索一美---第一次個人編程作業
作業介紹
| 博客班級 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/ |
|---|---|
| 作業要求 | 第一次編程作業 |
| 作業目標 | 1.采集電視劇《在一起》的全部評論信息 2.數據處理3.數據分析,將采集到的評論信息做成詞云圖 |
| 作業源代碼 | first-personal_work |
| 學號 | 211606618 |
時間分布
| 步驟 | 具體做法 | 時間 |
|---|---|---|
| 數據采集 | 采集騰訊視頻里電視劇《在一起》的全部評論信息 | 1.5h |
| 數據處理 | 把所有數據下載到本地保存到json文件里面comments.json, 頁面用js讀取文件 | nh |
| 數據分析 | 將采集到的評論信息做成詞云圖 | nh |
| 上傳代碼到Github | 上傳到Github | nh |
前言
看到這次作業我是慌亂的,看完作業要求無從下手,很多內容都是新知識,尤其是爬蟲,之前沒有接觸過,上學期聽大數據的同學常常討論爬蟲啊,反爬蟲啊,異步加載之類的。開始之前我先學習了與爬蟲相關的基礎知識,接著下載了pycharm進行數據采集。在學習過程中查資料和詢問同學對我的幫助很大。讓我對爬蟲,詞云圖有了初步了解。
具體步驟
一、采集影評數據
1.打開騰訊視頻電視劇《在一起》的全部影評
2.按下Fn+F12,點擊加載更多評論,按下Fn+F5刷新界面,可以看到會有多個以“v2?”開頭的文件
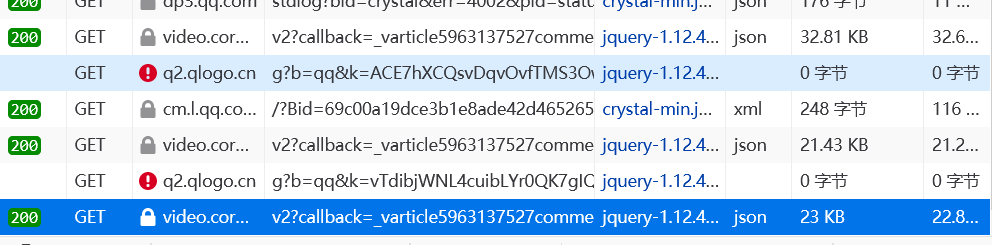
3.多次點擊加載更多評論,出現新的響應,獲取到請求后,我們對這兩的requesturl進行仔細分析,發現第二個url里的cursor值,是第一個url的preview里last的值,然后第一個url的最后1位數字+1,就是第二個url,即找到規律



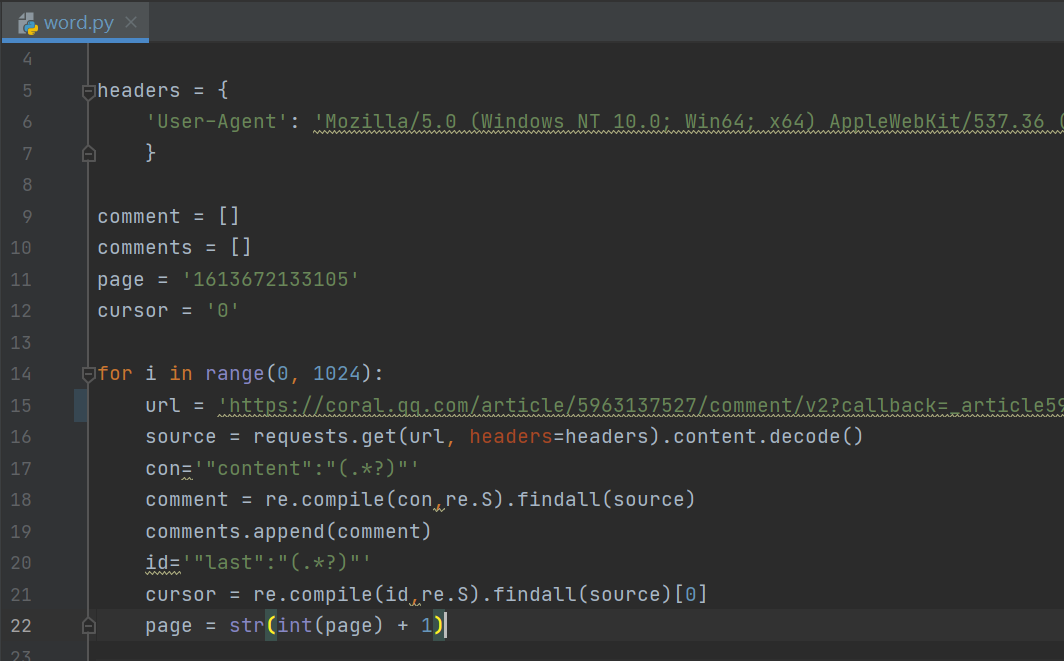
4.找到規律后,開始爬取數據,主要的思路是:抓取url地址-→遍歷所有url-→正則提取評論-→保存結果為.json
主要代碼:
二、數據處理
這里用的是jieba分詞器分詞,統計評論中的高頻詞及數量。jieba下載花費較長的時間,代碼這塊問題也比較大,問了問同學,參考她們的代碼費勁的開始數據處理,這些知識對于我可以說是全新的,出現各種各樣的問題,運行的時候庫不存在,才知道自己沒有導入庫。在PyCharm里我覺得有一個好處就是,可以在settings設置添加庫。準備工作做好以后,開始分詞。
主要代碼:
三、數據分析
結合js插件echarts.js和echarts-wordcloud.min.js完成index.html

四、上傳代碼到Github
詳細步驟:
1.在文件夾右鍵,點擊 Git Bash Here。
2.git init,進行初始化。
3.git remote add origin 倉庫地址,連接倉庫。
4.cd first-personal-work,進入文件夾。
5.git checkout -b crawl,切換分支。
6.git add 文件名,將文件添加到暫存區。
7.git commit -m "注釋",提交到版本庫。
注釋的時候是中文命令出錯,無法在運行,Ctrl+C才退出去,繼續運行。
8.git push -u origin crawl,推送到遠程倉庫。
9.按上述步驟依次將文件提交到遠程倉庫。
10.git checkout main,切換分支。
11.git merge crawl 和 git merge chart,合并分支。
合并分支出現問題,只把chart合并到main,crawl無法合并,反復做了幾次都不對,每次都顯示已合并,錯誤太多無法挽救。
總結
這次作業對我來說是個很大的挑戰,許多新知識需要去學習去摸索,雖然過程很艱難,腦子不斷輸入各種知識點,但是在完成后心情還是蠻不錯的哈哈哈哈哈。再啰嗦幾句,這次作業可能做的不是很完善,存在許多的瑕疵,這也是給我敲了一個警鐘,知道自己很多的不足之處,還需要下功夫,不然與別人差距會越來越大。我希望自己可以通過這次作業,在以后的學習中,再遇到困難,能夠克服一切,更加努力更加認真的去學習。
參考文獻
“jieba”中文分詞:Python 中文分詞組件
echarts相關知識
Echarts中詞云圖的構造
Git官網


 浙公網安備 33010602011771號
浙公網安備 33010602011771號