
MySQL 性能定位
一、SQL性能分析

1.SQL執行頻率
MySQL 客戶端連接成功后,通過 show [session|global] status 命令可以提供服務器狀態信息。通過如下指令,可以查看當前數據庫的 INSERT 、 UPDATE 、 DELETE 、 SELECT 的訪問頻次:
-- session 是查看當前會話 ;
-- global 是查詢全局數據 ;
SHOW GLOBAL STATUS LIKE 'Com_______';
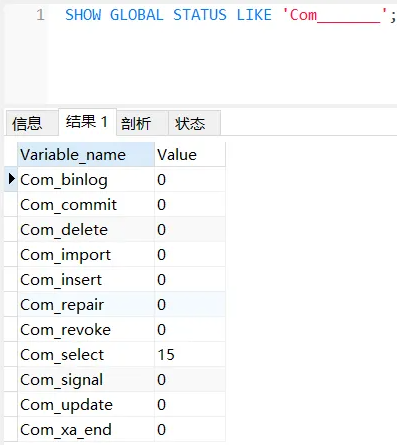
Com_delete: 刪除次數 Com_insert: 插入次數
Com_select: 查詢次數 Com_update: 更新次數
我們可以在當前數據庫再執行幾次查詢操作,然后再次查看執行頻次,看看 Com_select 參數會不會變化。
通過上述指令,我們可以查看到當前數據庫到底是以查詢為主,還是以增刪改為主,從而為數據庫優化提供參考依據。 如果是以增刪改為主,我們可以考慮不對其進行索引的優化。 如果是以查詢為主,那么就要考慮對數據庫的索引進行優化了
那么通過查詢SQL的執行頻次,我們就能夠知道當前數據庫到底是增刪改為主,還是查詢為主。 那假如說是以查詢為主,我們又該如何定位針對于那些查詢語句進行優化呢? 我們可以借助于慢查詢日志。
2.慢查詢日志
慢查詢日志記錄了所有執行時間超過指定參數( long_query_time ,單位:秒,默認 10 秒)的所有SQL 語句的日志。
MySQL 的慢查詢日志默認沒有開啟,我們可以查看一下系統變量 slow_query_log 。
slow_query_log_file 慢查詢文件路徑
log_output= file 慢查詢日志的格式


3.profile詳情

show profiles 能夠在做 SQL 優化時幫助我們了解時間都耗費到哪里去了。通過 have_profiling參數,能夠看到當前 MySQL 是否支持 profile 操作:
SELECT @@have_profiling ;
開關已經打開了,接下來,我們所執行的SQL語句,都會被MySQL記錄,并記錄執行時間消耗到哪兒去了。 我們直接執行如下的SQL語句:
select * from tb_user;
select * from tb_user where id = 1;
select * from tb_user where name = '白起';
select count(*) from tb_user;
執行一系列的業務 SQL 的操作,然后通過如下指令查看指令的執行耗時:
-- 查看每一條SQL的耗時基本情況
show profiles;
-- 查看指定query_id的SQL語句各個階段的耗時情況
show profile for query query_id;
-- 查看指定query_id的SQL語句CPU的使用情況
show profile cpu for query query_id;
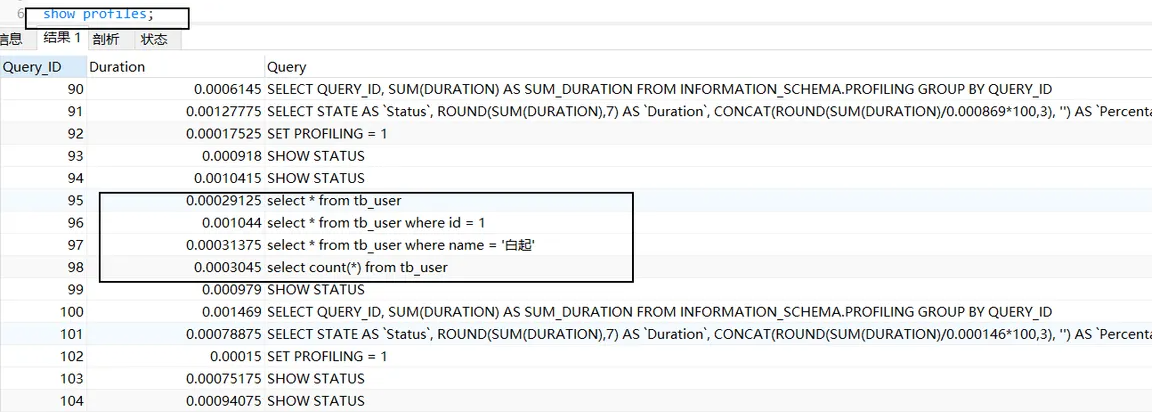
查看指定SQL各個階段的耗時情況 :
show profile for query 97;

4.explain分析
EXPLAIN 或者 DESC 命令獲取 MySQL 如何執行 SELECT 語句的信息,包括在 SELECT 語句執行過程中表如何連接和連接的順序
-- 直接在select語句之前加上關鍵字 explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 條件 ;






在MySQL中,EXPLAIN語句用于分析查詢的執行計劃,幫助開發者理解MySQL是如何執行查詢的。EXPLAIN輸出中的type列是一個非常重要的屬性,它描述了表的訪問類型,即MySQL是如何找到匹配行的。以下是type屬性的可能值及其含義: system 描述: 表中只有一行數據(系統表)。這是const類型的一個特例。 示例: EXPLAIN SELECT * FROM mysql.user WHERE User='root'; const 描述: 查詢到唯一一行記錄,常用于主鍵或唯一索引與常量值比較的情況。 示例: EXPLAIN SELECT * FROM users WHERE id=1; eq_ref 描述: 多表關聯查詢中,對于前表的每一行,后表只有一行與之匹配。常用于主鍵或唯一索引的關聯。 示例: EXPLAIN SELECT * FROM orders o JOIN users u ON o.user_id = u.id; ref 描述: 非唯一索引的等值查詢,可能返回多行。 示例: EXPLAIN SELECT * FROM users WHERE name='John'; fulltext 描述: 使用全文索引進行查詢。 