
在 CentOS7/CentOS8 上使用 cephadm 安裝分布式存儲系統 Ceph【轉 https://www.koenli.com/ef5921b8.html】
Cephadm 介紹
官方文檔:https://docs.ceph.com/en/latest/cephadm/
cephadm 用于部署和管理 Ceph 集群,它通過 SSH 將 manager 守護進程連接到主機來實現這一點。manager 守護進程支持添加、刪除和更新 Ceph 容器。cephadm 不依賴外部配置工具,例如 Ansible、Rook 和 Salt。
cephadm 管理 Ceph 集群的整個生命周期。此生命周期從引導過程開始,cephadm 在單個節點上創建一個小型 Ceph 集群。此集群由一個監視器(MON)和一個管理器(MGR)組成。然后,cephadm 使用編排接口擴展集群,添加所有主機并提供所有 Ceph 守護進程和服務。此生命周期的管理可以通過 Ceph 命令行接口或儀表盤(Dashboard)執行。
說明:
cephadm是 Ceph v15.2.0(Octopus)中的新功能,不支持舊版本的 Ceph。并且由于某些功能還在開發完善中,部署方式也會隨著版本更新會有比較大的變化,建議多參考對應版本的官方文檔
警告: Ceph Pacific 版本開始默認不提供 EL7 上的 RPM 源,只提供 EL8 上的
cephadm 正在積極開發中,兼容性與穩定性請關注官方說明
環境信息
| 主機名 | 配置 | 操作系統 | IP 地址 | 角色 | 磁盤 (除系統盤) |
|---|---|---|---|---|---|
| ceph-mon01 | 2 核 4G | CentOS7.5/CentOS8.3 | 10.211.55.7 | cephadm prometheus grafana MON OSD MGR MDS NFS ganesha RGW iSCSI rbd-mirror |
100G * 3 |
| ceph-mon02 | 2 核 4G | CentOS7.5/CentOS8.3 | 10.211.55.8 | MON OSD MGR MDS NFS ganesha RGW iSCSI rbd-mirror |
100G * 3 |
| ceph-mon03 | 2 核 4G | CentOS7.5/CentOS8.3 | 10.211.55.9 | MON OSD MGR MDS NFS ganesha RGW iSCSI rbd-mirror |
100G * 3 |
環境要求
- Python3
- 容器運行時,例如 Docker、Podman
- 所有節點之間保持時間同步,使用 chrony 或 NTP 服務
- 用于調配存儲設備的 LVM2
初始化配置
說明:除非特別說明,否則本節操作在所有節點進行。
配置主機名
1
|
hostnamectl set-hostname <hostname>
|
關閉 SELINUX
1
|
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
|
關閉防火墻
1
|
systemctl stop firewalld
|
節點之間時間同步
server 端
任選一臺機器作為 server 端;如果環境可以訪問互聯網,可以不需要自己搭建 server 端,參考后面的 client 端部分設置所有節點與公網 ntp 時間服務器 (例如 time1.cloud.tencent.com) 同步時間即可
CentOS7.x
1
|
# 設置時區為Asia/Shanghai
|
CentOS8.x
1
|
# 設置時區為Asia/Shanghai
|
client 端
CentOS7.x
