
Hystrix
服務故障引起的雪崩:
多個微服務之間調用時,A調用B和C,B和C又調用其他服務,這就是所謂扇出,如果鏈路上某個微服務由于網絡或自身原因導致服務響應時間過長或不可用,對A的調用就會占用越來越多的系統資源,進而引起系統崩潰。
對于高流量的應用來說,單一的后端依賴可能會導致所有服務器上的所有資源都在幾秒鐘內飽和。比失敗更糟糕的是,這些應用程序還可能導致服務之間的延遲增加,備份隊列,線程和其他系統資源緊張,導致整個系統發生更多的級聯故障。這些都表示需要對故障和延遲進行隔離和管理,以便單個依賴關系的失敗,不能取消整個應用程序或系統。所以,通常當發現一個模塊下的某個實例失敗后,這時候這個模塊依然還會接收流量,然后這個有問題的模塊還調用了其他的模塊,這樣就會發生級聯故障,或者叫雪崩
Hystrix:
Hystrix是一個用于處理分布式系統的延遲和容錯的開源庫,在分布式系統里,許多依賴不可避免的會調用失敗,比如超時、異常等,通過Hystrix可以通過 添加等待時間容限或容錯邏輯來控制分布式服務之間的調用。Hystrix通過隔離服務之間的訪問點,停止服務之間的級聯故障并提供后備選項來實現此目的,提高系統整體穩定性
雪崩解決方案:
請求緩存:對于訪問量高,且數據變動不頻繁的數據,使用緩存降低DB和服務壓力
請求合并:將相同的請求進行合并然后調用批處理接口
服務隔離:限制調用分布式服務的資源,某一個調用的服務出現問題不會影響其他服務調用
服務熔斷:犧牲局部服務,保全整體系統穩定性的措施
服務降級:服務熔斷以后,客戶端調用自己本地方法返回缺省值
線程池隔離:
- 概念:采用艙壁隔離技術,將外部依賴進行資源隔離,避免任何外部依賴故障導致本服務崩潰。對每個外部依賴用一個單獨線程池,如果某個外部依賴調用延遲很嚴重,最多是耗盡那個依賴自己的線程池,不影響其他依賴調用。在用戶請求和服務之間加入線程池,用戶請求不能直接訪問服務,通過線程池中空閑線程來訪問服務,如果線程池滿了,會進行降級,用戶請求不會阻塞或超時,至少可以看到一個執行結果,防止無休止等待和系統崩潰。
- 優點:可以安全隔離依賴的服務,減少所依賴服務發生故障時的影響面、當失敗的服務再次變得可用時,線程池將清理并立即恢復,不需要一個長時間的恢復、獨立的線程池提高了并發性
- 缺點:請求在線程池中執行,會帶來任務調度,排隊和上下文切換帶來的CPU開銷、涉及到跨線程,就存在ThreadLocal數據的傳遞問題,比如在主線程初始化的ThreadLocal變量,在線程中無法獲取
- 特性:請求線程和調用服務線程不是同一條線程(請求線程是tomcat線程,調用服務線程是hystrix線程池的線程)、支持超時可直接返回,支持熔斷,當線程池到達最大線程數后,再請求會觸發fallback接口進行熔斷、隔離原理:每個服務單獨用線程池,支持同步和異步兩種方式、資源消耗大,大量線程的上下文切換、排隊、調度等,無法傳遞Http Header
信號量隔離:
概念:每次調用線程,當前請求通過計數信號量進行限制,當信號量大于最大請求數時,進行限制,調用fallback接口快速返回。信號量是同步的,每次調用都要阻塞調用方的線程,直到結果返回,導致了無法對訪問做超時,只能依靠調用協議超時,無法主動釋放
特性:請求線程和調用服務線程是同一條線程(tomcat線程)、不支持超時、支持熔斷,當信號量達到maxConcurrentRequests后,再請求會觸發fallback接口進行熔斷
使用總結:
- 請求并發大,耗時長(計算大,或操作關系型數據庫),采用線程隔離策略。這樣可以保證大量的線程可用,不會由于服務原因一直處于阻塞或等待狀態,快速失敗返回。還有就是對依賴服務的網絡請求的調用和訪問,會涉及timeout這種問題的都使用線程池隔離。