示例: EXPLAIN SELECT * FROM articles WHERE MATCH(content) AGAINST('keyword'); ref_or_null 描述: 類似于ref,但是還會額外搜索包含NULL值的行。 示例: EXPLAIN SELECT * FROM users WHERE email='john@example.com' OR email IS NULL; index_merge 描述: 多個索引被合并使用。 示例: EXPLAIN SELECT * FROM users WHERE name='John' OR age=30; unique_subquery 描述: 用于某些IN子查詢的情況,取代了eq_ref。 示例: EXPLAIN SELECT * FROM users WHERE id IN (SELECT user_id FROM orders WHERE status=1); index_subquery 描述: 與unique_subquery類似,但用于非唯一索引。 示例: EXPLAIN SELECT * FROM users WHERE name IN (SELECT name FROM orders WHERE status=1); range 描述: 使用索引進行范圍查詢(如BETWEEN, IN, >等)。 示例: EXPLAIN SELECT * FROM users WHERE age BETWEEN 20 AND 30; index 描述: 全索引掃描,與ALL類似,但只遍歷索引樹,通常比ALL快。 示例: EXPLAIN SELECT name FROM users; ALL 描述: 全表掃描,遍歷整張表。這是最不理想的情況,通常需要優化。 示例: EXPLAIN SELECT * FROM users; 原文鏈接:https://blog.csdn.net/aliyunyyds/article/details/140550870
來源:https://blog.51cto.com/u_15011668/7734846
二、正在執行的線程查看 show processlist; +----+------+--------------------+-----------+---------+------+-------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+------+--------------------+-----------+---------+------+-------------+------------------+ | 36 | root | 172.16.100.19:7954 | tpcc_test | Sleep | 456 | | NULL | | 37 | root | 172.16.100.19:7969 | tpcc_test | Sleep | 456 | | NULL | | 42 | root | localhost | NULL | Query | 0 | System lock | show processlist | | 43 | root | 10.0.102.204:49224 | employees | Sleep | 12 | | NULL | +----+------+--------------------+-----------+---------+------+-------------+------------------+ 4 rows in set (0.00 sec) ID:連接標識。這個值和INFORMATION_SCHEMA.PROCESSLIST表的ID列,以及PERFORMANCE_SCHEMA中的threads中的process_id值是相同的。 time: 線程已經在當前狀態的時間。 kill線程 與MySQL服務器每個鏈接都在一個單獨的線程中運行。可以使用如下語句殺死一個線程。 kill [connection| query] processlist_id connection: 與kill processlist_id相同;中斷連接正在執行的任何語句之后,中斷連接。 query: 中斷連接正在執行的語句,但是保持本身的連接。 注意: 這里需要注意的就是如果出現大量的sleep進程的話,并且時間很長的話,這種都是鏈接的客戶端在使用完鏈接沒有close造成的。這里是需要調整的屬性 wait_timeout 就是 sleep 連接最大存活時間,默認是 28800 s,換算成小時就是 8 小時,
相當于今天上班以來所有建立過而未關閉的連接都不會被清理。 這里說明一下,下面的時間單位是秒。 執行命令: show global variables like '%wait_timeout'; set global wait_timeout=250;