1
|
# 設置時區為Asia/Shanghai
|
CentOS8.x
1
|
# 設置時區為Asia/Shanghai
|
配置 Host 解析
1
|
cat >> /etc/hosts << EOF
|
安裝 LVM2
1
|
yum install lvm2 -y
|
安裝 Python3
1
|
yum install python3 -y
|
安裝 Docker
配置 docker-ce repository
1
|
# 安裝所需要的包,yum-utils提供了yum-config-manager工具,device-mapper-persistent-data和lvm2是設備映射存儲驅動所需要的
|
說明:若無法訪問國外網站,可配置國內阿里云的 docker 源
1
|
yum install wget -y
|
配置好 Docker 倉庫后,運行如下命令安裝最新版 Docker
1
|
# 安裝最新版本的docker-ce
|
說明:若要安裝指定版本的 docker,按照如下步驟
1
|
# 列出repo倉庫中可用的docker版本并降序排列
|
啟動 Docker 并設置開機自啟
1
|
systemctl start docker
|
設置阿里云鏡像加速器(可選)
1
|
mkdir -p /etc/docker
|
安裝 Cephadm
說明:本節操作在所有節點進行
使用 curl 獲取 cephadm 腳本的最新版本。
1
|
cd /root/
|
賦予 cephadm 腳本可執行權限
1
|
chmod +x cephadm
|
盡管 cephadm 腳本足以啟動集群,但在主機上安裝 cephadm 命令還是比較方便的。運行以下命令安裝提供 cephadm 命令的軟件包
1
|
# ./cephadm add-repo --release <ceph_version,such as octopus>
|
確認 cephadm 是否已加入 PATH 環境變量
1
|
which cephadm
|
返回如下內容表示添加成功
1
|
/usr/sbin/cephadm
|
引導一個新集群
說明:本節操作在引導節點執行
說明:創建新 Ceph 集群的第一步是在 Ceph 集群的第一臺主機上運行
cephadm bootstrap命令,在 Ceph 集群的第一臺主機上運行cephadm bootstrap命令會創建 Ceph 集群的第一個 “監視器(MON)守護進程”,并且該監視器守護進程需要一個 IP 地址,因此需要知道該主機的 IP 地址。如果有多個網絡和接口,請確保選擇一個可供任何訪問 Ceph 集群的主機訪問的網絡和接口。
說明:關于
cephadm bootstrap的更多自定義配置可查閱關于 CEPHADM 引導的更多信息
運行 ceph bootstrap 命令
1
|
# cephadm bootstrap --mon-ip *<mon-ip>*
|
該命令執行以下操作:
- 在本地主機上為新集群創建監視器(MON)和管理器(MGR)守護進程
- 為 Ceph 集群生成新的 SSH 密鑰,并將其添加到 root 用戶的
/root/.ssh/authorized_keys - 將公鑰的副本寫入
/etc/ceph/ceph.pub - 將最小配置文件寫入
/etc/ceph/ceph.conf,與新集群通信需要此文件 - 將 client.admin 管理(特權)的密鑰副本寫入到
/etc/ceph/ceph.client.admin.keyring - 給引導主機添加
_admin標簽,默認情況下,具有此標簽的主機也將獲得/etc/ceph/ceph.conf和/etc/ceph/ceph.client.admin.keyring的副本
出現如下信息表示引導成功
