

實用指南:Your ViT is Secretly an Image Segmentation Model
論文基本信息 (Basic Information)
| 標題 (Title) | Your ViT is Secretly an Image Segmentation Model |
|---|---|
| Adress | https://arxiv.org/pdf/2503.19108 |
| Journal/Time | CVPR2025 |
| Author | 荷蘭Eindhoven University of Technology\ 意大利Polytechnic of Turin\ 德國RWTH Aachen University |
| Code | https://www.tue-mps.org/eomt/ |
1. 核心思想 (Core Idea)
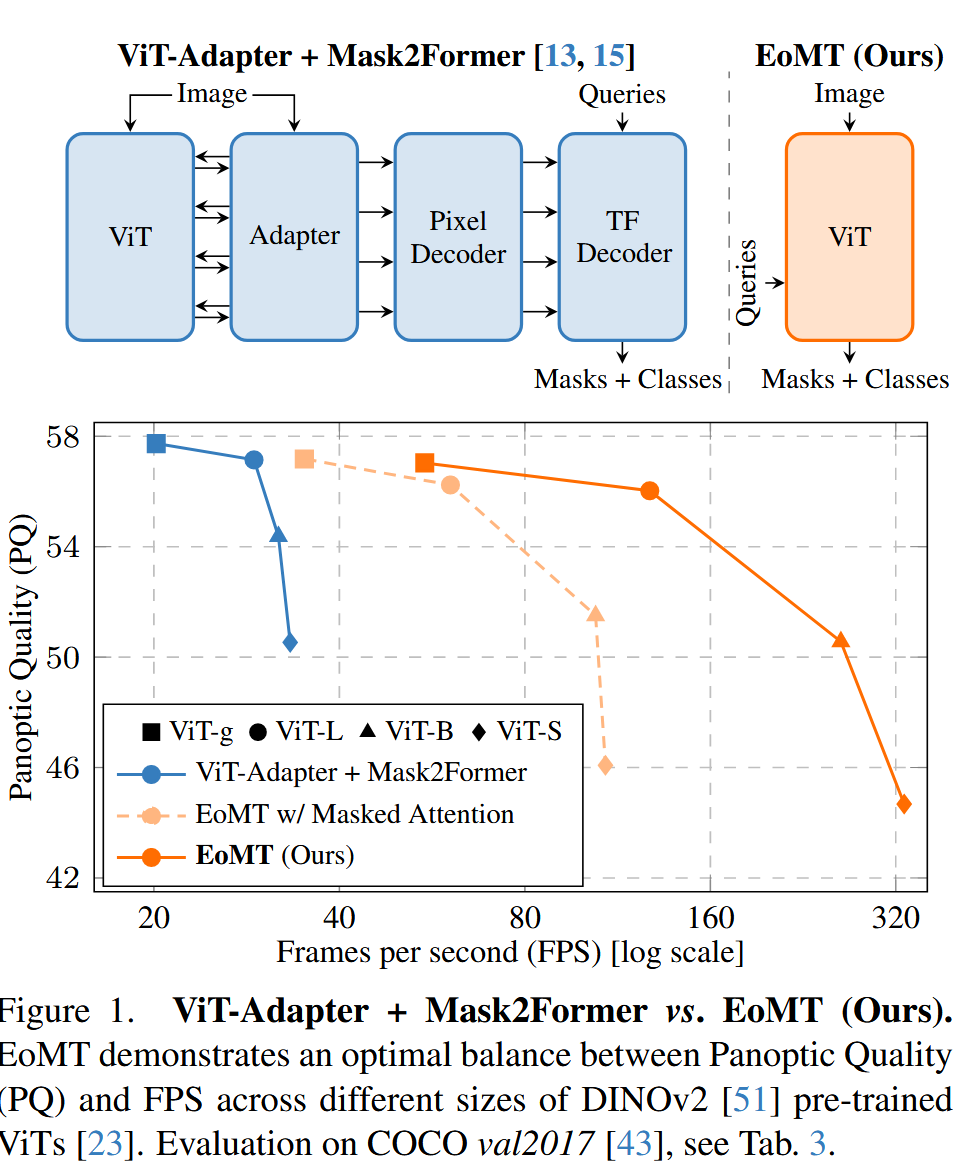
就是將之前的 ViT-Adapter + Mask2Former 變成了 只有 ViT的,在ViT的后面部分進行了一些小改動,達到了 sota。
疑問 (Problem):當前將視覺Transformer(ViT)應用于圖像分割任務的SOTA途徑(如ViT-Adapter + Mask2Former)架構過于困難。它們普遍依賴于多個為引入卷積歸納偏置而設計的附加組件:1) Adapter,用于生成多尺度特征;2) Pixel Decoder,用于融合多尺度特征;3) Transformer Decoder,用于處理可學習查詢(queries)并與圖像特征交互。這些組件雖然有效,但導致模型臃腫、計算密集、推理速度慢,且難以實現和優化。
核心假設 (Hypothesis):當ViT骨干網絡足夠大,并且經過了足夠強大的大規模預訓練(如DINOv2)后,ViT自身已經具備了學習這些歸納偏置的能力,不再需要這些復雜的外部組件。
