是怎么回事兒。
Total Active Warps Per Cycle是統計整個GPU范圍內的活躍warp數1.09k,理論上RTX 4060中SM數是24,所以總的活躍warp數為24*48=1152,能看的出這里的值已經非常接近理論值,說明在warp調度層面已經達到較高的GPU利用率。

Blocks Launched = 144,是在采樣周期內啟動的block數,從圖中可以看出block集中在早期啟動,block啟動后持續執行,不需要頻繁啟動新block。
SM Active Cycles = 1.55k cycle,是對所有 SM 處于活躍狀態的時鐘周期進行統計和累加,在 GPU 運行內核(Kernel)時,每個 SM 都有獨立的調度器,負責管理線程束(warp)的執行。當 SM 內有可執行的 warp(比如 warp 沒有因為等待內存數據、資源沖突等原因被阻塞 ),并且調度器給這些 warp 分配指令,讓它們在計算單元(如 CUDA Core、FMA 單元等)上執行時, 這個 SM 就處于活躍狀態,此時會記錄一個活躍時鐘周期,1.55k cycle是一個采樣周期1us內活躍時鐘cycle數。
Executed IPC Active = 366m inst/cycle,這里的 “m” 代表 “milli”(千分之一),所以366m = 0.366,在流多處理器(SM)處于活躍狀態的每個周期內,平均執行了 0.366 條指令,這和Ada Lovelace 架構的理論 IPC(每周期指令數)約 4 - 5 左右相差甚遠,所以說明從指令執行層面來說還有巨大優化空間。
再接下來,和SM相關指標:SM Throughput(流多處理器吞吐量)、SM ALU Pipe Throughput(SM整數和邏輯運算流水線吞吐量)、SM FMA Light Pipe Throughput(SM輕量浮點乘加流水線吞吐量,FP32)、SM FMA Heavy Pipe Throughput(SM重量浮點乘加流水線吞吐量,FP64)、SM Tensor Pipe Throughput(SM 張量核心流水線吞吐量)的值都比較低,如SM Throughput(SM 吞吐量)的實際數值最高僅約為 9.14%,遠未達到左側顯示的 100%,這表明SM的大量計算資源處于閑置狀態,沒有被利用起來。

再之后的DRAM顯存雖然也沒有達到100%,但是在部分采樣周期內已經達到88%,相比計算資源來說,利用率已經相對充分。
 再接下來的指標由于沒有采樣信息不再進行詳細說明。
再接下來的指標由于沒有采樣信息不再進行詳細說明。
(3)Compute Workload Analysis(計算工作負載分析)
含義:分析 SM 的計算工作負載,包括指令吞吐量、浮點運算效率等。
用途:評估 GPU 計算資源的利用率,識別計算瓶頸。
場景:優化矩陣計算或科學計算內核。
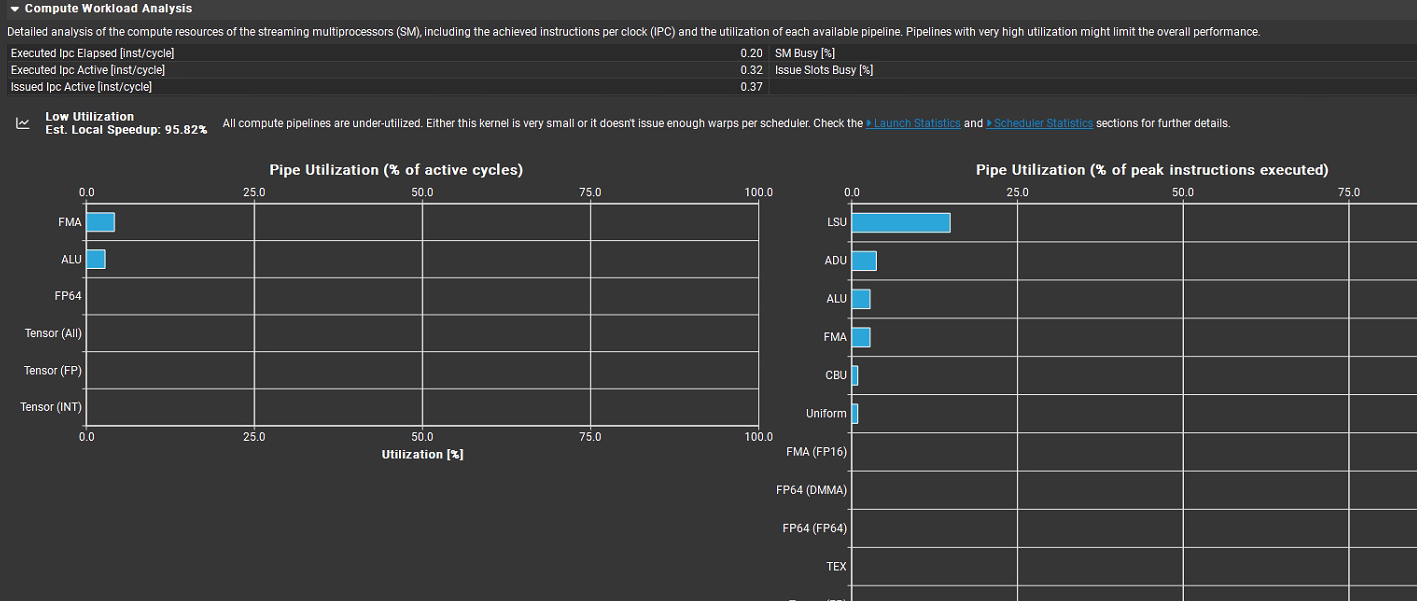
最上面核心指標:
Executed IPC Elapsed = 0.20 inst/cycle:在整個內核運行期間(包含空閑周期),平均每周期僅執行 0.2 條指令。
Executed IPC Active = 0.32 inst/cycle:在活躍周期內,每周期執行 0.32 條指令。對比 Ada Lovelace 架構理論峰值 ~8,這個利用率非常低。
Issued IPC Active = 0.37 inst/cycle:活躍周期內每周期發射(issue)的指令數是 0.37。和上面的 0.32 很接近,說明 pipeline 本身沒有嚴重瓶頸,問題主要在并行度/指令密度不足。
SM Busy [%] = 0.20:SM 在總運行時間中只有 20% 的時間在忙碌,其余 80% 在空閑。