1
|
Creating directory /etc/ceph for ceph.conf
|
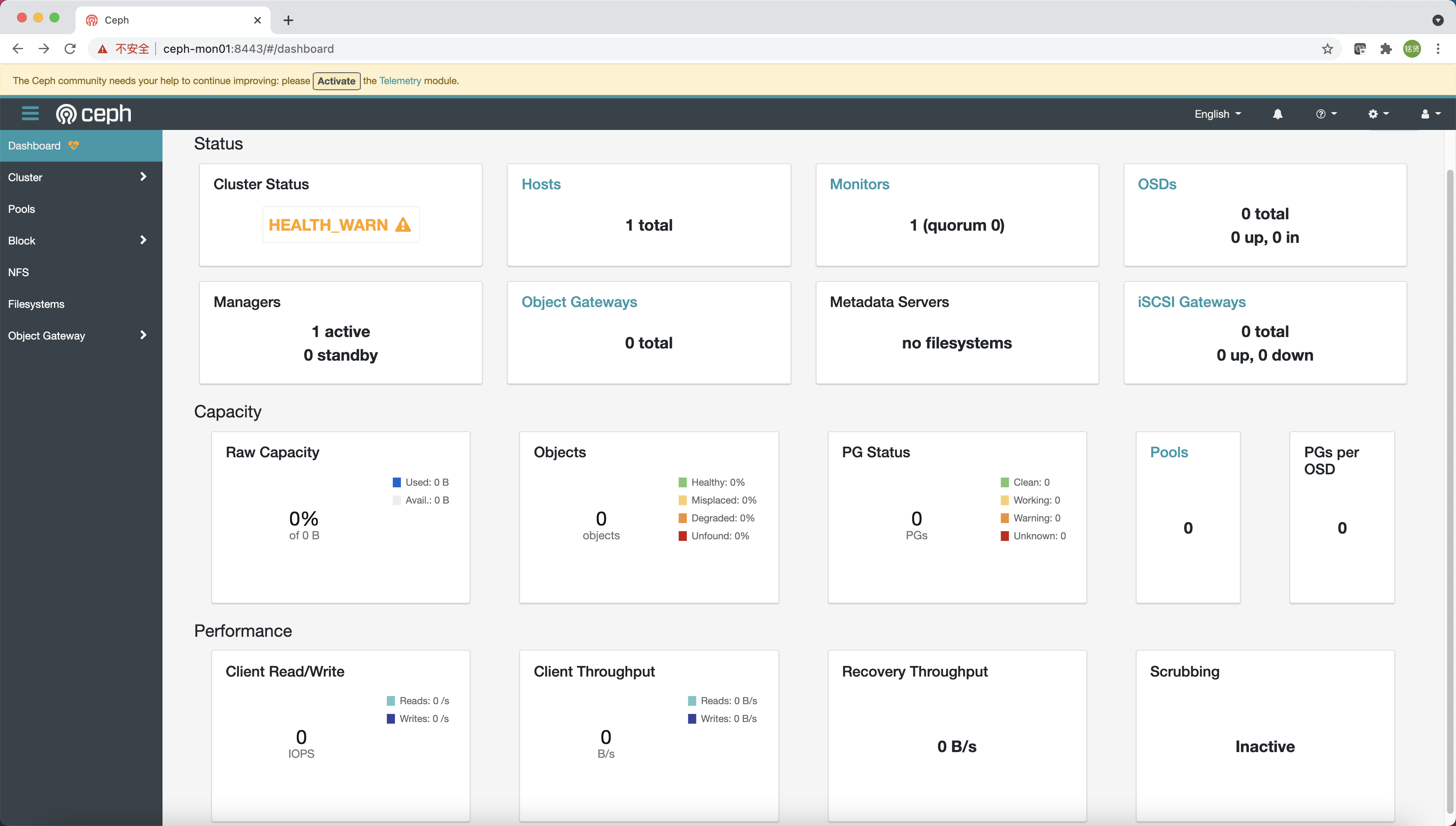
根據引導完成的提示信息使用瀏覽器訪問 Dashboard (https://ceph-mon01:8443/),修改密碼后登錄到 Ceph Dashboard
說明:引導提示默認通過主機名訪問,需在訪問的機器上配置 HOST 解析或者改為 IP 地址訪問
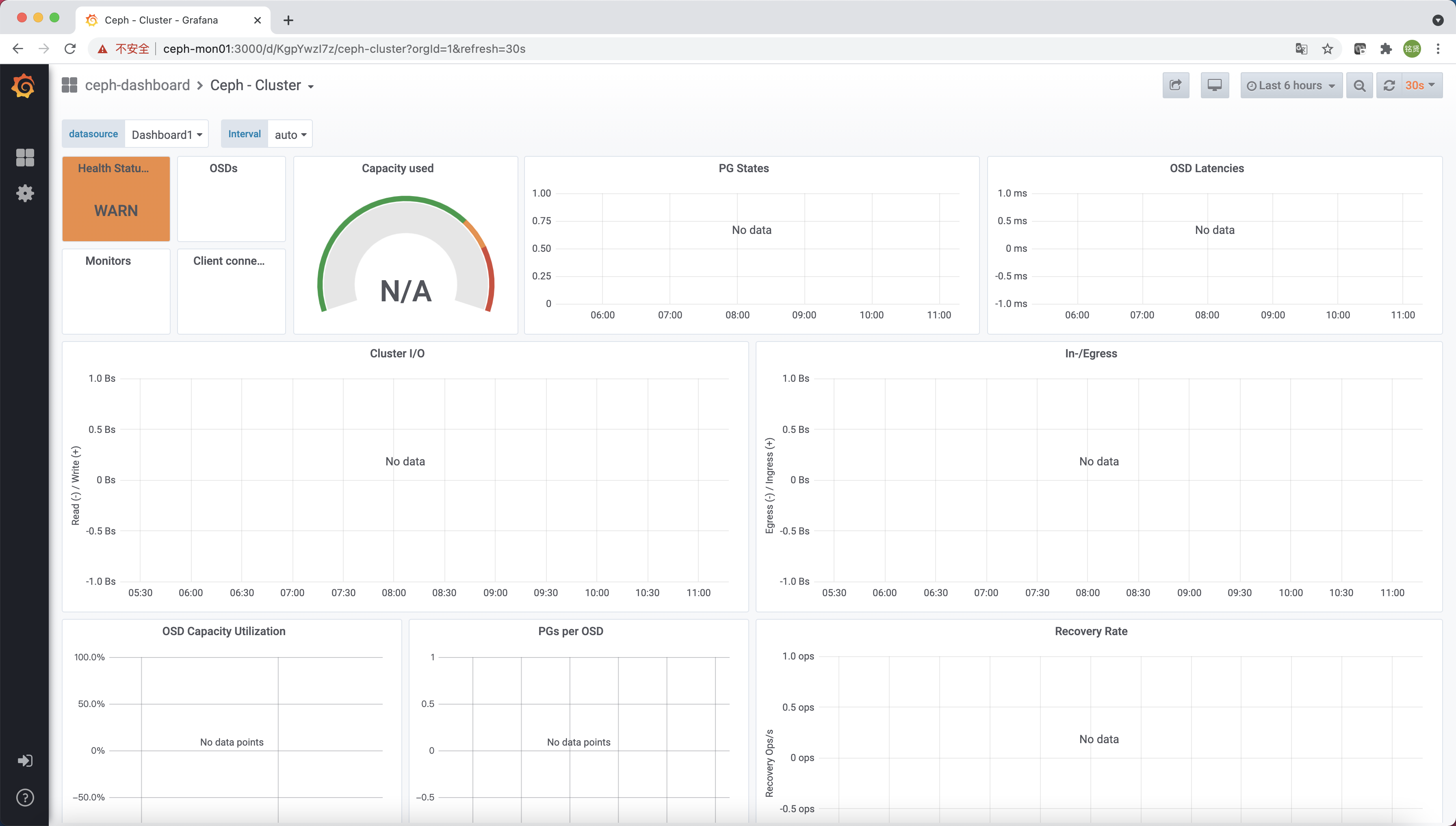
還有一個實時顯示 Ceph 集群狀態的 Grafana 展示頁面(https://ceph-mon01:3000/)
查看當前配置文件
1
|
[root@ceph-mon01 ~]# ll /etc/ceph/
|
查看當前拉取的鏡像及容器運行狀態
1
|
[root@ceph-mon01 ~]# docker image ls
|
通過以上信息可知此時在引導節點上已經運行了以下組件:
mgr:Ceph 管理器(MGR)程序mon:Ceph 監視器crash:崩潰數據采集模塊prometheus:prometheus 監控組件alertmanager:prometheus 告警組件node-exporter:prometheus 節點監控數據采集組件grafana:監控數據展示儀表盤 grafana
啟用 Ceph 命令
說明:本節操作在所有節點進行
默認情況下 cephadm 不會在主機上安裝任何 Ceph 軟件包,需運行 cephadm shell 命令在安裝了所有 Ceph 軟件包的容器中啟動 Bash Shell (運行 exit 可退出 Shell),在此特定的 Shell 中運行 Ceph 相關命令
說明:默認情況下,如果在主機上的
/etc/ceph中找到ceph.conf配置文件和ceph.client.admin.keyring文件,則會將它們傳遞到容器環境中,以便 Shell 能夠完全正常工作。但若在 MON 主機上執行時,cephadm shell將從 MON 容器查找配置,而不是使用默認配置。
1
|
[root@ceph-mon01 ~]# cephadm shell
|
為了方便訪問,我們可以在主機上安裝 ceph-common 軟件包,該軟件包包含所有 Ceph 命令,包括 ceph、rbd、mount.ceph 等
1
|
cephadm install ceph-common
|
驗證可通過本機的 Ceph 命令連接到集群
1
|
[root@ceph-mon01 ~]# ceph -v
|
添加主機
說明:本節操作在引導節點執行
要列出當前與集群關聯的主機,可運行如下命令:
1
|
ceph orch host ls
|
安裝集群公鑰
通過 ssh-copy-id 命令配置集群的公共 SSH 公鑰至其它所有 Ceph 節點
1
|
# ssh-copy-id -f -i /etc/ceph/ceph.pub root@*<new-host>*
|
添加指定新節點
通過 ceph orch host add 命令添加新節點到 Ceph 集群中
1
|
# ceph orch host add *<newhost>* [*<ip>*] [*<label1> ...*]
|
說明:可明確提供主機 IP 地址。如果未提供 IP,則將立即通過 DNS 解析主機名,并使用該 IP。還可以包括一個或多個標簽,以立即標記新主機。
1
|
# ceph orch host add *<newhost>* [*<ip>*] [*<label1> ...*]
|
驗證
查看 Ceph 納管的所有節點
1
|
[root@ceph-mon01 ~]# ceph orch host ls