實用小sql(20221009)
-- 按照客戶端IP分組,看哪個客戶端的連接數最多 select client_ip, count(client_ip) as client_num from (select substring_index(host, ':', 1) as client_ip from `information_schema`.processlist) as connect_info group by client_ip order by client_num desc; -- 查看正在執行的線程,并按 Time 倒排序,看看有沒有執行時間特別長的線程 select * from `information_schema`.processlist where Command != 'Sleep' order by Time desc; -- 找出所有執行時間超過 5 分鐘的線程,拼湊出 kill 語句,方便后面查殺 select concat('kill ', id, ';') from `information_schema`.processlist where Command != 'Sleep' and Time > 300 order by Time desc;
三、查看最大鏈接數 show variables like '%max_connection%'; 查看最大連接數 set global max_connections=1000; 重新設置最大連接數 mysql> show status like 'Threads%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | Threads_cached | 32 | | Threads_connected | 10 | | Threads_created | 50 | | Threads_rejected | 0 | | Threads_running | 1 | +-------------------+-------+ 5 rows in set (0.00 sec) Threads_connected :這個數值指的是打開的連接數. Threads_running :這個數值指的是激活的連接數,這個數值一般遠低于connected數值. Threads_connected 跟show processlist結果相同,表示當前連接數。準確的來說,Threads_running是代表當前并發數
四、事務相關 # 查看正在鎖的事務 SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS; # 查看等待鎖的事務 SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
Lock wait timeout exceeded:后提交的事務等待前面處理的事務釋放鎖,但是在等待的時候超過了mysql的鎖等待時間,就會引發這個異常。
Dead Lock:兩個事務互相等待對方釋放相同資源的鎖,從而造成的死循環,就會引發這個異常。
還有一個要注意的是innodb_lock_wait_timeout與lock_wait_timeout也是不一樣的。
innodb_lock_wait_timeout:innodb的dml操作的行級鎖的等待時間
lock_wait_timeout:數據結構ddl操作的鎖的等待時間
那么如何查看innodb_lock_wait_timeout的具體值:
SHOW VARIABLES LIKE 'innodb_lock_wait_timeout'
ps. 注意global的修改對當前線程是不生效的,只有建立新的連接才生效
五、日志刷新導致IO過高 可能存在MySQL在日志在每次事務提交時,都會將其寫入并刷新到磁盤,造成磁盤IO的高占用。如果所在磁盤是機械磁盤的話,可能io會更高。 通過在MySQL命令行運行以下命令: show variables like 'sync_binlog'; 可以看到:sync_binlog 的值為1。 該值意味著:啟用在提交事務之前將二進制日志同步到磁盤。這是最安全的設置,但是會造成磁盤的較高占用。 show variables like 'innodb_flush_log_at_trx_commit'; 可以看到:innodb_flush_log_at_trx_commit 的值為1。 該值意味著:日志會在每次事務提交時寫入并刷新到磁盤。
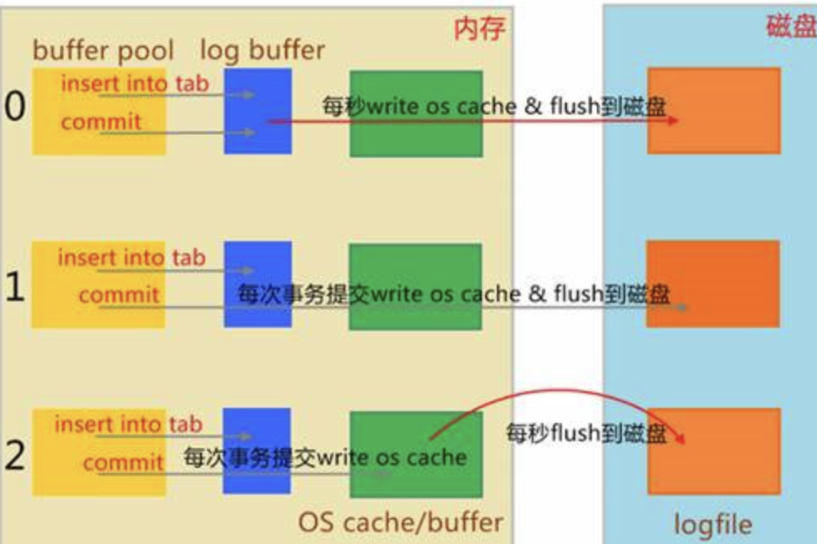
對于設置 0 和 2,不能 100% 保證每秒一次刷新。
注意:這種解決辦法是在犧牲數據庫安全的前提下,提高磁盤的性能!!!更改配置可能會帶來更高的數據丟失風險!!!