Issue Slots Busy [%] = 0.32:warp scheduler 的 issue 槽位利用率約 32%。調度器資源大部分時間閑置。
中間提示信息:
“所有計算管道都未充分利用(All compute pipelines are under-utilized)”,推測原因是 “內核非常小,或者每個調度器發出的 warp 數量不足”,并建議查看 “Launch Statistics” 和 “Scheduler Statistics” 部分獲取更多細節。同時預估本地加速比(Est. Local Speedup)為 95.82%,說明有很大的性能提升空間。
下方 Pipe Utilization 圖表:
左側是活躍周期占比,FMA(浮點乘加)、ALU(整型算術)利用率只有個位數,Tensor Core、FP64、其他計算單元幾乎完全空閑,說明這個 kernel 的算術指令極少。
右側是峰值指令執行占比,LSU(加載 / 存儲單元,內存訪問管線)利用率相對最高,ADU、ALU、FMA 等有少量利用,其余如 CBJ(條件分支)、Uniform(統一操作)、各類 FP64 及 TEX(紋理單元)等利用率極低。說明這個 kernel 主要在做訪存,幾乎沒有算術計算。
(4)Memory Workload Analysis(內存工作負載分析)
含義:分析內存工作負載,涵蓋全局、共享、紋理和本地內存訪問。
用途:識別內存訪問瓶頸,如緩存未命中或非合并訪問。
場景:優化內存訪問模式,減少全局內存延遲。
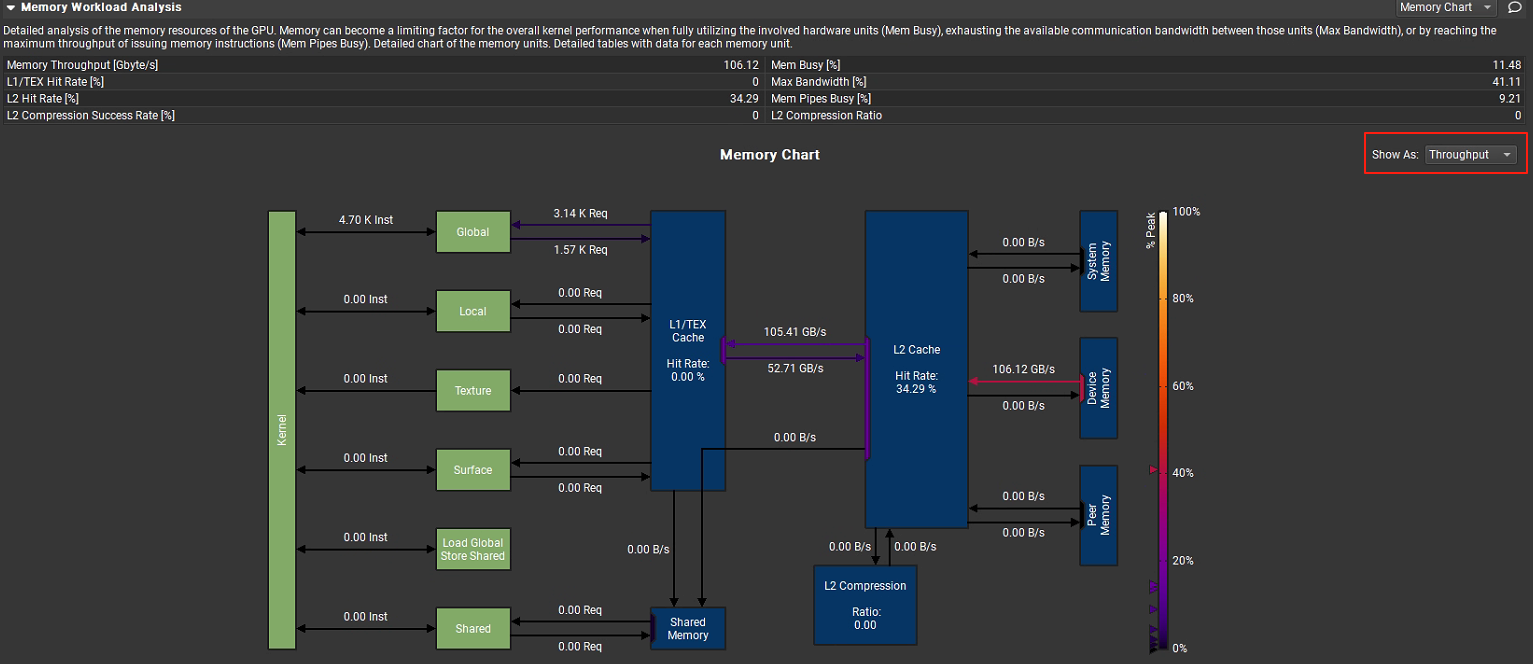
用于分析 GPU 內存資源的使用情況,當涉及內存硬件單元(Mem Busy)已經完全使用,各單元之間的最大通信寬帶(Max Bandwidth)已經完全耗盡或者發射內存指令的管道(Mem Pipes Busy)已經達到最大吞吐量時,內存可能會成為整體kernel性能的限制因素。相關指標統計如下:
Memory Throughput [Gbyte/s]:106.12,即內存吞吐量為 106.12GB / 秒。
L1/TEX Hit Rate [%]:0.0,L1 緩存或紋理緩存的命中率為 0,說明從 L1 緩存或紋理緩存中獲取數據的成功率極低。
L2 Hit Rate [%]:34.29,L2 緩存命中率為 34.29%,有一定比例的數據能從 L2 緩存命中。
Mem Busy [%]:11.48,內存總線忙碌程度為 11.48%,表示內存總線有 11.48% 的時間處于忙碌狀態。
Max Bandwidth [%]:41.11,最大帶寬利用率為 41.11%,說明內存帶寬還有較大的利用空間。
Mem Pipes Busy [%]:9.21,內存管道忙碌程度為 9.21%,內存管道的使用并不充分。
L2 Compression Success Rate [%]:0,L2 緩存壓縮成功率為 0,沒有數據通過壓縮節省空間。
L2 Compression Ratio:0,L2 緩存壓縮比為 0,同樣說明沒有進行有效的壓縮。
圖中下方的內存圖表直觀的顯示各關鍵部件之間的通信數據吞吐量,還可以通過左側下拉列表切換查看總的傳輸大小。
(5)Scheduler Statistics(調度器統計)
含義:統計 warp 調度器行為,分析調度效率和暫停原因。
用途:定位調度瓶頸,如分支發散或資源競爭。
場景:優化 warp 調度,減少分支發散。
用于分析 GPU 指令調度器的工作情況,每個調度器維護一個 warp(線程束)池,可從中發射指令。warp 池的上限(Theoretical Warps)由啟動配置限制。每個周期調度器會檢查池中已分配 warp 的狀態(Active Warps),未停滯的活躍 warp(Eligible Warps)可發射下一條指令,調度器從符合條件的 warp 中選擇一個來發射一條或多條指令(Issued Warp)。若周期內無符合條件的 warp,發射槽會被跳過,無指令發射,大量跳過發射槽意味著延遲隱藏效果差。