|
說明:添加完成后 Ceph 會自動擴展 MON 和 MGR 到另外節點 (此過程時間可能會稍久,耐心等待),另外可用命令 (
ceph -s) 或 Ceph 的 Dashboard 頁面查看添加情況
1
|
[root@ceph-mon01 ~]# ceph -s
|
部署其他 MON(可選)
說明:本節操作在引導節點執行
默認情況下,隨著集群的增長,Ceph 會自動部署 MON 守護程序,而隨著集群的縮小,Ceph 也會自動減少 MON 守護程序。此過程是自動的,就像在上節完成主機添加后,Ceph 立即自動擴展 MON 到另外的兩臺節點(最多自動添加到 5 個 MON)。如果要調整 5 個 MON 的默認值,可運行如下命令:
1
|
# ceph orch apply mon *<number-of-monitors>*
|
說明:典型的 Ceph 群集有三個或五個分布在不同主機上的 MON 守護進程。如果集群中有五個或更多節點,建議部署五個 MON。
如果要禁用 MON 的自動部署,可運行如下命令:
1
|
ceph orch apply mon --unmanaged
|
關于更多 MON 部署配置(例如指定子網部署)可參考官方文檔 MON Service 章節
部署 MGR(可選)
說明:本節操作在引導節點執行
添加節點后,Ceph 會自動擴展 MGR 節點,可通過 ceph orch ls mgr 命令查看當前 MGR 數量
1
|
[root@ceph-mon01 ~]# ceph orch ls mgr
|
可以看到,默認會啟動 2 個 MGR,若要查看具體運行 MGR 的節點可通過如下 ceph orch ps --daemon_type mgr 命令
1
|
[root@ceph-mon01 ~]# ceph orch ps --daemon_type mgr
|
可以看到,MGR 運行在 ceph-mon01 和 ceph-mon02 上,若想繼續擴展 MGR 節點,可運行如下命令:
警告:指定的主機列表一定要包括原來的主機,有關指定守護進程位置的詳細信息請見官網 Placement Specification
1
|
# ceph orch apply mgr *<host1,host2,host3,...>*
|
部署 OSD
說明:本節操作在引導節點執行
列出設備
ceph-volume 會不時掃描集群中的每個主機,以確定存在哪些設備以及這些設備是否可用做 OSD。要查看 cephadm 發現的設備列表,可運行以下命令:
1
|
# ceph orch device ls [--hostname=...] [--wide] [--refresh]
|
輸出類似如下:
1
|
[root@ceph-mon01 ~]# ceph orch device ls
|
說明:使用
--wide選項提供與設備相關的所有詳細信息,包括設備可能不適合用作 OSD 的任何原因
如果滿足以下所有條件,則認為存儲設備可用:
- 設備必須沒有分區
- 設備不得具有任何 LVM 狀態
- 設備必須沒有被掛載
- 設備必須沒有包含任何文件系統
- 設備不得包含 Ceph BlueStore OSD
- 設備必須大于 5GB
創建 OSD
有幾種方式可以創建新的 OSD:
方式一(不推薦)
自動使用任何可用且未使用的存儲設備
1
|
ceph orch apply osd --all-available-devices
|
運行上述命令后:
- 如果向集群中添加新硬盤,將自動用于創建新的 OSD
- 如果刪除 OSD 并清理 LVM 物理卷,將自動創建新的 OSD
如果要禁用在可用設備上自動創建 OSD,可使用非托管參數
1
|