解決方法 (Solution):基于該假設,作者提出了一種極簡的僅編碼器掩碼Transformer (Encoder-only Mask Transformer, EoMT)。該方法移除了所有上述的附加組件,通過將可學習的分割查詢(queries)直接注入到ViT編碼器的中間層,讓編碼器的后半部分同時承擔特征提取和解碼的功能。這種設計極大地簡化了模型架構,使其回歸到一個幾乎純粹的ViT結構,從而在保持高精度的同時,實現了數倍的推理速度提升。
2. 研究背景與動機 (Background and Motivation)
動機 (Motivation):追求模型設計的簡潔性(Simplicity)和推理效率(Efficiency)。作者觀察到,為了讓ViT適用于分割任務,研究社區陷入了一種不斷“做加法”的模式,借助堆疊各種模塊來彌補ViT所謂的“原生缺陷”(如缺乏多尺度能力)。這導致模型越來越復雜,違背了ViT誕生時簡潔統一的初衷,也使其難以完全享受底層計算庫(如FlashAttention)對標準Transformer架構的優化紅利。就是核心動機
與前人研究的不同 (The Difference):
思路上的根本對立:之前的工作(ViT-Adapter, Mask2Former等)是在“幫忙”ViT”,需要外部模塊來“賦能”;而本文則認為一個“強大”的ViT“天生就行”,之前的外部模塊在高水平的預訓練和模型規模面前是“冗余的輔助輪”。這是一種從“做加法”到“做減法”的范式轉變。
經過“復用”編碼器的一部分來完成解碼作用。這與YOLOS等早期探索encoder-only的模型相比,在方法上更純粹,并且首次系統性地證明了這種極簡設計在強大的基礎模型加持下,性能上可以與麻煩SOTA模型相媲美。就是架構上的極簡主義:EoMT幾乎完全拋棄了獨立解碼器的概念,而
疑問的提出方式 (How the question is proposed):論文的切入點非常精彩。它首先清晰地描繪了當前SOTA分割模型的復雜管線(ViT + Adapter + Pixel Decoder + Transformer Decoder),然后直接提出兩個核心假設作為待驗證的命題:
- 大規模預訓練(特殊是MIM)已經教會了ViT提取分割所需的細粒度信息,因此額外的輔助組件可能不再必要。
- 更大的模型容量允許ViT在沒有這些附加組件的情況下直接勝任分割任務。
3. 方法論 (Methodology)
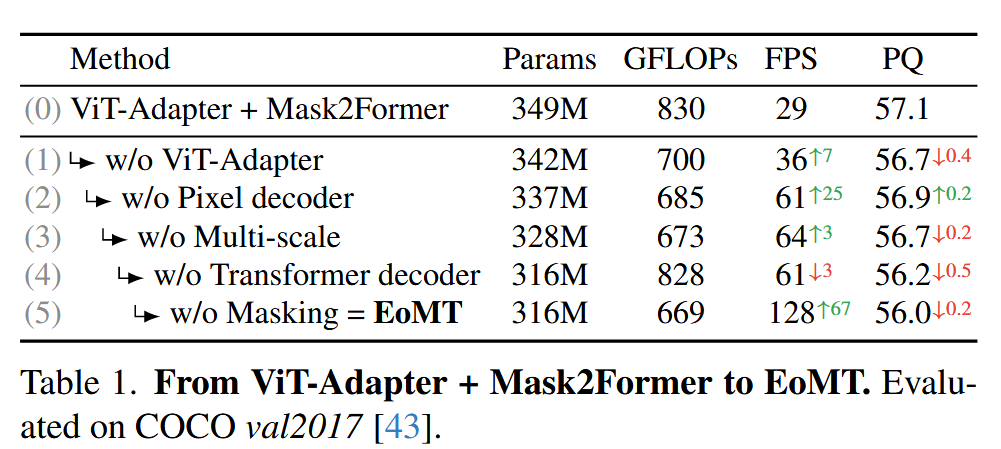
EoMT的構建過程可以看作是一場“拆解實驗”,從一個復雜的SOTA模型逐步簡化而來:
逐步拆解 (Step-by-step removal):
- 基線: ViT-Adapter + Mask2Former。
- 步驟1 (w/o ViT-Adapter):移除Adapter,用容易的轉置卷積和卷積從ViT的單尺度輸出(e.g.,
1/16)生成一個簡化的特征金字塔。 - 步驟2 (w/o Pixel Decoder):進一步移除Pixel Decoder,將上述簡化的特征金字塔直接送入Transformer
Decoder。 - 步驟3 (w/o Multi-scale):移除多尺度特征處理,Transformer Decoder只與ViT的原始單尺度輸出F_vit進行交互。
- 步驟4 (w/o Transformer Decoder) -> EoMT誕生: 徹底移除獨立的Transformer Decoder。
EoMT 架構: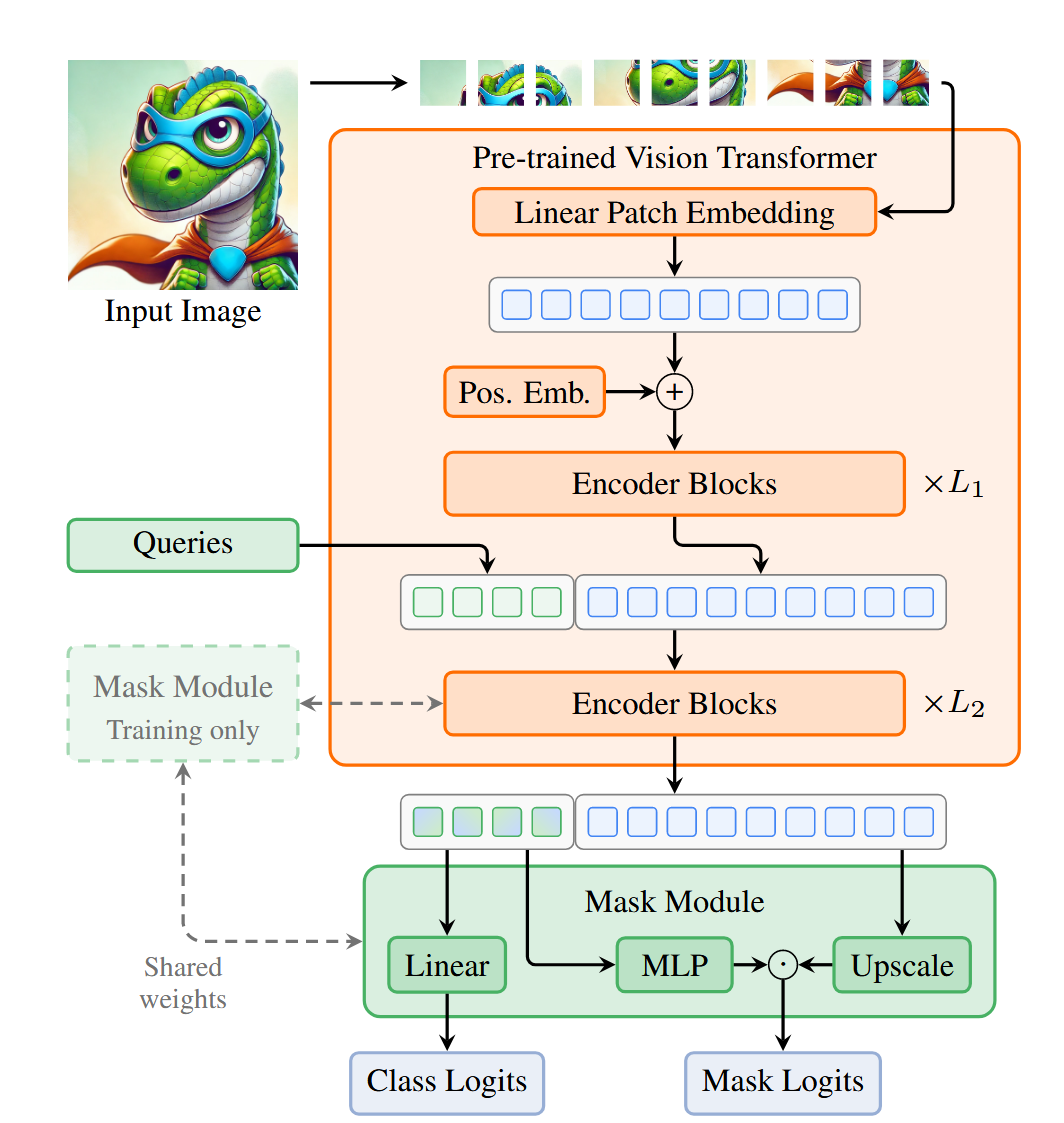
Query注入: 將K個可學習的分割查詢(queries)在ViT的第L1 個block之后,與patch tokens進行拼接(Concatenate)。
聯合處理: 拼接后的序列(具備patch tokens和query tokens)共同送入剩余的L2個ViT block中。在這些block里,標準的自注意力機制會自然地處理四種交互:patch-patch, patch-query, query-patch, query-query。這巧妙地復用編碼器層來搭建了傳統解碼器的效果。
預測頭: 經過所有L個block后,取出最終的query tokens,通過一個輕量的MLP預測類別(Class Logits)和掩碼(Mask Logits)。
