
MySQL優(yōu)化---Count優(yōu)化、limit優(yōu)化、Update優(yōu)化
一、limit優(yōu)化
這里我有一張表tb_sku 里面有400w條數(shù)據(jù),以這個(gè)表作為案例對象

1. 未優(yōu)化案例
select * from tb_sku limit 0,10; 可以看出耗時(shí)幾乎為0,一下子就完成了
(2)查詢起始索引100w后的10條記錄
select * from tb_sku limit 1000000,10; 這里耗時(shí)要3秒多,需要的時(shí)間變長了
(3) 查詢起始索引300w后的10條記錄
select * from tb_sku limit 3000000,10; 這里耗時(shí)幾乎翻倍,要11秒多。所以越往后需要的時(shí)間就越多。
通過測試我們會(huì)看到,越往后,分頁查詢效率越低,這就是分頁查詢的問題所在。 因?yàn)椋?dāng)在進(jìn)行分頁查詢時(shí),如果執(zhí)行 limit 2000000,10 ,此時(shí)需要 MySQL 排序前 2000010 記 錄,僅僅返回 2000000 - 2000010 的記錄,其他記錄丟棄,查詢排序的代價(jià)非常大 。
優(yōu)化思路 : 一般分頁查詢時(shí),通過創(chuàng)建 覆蓋索引 能夠比較好地提高性能,可以通過覆蓋索引加子查詢形式進(jìn)行優(yōu)化。
二、 limit大分頁問題的性能優(yōu)化方法
(1)利用表的覆蓋索引來加速分頁查詢
MySQL的查詢完全命中索引的時(shí)候,稱為覆蓋索引,是非常快的。因?yàn)椴樵冎恍枰谒饕线M(jìn)行查找之后可以直接返回,而不用再回表拿數(shù)據(jù)。
在我們的例子中,我們知道id字段是主鍵,自然就包含了默認(rèn)的主鍵索引。現(xiàn)在讓我們看看利用覆蓋索引的查詢效果如何。
select id from test limit 1000000, 20 ; //0.2秒
那么如果我們也要查詢所有列,如何優(yōu)化?
優(yōu)化的關(guān)鍵是要做到讓MySQL每次只掃描20條記錄,我們可以使用limit n,這樣性能就沒有問題,因?yàn)镸ySQL只掃描n行。我們可以先通過子查詢先獲取起始記錄的id,然后根據(jù)Id拿數(shù)據(jù):
select * from test where id>=(select id from test limit 1000000,1) limit 20;
(2)延遲關(guān)聯(lián)(覆蓋索引 + JOIN)
和上述的子查詢做法類似,我們通過先掃描出對應(yīng)的主鍵,然后再回表查詢出對應(yīng)的列,極大的減少了MySQL對數(shù)據(jù)頁的掃描。
即先利用limit分頁查詢找到所需記錄的主鍵(比如ID)生成派生表,再通過主鍵作為連接條件與原表進(jìn)行join連接。
select a.* from test a inner join (select id from test limit 1000000,20) b on a.id=b.id;
注意:如果不使用ORDER BY對主鍵或者索引字段進(jìn)行排序,結(jié)果集返回不穩(wěn)定(如某次返回1,2,3,另外的一次返回2,1,3)。
(3)用上次分頁的最大id優(yōu)化(效果最好,推薦使用)
優(yōu)化思路是使用某種變量記錄上一次數(shù)據(jù)的位置,下次分頁時(shí)直接從這個(gè)變量的位置開始掃描,從而避免MySQL掃描大量的數(shù)據(jù)再拋棄的操作。
例如:先找到上次分頁的最大ID,然后利用id上的索引來查詢:
select * from test where id>1000000 limit 100 ;
說明:優(yōu)化方法中所有的例子都是基于id為主鍵這個(gè)前提,不能使用索引字段,否則會(huì)出現(xiàn)返回?cái)?shù)據(jù)記錄數(shù)不對的情況。
三、count優(yōu)化
select count(*) from tb_user ;
MyISAM 引擎把一個(gè)表的總行數(shù)存在了磁盤上,因此執(zhí)行 count(*) 的時(shí)候會(huì)直接返回這個(gè) 數(shù),效率很高; 但是如果是帶條件的count,MyISAM也慢。 InnoDB 引擎就麻煩了,它執(zhí)行 count(*) 的時(shí)候,需要把數(shù)據(jù)一行一行地從引擎里面讀出 來,然后累積計(jì)數(shù)。 我們都知道MySQL一般主要用到的引擎就是InnoDB 引擎,如果說要大幅度提升InnoDB 表的 count 效率,主要的優(yōu)化思路:自己計(jì)數(shù) ( 可以借助于 redis 這樣的數(shù)據(jù)庫進(jìn)行, 但是如果是帶條件的 count 又比較麻煩了 ) 。所以下面我們要進(jìn)一步了解count聚合函數(shù)的使用。 count用法 count() 是一個(gè)聚合函數(shù),對于返回的結(jié)果集,一行行地判斷,如果 count 函數(shù)的參數(shù)不是 NULL ,累計(jì)值就加 1 ,否則不加,最后返回累計(jì)值。 用法: count ( * )、 count (主鍵)、 count (字段)、 count (數(shù)字)