ceph orch apply osd --all-available-devices --unmanaged=true
|
方式二(推薦)
從指定的主機的指定設備創建 OSD
1
|
# ceph orch daemon add osd *<host>*:*<device-path>*
|
方式三(推薦)
可以使用高級 OSD 服務規范根據設備的屬性對設備進行分類。這有助于更清楚地了解哪些設備可供消費。屬性包括設備類型(SSD 或 HDD)、設備型號名稱、大小以及設備所在的主機等
1
|
ceph orch apply -i spec.yml
|
檢查 OSD 和集群狀態
通過 ceph -s 確定 OSD 狀態是否均處于 up 并 in 狀態,集群狀態是否為 HEALTH_OK
1
|
[root@ceph-mon01 ~]# ceph -s
|
也可通過 Dashboard 查看 OSD 和集群狀態


使用 Ceph 集群提供塊存儲服務
說明:本節操作在引導節點執行
確認默認 pg_num 和副本數
- pg_num:根據
Total PGs = (#OSDs * 100) / pool size公式來決定pg_num(pgp_num 應該設成和 pg_num 一樣),所以9*100/3=300,官方建議取最接近的 2 的指數倍數,比如 256。這是針對集群中所有 pool 的,每個 pool 的默認 pg_num 建議設置更小,比如 32 - 副本數:默認副本數建議為 3,最小副本數建議為 2
配置默認 pg_num 和副本數
動態更新配置
1
|
ceph tell mon.\* injectargs '--osd_pool_default_size=3'
|
創建塊存儲池
創建一個塊存儲池 koenli
1
|
# ceph osd pool create <poolname> <pg_num> <pgp_num>
|
創建完 pool 后再次查看集群狀態,確認 pgs 均為 active+clean 狀態,并且集群狀態為 HEALTH_OK
1
|
[root@ceph-mon01 ~]# ceph -s
|
創建塊并映射到本地
創建一個 10G 的塊
1
|
# rbd create --size <size> <rbdname> --pool <poolname>
|
查看 rbd
1
|
# rbs ls <poolname> -l
|
將 rbd 塊映射到本地
1
|
# rbd map <poolname>/<rbdname>
|
查看映射,可見 koenli/disk0 已經映射到本地,相當于本地的一塊硬盤 /dev/rbd0,可對其進行分區、格式化、掛載等相關操作,此處不再贅述。
1
|
# rbd showmapped
|
取消映射并刪除塊
1
|
# rbd unmap <poolname>/<rbdname>
|
使用 Ceph 集群提供對象存儲服務
說明:本節操作在引導節點執行
部署 RGW
Cephadm 將 radosgw 部署為守護進程的集合,這些守護進程管理單個集群或多站點(multisite)中的特定 realm 和 zone(有關 realm 和 zone 的更多信息可參見 Multi-Site)
說明:對于 cephadm,radosgw 守護進程是通過監視器配置數據庫配置的,而不是通過 ceph.conf 或命令行配置的。如果該配置尚未就緒(通常在
client.rgw.<something>部分),那么 radosgw 守護進程將以默認設置啟動(例如綁定到端口 80)。
要部署一組 radosgw 守護進程,請運行以下命令:
1
|
# 創建realm
|
說明:Pacific 版本版本創建 radosgw 守護進程的命令略有不同,需要指定一個