上方核心指標
Active Warps Per Scheduler = 8.78:每個調度器平均有 ~8.8 個活躍 warp 在池子里,理論上限是 12 warp per scheduler,所以活躍 warp 數量還算可觀(~73% 滿載)。
No Eligible = 91.01:有91.01%的周期內沒有符合條件的warp。
Eligible Warps Per Scheduler = 0.19:在這 8.78 個活躍 warp 里,平均只有 0.19 個 warp 處于“可立即發射指令”狀態,換句話說,大多數 warp 雖然活躍,但被 stall(等待數據/資源) 卡住了。
One or More Eligible = 8.99:僅有 8.99% 的周期內有一個或多個符合條件的 warp。
Issued Warp Per Scheduler = 0.09:每個調度器每周期平均發射 0.09 個 warp,相當于 11.1 個周期才發射一次指令,調度效率非常低。
發射槽利用率(Issue Slot Utilization)
每個調度器每周期能發射一條指令,但當前內核每個調度器每 11.1 個周期才發射一條指令,這導致硬件資源未充分利用,性能不是最優。每個調度器最多可處理 12 個 warp,當前內核每個調度器平均分配 8.78 個活躍 warp,但每周期平均只有 0.19 個符合條件的 warp。沒有符合條件的 warp 時,發射槽閑置。預估本地加速比(Est. Local Speedup)為 58.89%,說明有較大性能(59%)提升空間。Nsight Compute建議通過查看 “Warp State Statistics” 和 “Source Counters” 部分,減少活躍 warp 的停滯時間,以增加符合條件的 warp 數量。
調度器圖表解讀(Warps Per Scheduler)
GPU Maximum Warps Per Scheduler = 12:硬件上限,每個調度器最多可管理 12 個 warp。
Theoretical Warps Per Scheduler = 12:根據 kernel 配置(block 數、線程數),理論上最多能達到 12。
Active Warps Per Scheduler ≈ 8.78:實際運行中有 ~9 個 warp 活躍。
Eligible Warps Per Scheduler ≈ 0.19:活躍 warp 里,幾乎都在等待(數據依賴、訪存、同步等),只有不到 1 個 warp 真正 ready。
Issued Warp Per Scheduler ≈ 0.09:平均每 10+ 個周期才發射一次 warp,調度利用率極低。
綜合分析,Warp并行度足夠(8.78/12),說明block/warp數量是夠的,但是幾乎所有warp都在等待,從現象上看像是訪存受限(memory-bound),實際上是因為kernel計算量太小,使得每次執行過程中好像時間都花費在等內存就位。
(6)Warp State Statistics
含義:詳細統計 warp 狀態(如等待內存、分支發散、活躍)。
用途:分析線程執行效率,定位 warp 級瓶頸。
場景:優化線程同步和分支邏輯。
用于分析 GPU 中 warp(線程束)在 kernel(內核)執行期間的狀態,以找出性能瓶頸,相關信息如下:

核心指標