六、臨時表創建過多導致IO過高 mysql> show global status like '%tmp%'; +-------------------------+-------+ | Variable_name | Value | +-------------------------+-------+ | Created_tmp_disk_tables | 3 | | Created_tmp_files | 22 | | Created_tmp_tables | 8 | +-------------------------+-------+ ————————————————
多執行幾次,如果發現tmp_files和tmp_disk_tables的值在增長,證明在大量的創建臨時文件及磁盤臨時表,則會引起磁盤IO過高。
常見的情況會導致頻繁建立臨時表
1. UNION查詢;
2. insert into select ...from ...
3. ORDER BY和GROUP BY的子句不一樣時;
4.數據表中包含blob/text列
其他更多創建臨時表過多的情況可參考官方文檔:
七、有頻繁的全表掃描的sql導致IO過高 查看sql的全表掃描次數: show global status like '%Select_scan%'; 頻繁的全表掃描也會引起數據庫的io過高。
八、大事務寫Binlog導致實例I/O高 現象 事務只有在提交時才會寫Binlog文件,如果存在大事務,例如一條Delete語句刪除大量的行,可能會產生幾十GB的Binlog文件,Binlog文件刷新到磁盤時,會造成很高的I/O吞吐。 解決方案 建議盡量將事務拆分,避免大事務和降低刷新磁盤頻率。
九、DDL語句導致實例I/O高
現象
DDL語句可能會重建表空間,期間會掃描全表數據、創建索引排序、刷新新表產生的臟頁,這些都會導致大量的I/O吞吐。另外一種場景是刪除大表造成的I/O抖動。
十、 MySQL活躍線程數高 活躍線程數或活躍連接數是衡量MySQL負載狀態的關鍵指標,通常來說一個比較健康的實例活躍連接數應該低于10,高規格和高QPS的實例活躍連接數可能20、30,如果出現幾百、上千的活躍連接數,說明出現了SQL堆積和響應變慢,嚴重時會導致實例停止響應,無法繼續處理SQL請求。 mysql> show global status like 'Thread%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | Threads_cached | 31 | | Threads_connected | 239 | | Threads_created | 2914 | | Threads_running | 4 | +-------------------+-------+ 排查慢SQL堆積問題 首先通過show processlist;命令查看是否有慢SQL。如果有很多掃描行數太多的SQL,容易導致活躍連接數升高。 排查表緩存(Table Cache)問題 現象 Table Cache不足時,會導致大量SQL處于Opening table狀態,在QPS過高或者表很多的場景容易出現。 解決方案 將參數table_open_cache(不需要重啟實例)和table_open_cache_instances(需要重啟實例)調大。 排查行鎖沖突問題 現象 行鎖沖突表現為Innodb_row_lock_waits和Innodb_row_lock_time監控項的指標升高。 解決方案 可以通過show engine innodb status;命令查看是否有大量會話處于Lock wait狀態,如果有,說明行鎖沖突比較嚴重,需要通過優化熱點更新、降低事務大小、及時提交事務等方法避免行鎖沖突。
https://blog.csdn.net/xiangzaixiansheng/article/details/127049454

 浙公網安備 33010602011771號
浙公網安備 33010602011771號