svc_id,可參考如下。Pacific 版本之后是否還有變化請參考官方文檔
1
|
# ceph orch apply rgw <svc_id> [<realm_name>] [<zone_name>] [<port:int>] [--ssl] [<placement>] [--dry-run] [--format {plain|json|json-pretty|yaml}] [--unmanaged] [--no-overwrite]
|
通過 ceph -s 確定 RGW 是否 active,集群狀態是否為 HEALTH_OK
1
|
[root@ceph-mon01 ~]# ceph -s
|
說明:如上輸出所示,集群健康狀態為
HEALTH_OK,不過下方的progress顯示正在進行 PG 數量的調整,原因是 Ceph 在 Nautilus 版本中引入了 PG 的自動調整功能,待自動調整完成后即可。
配置 Dashboard(可選)
說明:Octopus 版本才需配置。
https://docs.ceph.com/en/octopus/mgr/dashboard/#enabling-the-object-gateway-management-frontend
由于 RGW 擁有自己的一套賬號體系,所以為了能夠使用 Dashboard 的對象存儲網關管理功能,需要在 RGW 中創建一個 Dashboard 用的賬號
1
|
# radosgw-admin user create --uid=<user_id> --display-name=<display_name> --system
|
通過如下命令導出
1
|
# radosgw-admin user info --uid=<user_id> | grep access_key | awk -F '"' '{print $4}' > /root/rgw-dashboard-access-key
|
最后將相關憑證配置到 Dashboard
1
|
# ceph dashboard set-rgw-api-access-key -i <file-containing-access-key>
|
配置完成后即可在 Dashboard 上使用對象存儲網關的管理功能
RGW 高可用
說明:在 Ceph Pacific(16.x)版本
cephadm新增了一個實現 RGW 服務高可用的功能
ingress 服務支持使用最少的一組配置為 RGW 服務創建高可用性端點(endpoint),orchestrator 將部署和管理 HAProxy 和 Keepalive 的組合,以在虛擬 IP 上為 RGW 提供負載平衡服務。
說明:如果要使用 SSL,則必須在 ingress 服務配置 SSL 而不是 RGW 本身

由上圖可看到,有 N 臺主機部署了 ingress 服務。每個主機都有一個 HAProxy 守護程序和一個 Keepalived 守護程序。一次只能在其中一臺主機上自動配置虛擬 IP。
每個 Keepalived 守護程序每隔幾秒鐘檢查一次同一主機上的 HAProxy 守護程序是否有響應。Keepalived 還將檢查處于 MASTER 狀態的 Keepalived 守護程序是否正常運行。如果處于 MASTER 狀態的 Keepalived 守護程序或 HAProxy 沒有響應,則在 BACKUP 模式下運行的其余 Keepalived 守護程序中的一個將被選舉為 MASTER,虛擬 IP 也將移動到該節點。
HAProxy 就像負載平衡器一樣,在所有可用的 RGW 守護進程之間分發所有 RGW 請求。
具體的部署請參考官方文檔相關內容
使用 Ceph 集群提供文件存儲服務
說明:除非特別說明,否則本節操作在引導節點執行
