
Maui 實踐:用 Channel 實現數據庫查詢時讀取速度與內存占用的平衡
作者:夏群林 原創 2025.7.17
我們在進行數據庫查詢時,通常并不是為了取得整個表的數據,而是某些符合過濾條件的記錄。比如:
var unassociatedSudokus = await _dbContext.DbSudokus
.Where(s => !relatedSudokuIds.Contains(s.ID))
.ToListAsync();
這里 relatedSudokuIds 元素不多,過濾條件 s => !relatedSudokuIds.Contains(s.ID) 簡單,運算量不大。所以,一切正常。
但我們經常會加入別的過濾條件,比如:
var unassociatedSudokus = await _dbContext.DbSudokus
.Where(s => !relatedSudokuIds.Contains(s.ID) && string.Join(string.Empty, s.Ans) == targetAns)
.ToListAsync();
過濾條件 string.Join(string.Empty, s.Ans) == targetAns 還算簡單,但因為在讀取數據表的時候現場裝配 s.Ans,速度變慢,記錄量大時,延遲明顯。
推薦方案,是在數據庫設計層面優化,添加一個存儲拼接后結果的字段并建立索引。一般來說,可以從根本上解決讀取速讀慢的問題。
偏偏我的應用,DbSudokus 表非常大,而需要這種查詢的場景,卻不多。我舍不得多加一個 Column,讓 DbSudokus 數據表無謂地臃腫。
另一個方案,數據庫加載階段簡單過濾,將拼接之類的復雜過濾運算放在數據庫加載之后,在內存里過濾:
var unassociatedSudokus = await _dbContext.DbSudokus
.Where(s => !relatedSudokuIds.Contains(s.ID))
.ToListAsync();
unassociatedSudokus = [.. unassociatedSudokus.Where(s => string.Join(string.Empty, s.Ans) == targetAns)];
代價是一次性加載全部數據,內存占用過多。尤其在我的應用的情形,數據表本身很大,過濾后的結果集很小,總覺得不劃算。
于是想到用 Channel。
Channel 主要是通過流處理的方式來平衡性能和內存占用。原理是:
- 先從數據庫分批讀取數據(避免一次性加載全部數據)
- 通過 Channel 將數據逐個或批量傳遞到消費者
- 在消費者端進行內存中的字符串拼接和比較等耗時運算
- 只保留符合條件的結果
這樣既避免了在數據庫中執行復雜操作,如字符串拼接等,可能無法有效利用索引,又避免了一次性加載所有數據導致的高內存占用。數據一邊讀取一邊處理,通過批次大小和通道容量,可以限制同時加載到內存中的數據量,而且流處理,不需要等待全部數據加載完成。預計到結果集很小時,大部分數據需要被過濾掉,使用 Channel 優勢明顯,在流處理讀取過程中盡早過濾掉不需要的數據,自然降低了內存占用。
我的想法,把過濾條件切分兩部分:
第一,簡單的部分,放在數據庫加載階段,有 Channel 的生產者處理,并且可接受消費者的通知,提前結束數據庫讀入:
// 生產者任務:支持提前終止
var producerTask = Task.Run(async () =>
{
try
{
var page = 0;
while (!stopProcessing) // 當消費者發現足夠結果時可以提前停止
{
var batch = await _dbContext.DbSudokus
.Where(s => !relatedSudokuIds.Contains(s.ID))
.Skip(page * batchSize)
.Take(batchSize)
.ToListAsync(cancellationToken);
if (batch.Count == 0)
break;
foreach (var sudoku in batch)
{
// 再次檢查是否需要停止,避免寫入多余數據
if (stopProcessing) break;
await channel.Writer.WriteAsync(sudoku, cancellationToken);
}
page++;
}
}
finally
{
channel.Writer.Complete();
}
});
第二,復雜的部分,
// 消費者任務:找到足夠結果后可以提前停止
var consumerTask = Task.Run(async () =>
{
await foreach (var sudoku in channel.Reader.ReadAllAsync(cancellationToken))
{
// 檢查是否已經找到足夠的結果
if (maxResults.HasValue && result.Count >= maxResults.Value)
{
stopProcessing = true;
break;
}
// 內存中過濾
var ansString = string.Join(string.Empty, sudoku.Ans);
if (ansString == targetAns)
{
result.Add(sudoku);
}
}
});
如果知道大概的結果數量,可以設置 maxResults 參數,得到額外的提前終止的好處。例如,如果通常只需要找到 1-2 條匹配結果,就可以將 maxResults 設為 2,系統會在找到 2 條結果后立即停止所有操作。
進一步,我們可以把上面的做法泛型化,核心是分離數據庫端和內存端篩選邏輯,以兼顧性能和靈活性。具體做法,是把篩選邏輯包裝成委托,作為參數傳入。
最后,給出我的實現代碼。這是一個 LINQ 風格 IQueryable
(以下是更新版本,根據 @韋家小寶 意見修改。在此致謝!)
