
MAT分析內存溢出- ShardingSphere JDBC的緩存泄露問題
MAT分析Dump文件:
1、設置MemoryAnalyzer.ini中的-Xmx為需要用的大小,否則會遇到打開dump文件報錯。。
2、dump文件導出配置:在節(jié)點配置中增加dump導出
3、dump文檔加載出來后,圖示如下:

核心指標解析:
1、定位可疑區(qū)域:查看報告中的Leak Suspects,每個Suspect會【顯示可疑對象占用內存比例】;重點看Problem Suspect 1(最可能的泄漏點),記錄其對象類型(如

解析:
Keywords:關鍵信息,列出了關鍵的類和類加載器等標識,方便定位和關聯(lián)代碼及相關組件,
2、分析details:
解析:
3、跟蹤引用鏈

關鍵路徑:
內存占比驗證:
以上只是為了從不同的區(qū)域去看,同樣也可以從直方圖去看,根據Retained Heap降序,找出top對象信息,并看引用鏈。
4、結合業(yè)務代碼分析:
1、設置MemoryAnalyzer.ini中的-Xmx為需要用的大小,否則會遇到打開dump文件報錯。。
2、dump文件導出配置:在節(jié)點配置中增加dump導出
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/path/to/dump/heapdump.hprof
核心指標解析:
- Histogram:直方圖,列出每個類的實例數(shù)量
- Objects:對象個數(shù)
- Shallow Heap:淺堆,表示對象占用多少內存。
- Retained Heap:深堆,表示對象依賴的底層所有對象的總內存。
- with outgoing references:此對象引用了哪些對象
- with incoming references:此對象被誰引用
- Dominator Tree:支配樹,列出最大的對象以及它們使哪些對象保持存活。
- Top Consumers:按類和包對最占用資源的對象進行分組打印。
- Duplicate Classes:檢測由多個類加載器加載的類。
- Leak Suspects:懷疑內存泄露
- Top Components:列出占堆總大小超過 1% 的組件報告。
- Component Report:組件報告,分析屬于同一個根包或類加載器的對象。
1、定位可疑區(qū)域:查看報告中的Leak Suspects,每個Suspect會【顯示可疑對象占用內存比例】;重點看Problem Suspect 1(最可能的泄漏點),記錄其對象類型(如
java.util.HashMap)和支配樹路徑(如MyCache → HashMap → Entry[])。解析:
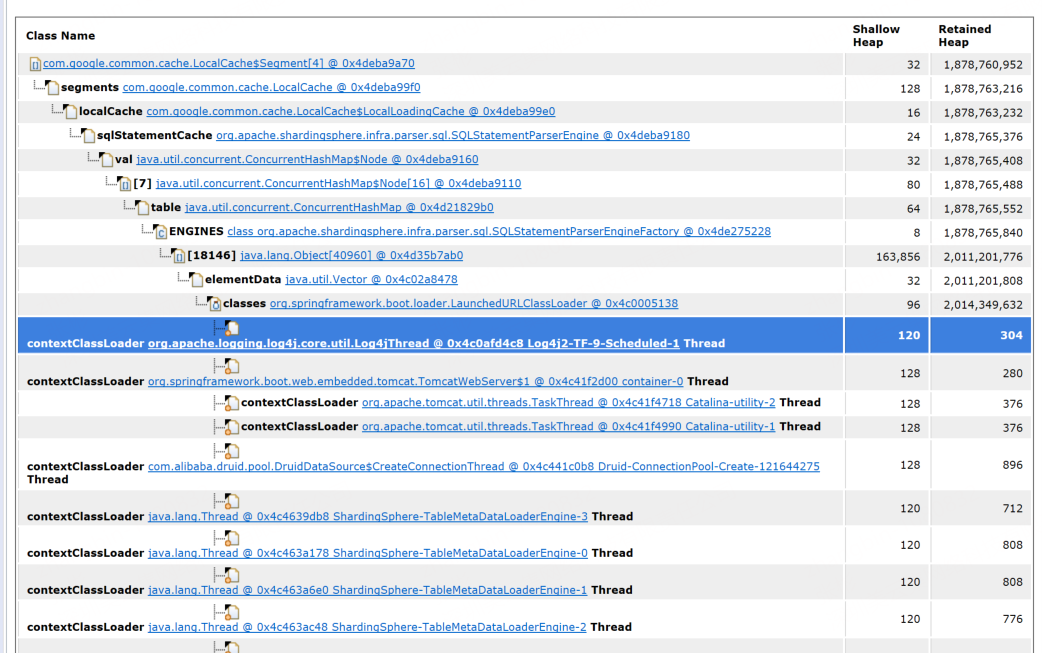
org.springframework.boot.loader.LaunchedURLClassLoader @0x4c0005138 是一個類加載器,占用了約 2,014,349,632 字節(jié)(占比 67.97% ),這些內存主要是因為加載了 com.google.common.cache.LocalCache$Segment[] 這個實例導致的堆積。可能存在內存泄漏或者該部分對象占用內存過大的情況,需要進一步結合代碼里對 Guava Cache(即 com.google.common.cache 相關)的使用邏輯,比如緩存對象是否沒有合理失效、緩存配置的容量是否過大等,來排查為何會出現(xiàn)這么高的內存占用 。Keywords:關鍵信息,列出了關鍵的類和類加載器等標識,方便定位和關聯(lián)代碼及相關組件,