注意: count(null)為0 ==》值為Null的時(shí)候都不計(jì)數(shù),只要值不為Null其它的都計(jì)1,比如count(-1)和count(1)結(jié)果一致,
只不過count(-1)是在每一行維護(hù)著一個(gè)-1的值, 后面對齊進(jìn)行累計(jì)數(shù)量,count(1)是在每一行維護(hù)一個(gè)1的值
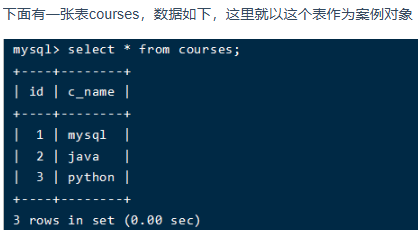
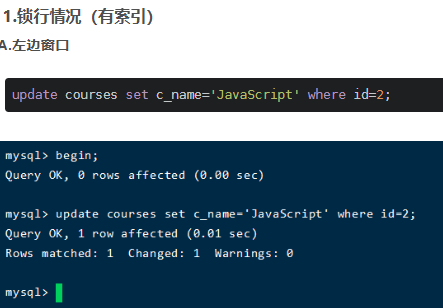
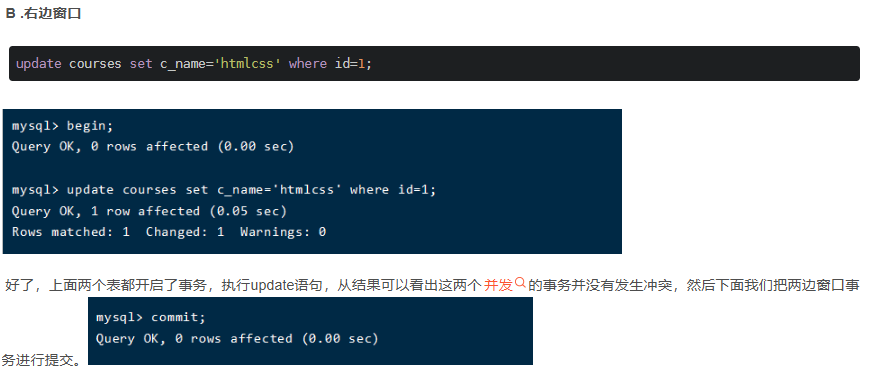
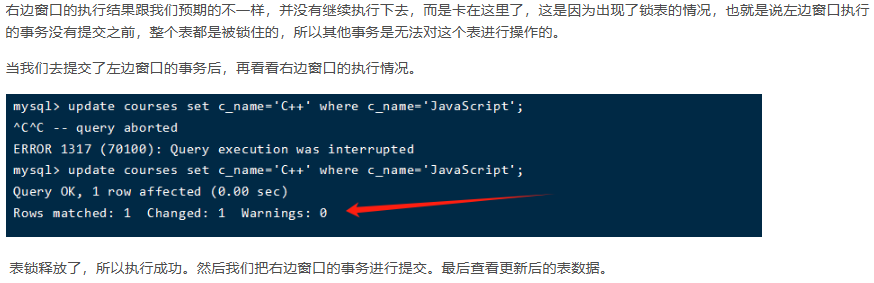
四、update優(yōu)化




來源:https://blog.csdn.net/m0_73633088/article/details/137779994

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號