Mask Annealing (掩碼退火):
動機:Mask2Former中的masked attention機制在訓練時能提升精度,但在推理時需要計算中間掩碼,非常耗時。
策略:在訓練初期,masked attention以100%的概率被采用,以幫助模型穩定收斂。隨著訓練的進行,這個概率會分層、逐步地衰減(anneal)到0。例如,先讓第21個block的mask概率衰減,再到第22個,以此類推。
效果:模型在訓練后期逐漸“忘記”對masked attention的依賴,從而在推理時行完全關閉它,大大提升速度,同時性能損失極小。
4. 實驗結果 (Experimental Results)
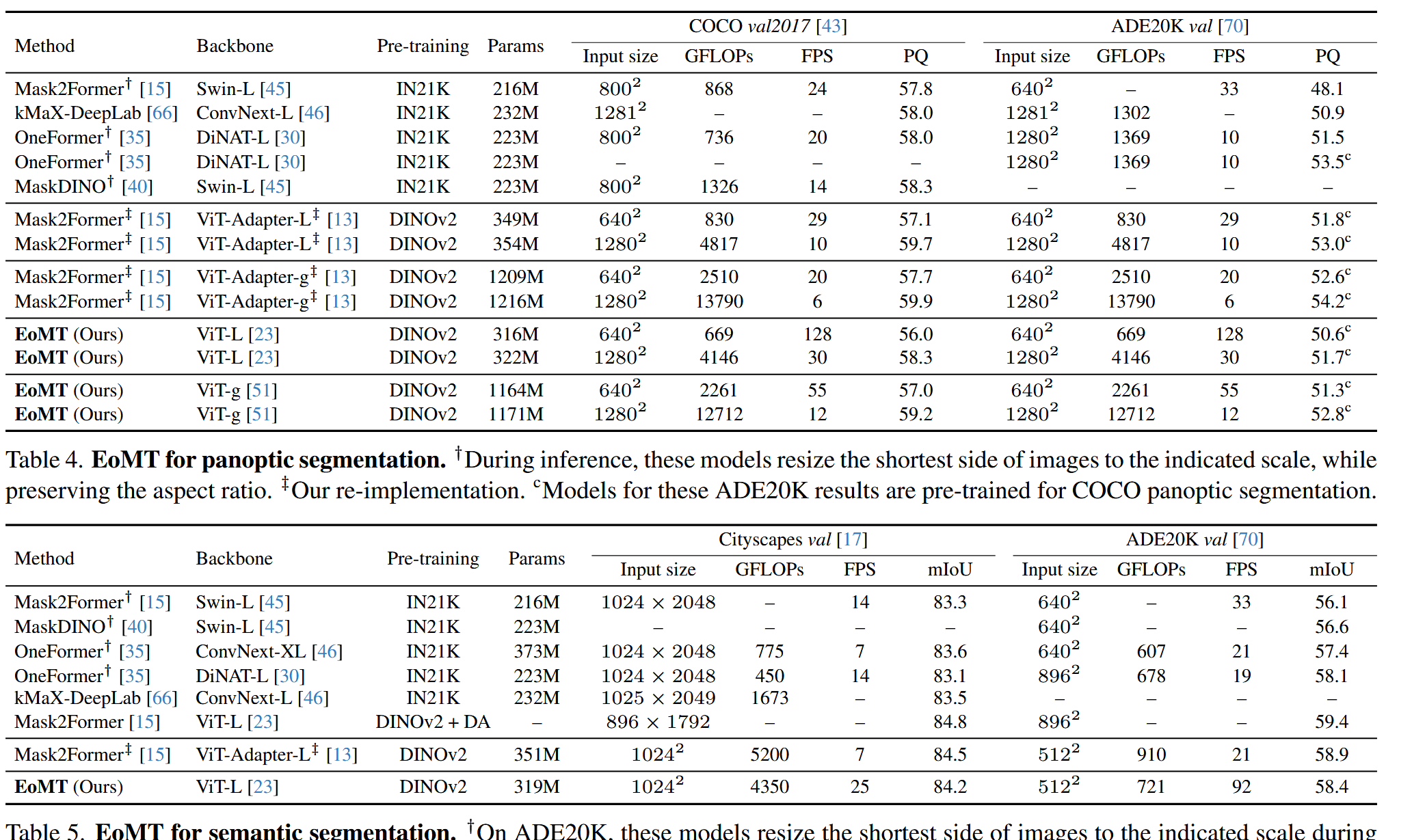
核心消融實驗 (Table 1):從ViT-Adapter+M2F逐步簡化到EoMT,在COCO數據集上,模型速度提升了4.4倍 (29 -> 128 FPS),而精度(PQ)僅從57.1輕微下降到56.0。這證明了復雜組件的“可替代性”。
預訓練的影響 (Table 2):使用弱的ImageNet預訓練時,EoMT與復雜模型的性能差距較大(-3.9 PQ);但當換用強大的DINOv2預訓練時,差距迅速縮小到-1.1 PQ。這證明了強大的預訓練是簡化架構的前提。
模型規模的影響 (Table 3 & Figure 1):隨著ViT模型從Small增大到Giant,EoMT與艱難模型的性能差距從-5.8 PQ縮小到-0.7 PQ。這證明了模型規模是彌補歸納偏置缺失的關鍵。Figure 1的精度-速度曲線清晰地表明,EoMT在所有模型尺寸上都給出了更優的帕累托前沿。
實例分割,EoMT都取得了與SOTA方法(如Mask2Former, OneFormer)相當甚至更好的“精度-速度”權衡。就是各大基準測試 (Tables 4, 5, 6):在COCO, ADE20K, Cityscapes等主流內容集上,無論是全景、語義還
附加優勢:
- OOD泛化 (Table 8):得益于DINOv2預訓練和純ViT架構,EoMT在分布外(OOD)素材集上的泛化能力遠強于使用Swin或ConvNeXt等架構的SOTA模型。
- 兼容性 (Table 9):EoMT的簡潔架構使其能無縫接入ViT的生態優化,如Token Merging,進一步提升吞吐量;而帶有復雜Adapter的模型則因為需解耦和交互,無法獲得同樣的速度增益。
5. 結論與討論 (Conclusion & Discussion)
通過核心結論:對于圖像分割任務,架構的復雜性能夠被模型規模和預訓練的質量所替代。一個經過大規模自監督預訓練的大尺寸ViT,其本身就蘊含了強大的分割能力,無需再為其設計繁瑣的外部“輔助結構”。
討論與展望:這項工作倡導了一種**“少即是多”**的設計哲學。未來的研究重心或許應該從設計越來越精巧的任務頭,轉向如何更有效地擴大模型規模、提升預訓練的質量和效率。EoMT作為一個方便、可擴展的基線,為下一代分割模型的發展奠定了堅實的基礎,使其能更好地擁抱Transformer和基礎模型領域的飛速發展。
6. 核心貢獻總結 (Summary of Key Contributions)
提出并驗證了一個核心假設:系統性地證明了,隨著模型規模和預訓練水平的提升,用于圖像分割的ViT模型中復雜的任務專用組件(Adapter, Decoders)變得越來越不核心。
提出了EoMT架構:設計了一種極簡、高效的Encoder-only分割模型,它依據在編碼器內部處理分割查詢,復用了ViT的標準模塊,顯著提升了推理速度,同時保持了SOTA級的精度。
提出了Mask Annealing策略:發明了一種新穎的訓練技巧,能夠在不犧牲性能的前提下,移除推理時對計算昂貴的masked attention的依賴,進一步提升了模型的效率。
樹立了新的效率標桿:在多個分割基準上,EoMT在“精度 vs. 速度”的權衡上達到了新的SOTA水平,證明了將計算資源投入到擴展ViT本身是比增加架構復雜性更優的選擇。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號