- 請求并發大,耗時短(計算小,或操作緩存) ,采用信號量隔離策略,因為這類服務的返回通常會非常的快,不會占用線程太長時間,而且也減少了線程切換的開銷,提高了緩存服務的效率。還有就是適臺訪問不是對外部依賴的訪問,而是對內部的一些比較復雜的業務邏輯的訪問,像這種訪問系統內部的代碼,不涉及任何的網絡請求,做信號量的普通限流就可以了,因為不需要去捕獲timeout類似的問題,并發量突然太高,稍微耗時一些導致很多線程卡在這里,所以進行一個基本的資源隔離和訪問,避免內部復雜的低效率的代碼,導致大量的線程被夯住。
服務熔斷:由于某些原因使服務出現過載現象,為防止造成整個系統故障,從而采用的一種保護錯誤,也叫過載保護
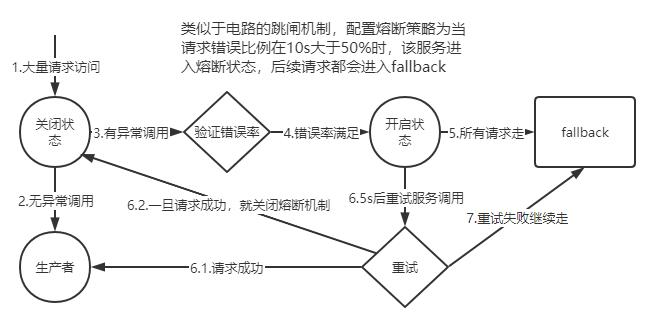
服務降級:請求滿足降級條件,直接走fallback,滿足以下條件觸發:
- 方法拋出HystrixBadRequestException異常
- 方法調用超時或熔斷器開啟攔截調用
- 線程池/隊列/信號量跑滿
- command 執行超時
- run() 或者 construct() 拋出異常
hystrix執行原理:

請求緩存:對于一個request context內的多個相同command,使用request cache,提升性能
斷路器原理:
判斷滑動窗口中,至少有多少個請求才可能觸發斷路。即在一定時間內經過斷路器的流量必須達到設定的值,才會去判斷要不要斷路
判斷異常比例,斷路器統計到的異常調用占比超過一定閾值(默認50%),即在一定時間內經過斷路器的流量超過了閾值,同時異常訪問的數量也達到了設定的比例,就會開啟斷路
斷路開啟,由close轉換到 open 狀態。之后在 SleepWindowInMilliseconds 時間內,所有經過該斷路器的請求全部都會被斷路,不調用后端服務,直接走 fallback 降級機制。而在該參數時間過后,斷路器會變為半開閉狀態,嘗試讓一條請求經過斷路器,看能不能正常調用。如果調用成功了,那么就自動恢復,斷路器轉為 close 狀態。
屬性設置:
- Enabled:控制是否允許斷路器工作,包括跟蹤依賴服務調用的健康狀況,以及對異常情況過多時是否允許觸發斷路。默認值是 true。
- ForceOpen:如果設置為 true 的話,直接強迫打開斷路器,相當于是手動斷路了,手動降級,默認值是 false
- ForceClosed:如果設置為 true,直接強迫關閉斷路器,相當于手動停止斷路了,手動升級,默認值是 false。
- requestVolumeThreshold:設置滑動窗口中,最少要有多少個請求時,才觸發開啟短路
- sleepWindowInMilliseconds:設置短路后,需要多長時間內直接拒絕請求,這個時間后,重新變為半開閉。
- errorThresholdPercentage:異常請求百分比,默認50%。
Hystrix參數配置:
- execution.isolation.strategy:指定資源隔離策略,THREAD或SEMAPHORE。THREAD基于線程池,每個command運行在一個線程中,限流通過線程池的大小控制。SEMAPHORE基于信號量,command運行在調用線程中,通過信號量的容量來進行限流
- command:每個command都可以設置一個名稱和一個組。通過command group來定義一個線程池,并聚合一些監控和報警信息,同一個command group的請求會進入同一個線程池。默認threadpool key就是command group的名稱。
- coreSize:線程池大小,默認10
- queueSizeRejectionThreshold:隊列的最大大小,默認值5。HystrixCommand提交到線程池之前,會先進入一個隊列,隊列滿后,才會拒絕。