Warp Cycles Per Issued Instruction [cycle]:每條已發射指令對應的 warp 周期數,為97.67。該值越高,說明指令間延遲越大,需要更多并行 warp 來隱藏延遲。
Warp Cycles Per Executed Instruction [cycle]:每條已執行指令對應的 warp 周期數,為 115.61,反映指令執行的整體延遲情況。
Avg. Active Threads Per Warp:每個 warp 中平均活躍線程數,為 32,說明 warp 內線程基本都處于活躍狀態。
Avg. Not Predicated Off Threads Per Warp:每個 warp 中平均未被謂詞關閉的線程數,為 30.12,表明大部分線程未因謂詞判斷而不執行。
主要停滯類型
Stall Long Scoreboard:Long Scoreboard 表示 warp 在等長延遲內存操作(L1TEX:global/local/texture/surface)的數據依賴,也就是發起過 load/store 之后,結果沒回來,scoreboard 把后續依賴指令卡住而停滯 69.4 個周期,這類停滯占總發射指令平均周期(97.7 周期)的約 71.0%。
Stall IMC Miss:因 IMC(內存控制器)未命中導致的停滯,有一定占比,需優化內存訪問以提升緩存命中率。
Stall Wait、Stall No Instruction、Stall Short Scoreboard 等:這些停滯類型占比較小,對整體性能影響相對有限,但也可結合具體場景優化(如檢查指令調度、減少不必要的等待等)。
和上節內容聯系起來,Active Warps Per Scheduler為8.78,表示調度器運行過程中,平均有8.78個Warps處于活躍狀態,而Warp Cycles Per Issued Instruction為97.67表明同一個Warp每發射一次需要97.67個cycle,即在97.67個cycle內要保證8.78個Warps處于活躍,每97.67/8.78=11.1個cycle發射一次Warp才能保證這樣的活躍Warp數,這個和Issued Warp Per Scheduler ≈ 0.09是可以對應上的。
(7)Instruction Statistics
含義:統計 SASS(底層 Shader Assembly)指令的分布和執行情況。
用途:分析指令類型(如算術、內存操作)和執行頻率,定位低效指令。
場景:優化指令級性能,減少冗余操作。

核心指標
Executed Instructions [inst]:執行的指令總數,為 26,656 條。
Issued Instructions [inst]:發射的指令總數,為 31,552 條(發射數多于執行數,可能因分支預測、指令回滾等原因)。
Avg. Executed Instructions Per Scheduler [inst]:每個調度器平均執行的指令數,為 277.67 條。
Avg. Issued Instructions Per Scheduler [inst]:每個調度器平均發射的指令數,為 328.67 條。
指令分布(Executed Instruction Mix)
IMAD:執行數量最多(約 6000+ 條),屬于整數乘加類指令,是內核的核心計算指令之一。
S2R:特殊寄存器讀取指令,數量約 3000+ 條,用于線程與特殊寄存器(如線程 ID、塊 ID 等)的交互。
MOV:數據移動指令,數量約 3000+ 條,用于寄存器間的數據傳遞。
LDG:全局內存加載指令,數量約 3000+ 條,負責從 GPU 全局內存讀取數據。
FADD:單精度浮點加法指令,數量約 3000+ 條,是浮點計算的核心指令。
EXIT:線程退出指令,數量約 3000+ 條,用于線程執行完畢后的退出操作。