使用 CEPFS 文件系統需要一個或多個 MDS 守護進程。
創建文件存儲池
創建兩個存儲池,cephfs_metadata 用于存文件系統元數據,cephfs_data 用于存文件系統數據
1
|
# ceph osd pool create <poolname> <pg_num> <pgp_num>
|
創建文件系統
1
|
# fs new <fsname> <metadata_pool> <data_pool>
|
部署 MDS
1
|
# ceph orch apply mds <fs_name> [<placement>] [--dry-run] [--unmanaged] [plain|json|
|
查看文件系統和 MDS 狀態
1
|
# ceph fs ls
|
驗證掛載
在要掛載的節點上安裝 EPEL 軟件源并配置對應版本的 Ceph 軟件源
說明:如果掛載的節點為 Ceph 集群節點則跳過此步
CentOS7.x
1
|
# 安裝EPEL軟件源
|
CentOS8.x
1
|
# 安裝EPEL軟件源
|
在要掛載的節點上安裝 ceph-fuse
1
|
yum install ceph-fuse -y
|
將引導節點 /etc/ceph 目錄下的文件和 /var/lib/ceph/{fsid}/mon.{hostname}/config 文件拷貝到要掛載的節點上
說明:如果要掛載的節點為引導節點則忽略此步
1
|
scp -r /etc/ceph/* <client_ip>:/etc/ceph/
|
使用 ceph-fuse 命令掛載
說明:更多關于
ceph-fuse的使用說明可以參考官方文檔
1
|
# ceph-fuse -n client.<username> -m <mon-ip1>:<mon-port>,<mon-ip2>:<mon-port>,<mon-ip3>:<mon-port> <mountpoint>
|
說明:若要開機自動掛載,需要在
/etc/fstab中添加如下相關條目
1
|
# none <mountpoint> fuse.ceph ceph.id=<username>,ceph.conf=<path/to/ceph.conf>,_netdev,defaults 0 0
|
卸載
1
|
# umount <mountpoint>
|
說明:若配置過開機自動掛載,還需刪除
/etc/fstab中的對應掛載條目
部署 NFS ganesha 服務
說明:除非特別說明,否則本節操作在引導節點執行
說明:用戶可以用 Ceph 提供的 ceph-fuse 掛載 CephFS 進行訪問,也可以通過 Ceph 的內核模塊進行掛載訪問。但有時候,由于各種原因,一些系統無法通過這兩種方法訪問 CephFS,我們可以使用 NFS-ganesha 將 CephFS 通過 NFS 協議發布出去,用戶可以通過 NFS 客戶端掛載發布出去的 CephFS。
說明:Pacific 版本開始只支持 NFSv4
首先創建 nfs-ganesha 存儲池
1
|
# ceph osd pool create <poolname> <pg_num> <pgp_num>
|
然后通過 cephadm 部署 NFS Ganesha 守護進程(或一組守護進程)。NFS 的配置存儲在 nfs-ganesha 存儲池中并且通過 ceph nfs export ... 命令或通過 Dashboard 儀表板管理服務暴露
說明:不同 Ceph 版本部署 NFS Ganesha 守護進程的命令可能有所差異,可查看對應版本的命令幫助說明
Octopus 版本
1
|
# ceph orch apply nfs *<svc_id>* *<pool>* *<namespace>* --placement="*<num-daemons>* [*<host1>* ...]"
|