- execution.isolation.semaphore.maxConcurrentRequests:使用信號量策略時,允許訪問的最大并發量,超過這個并發量直接被拒絕。默認是10。信號量是基于調用線程去執行command的,而且不能從timeout中抽離,因此一旦設置的太大,而且有延時發生,可能瞬間導致tomcat本身的線程資源本占滿
Hystrix選擇用線程池機制來進行資源隔離,要面對的場景如下:
- 每個服務都會調用幾十個后端依賴服務,那些后端依賴服務通常是由很多不同的團隊開發的
- 每個后端依賴服務都會提供它自己的client調用庫,比如說用thrift的話,就會提供對應的thrift依賴
- client調用庫隨時會變更
- client調用庫隨時可能會增加新的網絡請求的邏輯
- client調用庫可能會包含諸如自動重試,數據解析,內存中緩存等邏輯
- client調用庫一般都對調用者來說是個黑盒,包括實現細節,網絡訪問,默認配置,等等
- 在真實的生產環境中,經常會出現調用者,突然間驚訝的發現,client調用庫發生了某些變化
- 即使client調用庫沒有改變,依賴服務本身可能有會發生邏輯上的變化
- 有些依賴的client調用庫可能還會拉取其他的依賴庫,而且可能那些依賴庫配置的不正確
- 大多數網絡請求都是同步調用的
- 調用失敗和延遲,也有可能會發生在client調用庫本身的代碼中,不一定就是發生在網絡請求中
線程池隔離技術的設計原則:艙壁隔離技術,來將外部依賴進行資源隔離,進而避免任何外部依賴的故障導致本服務崩潰。Hystrix對每個外部依賴用一個單獨的線程池,這樣的話,如果對那個外部依賴調用延遲很嚴重,最多就是耗盡那個依賴自己的線程池而已,不會影響其他的依賴調用。必須默認遠程調用庫就很不靠譜,而且隨時可能各種變化,所以就要用強制隔離的方式來確保任何服務的故障不能影響當前服務
線程池機制的優點:
- 任何一個依賴服務都可以被隔離在自己的線程池內,即使自己的線程池資源填滿了,也不會影響任何其他的服務調用
- 服務可以隨時引入一個新的依賴服務,因為即使這個新的依賴服務有問題,也不會影響其他任何服務的調用
- 當一個故障的依賴服務重新變好的時候,可以通過清理掉線程池,瞬間恢復該服務的調用,而如果是tomcat線程池被占滿,再恢復就很麻煩
- 如果一個client調用庫配置有問題,線程池的健康狀況隨時會報告,比如成功/失敗/拒絕/超時的次數統計,然后可以近實時熱修改依賴服務的調用配置,而不用停機
- 如果一個服務本身發生了修改,需要重新調整配置,此時線程池的健康狀況也可以隨時發現,比如成功/失敗/拒絕/超時的次數統計,然后可以近實時熱修改依賴服務的調用配置,而不用停機
- 基于線程池的異步本質,可以在同步的調用之上,構建一層異步調用層
線程池機制的缺點:
- 最大的缺點就是增加了cpu的開銷
- 每個command的執行都依托一個獨立的線程,會進行排隊,調度,還有上下文切換
- Hystrix官方自己做了一個多線程異步帶來的額外開銷,通過對比多線程異步調用+同步調用得出,Netflix API每天通過hystrix執行10億次調用,每個服務實例有40個以上的線程池,每個線程池有10個左右的線程。最后發現說,用hystrix的額外開銷,就是給請求帶來了3ms左右的延時,最多延時在10ms以內,相比于可用性和穩定性的提升,這是可以接受的
本文來自博客園,作者:難得,轉載請注明原文鏈接:http://www.rzrgm.cn/zhangbLearn/p/18829374

 浙公網安備 33010602011771號
浙公網安備 33010602011771號