ULDC、STG、ISETP:執行數量相對較少,分別涉及常量內存加載、全局內存存儲、整數比較等操作。
(8)NVLink Topology
含義:顯示 NVLink 拓撲結構,描述多 GPU 間的互連配置。
用途:幫助理解系統拓撲,優化 GPU 間數據傳輸路徑。
場景:規劃多 GPU 系統的數據分配。
(9)NVLink Tables
含義:提供 NVLink 性能的詳細表格數據,補充 Nvlink Section。
用途:為 NVLink 性能提供結構化數據,便于分析。
場景:導出 NVLink 數據進行離線分析。
(10)NUMA Affinity
含義:分析 NUMA(非均勻內存訪問)親和性,評估內存分配與 GPU/CPU 親和性。
用途:在多 GPU 或 CPU-GPU 系統中,優化內存分配以降低訪問延遲。
場景:優化 DGX 或服務器環境中的內存親和性。
(11)Launch Statistics
啟動統計(Launch Statistics)用于分析 GPU 內核啟動配置的相關信息,以下是詳細解讀:
核心配置參數
這些參數定義了內核啟動時的資源分配和并行結構:
Grid Size:內核網格大小,值為 196,表示整個計算任務被劃分為 196 個 “塊(block)” 的集合。
Registers Per Thread [register/thread]:每個線程使用的寄存器數量,為 16,寄存器是 GPU 線程的快速存儲資源,該值影響線程束(warp)的調度和資源占用。
Block Size:每個塊的大小,為 256,即每個塊包含 256 個線程。
Threads Per Thread:表述可能有誤,結合上下文應為 Threads Per Block(每個塊的線程數),與 Block Size 一致(256)。
Waves Per SM:每個流式多處理器(SM)上的 “波(wave)” 數量,為 1.36。“波” 指 SM 上可并行執行的塊的最大數量,該值反映 SM 的并行度利用情況。
Uses Green Context:是否使用 “Green Context”(一種特殊的執行上下文,通常與低延遲、高優先級任務相關),此處未明確顯示具體值,需結合工具邏輯判斷(若為 true 則啟用)。
# SMs [SM]:GPU 包含的流式多處理器數量,為 24,SM 是 GPU 的核心計算單元。
緩存與共享內存配置
這些參數控制 GPU 內存子系統的資源分配:
Function Cache Configuration:函數緩存配置,為 CachePreferNone,表示函數緩存策略為 “不偏好特定緩存”(可根據需求調整為偏好 L1 / 紋理緩存等)。
Static Shared Memory Per Block [byte/block]:每個塊的靜態共享內存大小,為 0,靜態共享內存是編譯時確定的塊內共享內存。
Dynamic Shared Memory Per Block [byte/block]:每個塊的動態共享內存大小,為 0,動態共享內存是運行時分配的塊內共享內存。
Driver Shared Memory Per Block [byte/block]:驅動層為每個塊分配的共享內存大小,為 1.02 字節(通常由驅動自動管理)。
Shared Memory Configuration [Kbyte]:共享內存總配置大小,為 16.38 KB,反映塊可使用的共享內存總容量。

(12)Occupancy
含義:評估 SM 的占用率,即活躍 warp 數與最大 warp 數的比例。
用途:分析線程并行度,優化資源利用。
場景:調整塊大小以提高 SM 占用率。
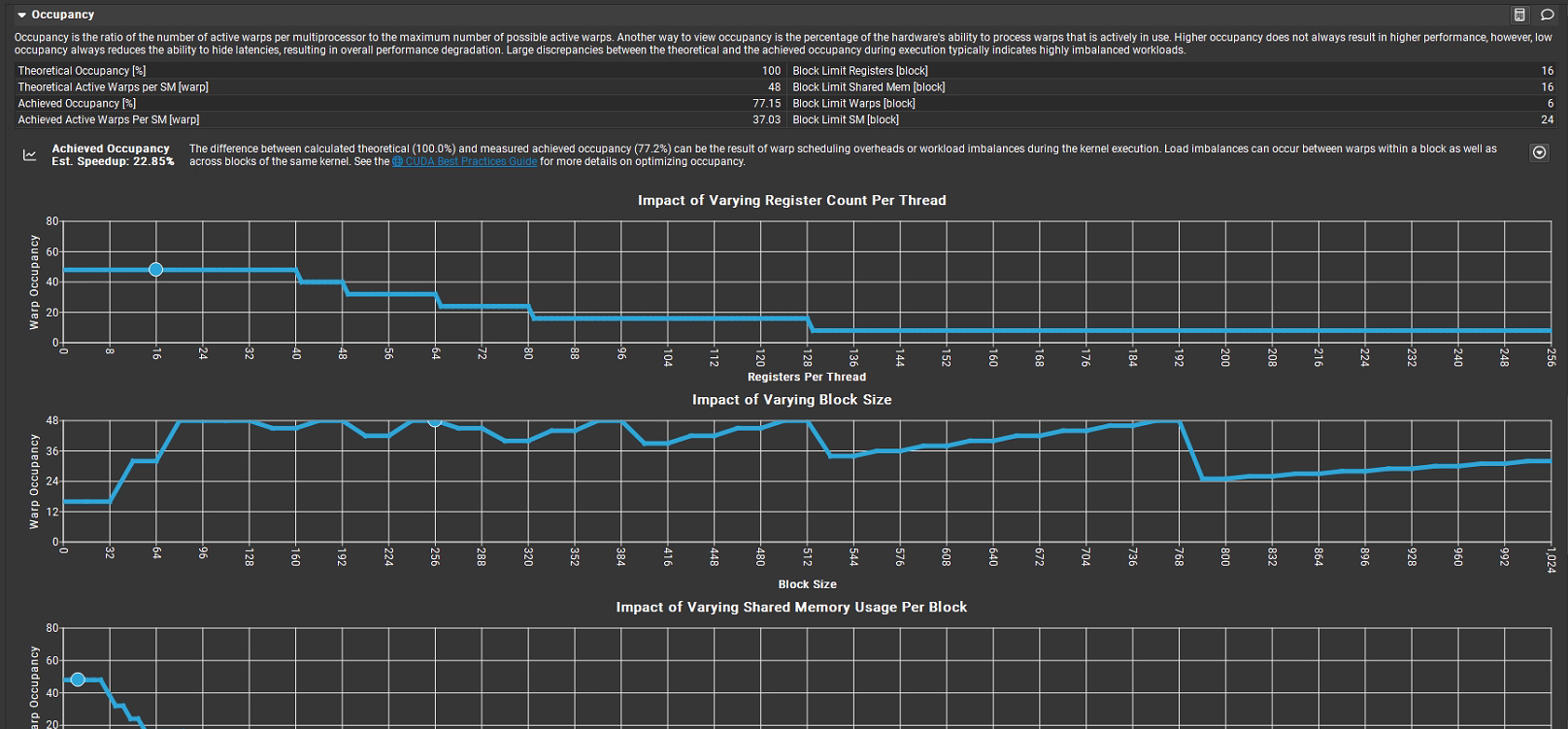