Pacific 版本
1
|
# ceph orch apply nfs <svc_id> [<placement>] [<pool>] [<namespace>] [<port:int>] [--dry-run] [--unmanaged] [--no-overwrite]
|
檢查 NFS Ganesha 守護進程狀態
1
|
[root@ceph-mon01 ~]# ceph orch ls nfs
|
說明:Octopus 版本為了在 Dashboard 中啟用對 NFS Ganesha 的管理,需要進行下面設置
1
|
# ceph dashboard set-ganesha-clusters-rados-pool-namespace <pool>[/<namespace>]
|
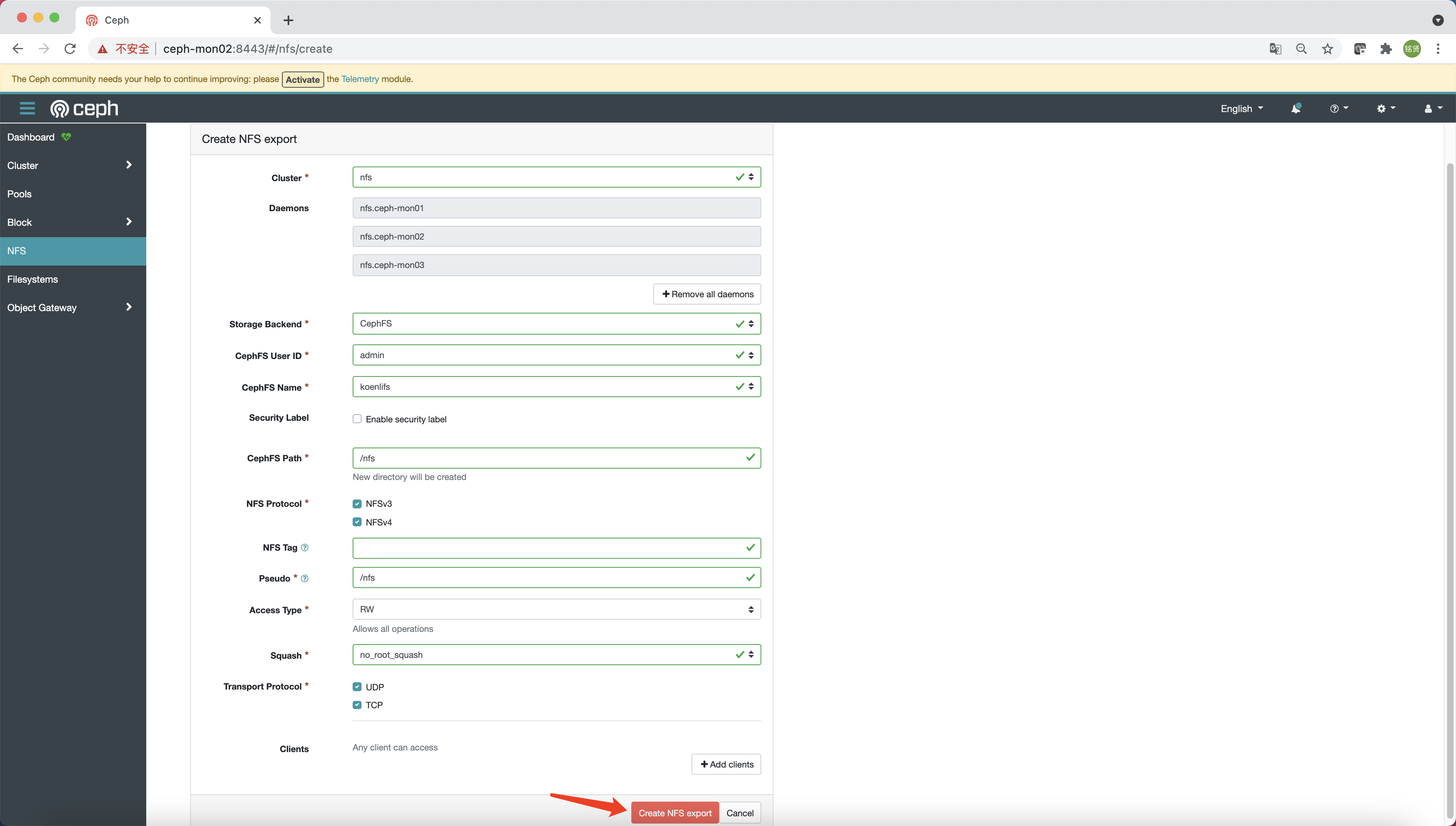
訪問 Dashboard,選擇 “NFS”,點擊 “Create”

參考下圖填寫相關配置信息,最后點擊 “Create NFS export”
說明:在 Pacific 版上可能會創建失敗,提示沒有權限創建
/nfs目錄,則需先參考上面使用ceph-fuse命令掛載的步驟,在 cephfs 中創建nfs目錄(目錄名稱與 CephFS Path 對應)后再次點擊 “Create NFS export” 即可
在客戶端節點驗證 NFS 掛載
說明:
<daemon_ip>與創建 NFS export 時選擇的 Daemons 主機 IP 匹配;<path>與創建 NFS export 時指定的 CephFS Path 對應
1
|
# 驗證掛載
|
部署 iSCSI 服務
說明:本節操作在引導節點執行
創建 iSCSI 所需要的存儲池
1
|
# ceph osd pool create <poolname> <pg_num> <pgp_num>
|
創建 iSCSI 的 yaml 文件
說明:更多配置請參考官方文檔
1
|
cat > /root/iscsi.yaml << EOF
|
部署 iSCSI
1
|
ceph orch apply -i /root/iscsi.yaml
|
查看 iSCSI service 和 daemon 狀態
1
|
[root@ceph-mon01 ~]# ceph orch ls iscsi
|
查看 Ceph Dashboard 狀態

如何剔除 OSD
從集群中剔除 OSD 包括兩個步驟:
- 從集群中撤出此 OSD 上所有的 PG
- 從集群中卸載無 PG 的 OSD
以下命令執行這兩個步驟:
1
|
# ceph orch osd rm <osd_id(s)> [--replace] [--force]
|
可以使用 ceph orch osd rm status 命令查詢 OSD 操作的狀態
Troubleshooting
無法 rbd 映射到本地
問題現象
將 rbd 映射到本地時出現如下錯誤信息:
1
|
rbd: sysfs write failed
|
解決方法
因為 CentOS7 默認內核版本不支持 Ceph 的一些特性,需要手動禁用掉才能 map 成功
1
|
rbd feature disable koenli/disk01 object-map fast-diff deep-flatten
|
-------------------------------------------
個性簽名:獨學而無友,則孤陋而寡聞。做一個靈魂有趣的人!
如果覺得這篇文章對你有小小的幫助的話,記得在右下角點個“推薦”哦,在此感謝!

 浙公網安備 33010602011771號
浙公網安備 33010602011771號