using Microsoft.EntityFrameworkCore;
using System.Linq.Expressions;
namespace Zhally.Sudoku.Data;
public static class QueryFilterExtensions
{
/// <summary>
/// 流式篩選IQueryable數據,平衡性能和內存占用
/// </summary>
/// <typeparam name="T">實體類型</typeparam>
/// <param name="query">原始查詢</param>
/// <param name="productionFilter">數據庫端篩選表達式(生產階段)</param>
/// <param name="consumptionFilter">內存端篩選委托(消費階段)</param>
/// <param name="batchSize">批次大小</param>
/// <param name="maxResults">最大結果數量(達到后提前終止)</param>
/// <returns>篩選后的結果列表</returns>
public static async Task<List<T>> FilterWithChannelAsync<T>(
this IQueryable<T> query,
Expression<Func<T, bool>> productionFilter,
Func<T, bool> consumptionFilter,
int batchSize, int? maxResults,
CancellationToken token)
where T : class
{
// 創建有界通道控制內存占用
var channel = Channel.CreateBounded<T>(new BoundedChannelOptions(2 * batchSize)
{
FullMode = BoundedChannelFullMode.Wait,
SingleReader = true,
SingleWriter = true
});
var result = new List<T>();
bool stopProcessing = false;
// 消費者任務:處理并篩選數據
async Task ComsumerAsync(CancellationToken token)
{
await foreach (var item in channel.Reader.ReadAllAsync(token))
{
// 檢查是否已達到最大結果數
if (maxResults.HasValue && result.Count >= maxResults.Value)
{
stopProcessing = true;
break;
}
// 應用內存篩選條件
if (consumptionFilter(item))
{
result.Add(item);
}
}
}
// 生產者任務:從數據庫分批讀取數據
async Task ProducerAsync(CancellationToken token)
{
try
{
var page = 0;
while (!stopProcessing)
{
// 應用數據庫篩選并分頁查詢
var batch = await query
.Where(productionFilter)
.Skip(page * batchSize)
.Take(batchSize)
.ToListAsync(token);
if (batch.Count == 0)
break; // 沒有更多數據
// 將批次數據寫入通道
foreach (var item in batch)
{
if (stopProcessing) break;
await channel.Writer.WriteAsync(item, token);
}
page++;
}
}
finally
{
channel.Writer.Complete(); // 通知消費者數據已寫完
}
}
var consumerTask = ComsumerAsync(token);
var producerTask = ProducerAsync(token);
// 等待所有任務完成
await Task.WhenAll(producerTask, consumerTask);
return result;
}
}
這種設計特別適合以下場景:
- 需要在數據庫端做初步篩選,再在內存中做復雜篩選
- 預期結果集較小,但源數據集可能很大
- 希望平衡數據庫負載和內存占用
還可以根據實際需求調整批次大小和通道容量,以獲得最佳性能。
使用示例:
var result = await _dbContext.DbSudokus
.FilterWithChannelAsync(
// 數據庫端篩選:排除關聯的Sudoku
s => !relatedSudokuIds.Contains(s.ID),
// 內存端篩選:比較拼接后的答案
s => string.Join(string.Empty, s.Ans) == targetAns,
batchSize: 100,
maxResults: null,
CancellationToken.None // 我的應用場景無大礙,建議用戶傳入自己的 token
);
多邊形戰士 補充提供了思維導圖,很棒,在評論區,推薦大家參考。
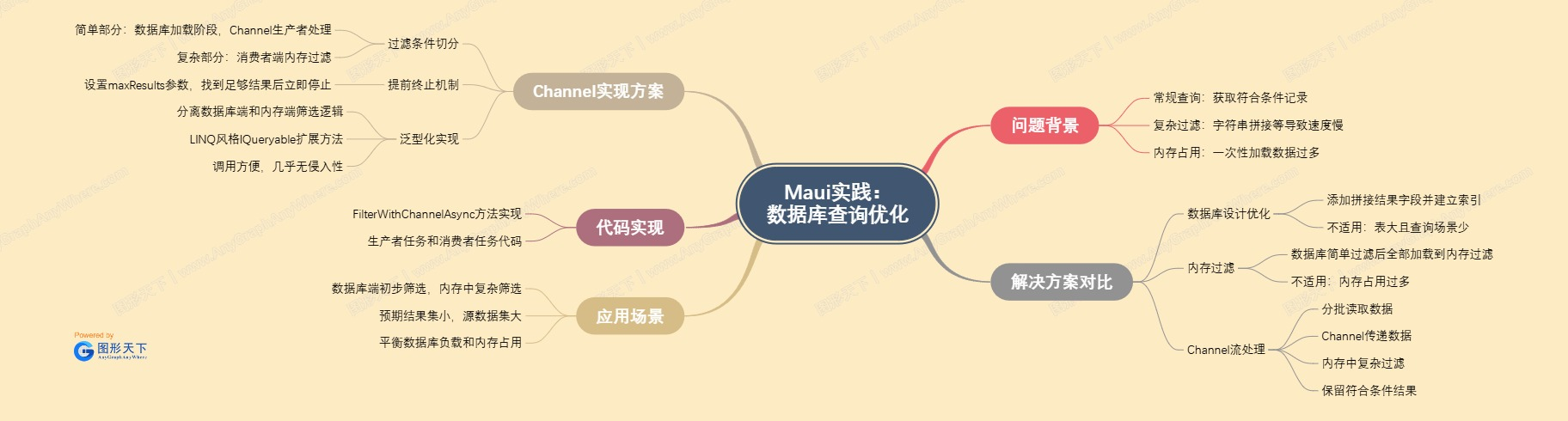
本方案源代碼開源,按照 MIT 協議許可。地址:xiaql/Zhally.Toolkit: Practices on specific tool kit in MAUI

 浙公網安備 33010602011771號
浙公網安備 33010602011771號