占用率是每個多處理器的活躍線程束數與最大可能活躍線程束數的比值,反映硬件處理線程束能力的實際使用率:
Theoretical Occupancy [%]:理論占用率為 100%,表示硬件資源(寄存器、共享內存等)理論上可支持的最大線程束并行度。
Theoretical Active Warps per SM [warp]:每個 SM 理論上可容納的活躍線程束數,為 48。
Achieved Occupancy [%]:實際達到的占用率為 77.15%,說明實際活躍線程束數僅為理論值的約 77%。
Achieved Active Warps per SM [warp]:每個 SM 實際活躍的線程束數,為 37.03(約為 48 × 77.15%)。
理論占用率(100%)與實際占用率(77.15%)的差異,可能源于線程束調度開銷或內核執行時的負載不均衡(Block 內或 Block 間的負載差異)。
資源限制說明
右側列出了不同資源對線程塊(Block)的限制:
Block Limit Registers [block]:寄存器限制下,每個 Block 最多支持 16 個線程束。
Block Limit Shared Mem [block]:共享內存限制下,每個 Block 最多支持 16 個線程束。
Block Limit Warps [block]:綜合限制下,每個 Block 最多支持 6 個線程束。
Block Limit SM [block]:SM 資源限制下,每個 SM 最多支持 24 個 Block。
參數影響圖表
界面包含三張圖表,展示不同參數對占用率的影響:
Impact of Varying Register Count Per Thread:橫軸為 “每個線程的寄存器數量”,縱軸為 “線程束占用率”。隨著寄存器數增加,占用率在某一閾值后驟降(如寄存器數 > 40 時,占用率從約 50% 快速下降),說明寄存器過度使用會嚴重限制線程束并行度。
Impact of Varying Block Size:橫軸為 “Block 大小”,縱軸為 “線程束占用率”。Block 大小在 96–768 范圍內時,占用率維持在較高水平(約 40–50%);當 Block 過大(如 > 768),占用率驟降,說明 Block 大小需合理選擇以平衡并行度與資源消耗。
Impact of Varying Shared Memory Usage Per Block:橫軸為 “每個 Block 的共享內存使用量”,縱軸為 “線程束占用率”。共享內存使用量增加時,占用率快速下降(如從 0 增加到一定值時,占用率從約 50% 降至接近 0),說明共享內存過度使用會極大限制線程束并行度。
(13)GPU and Memory Workload Distribution
含義:分析工作負載在 SM 間的分布,評估負載均衡性。
用途:確保所有 SM 均勻分配工作,最大化 GPU 利用率。
場景:優化線程塊分配,平衡多 SM 負載。
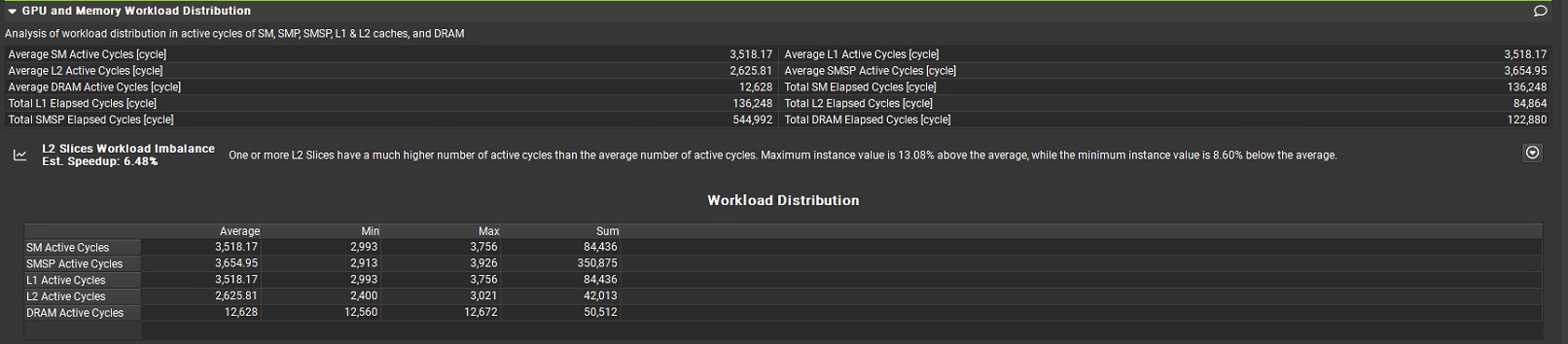
Average SM Active Cycles [cycle]:每個流式多處理器(SM)的平均活躍周期,為 3,518.17 周期,SM 是 GPU 的核心計算單元。
Average L1 Active Cycles [cycle]:L1 緩存的平均活躍周期,為 3,518.81 周期,L1 是核心專用或SM專用。每個GPU SM都有自己私有的L1緩存。
Average L2 Active Cycles [cycle]:L2 緩存的平均活躍周期,為 2,625.81 周期,L2 是共享緩存,所有GPU SM共享一個統一的L2緩存,L1訪問速度快于L2快于DRAM。