com.google.common.cache.LocalCache$Segment[] 表明是 Guava 緩存的段數(shù)組相關,org.springframework.boot.loader.LaunchedURLClassLoader @0x4c0005138 是加載這些類的類加載器實例標識,可輔助在代碼和類加載機制層面去深挖問題根源 。點擊 Details 通常能查看更詳細的對象引用鏈、內存占用細節(jié)等,助力進一步分析內存問題。2、分析details:
解析:
- 從引用鏈看
LocalCache→loadingCache→sqlStatementCache,說明是 ShardingSphere 的 SQL 語句解析緩存(SQLStatementParserEngine相關) 在占用內存。 - 逐層展開后,最終關聯(lián)到
org.springframework.boot.loader.LaunchedURLClassLoader加載的類(classes節(jié)點),體現(xiàn)了類加載器持有緩存對象,導致內存無法釋放 。 - 下方多個線程(如 Log4j 線程、Tomcat 線程、ShardingSphere 元數(shù)據加載線程等)的
contextClassLoader都指向LaunchedURLClassLoader,說明 這些線程在運行時依賴該類加載器加載的類 。若線程未正確終止或類加載器未被釋放,會進一步延長緩存對象的生命周期,加劇內存占用。
SQLStatementParserEngine 相關的內存占用非常大,3、跟蹤引用鏈
with outgoing references關鍵路徑:
SQLStatementParserEngineFactory → ENGINES(ConcurrentHashMap) → SQLStatementParserEngine → sqlStatementCache → LocalCache → segments(LocalCache$Segment[])。這是 ShardingSphere SQL 解析緩存的完整引用鏈,segments 數(shù)組是內存堆積的直接載體(對應最初的 LocalCache$Segment[] 占用問題)。內存占比驗證:
LocalCache 的 Retained Heap 高達 1,878,763,216(約 1.75GB),說明緩存對象確實在此大量堆積。以上只是為了從不同的區(qū)域去看,同樣也可以從直方圖去看,根據Retained Heap降序,找出top對象信息,并看引用鏈。
4、結合業(yè)務代碼分析:
- 組件關聯(lián):所有內存堆積都關聯(lián)
SQLStatementParserEngine(ShardingSphere 負責 SQL 解析緩存的核心類)和LocalCache(Guava Cache 實現(xiàn)),且SQLStatementParserEngine是 ShardingSphere JDBC 的內置組件,說明緩存邏輯由 ShardingSphere 觸發(fā)。 - 緩存特性:ShardingSphere JDBC 默認會緩存 SQL 解析結果(通過
SQLStatementCache),若未合理配置緩存容量 / 過期時間,或業(yè)務場景中SQL 多樣性極高(如動態(tài)參數(shù) SQL 過多),就會導致緩存無限堆積,符合 “緩存泄漏” 特征(對象無法被 GC 回收,內存持續(xù)增長)。 - 找到ShardingSphere 緩存配置的核心類,ShardingSphere JDBC 的 SQL 解析緩存由
SQLStatementParserEngine管理,其緩存初始化邏輯在SQLStatementParserEngineFactory或SQLStatementCache相關類中。 -
筆者項目中確實沒有這個配置的,但默認已有大小,那為什么還會大內存,分析這個緩存存的內容有:
/** * SQL語句解析引擎,負責SQL語句的解析和緩存管理 * 核心作用是將原始SQL字符串解析為結構化的SQLStatement對象,同時提供緩存機制提升性能 */ public final class SQLStatementParserEngine { /** * SQL語句解析執(zhí)行器,實際執(zhí)行SQL解析的組件 * 封裝了不同數(shù)據庫類型的SQL解析邏輯 */ private final SQLStatementParserExecutor sqlStatementParserExecutor; /** * SQL語句緩存,使用LoadingCache實現(xiàn)(通常是Guava的緩存實現(xiàn)) * 鍵為SQL字符串,值為解析后的SQLStatement對象 * 具備自動加載和過期淘汰能力 */ private final LoadingCache<String, SQLStatement> sqlStatementCache; /** * 構造方法,初始化解析引擎 * * @param databaseType 數(shù)據庫類型(如MySQL、PostgreSQL等) * @param sqlCommentParseEnabled 是否解析SQL中的注釋 */ public SQLStatementParserEngine(String databaseType, boolean sqlCommentParseEnabled) { // 初始化解析執(zhí)行器,傳入數(shù)據庫類型和注釋解析開關 this.sqlStatementParserExecutor = new SQLStatementParserExecutor(databaseType, sqlCommentParseEnabled); // 構建SQL語句緩存 // CacheOption參數(shù)說明: // 2000:緩存最大條目數(shù)(maximumSize) // 65535L:緩存過期時間(expireAfterWrite,單位根據實現(xiàn)可能為秒或毫秒) // 4:可能是并發(fā)級別(concurrencyLevel),允許同時寫入緩存的線程數(shù) this.sqlStatementCache = SQLStatementCacheBuilder.build( new CacheOption(2000, 65535L, 4), databaseType, sqlCommentParseEnabled ); } /** * 解析SQL語句的核心方法 * * @param sql 原始SQL字符串 * @param useCache 是否使用緩存:true-優(yōu)先從緩存獲取,未命中則解析并緩存;false-直接解析不使用緩存 * @return 解析后的SQLStatement對象(包含SQL結構化信息,如表名、條件、排序等) */ public SQLStatement parse(String sql, boolean useCache) { // 根據useCache參數(shù)決定是否使用緩存 return useCache ? (SQLStatement)this.sqlStatementCache.getUnchecked(sql) // 使用緩存:從緩存獲取,無則自動加載 : this.sqlStatementParserExecutor.parse(sql); // 不使用緩存:直接調用執(zhí)行器解析 } }
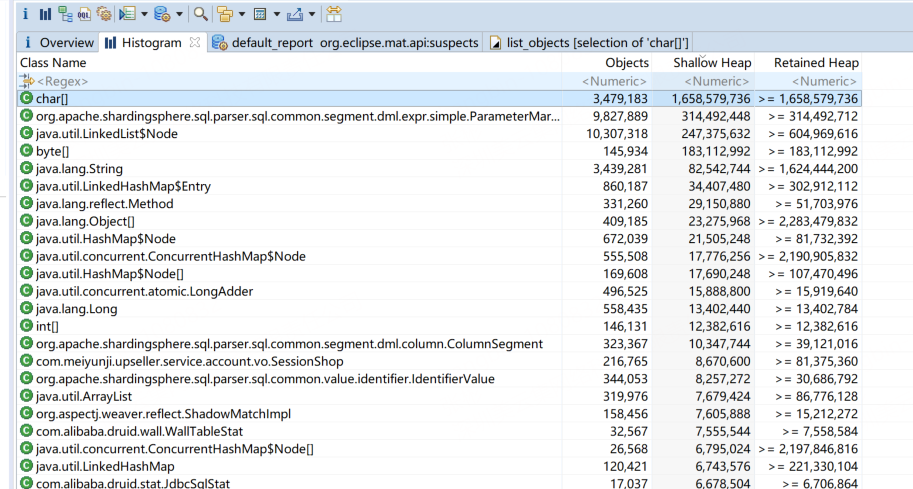 可以看到,大對象都是查詢的sql,當sql過大時,會間接導致sharding緩存過大。
可以看到,大對象都是查詢的sql,當sql過大時,會間接導致sharding緩存過大。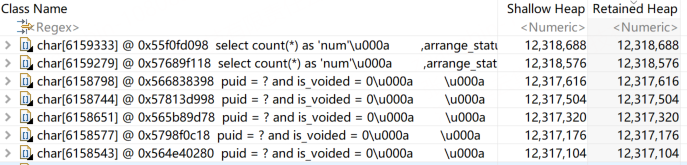 因此對
因此對本文來自博客園,作者:難得,轉載請注明原文鏈接:http://www.rzrgm.cn/zhangbLearn/p/18996179

 浙公網安備 33010602011771號
浙公網安備 33010602011771號