Average SMSP Active Cycles [cycle]:流式多處理器子系統(SMSP,包含 SM 及周邊控制單元)的平均活躍周期,為 3,654.95 周期。
Average DRAM Active Cycles [cycle]:DRAM(顯存)的平均活躍周期,為 12,628 周期,DRAM 是 GPU 的大容量內存。
Total SM Elapsed Cycles:SM總用時12,628 cycles (這是基準時間)
Total L1 Elapsed Cycles:L1總用時136,248 cycles。
Total L2 Elapsed Cycles:84,864 cycles。
Total SMSP Elapsed Cycles:544,992 cycles。
Total DRAM Elapsed Cycles:122,880 cycles。
(14)Source Counters
含義:將性能指標映射到源代碼行,分析代碼級性能。
用途:幫助開發者定位特定代碼行的性能瓶頸。
場景:優化特定 CUDA 內核代碼。

這部分可以結合下一節Source進行分析,從圖中左側可知0x200c64cd0對應指令等待時間最長,對應源碼A[idx] + B[idx]即浮點數加法指令,圖中右側部分執行指令最多次數的指令,這里1568=50176/32,50167是總的線程數,32是每個warp中包含線程數,每個warp中線程指令并行執行,相當于對該指令僅需發射 1 次 ,即所謂SIMD(Single Instruction, Multiple Data),相當于僅執行“一次”指令,所以總共執行1568次指令。
3. Source
功能概述:該頁面主要展示內核代碼的原始視圖,并將性能數據與代碼行進行關聯。
具體作用:
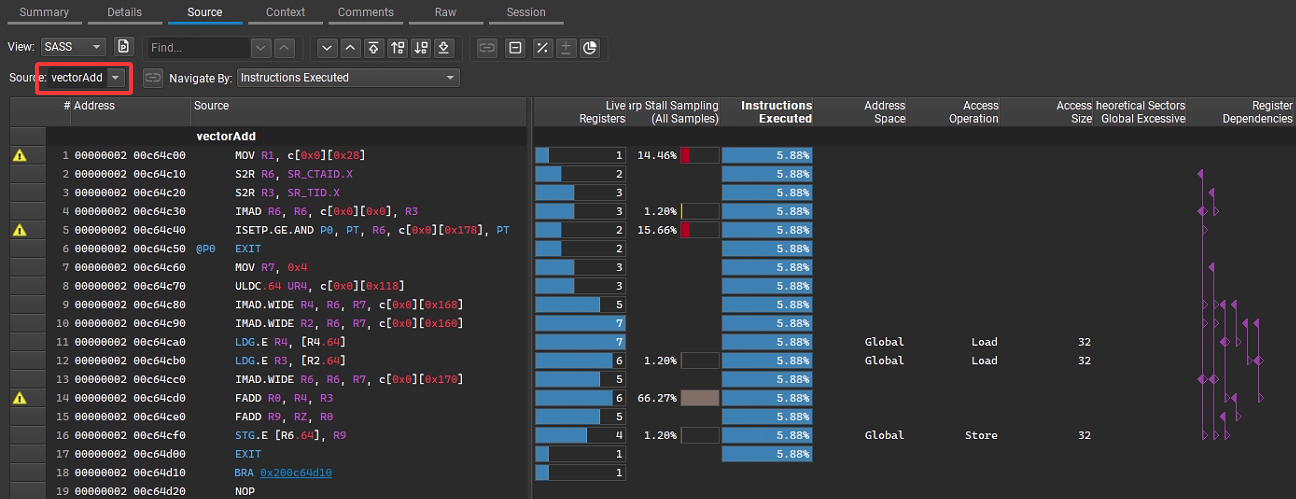
核函數vectorAdd對應PTX匯編指令解析如下:
MOV R1, c[0x0][0x28] 加載線程塊數量等核配置參數(輔助后續索引計算)。 S2R R6, SR_CTAID.X 讀取當前線程塊的 blockIdx.x(線程塊在網格中的 X 維度索引)。 S2R R3, SR_TID.X 讀取當前線程的 threadIdx.x(線程在線程塊中的 X 維度索引)。 IMAD R6, R6, c[0x0][0x0], R3 計算全局索引 i = blockIdx.x * blockDim.x + threadIdx.x(c[0x0][0x0] 存儲 blockDim.x)。 ISETP.GE.AND P0, PT, R6, c[0x0][0x178], PT 判界:比較 i(R6)與 numElements(c[0x0][0x178] 存儲 numElements),若 i >= numElements,則標記分支條件 P0 為真。 @P0 EXIT 若 P0 為真(即 i >= numElements),直接退出線程,跳過后續計算(對應核函數的 if (i < numElements) 不成立的分支)。 MOV R7, 0x4 準備后續內存訪問的偏移量(0x4 對應 float 類型的字節數,因為 float 占 4 字節)。 ULDC.64 UR4, c[0x0][0x118] 加載數組 A 的基地址到寄存器 UR4(UR 是統一寄存器,用于地址計算)。 IMAD.WIDE R4, R6, R7, UR4 計算 A[i] 的地址:A 的基地址 UR4 + 索引 i × 4 字節(R7=0x4)。 IMAD.WIDE R2, R6, R7, c[0x0][0x160] 計算 B[i] 的地址:B 的基地址(c[0x0][0x160]) + 索引 i × 4 字節。 LDG.E R4, [R4,64] 加載 A[i] 的值到寄存器 R4(LDG 是全局內存加載指令)。 LDG.E R3, [R2,64] 加載 B[i] 的值到寄存器 R3。 IMAD.WIDE R6, R6, R7, c[0x0][0x170] 計算 C[i] 的地址:C 的基地址(c[0x0][0x170]) + 索引 i × 4 字節。 FADD R0, R4, R3 執行浮點加法:A[i] + B[i],結果存在 R0。 FADD R9, RZ, R0 執行 0.0f + (A[i] + B[i])(RZ 是值為 0 的寄存器),對應核函數的 +0.0f。 STG.E [R6,64], R9 將結果存儲到 C[i] 的地址(全局內存寫操作)。 EXIT 線程正常退出(對應 if 分支執行完畢)。
4. Context
功能概述:提供當前內核分析的上下文信息,幫助理解內核執行的環境和條件。
具體作用:
5. Comments
功能概述:用于添加和查看關于當前性能分析報告的注釋信息,方便記錄分析過程中的想法、發現和結論。
具體作用:
6. Raw
功能概述:呈現原始的性能數據,提供最基礎、未經過多處理和匯總的數據記錄。
具體作用:

7. Session
功能概述:管理和展示性能分析會話相關的信息,包括會話的創建時間、保存狀態等。
具體作用:
3 命令行使用
3.1 基本使用
通過命令行啟動ncu,基本語法如下:
ncu [options] <application> [application arguments]
如下圖在命令行下對vectorAdd.exe可執行程序進行分析,ncu會實時給出解析結果:
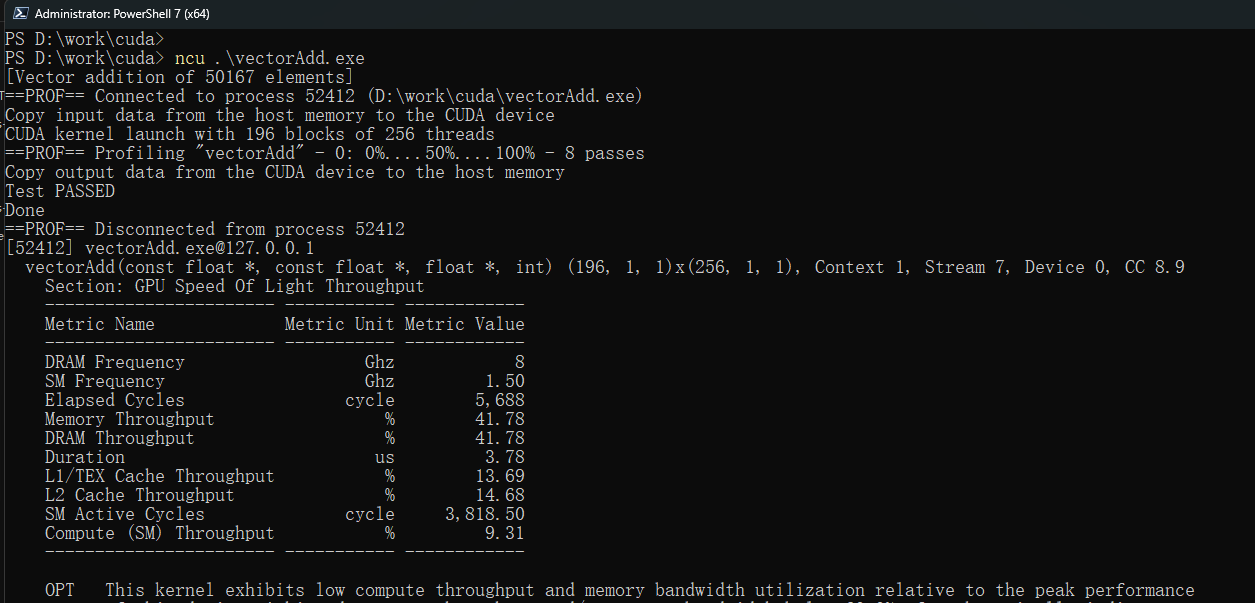
該基本命令只是輸出簡要的解析信息,要想詳細分析可執行程序,還需要傳入不同的參數來實現。
3.2 常用選項
1. 指定輸出文件
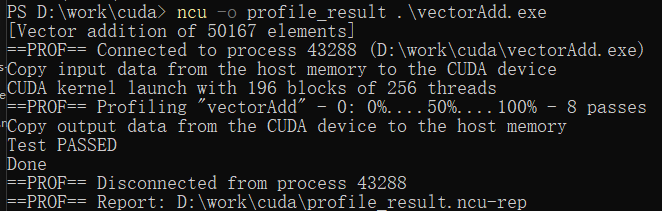
使用-o選項將分析結果保存到文件:
ncu -o profile_result .\vectorAdd.exe
2. 詳細報告
使用--print-details all選項生成詳細報告:
ncu --print-details all .\vectorAdd.exe
3. 指定內核
使用--kernel-name選項分析特定內核:
ncu --kernel-name vectorAdd .\vectorAdd.exe
4. 性能指標
使用--metrics選項指定性能指標:
ncu --metrics gpu__time_duration.sum .\vectorAdd.exe
5. 內存帶寬分析
使用--section MemroyWorkloadAnalysis分析內存帶寬:
ncu --section MemoryWorkloadAnalysis .\vectorAdd.exe
其實可以用--help查看所支持參數詳細用法,另外在文章最開始的圖1中最下端其實GUI工具也已經給出了當前launch的附加參數,可以對比進行學習參數用法。
參考
1. https://blog.csdn.net/weixin_43258309/article/details/148257449
2. https://blog.csdn.net/UCAS_HMM/article/details/126514127
3. https://docs.nvidia.com/nsight-compute/
4. https://blog.csdn.net/weixin_42849849/article/details/146290086

 浙公網安備 33010602011771號
浙公網安備 33010602011771號